
Top Related Projects

爬虫集合

一些非常有趣的python爬虫例子,对新手比较友好,主要爬取淘宝、天猫、微信、微信读书、豆瓣、QQ等网站。(Some interesting examples of python crawlers that are friendly to beginners. )

Python ProxyPool for web spider

😮python模拟登陆一些大型网站,还有一些简单的爬虫,希望对你们有所帮助❤️,如果喜欢记得给个star哦🌟

简单易用的Python爬虫框架,QQ交流群:597510560

A Powerful Spider(Web Crawler) System in Python.
Quick Overview
Jack-Cherish/python-spider is a comprehensive collection of Python web scraping projects and tutorials. It covers various scraping techniques for different websites and platforms, including social media, e-commerce, and entertainment sites. The repository serves as both a learning resource and a practical toolkit for developers interested in web scraping with Python.
Pros
- Diverse range of scraping projects covering popular websites and platforms
- Detailed explanations and comments in the code for educational purposes
- Regular updates and maintenance by the author
- Includes both basic and advanced scraping techniques
Cons
- Some projects may become outdated as websites change their structure
- Limited documentation in English (primarily in Chinese)
- May require additional setup for certain dependencies or libraries
- Some examples might not follow best practices for large-scale or production use
Code Examples
- Basic web scraping using requests and BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1').text
print(f"Page title: {title}")
- Scraping with Selenium for dynamic content:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://example.com')
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "dynamic-content"))
)
print(element.text)
driver.quit()
- Asynchronous scraping using aiohttp:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['https://example1.com', 'https://example2.com', 'https://example3.com']
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
responses = await asyncio.gather(*tasks)
for response in responses:
print(len(response))
asyncio.run(main())
Getting Started
To get started with the Jack-Cherish/python-spider projects:
-
Clone the repository:
git clone https://github.com/Jack-Cherish/python-spider.git -
Install required dependencies:
cd python-spider pip install -r requirements.txt -
Choose a project from the repository and navigate to its directory.
-
Run the Python script:
python script_name.py
Note: Some projects may require additional setup or configuration. Refer to the individual project's README or comments for specific instructions.
Competitor Comparisons
爬虫集合
Pros of awesome-spider
- Comprehensive collection of spider resources and projects
- Well-organized with categories for different types of spiders
- Includes a wide range of languages and frameworks
Cons of awesome-spider
- Lacks detailed explanations or tutorials for each project
- May not be as beginner-friendly as python-spider
- Some listed projects might be outdated or no longer maintained
Code Comparison
python-spider example:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
awesome-spider doesn't provide direct code examples, as it's a curated list of resources. However, it links to various projects with their own implementations.
Summary
python-spider is more focused on providing practical Python-based web scraping examples and tutorials, making it ideal for beginners and those specifically interested in Python. awesome-spider, on the other hand, offers a broader overview of web scraping resources across multiple languages and frameworks, making it valuable for developers seeking diverse approaches to web scraping.
一些非常有趣的python爬虫例子,对新手比较友好,主要爬取淘宝、天猫、微信、微信读书、豆瓣、QQ等网站。(Some interesting examples of python crawlers that are friendly to beginners. )
Pros of examples-of-web-crawlers
- More diverse examples covering various platforms (WeChat, Bilibili, Douban, etc.)
- Includes practical applications like sending emails and generating word clouds
- Better documentation with detailed explanations for each crawler
Cons of examples-of-web-crawlers
- Less frequently updated compared to python-spider
- Fewer stars and forks, indicating potentially less community engagement
- Some examples may be outdated due to changes in target websites
Code Comparison
examples-of-web-crawlers (WeChat friends analysis):
itchat.auto_login(hotReload=True)
friends = itchat.get_friends(update=True)[0:]
male = female = other = 0
for i in friends[1:]:
sex = i["Sex"]
if sex == 1:
male += 1
elif sex == 2:
female += 1
else:
other += 1
python-spider (Bilibili video downloader):
def download(self, url, name):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}
r = requests.get(url=url, headers=headers, stream=True)
with open(name, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
Both repositories offer valuable resources for learning web scraping in Python, with examples-of-web-crawlers providing a wider range of practical applications and python-spider offering more frequent updates and a larger community.
Python ProxyPool for web spider
Pros of proxy_pool
- Focuses specifically on proxy management, providing a robust solution for maintaining and utilizing proxy pools
- Offers a RESTful API for easy integration with other projects
- Includes automatic proxy validation and scoring system
Cons of proxy_pool
- More limited in scope compared to python-spider's diverse collection of web scraping examples
- May require additional setup and maintenance for the proxy pool infrastructure
- Less suitable for beginners looking for general web scraping tutorials
Code Comparison
proxy_pool example (proxy retrieval):
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
proxy = get_proxy().get("proxy")
python-spider example (basic web scraping):
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
proxy_pool is specialized for proxy management, while python-spider provides a broader range of web scraping examples and techniques. The choice between them depends on the specific needs of your project, with proxy_pool being more suitable for projects requiring extensive proxy usage and python-spider offering a wider variety of web scraping tutorials and examples.
😮python模拟登陆一些大型网站,还有一些简单的爬虫,希望对你们有所帮助❤️,如果喜欢记得给个star哦🌟
Pros of awesome-python-login-model
- Focuses specifically on login models, providing a more specialized resource
- Includes a wider variety of login examples for different websites and platforms
- Offers more detailed explanations and comments in the code samples
Cons of awesome-python-login-model
- Less comprehensive in terms of overall web scraping techniques
- Fewer examples of data extraction and processing after login
- May not be as frequently updated as python-spider
Code Comparison
python-spider:
def get_page(url):
response = requests.get(url, headers=headers)
return response.text
def parse_page(html):
soup = BeautifulSoup(html, 'html.parser')
# Extract data from soup
awesome-python-login-model:
def login(username, password):
session = requests.Session()
login_data = {'username': username, 'password': password}
response = session.post(login_url, data=login_data, headers=headers)
return session if response.status_code == 200 else None
def get_protected_content(session, url):
response = session.get(url)
# Process protected content
The code comparison shows that python-spider focuses more on general web scraping techniques, while awesome-python-login-model emphasizes the login process and accessing protected content.
简单易用的Python爬虫框架,QQ交流群:597510560
Pros of PSpider
- More comprehensive and structured framework for building scalable spiders
- Better documentation and code organization
- Includes built-in support for distributed crawling
Cons of PSpider
- Steeper learning curve due to its more complex architecture
- Less frequently updated compared to python-spider
- Fewer example scripts for specific use cases
Code Comparison
PSpider example:
from pspider import spider, parser
@spider.route()
def start_page(spider):
yield "http://example.com"
@parser.route()
def parse_page(parser):
title = parser.css("h1::text").extract_first()
yield {"title": title}
python-spider example:
import requests
from bs4 import BeautifulSoup
url = "http://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
title = soup.find("h1").text
print({"title": title})
PSpider offers a more structured approach with decorators and built-in parsing methods, while python-spider provides simpler, more straightforward scripts using popular libraries like requests and BeautifulSoup.
A Powerful Spider(Web Crawler) System in Python.
Pros of pyspider
- More comprehensive framework with a web-based UI for managing crawlers
- Built-in support for distributed crawling and task queue management
- Extensive documentation and active community support
Cons of pyspider
- Steeper learning curve due to its more complex architecture
- May be overkill for simple scraping tasks
- Less frequently updated compared to python-spider
Code Comparison
pyspider:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://example.com/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
python-spider:
import requests
from bs4 import BeautifulSoup
def crawl(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a', href=True)
for link in links:
print(link['href'])
The pyspider example showcases its framework-based approach with decorators and callbacks, while python-spider demonstrates a simpler, script-based method using popular libraries like requests and BeautifulSoup.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
注ï¼2020å¹´ææ°è¿è½½æç¨è¯·ç§»æ¥ï¼Python Spider 2020
å 责声æï¼
大家请以å¦ä¹ 为ç®ç使ç¨æ¬ä»åºï¼ç¬è«è¿æ³è¿è§çæ¡ä»¶ï¼https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
æ¬ä»åºçææå å®¹ä» ä¾å¦ä¹ ååèä¹ç¨ï¼ç¦æ¢ç¨äºåä¸ç¨éãä»»ä½äººæç»ç»ä¸å¾å°æ¬ä»åºçå 容ç¨äºéæ³ç¨éæä¾µç¯ä»äººåæ³æçãæ¬ä»åºææ¶åçç¬è«ææ¯ä» ç¨äºå¦ä¹ åç 究ï¼ä¸å¾ç¨äºå¯¹å ¶ä»å¹³å°è¿è¡å¤§è§æ¨¡ç¬è«æå ¶ä»éæ³è¡ä¸ºã对äºå 使ç¨æ¬ä»åºå 容èå¼èµ·çä»»ä½æ³å¾è´£ä»»ï¼æ¬ä»åºä¸æ¿æ ä»»ä½è´£ä»»ã使ç¨æ¬ä»åºçå 容å³è¡¨ç¤ºæ¨åææ¬å 责声æçæææ¡æ¬¾åæ¡ä»¶ã
Python Spider
ååæç« æ¯å¨æå°ä¸¤ç¯ï¼åç»ææ°æç« ä¼å¨ãå ¬ä¼å·ãé¦åï¼è§é¢ãBç«ãé¦åï¼å¤§å®¶å¯ä»¥å æã微信ãè¿äº¤æµç¾¤ï¼ææ¯äº¤æµæææè§é½å¯ä»¥ï¼æ¬¢è¿Starï¼

![]()
![]()
![]()
声æ
- 代ç ãæç¨ä» éäºå¦ä¹ 交æµï¼è¯·å¿ç¨äºä»»ä½åä¸ç¨éï¼
ç®å½
- ç¬è«å°å·¥å ·
- ç¬è«å®æ
- ç¬è¶£çå°è¯´ä¸è½½
- ç¾åº¦æåºå è´¹æç« ä¸è½½å©æ_rev1
- ç¾åº¦æåºå è´¹æç« ä¸è½½å©æ_rev2
- ãå¸ åãç½å¸ å¥å¾çä¸è½½
- æ建代çIPæ±
- ãç«å½±å¿è ã漫ç»ä¸è½½
- è´¢å¡æ¥è¡¨ä¸è½½å°å©æ
- ä¸å°æ¶å ¥é¨ç½ç»ç¬è«
- æé³Appè§é¢ä¸è½½
- GEETESTéªè¯ç è¯å«
- 12306æ¢ç¥¨å°å©æ
- ç¾ä¸è±éçé¢è¾ å©ç³»ç»
- ç½æäºé³ä¹å è´¹é³ä¹æ¹éä¸è½½
- Bç«å è´¹è§é¢åå¼¹å¹æ¹éä¸è½½
- 京ä¸ååæåå¾ä¸è½½
- æ£æ¹æå¡ç®¡çç³»ç»ä¸ªäººä¿¡æ¯æ¥è¯¢
- å ¶å®
ç¬è«å°å·¥å ·
-
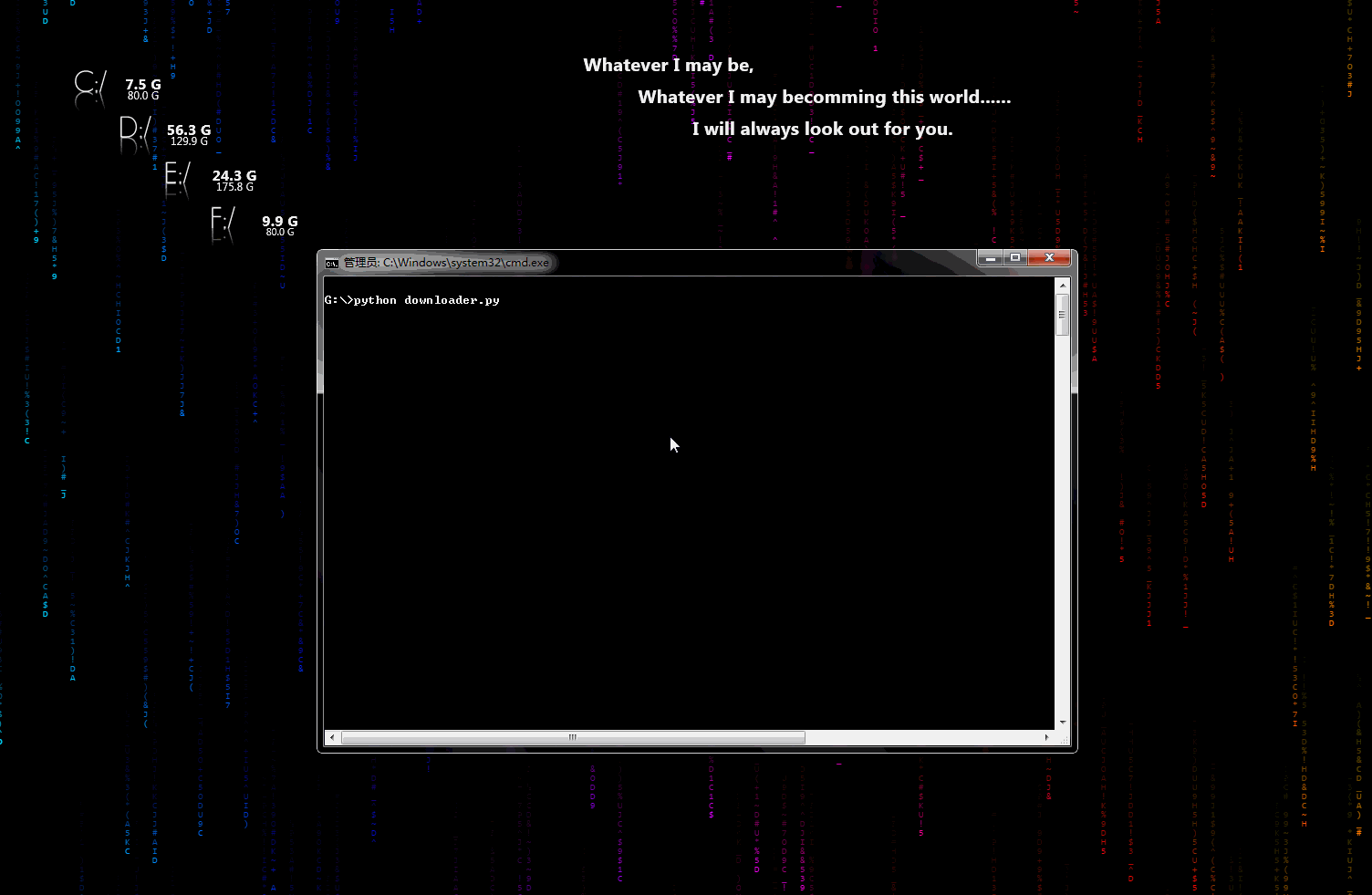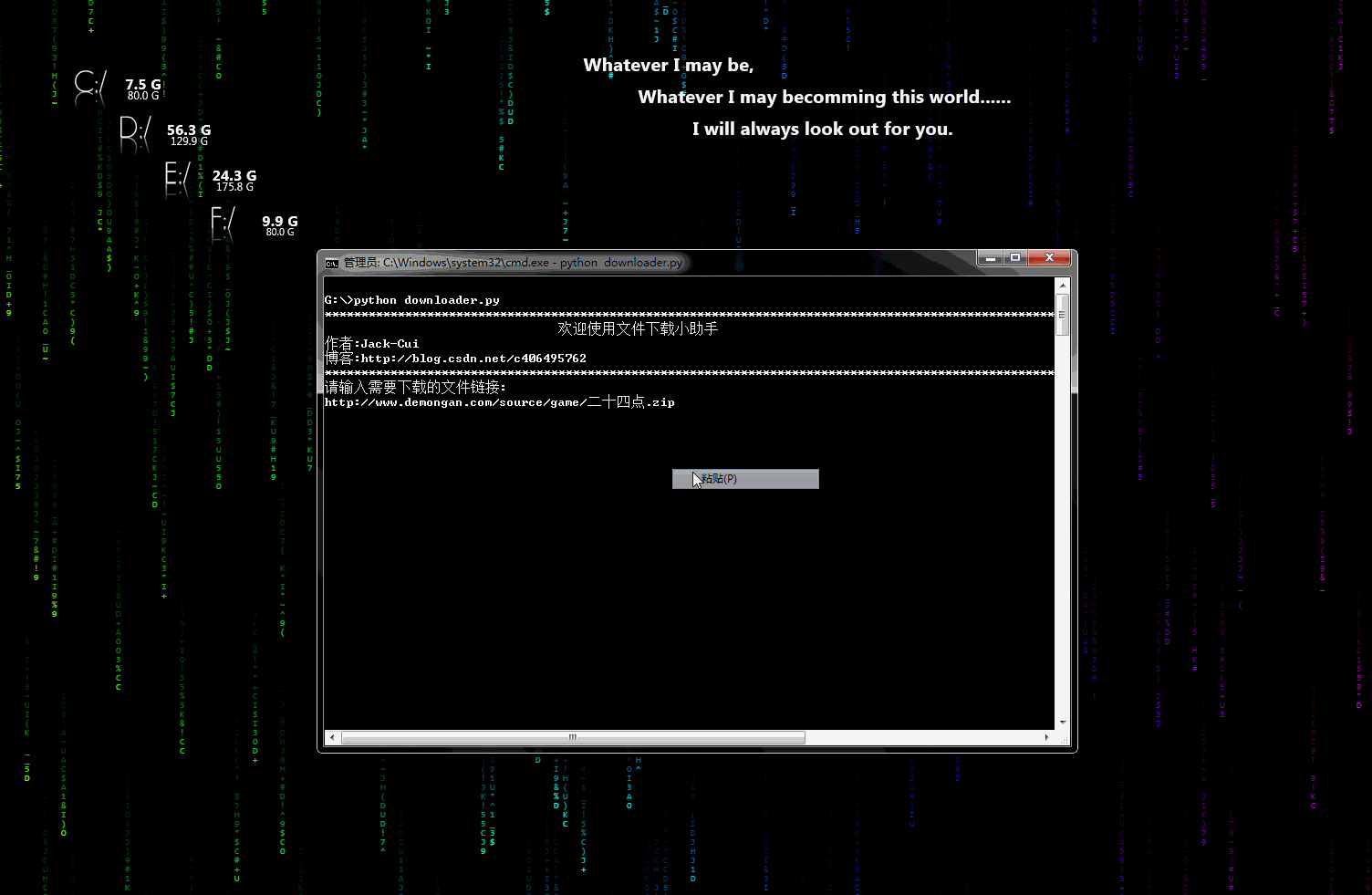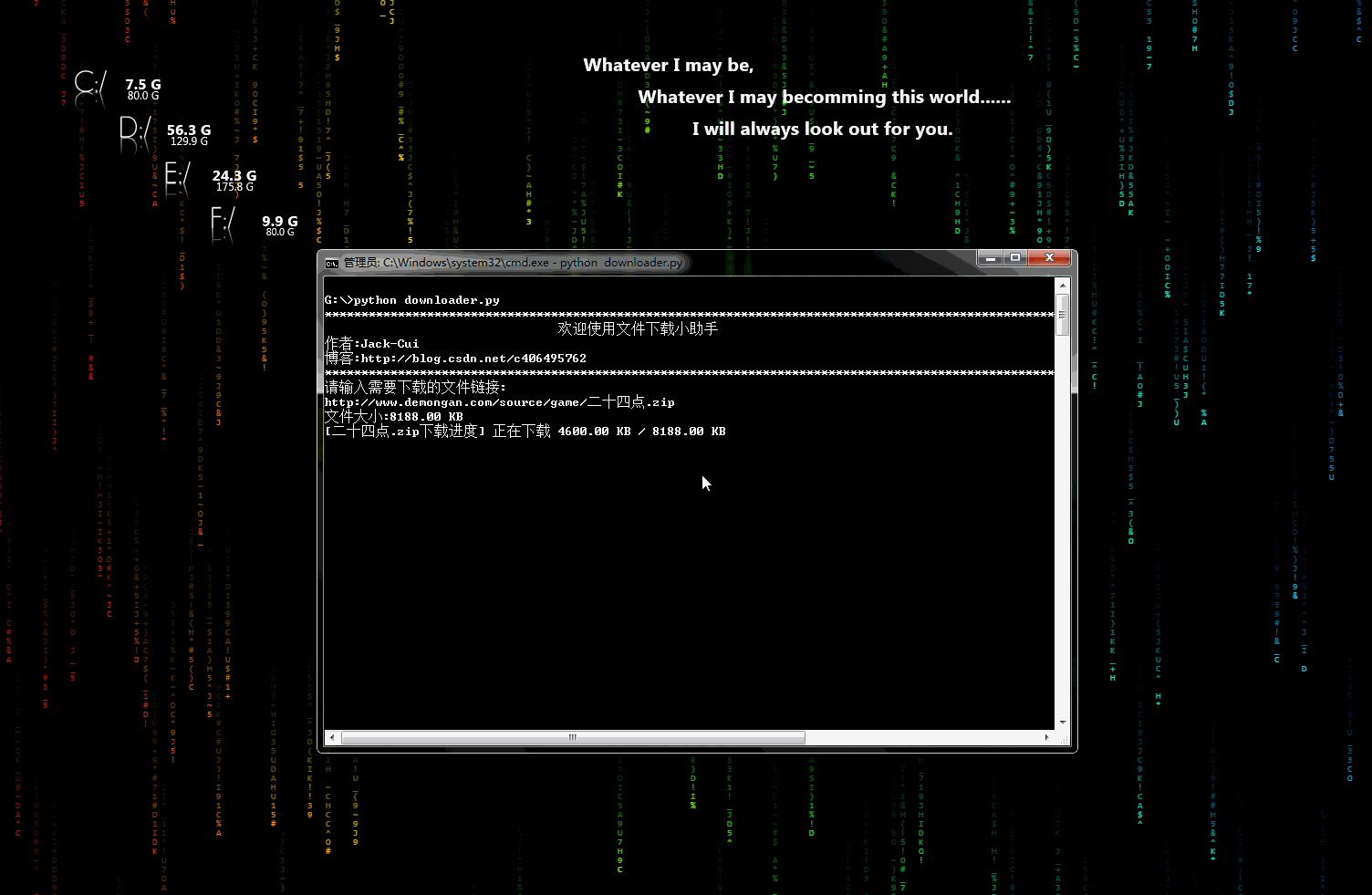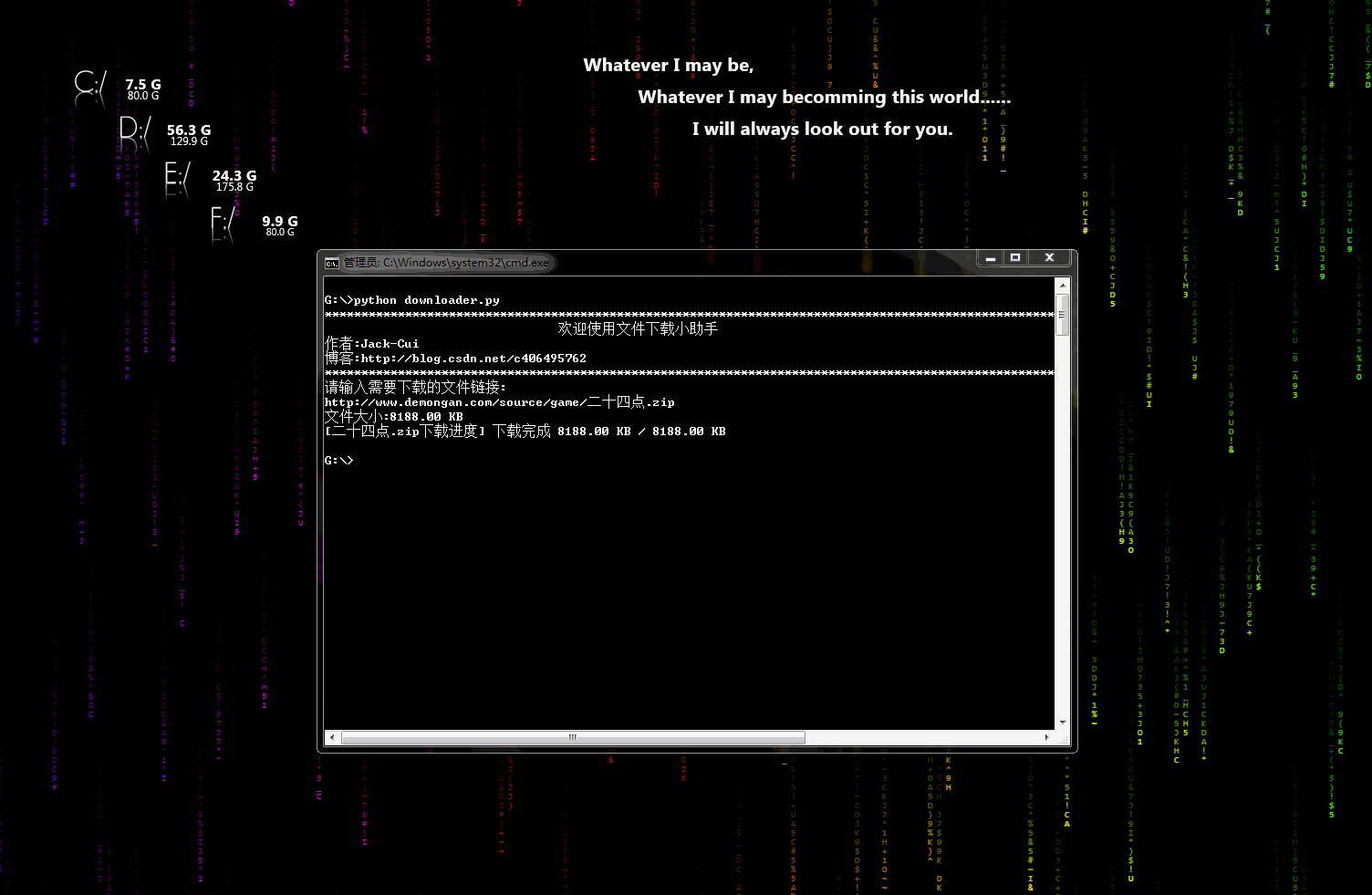
downloader.py:æ件ä¸è½½å°å©æ
ä¸ä¸ªå¯ä»¥ç¨äºä¸è½½å¾çãè§é¢ãæ件çå°å·¥å ·ï¼æä¸è½½è¿åº¦æ¾ç¤ºåè½ãç¨å ä¿®æ¹å³å¯æ·»å å°èªå·±çç¬è«ä¸ã
å¨æ示æå¾ï¼
ç¬è«å®æ
-
biqukan.py:ãç¬è¶£çãççå°è¯´ç½ç«ï¼ç¬åå°è¯´å·¥å ·
第ä¸æ¹ä¾èµåºå®è£ ï¼
pip3 install beautifulsoup4使ç¨æ¹æ³ï¼
python biqukan.py -
baiduwenku.py: ç¾åº¦æåºwordæç« ç¬å
åç说æï¼http://blog.csdn.net/c406495762/article/details/72331737
代ç ä¸å®åï¼æ²¡æè¿è¡æå ï¼ä¸å ·éç¨æ§ï¼çº¯å±å¨±ä¹ã
-
shuaia.py: ç¬åãå¸ åãç½ï¼å¸ å¥å¾ç
ãå¸ åãç½URLï¼http://www.shuaia.net/index.html
åç说æï¼http://blog.csdn.net/c406495762/article/details/72597755
第ä¸æ¹ä¾èµåºå®è£ ï¼
pip3 install requests beautifulsoup4 -
daili.py: æ建代çIPæ±
åç说æï¼http://blog.csdn.net/c406495762/article/details/72793480
-
carton: 使ç¨Scrapyç¬åãç«å½±å¿è ã漫ç»
代ç å¯ä»¥ç¬åæ´ä¸ªãç«å½±å¿è ã漫ç»ææç« èçå 容ï¼ä¿åå°æ¬å°ãæ´æ¹å°åï¼å¯ä»¥ç¬åå ¶ä»æ¼«ç»ãä¿åå°åå¯ä»¥å¨settings.pyä¸ä¿®æ¹ã
å¨æ¼«ç½ç«ï¼http://comic.kukudm.com/
åç说æï¼http://blog.csdn.net/c406495762/article/details/72858983
-
hero.py: ãçè è£èãæ¨èåºè£ æ¥è¯¢å°å©æ
ç½é¡µç¬åå·²ç»ä¼äºï¼æ³è¿ç¬åææºAPPéçå 容åï¼
åç说æï¼http://blog.csdn.net/c406495762/article/details/76850843
-
financical.py: è´¢å¡æ¥è¡¨ä¸è½½å°å©æ
ç¬åçæ°æ®åå ¥æ°æ®åºä¼åï¼ãè·è¡ç¥å·´è²ç¹å¦ä¹ çè¡ä¹è´¢å¡æ¥è¡¨å ¥åº(MySQL)ãä¹è®¸è½ç»ä½ ä¸äºæè·¯ã
åç说æï¼http://blog.csdn.net/c406495762/article/details/77801899
å¨æ示æå¾ï¼

-
one_hour_spider:ä¸å°æ¶å ¥é¨Python3ç½ç»ç¬è«ã
åç说æ:
- ç¥ä¹ï¼https://zhuanlan.zhihu.com/p/29809609
- CSDNï¼http://blog.csdn.net/c406495762/article/details/78123502
æ¬æ¬¡å®æå 容æï¼
- ç½ç»å°è¯´ä¸è½½(éæç½ç«)-biqukan
- ä¼ç¾å£çº¸ä¸è½½(å¨æç½ç«)-unsplash
- è§é¢ä¸è½½
-
douyin.py:æé³Appè§é¢ä¸è½½
æé³Appçè§é¢ä¸è½½ï¼å°±æ¯æ®éçAppç¬åã
åç说æ:
- 个人ç½ç«ï¼http://cuijiahua.com/blog/2018/03/spider-5.html
-
douyin_pro:æé³Appè§é¢ä¸è½½ï¼å级çï¼
æé³Appçè§é¢ä¸è½½ï¼æ·»å è§é¢è§£æç½ç«ï¼æ¯ææ æ°´å°è§é¢ä¸è½½ï¼ä½¿ç¨ç¬¬ä¸æ¹å¹³å°è§£æã
åç说æ:
- 个人ç½ç«ï¼http://cuijiahua.com/blog/2018/03/spider-5.html
-
douyin:æé³Appè§é¢ä¸è½½ï¼å级ç2ï¼
æé³Appçè§é¢ä¸è½½ï¼æ·»å è§é¢è§£æç½ç«ï¼æ¯ææ æ°´å°è§é¢ä¸è½½ï¼éè¿url解æï¼æ é第ä¸æ¹å¹³å°ã
åç说æ:
- 个人ç½ç«ï¼http://cuijiahua.com/blog/2018/03/spider-5.html
å¨æ示æå¾ï¼

-
geetest.py:GEETESTéªè¯ç è¯å«
åç说æ:
æ
-
12306.py:ç¨Pythonæ¢ç«è½¦ç¥¨ç®å代ç
å¯ä»¥èªå·±æ ¢æ ¢ä¸°å¯ï¼è®ç®åï¼æç¬è«åºç¡å¾å¥½æä½ï¼æ²¡æåç说æã
-
baiwan:ç¾ä¸è±éè¾ å©çé¢
ææå¾ï¼

åç说æï¼
- 个人ç½ç«ï¼http://cuijiahua.com/blog/2018/01/spider_3.html
åè½ä»ç»ï¼
æå¡å¨ç«¯ï¼ä½¿ç¨Pythonï¼baiwan.pyï¼éè¿æå è·å¾çæ¥å£è·åçé¢æ°æ®ï¼è§£æä¹åéè¿ç¾åº¦ç¥éæç´¢æ¥å£å¹é çæ¡ï¼å°æç»å¹é çç»æåå ¥æ件ï¼file.txt)ã
ææºæå ä¸ä¼çæåï¼å¯ä»¥çä¸æçæ©æææºAPPæå æç¨ã
Node.jsï¼app.jsï¼æ¯é1s读åä¸æ¬¡file.txtæ件ï¼å¹¶å°è¯»åç»æéè¿socket.ioæ¨éç»å®¢æ·ç«¯ï¼index.htmlï¼ã
亲æµçé¢å»¶æ¶å¨3så·¦å³ã
声æï¼æ²¡åè¿å端åå端ï¼è±äºä¸å¤©æ¶é´ï¼ç°å¦ç°åå¼å¥½çï¼javascriptä¹æ¯ç°çç°ç¨ï¼ç¾åº¦çç¨åºï¼è°è¯è°è¯èå·²ãå¯è½æå¾å¤ç¨æ³æ¯è¾lowçå°æ¹ï¼ç¨æ³ä¸å¯¹ï¼è¯·å¿è§æªï¼æ大çæå ´è¶£ï¼å¯ä»¥èªè¡å®åã
-
Netease:æ ¹æ®æåä¸è½½ç½æäºé³ä¹
ææå¾ï¼

åç说æï¼
ææ
åè½ä»ç»ï¼
æ ¹æ®music_list.txtæ件éçæåçä¿¡æ¯ä¸è½½ç½æäºé³ä¹ï¼å°èªå·±å欢çé³ä¹è¿è¡æ¹éä¸è½½ã
-
bilibiliï¼Bç«è§é¢åå¼¹å¹æ¹éä¸è½½
åç说æï¼
ææ
使ç¨è¯´æï¼
python bilibili.py -d ç« -k ç« -p 10 ä¸ä¸ªåæ°ï¼ -d ä¿åè§é¢çæ件夹å -k Bç«æç´¢çå ³é®å -p ä¸è½½æç´¢ç»æåå¤å°é¡µ -
jingdongï¼äº¬ä¸ååæåå¾ä¸è½½
ææå¾ï¼

åç说æï¼
ææ
使ç¨è¯´æï¼
python jd.py -k èæ ä¸ä¸ªåæ°ï¼ -d ä¿åå¾ççè·¯å¾ï¼é»è®¤ä¸ºfd.pyæ件æå¨æ件夹 -k æç´¢å ³é®è¯ -n ä¸è½½ååçæåå¾ä¸ªæ°ï¼å³n个ååºçæåå¾ -
zhengfang_system_spiderï¼å¯¹æ£æ¹æå¡ç®¡çç³»ç»ä¸ªäººè¯¾è¡¨ï¼ä¸ªäººå¦çæ绩ï¼ç»©ç¹çç®åç¬å
ææå¾ï¼

åç说æï¼
ææ
使ç¨è¯´æï¼
cd zhengfang_system_spider pip install -r requirements.txt python spider.py
å ¶å®
- æ¬¢è¿ Pull requestsï¼æ谢贡ç®ã
æ´å¤ç²¾å½©ï¼æ¬è¯·æå¾ ï¼

Top Related Projects
爬虫集合
一些非常有趣的python爬虫例子,对新手比较友好,主要爬取淘宝、天猫、微信、微信读书、豆瓣、QQ等网站。(Some interesting examples of python crawlers that are friendly to beginners. )
Python ProxyPool for web spider
😮python模拟登陆一些大型网站,还有一些简单的爬虫,希望对你们有所帮助❤️,如果喜欢记得给个star哦🌟
简单易用的Python爬虫框架,QQ交流群:597510560
A Powerful Spider(Web Crawler) System in Python.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot