
Top Related Projects
NVIDIA device plugin for Kubernetes
Build and run Docker containers leveraging NVIDIA GPUs
Tools for building GPU clusters
Build and run containers leveraging NVIDIA GPUs

Machine Learning Toolkit for Kubernetes

Deploy a Production Ready Kubernetes Cluster
Quick Overview
The NVIDIA GPU Operator is a Kubernetes operator that simplifies the management and deployment of NVIDIA GPUs in Kubernetes clusters. It automates the provisioning of GPU drivers, container runtime, device plugins, and monitoring tools, making it easier to run GPU-accelerated workloads on Kubernetes.
Pros
- Simplifies GPU management in Kubernetes environments
- Automates driver installation and updates across nodes
- Provides seamless integration with NVIDIA's GPU monitoring tools
- Supports various Kubernetes distributions and cloud platforms
Cons
- Requires cluster-admin privileges for installation
- May introduce additional complexity for small-scale deployments
- Limited to NVIDIA GPUs only
- Potential performance overhead due to containerization of GPU components
Getting Started
To deploy the NVIDIA GPU Operator, follow these steps:
- Add the NVIDIA Helm repository:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
- Install the GPU Operator:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator
- Verify the installation:
kubectl get pods -n gpu-operator
For more detailed instructions and configuration options, refer to the official documentation in the repository.
Competitor Comparisons
NVIDIA device plugin for Kubernetes
Pros of k8s-device-plugin
- Lightweight and focused solely on GPU device management
- Easier to set up and configure for basic GPU support in Kubernetes
- Lower resource overhead compared to the full GPU Operator
Cons of k8s-device-plugin
- Limited functionality, only handles GPU device allocation
- Requires manual installation and management of NVIDIA drivers and container runtime
- Less automated and comprehensive than the GPU Operator for complex deployments
Code Comparison
k8s-device-plugin:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
gpu-operator:
apiVersion: nvidia.com/v1
kind: ClusterPolicy
metadata:
name: cluster-policy
spec:
dcgmExporter:
enabled: true
devicePlugin:
enabled: true
driver:
enabled: true
The k8s-device-plugin uses a simple DaemonSet to deploy the plugin, while the gpu-operator uses a custom resource (ClusterPolicy) to manage various components, including the device plugin, drivers, and monitoring tools.
Build and run Docker containers leveraging NVIDIA GPUs
Pros of nvidia-docker
- Simpler setup and usage for Docker environments
- Lightweight solution for GPU support in containers
- Easier to integrate into existing Docker workflows
Cons of nvidia-docker
- Limited to Docker environments only
- Requires manual installation and configuration of NVIDIA drivers
- Less automated management of GPU resources
Code Comparison
nvidia-docker:
docker run --gpus all nvidia/cuda:11.0-base nvidia-smi
gpu-operator:
apiVersion: "nvidia.com/v1"
kind: "ClusterPolicy"
metadata:
name: "cluster-policy"
spec:
operator:
defaultRuntime: containerd
The nvidia-docker project focuses on enabling GPU support for Docker containers, while the gpu-operator is designed for Kubernetes environments. nvidia-docker provides a simpler solution for Docker users but lacks the comprehensive management features of gpu-operator.
gpu-operator offers automated driver installation, GPU resource allocation, and monitoring capabilities for Kubernetes clusters. It provides a more robust and scalable solution for managing GPUs in containerized environments, especially for larger deployments.
While nvidia-docker requires manual driver installation and configuration, gpu-operator automates these processes, making it easier to manage GPU resources across multiple nodes in a Kubernetes cluster.
Tools for building GPU clusters
Pros of DeepOps
- Broader scope, covering full-stack GPU-accelerated infrastructure deployment
- Supports multiple deployment options (on-premise, cloud, hybrid)
- Includes additional tools and scripts for cluster management and monitoring
Cons of DeepOps
- More complex setup and configuration process
- Requires more manual intervention and customization
- May have a steeper learning curve for users new to GPU-accelerated infrastructure
Code Comparison
DeepOps (Ansible playbook example):
- name: Install NVIDIA GPU Operator
kubernetes:
definition: "{{ lookup('template', 'gpu-operator.yml.j2') | from_yaml }}"
state: present
GPU Operator (Helm installation):
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm install --wait --generate-name nvidia/gpu-operator
Summary
DeepOps offers a comprehensive solution for deploying and managing GPU-accelerated infrastructure, while the GPU Operator focuses specifically on simplifying GPU management in Kubernetes clusters. DeepOps provides more flexibility and features but requires more setup effort, whereas the GPU Operator is easier to deploy but has a narrower scope.
Build and run containers leveraging NVIDIA GPUs
Pros of nvidia-container-toolkit
- Lightweight and focused on container runtime integration
- Easier to set up and use in non-Kubernetes environments
- More flexible for custom configurations and setups
Cons of nvidia-container-toolkit
- Requires manual installation and configuration of NVIDIA drivers
- Less automated management of GPU resources across nodes
- Limited built-in monitoring and health-checking capabilities
Code Comparison
nvidia-container-toolkit:
docker run --gpus all nvidia/cuda:11.0-base nvidia-smi
gpu-operator:
apiVersion: "nvidia.com/v1"
kind: "ClusterPolicy"
metadata:
name: "cluster-policy"
spec:
operator:
defaultRuntime: containerd
The nvidia-container-toolkit focuses on enabling GPU support in container runtimes, while the gpu-operator provides a more comprehensive solution for managing NVIDIA GPUs in Kubernetes clusters. The gpu-operator automates driver installation, device plugin deployment, and GPU feature discovery, making it easier to manage GPU resources at scale in Kubernetes environments. However, the nvidia-container-toolkit offers more flexibility for non-Kubernetes setups and custom configurations.
Machine Learning Toolkit for Kubernetes
Pros of Kubeflow
- Comprehensive ML platform with various components (pipelines, notebooks, model serving)
- Supports multiple ML frameworks and tools
- Active community and extensive documentation
Cons of Kubeflow
- More complex setup and configuration
- Steeper learning curve for beginners
- Requires more resources to run full platform
Code Comparison
Kubeflow deployment:
apiVersion: kfdef.apps.kubeflow.org/v1
kind: KfDef
metadata:
name: kubeflow
spec:
applications:
- name: jupyter
- name: pipelines
- name: katib
GPU Operator deployment:
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: gpu-operator-certified
spec:
channel: stable
name: gpu-operator-certified
source: nvidia-gpu-operator
The GPU Operator focuses specifically on managing NVIDIA GPUs in Kubernetes clusters, while Kubeflow provides a broader ML platform. GPU Operator is simpler to deploy and manage, but offers less functionality for ML workflows. Kubeflow is more feature-rich but requires more setup and resources. Both can be used together for GPU-accelerated ML workloads in Kubernetes.
Deploy a Production Ready Kubernetes Cluster
Pros of kubespray
- Broader scope: Deploys full Kubernetes clusters, not limited to GPU support
- Flexible deployment options: Supports various cloud providers and on-premises setups
- Customizable: Allows fine-tuning of cluster configuration
Cons of kubespray
- More complex setup: Requires more configuration and understanding of Kubernetes
- Not GPU-specific: Lacks specialized features for GPU management in clusters
Code Comparison
kubespray (inventory file example):
all:
hosts:
node1:
ansible_host: 192.168.1.10
ip: 192.168.1.10
access_ip: 192.168.1.10
node2:
ansible_host: 192.168.1.11
ip: 192.168.1.11
access_ip: 192.168.1.11
gpu-operator (Helm values example):
operator:
defaultRuntime: containerd
driver:
enabled: true
version: "470.82.01"
toolkit:
enabled: true
While kubespray focuses on overall cluster deployment with inventory files, gpu-operator uses Helm charts for GPU-specific configurations. kubespray offers more flexibility for general Kubernetes setups, but gpu-operator provides specialized GPU management features for NVIDIA hardware in Kubernetes environments.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME



NVIDIA GPU Operator
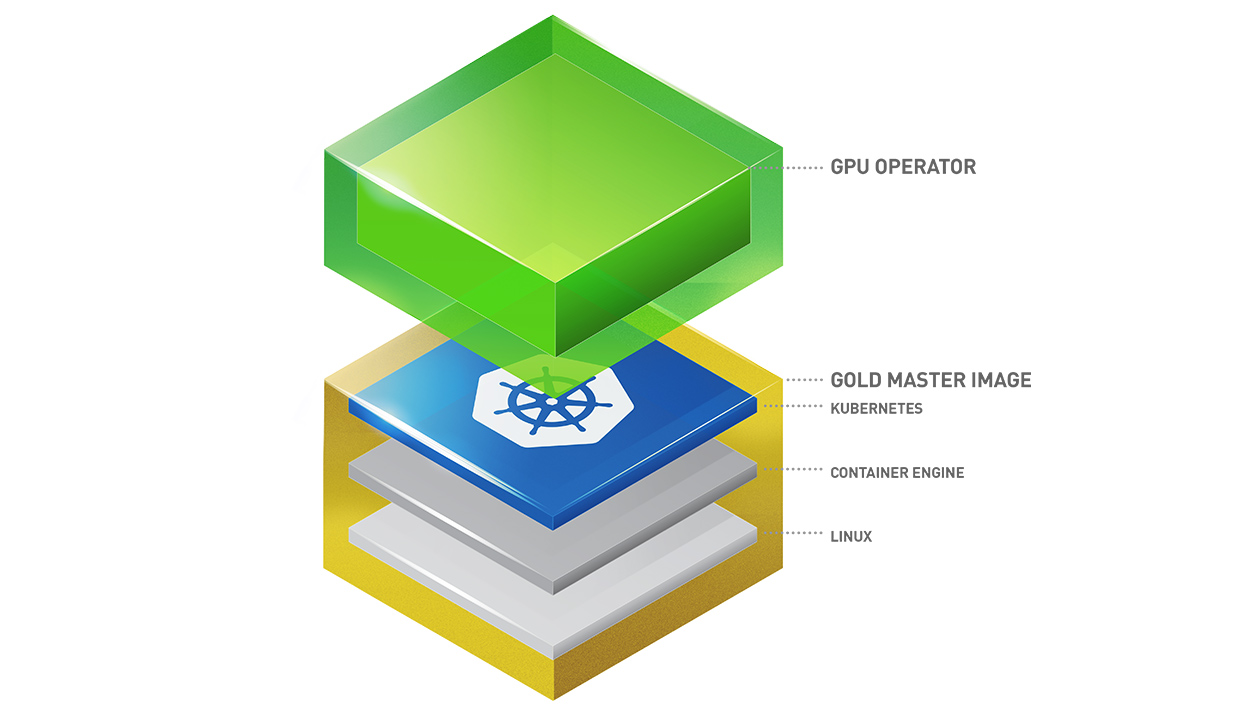
Kubernetes provides access to special hardware resources such as NVIDIA GPUs, NICs, Infiniband adapters and other devices through the device plugin framework. However, configuring and managing nodes with these hardware resources requires configuration of multiple software components such as drivers, container runtimes or other libraries which are difficult and prone to errors. The NVIDIA GPU Operator uses the operator framework within Kubernetes to automate the management of all NVIDIA software components needed to provision GPU. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin for GPUs, the NVIDIA Container Runtime, automatic node labelling, DCGM based monitoring and others.
Audience and Use-Cases
The GPU Operator allows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. Instead of provisioning a special OS image for GPU nodes, administrators can rely on a standard OS image for both CPU and GPU nodes and then rely on the GPU Operator to provision the required software components for GPUs.
Note that the GPU Operator is specifically useful for scenarios where the Kubernetes cluster needs to scale quickly - for example provisioning additional GPU nodes on the cloud or on-prem and managing the lifecycle of the underlying software components. Since the GPU Operator runs everything as containers including NVIDIA drivers, the administrators can easily swap various components - simply by starting or stopping containers.
Product Documentation
For information on platform support and getting started, visit the official documentation repository.
Webinar
How to easily use GPUs on Kubernetes
Contributions
Read the document on contributions. You can contribute by opening a pull request.
Support and Getting Help
Please open an issue on the GitHub project for any questions. Your feedback is appreciated.
Top Related Projects
NVIDIA device plugin for Kubernetes
Build and run Docker containers leveraging NVIDIA GPUs
Tools for building GPU clusters
Build and run containers leveraging NVIDIA GPUs
Machine Learning Toolkit for Kubernetes
Deploy a Production Ready Kubernetes Cluster
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot