 TNN
TNN
TNN: developed by Tencent Youtu Lab and Guangying Lab, a uniform deep learning inference framework for mobile、desktop and server. TNN is distinguished by several outstanding features, including its cross-platform capability, high performance, model compression and code pruning. Based on ncnn and Rapidnet, TNN further strengthens the support and performance optimization for mobile devices, and also draws on the advantages of good extensibility and high performance from existed open source efforts. TNN has been deployed in multiple Apps from Tencent, such as Mobile QQ, Weishi, Pitu, etc. Contributions are welcome to work in collaborative with us and make TNN a better framework.
Top Related Projects

MNN is a blazing fast, lightweight deep learning framework, battle-tested by business-critical use cases in Alibaba. Full multimodal LLM Android App:[MNN-LLM-Android](./apps/Android/MnnLlmChat/README.md). MNN TaoAvatar Android - Local 3D Avatar Intelligence: apps/Android/Mnn3dAvatar/README.md

MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms.
ncnn is a high-performance neural network inference framework optimized for the mobile platform

Tengine is a lite, high performance, modular inference engine for embedded device
Quick Overview
TNN is a high-performance, lightweight neural network inference framework developed by Tencent. It is optimized for mobile platforms, providing efficient model deployment solutions for iOS, Android, and embedded devices. TNN supports various neural network architectures and is designed to balance performance and flexibility.
Pros
- Cross-platform support (iOS, Android, Windows, Linux, and embedded devices)
- High performance and low latency on mobile devices
- Supports multiple deep learning frameworks (TensorFlow, PyTorch, MXNet, Caffe)
- Provides model compression and quantization tools
Cons
- Limited documentation and examples compared to some other frameworks
- Smaller community and ecosystem compared to more established frameworks
- Primarily focused on inference, not training
- May require more setup and configuration for complex use cases
Code Examples
- Loading and running a model:
#include "tnn/core/tnn.h"
TNN_NS::TNN tnn;
TNN_NS::Status status;
// Initialize TNN
status = tnn.Init(proto_file, model_file);
// Create input and output
std::shared_ptr<TNN_NS::Mat> input_mat = std::make_shared<TNN_NS::Mat>(TNN_NS::DEVICE_ARM, TNN_NS::N8UC3, nchw_dims);
std::shared_ptr<TNN_NS::Mat> output_mat = std::make_shared<TNN_NS::Mat>(TNN_NS::DEVICE_ARM, TNN_NS::NCHW_FLOAT, nchw_dims);
// Forward
status = instance->Forward(input_mat, output_mat);
- Converting a model to TNN format:
import onnx2tnn
onnx_path = "model.onnx"
output_dir = "./tnn_model"
onnx2tnn.convert(onnx_path, output_dir)
- Quantizing a model:
#include "tnn/utils/quantize_tool.h"
TNN_NS::QuantizeParams params;
params.proto_file = "model.tnnproto";
params.model_file = "model.tnnmodel";
params.save_path = "quantized_model";
params.batch_size = 1;
params.input_shapes = {{1, 3, 224, 224}};
TNN_NS::Status status = TNN_NS::QuantizeTool::Quantize(params);
Getting Started
-
Clone the TNN repository:
git clone https://github.com/Tencent/TNN.git cd TNN -
Build TNN:
./build.sh -
Convert your model to TNN format (if needed):
import onnx2tnn onnx2tnn.convert("your_model.onnx", "output_dir") -
Use TNN in your C++ project:
#include "tnn/core/tnn.h" TNN_NS::TNN tnn; tnn.Init("model.tnnproto", "model.tnnmodel"); // ... (refer to code examples for usage)
Competitor Comparisons
MNN is a blazing fast, lightweight deep learning framework, battle-tested by business-critical use cases in Alibaba. Full multimodal LLM Android App:[MNN-LLM-Android](./apps/Android/MnnLlmChat/README.md). MNN TaoAvatar Android - Local 3D Avatar Intelligence: apps/Android/Mnn3dAvatar/README.md
Pros of MNN
- Wider platform support, including iOS, Android, Windows, Linux, and macOS
- More comprehensive documentation and examples
- Better support for quantization and model compression techniques
Cons of MNN
- Slightly slower inference speed on some devices compared to TNN
- Less focus on specialized hardware acceleration (e.g., NPU support)
- Smaller community and fewer third-party contributions
Code Comparison
MNN example:
auto interpreter = std::shared_ptr<Interpreter>(Interpreter::createFromFile(modelPath));
interpreter->runSession(session);
auto output = interpreter->getSessionOutput(session, nullptr);
TNN example:
auto net = std::make_shared<TNN>();
net->Init(model_config);
auto instance = net->CreateInst(input_config, status);
instance->Forward();
Both libraries offer similar APIs for model loading and inference, but MNN's API is generally more intuitive and easier to use. TNN's API is more low-level, providing finer control over the inference process.
MNN and TNN are both efficient deep learning inference frameworks developed by major Chinese tech companies. While MNN offers broader platform support and better documentation, TNN excels in performance on mobile devices and specialized hardware. The choice between them depends on specific project requirements and target platforms.
MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms.
Pros of MACE
- Wider platform support, including Android, iOS, Linux, and Windows
- More extensive documentation and tutorials for easier adoption
- Better support for quantization and model compression techniques
Cons of MACE
- Less frequent updates and maintenance compared to TNN
- Smaller community and fewer contributors
- Limited support for newer neural network architectures
Code Comparison
MACE example (model inference):
mace::MaceEngine engine;
MaceStatus status = CreateMaceEngineFromProto(model_graph_proto,
model_weights_data,
input_names,
output_names,
device_type,
&engine);
engine.Run(inputs, &outputs);
TNN example (model inference):
auto net = std::make_shared<TNN::TNN>();
TNN::Status status = net->Init(model_path);
auto instance = net->CreateInst(network_config, status);
instance->Forward();
Both MACE and TNN are deep learning inference frameworks designed for mobile and embedded devices. MACE offers broader platform support and more comprehensive documentation, making it easier for developers to get started. However, TNN has more active development and better support for cutting-edge neural network architectures. The code examples demonstrate that both frameworks provide similar functionality for model inference, with slightly different syntax and initialization processes.
ncnn is a high-performance neural network inference framework optimized for the mobile platform
Pros of ncnn
- Wider platform support, including mobile and embedded devices
- Smaller footprint and faster inference speed
- More mature project with a larger community and ecosystem
Cons of ncnn
- Less focus on high-level APIs and ease of use
- Limited support for newer AI models and architectures
- Fewer built-in optimizations for specific hardware platforms
Code Comparison
ncnn:
ncnn::Net net;
net.load_param("model.param");
net.load_model("model.bin");
ncnn::Mat in = ncnn::Mat::from_pixels(image_data, ncnn::Mat::PIXEL_BGR, w, h);
ncnn::Mat out;
net.extract("output", out);
TNN:
TNN_NS::ModelConfig config;
config.model_type = TNN_NS::MODEL_TYPE_TNN;
config.params.push_back("model.tnnproto");
config.params.push_back("model.tnnmodel");
TNN_NS::TNN net;
net.Init(config);
TNN_NS::InputShapesMap input_shapes;
TNN_NS::MatConvertParam param;
TNN_NS::Mat input(TNN_NS::DEVICE_NAIVE, TNN_NS::N8UC3, {w, h, 3}, image_data);
TNN_NS::Mat output;
net.GetOutputMat(output, param, "output", TNN_NS::DEVICE_NAIVE);
Tengine is a lite, high performance, modular inference engine for embedded device
Pros of Tengine
- Broader platform support, including more CPU architectures (ARM, x86, RISC-V)
- More flexible model conversion tools, supporting a wider range of input formats
- Easier to integrate with existing projects due to its modular design
Cons of Tengine
- Less optimized for mobile devices compared to TNN
- Smaller community and fewer contributors, potentially slower development
- Limited support for quantization techniques
Code Comparison
Tengine initialization:
init_tengine();
context_t ctx = create_context("ctx", 1);
graph_t graph = create_graph(ctx, "graph", NULL, 0);
TNN initialization:
TNN_NS::TNN tnn;
TNN_NS::Status status;
status = tnn.Init(model_config);
auto instance = tnn.CreateInst(network_config, status);
Both libraries offer straightforward initialization processes, but TNN's approach is more object-oriented, while Tengine uses a more C-style API. Tengine's initialization allows for more granular control over contexts and graphs, which may be beneficial for complex applications.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

Introduction
TNN: A high-performance, lightweight neural network inference framework open sourced by Tencent Youtu Lab. It also has many outstanding advantages such as cross-platform, high performance, model compression, and code tailoring. The TNN framework further strengthens the support and performance optimization of mobile devices on the basis of the original Rapidnet and ncnn frameworks. At the same time, it refers to the high performance and good scalability characteristics of the industry's mainstream open source frameworks, and expands the support for X86 and NV GPUs. On the mobile phone, TNN has been used by many applications such as mobile QQ, weishi, and Pitu. As a basic acceleration framework for Tencent Cloud AI, TNN has provided acceleration support for the implementation of many businesses. Everyone is welcome to participate in the collaborative construction to promote the further improvement of the TNN inference framework.
Effect Example
| Face Detection(blazeface) | Face Alignment (from Tencent Youtu Lab) | Hair Segmentation (from Tencent Guangying Lab) |
|---|---|---|
 model link: tflite tnn |  model link: tnn |  model link: tnn |
| Pose Estimation (from Tencent Guangliu) | Pose Estimation (blazepose) | Chinese OCR |
|---|---|---|
 model link: tnn |  model link: tflite tnn |  model link: onnx tnn |
| Object Detection(yolov5s) | Object Detection(MobilenetV2-SSD) | Reading Comprehension |
|---|---|---|
 model link: onnx tnn |  model link: tensorflow tnn | 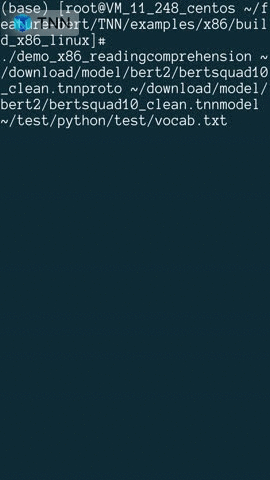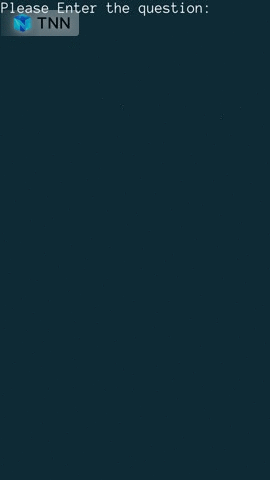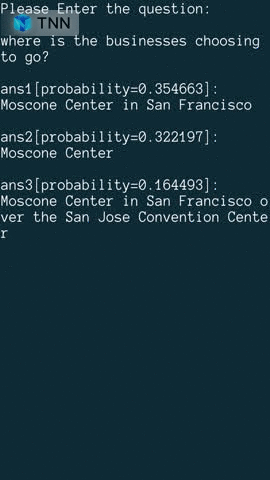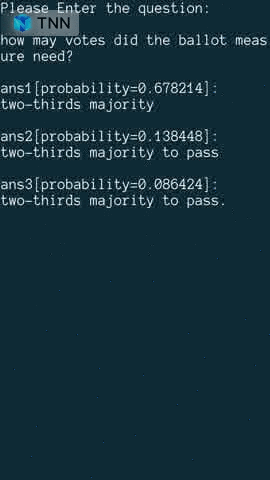 model link: onnx tnn |
Chinese OCR demo is the TNN implementation of chineseocr_lite project. It is lightweight and supports tilted, rotated and vertical text recognition.
The support for each demo is shown in the following table. You can click the â and find the entrance code for each demo.
| demo | ARM | OpenCL | Metal | Huawei NPU | Apple NPU | X86 | CUDA |
|---|---|---|---|---|---|---|---|
| Face Detection (blazeface) | â | â | â | â | â | â | â |
| Object Detection (yolov5s) | â | â | â | â | â | â | â |
| Face Alignment | â | â | â | â | â | â | â |
| Hair Segmentation | â | â | â | â | â | â | â |
| Pose Estimation (from Tencent Guangliu) | â | â | â | â | â | â | â |
| Pose Estimation (blazepose) | â | â | â | â | â | â | â |
| Chinese OCR | â | â | â | â | â | ||
| Reading Comprehension | â | â |
Quick Start
It is very simple to use TNN. If you have a trained model, the model can be deployed on the target platform through three steps.
-
Convert the trained model into a TNN model. We provide a wealth of tools to help you complete this step, whether you are using Tensorflow, Pytorch, or Caffe, you can easily complete the conversion. Detailed hands-on tutorials can be found here How to Create a TNN Model.
-
When you have finished converting the model, the second step is to compile the TNN engine of the target platform. You can choose among different acceleration solutions such as ARM/OpenCL/Metal/NPU/X86/CUDA according to the hardware support. For these platforms, TNN provides convenient one-click scripts to compile. For detailed steps, please refer to How to Compile TNN.
-
The final step is to use the compiled TNN engine for inference. You can make program calls to TNN inside your application. We provide a rich and detailed demo as a reference to help you complete.
Technical Solutions
At present, TNN has been launched in various major businesses, and its following characteristics have been widely praised.
-
Computation optimization
- The backend operators are primely optimized to make the best use of computing power in different architectures, regarding instruction issue, throughput, delay, cache bandwidth, cache delay, registers, etc..
- The TNN performance on mainstream hardware platforms (CPU: ARMv7, ARMv8ï¼ X86, GPU: Mali, Adreno, Appleï¼ NV GPUï¼ NPU) has been greatly tuned and improved.
- The convolution function is implemented by various algorithms such as Winograd, Tile-GEMM, Direct Conv, etc., to ensure efficiency under different parameters and sizes.
- Op fusion: TNN can do offline analysis of network graph, fuse multiple simple operations and reduce overhead such as redundant memory access and kernel startup cost.
-
Low precision computation acceleration
- TNN supports INT8/FP16 mode, reduces model size & memory consumption, and utilizes specific hardware low-precision instructions to accelerate calculations.
- TNN supports INT8 WINOGRAD algorithm, (input 6bit), further reduces the model calculation complexity without sacrificing the accuracy.
- TNN supports mixed-precision data in one model, speeding up the model's calculation speed while preserving its accuracy.
-
Memory optimization
- Efficient "memory pool" implementation: Based on a full network DAG analysis, the implementation reuses memory between non-dependent nodes which reduces memory cost by 90%.
- Cross-model memory reduces: This supports external real-time design for network memory so that multiple models can share mutual memory.
-
The performance of mainstream models on TNN: benchmark data
-
TNN architecture diagramï¼

-
TNN supports TensorFlow, Pytorch, MxNet, Caffe, and other training frameworks through ONNX, leveraging the continuous improvement of the ONNX open-source society. Currently, TNN supports 100+ ONNX operators, consisting of most of the mainstream CNN, NLP operators needed.
-
TNN runs on mainstream operating systems (Android, iOS, embedded Linux, Windows, Linux), and is compatible with ARM CPU,X86 GPU, NPU hardware platform.
-
TNN is constructed through Modular Design, which abstracts and isolates components such as model analysis, graph construction, graph optimization, low-level hardware adaptation, and high-performance kernel. It uses "Factory Mode" to register and build devices, that tries to minimize the cost of supporting more hardware and acceleration solutions.
-
The size of the mobile dynamic library is only around 400KB, and it provides basic image conversion operations, which are light-weight and convenient. TNN uses unified models and interfaces across platforms and can switch easily by configuring just one single parameter.
Learn About TNN Abilities
Manual
API Document
Contribute to TNN
Roadmap
Acknowledgement
TNN referenced the following projectsï¼
License
FAQ
Join Us
-
Everyone is welcome to participate to build the best inference framework in the industry.
-
Technical Discussion QQ Group: 704900079 Answer: TNN
-
Scan the QR code to join the TNN discussion groupï¼

Top Related Projects
MNN is a blazing fast, lightweight deep learning framework, battle-tested by business-critical use cases in Alibaba. Full multimodal LLM Android App:[MNN-LLM-Android](./apps/Android/MnnLlmChat/README.md). MNN TaoAvatar Android - Local 3D Avatar Intelligence: apps/Android/Mnn3dAvatar/README.md
MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms.
ncnn is a high-performance neural network inference framework optimized for the mobile platform
Tengine is a lite, high performance, modular inference engine for embedded device
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot