
Top Related Projects

Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.

12 weeks, 26 lessons, 52 quizzes, classic Machine Learning for all

🎓 Sharing machine learning course / lecture notes.
12 Weeks, 24 Lessons, AI for All!

All course materials for the Zero to Mastery Deep Learning with TensorFlow course.

A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in Python using Scikit-Learn, Keras and TensorFlow 2.
Quick Overview
The afshinea/stanford-cs-230-deep-learning repository is a comprehensive collection of cheat sheets and notes for Stanford's CS 230 Deep Learning course. It provides concise summaries of key concepts in deep learning, including neural networks, convolutional neural networks, and recurrent neural networks, as well as tips for training and optimizing deep learning models.
Pros
- Offers clear and concise summaries of complex deep learning concepts
- Provides visual aids and diagrams to enhance understanding
- Available in multiple languages, making it accessible to a global audience
- Regularly updated to reflect the latest developments in deep learning
Cons
- Not a substitute for in-depth study of the course material
- May oversimplify some concepts for the sake of brevity
- Limited interactive elements or practical exercises
- Might not cover all topics in the same depth as the full course
Code Examples
This repository does not contain code examples as it primarily consists of educational cheat sheets and notes. Therefore, this section is not applicable.
Getting Started
As this is not a code library but rather a collection of educational resources, there is no specific code-based getting started instructions. However, users can access the cheat sheets by following these steps:
- Visit the repository at https://github.com/afshinea/stanford-cs-230-deep-learning
- Browse the available cheat sheets in the desired language folder
- Click on the PDF files to view or download the cheat sheets
- Use the cheat sheets as quick reference guides while studying deep learning concepts or working on related projects
Competitor Comparisons
Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.
Pros of llm-course
- Focused specifically on Large Language Models (LLMs), providing in-depth coverage of this cutting-edge topic
- Includes practical examples and code snippets for implementing LLM techniques
- Regularly updated with the latest advancements in LLM technology
Cons of llm-course
- Less comprehensive coverage of general deep learning concepts compared to stanford-cs-230-deep-learning
- May be more challenging for beginners without a strong foundation in machine learning
- Lacks the academic rigor and structured curriculum of a Stanford course
Code Comparison
llm-course:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
stanford-cs-230-deep-learning:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
The llm-course example demonstrates loading a pre-trained LLM, while stanford-cs-230-deep-learning shows a basic neural network architecture using TensorFlow.
12 weeks, 26 lessons, 52 quizzes, classic Machine Learning for all
Pros of ML-For-Beginners
- Comprehensive curriculum covering various ML topics
- Hands-on approach with practical exercises and projects
- Suitable for beginners with little to no prior ML experience
Cons of ML-For-Beginners
- Less focus on deep learning compared to stanford-cs-230-deep-learning
- May not cover advanced topics in as much depth
- Lacks the academic rigor of a Stanford course
Code Comparison
ML-For-Beginners (Python):
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
stanford-cs-230-deep-learning (Python with TensorFlow):
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(input_dim,)),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
🎓 Sharing machine learning course / lecture notes.
Pros of ML-Course-Notes
- Covers a broader range of machine learning topics beyond deep learning
- Includes more practical examples and code snippets
- Regularly updated with new content and resources
Cons of ML-Course-Notes
- Less structured and organized compared to stanford-cs-230-deep-learning
- May lack the depth and rigor of a formal university course
- Not specifically tailored for a single course or curriculum
Code Comparison
ML-Course-Notes:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
stanford-cs-230-deep-learning:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
The code snippets demonstrate the difference in focus between the two repositories. ML-Course-Notes provides examples using popular machine learning libraries like scikit-learn, while stanford-cs-230-deep-learning emphasizes deep learning frameworks such as TensorFlow.
12 Weeks, 24 Lessons, AI for All!
Pros of AI-For-Beginners
- Comprehensive curriculum covering various AI topics beyond deep learning
- Includes hands-on coding exercises and projects for practical learning
- Regularly updated with contributions from the community
Cons of AI-For-Beginners
- Less focused on deep learning specifically compared to stanford-cs-230-deep-learning
- May be overwhelming for absolute beginners due to its broad scope
- Lacks the academic rigor of a Stanford course
Code Comparison
stanford-cs-230-deep-learning (Python):
# Example of a neural network layer
class Dense(Layer):
def __init__(self, input_dim, output_dim, activation):
self.weights = np.random.randn(input_dim, output_dim) * 0.01
self.bias = np.zeros((1, output_dim))
self.activation = activation
AI-For-Beginners (Python):
# Example of a simple neural network
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.hidden_layer = Layer(input_size, hidden_size)
self.output_layer = Layer(hidden_size, output_size)
Both repositories provide code examples, but AI-For-Beginners tends to offer more diverse and practical implementations across various AI topics, while stanford-cs-230-deep-learning focuses specifically on deep learning concepts and implementations.
All course materials for the Zero to Mastery Deep Learning with TensorFlow course.
Pros of tensorflow-deep-learning
- More comprehensive and practical, with hands-on code examples
- Regularly updated with the latest TensorFlow features
- Includes end-to-end projects and real-world applications
Cons of tensorflow-deep-learning
- Focuses primarily on TensorFlow, limiting exposure to other frameworks
- May be overwhelming for absolute beginners due to its depth
- Less emphasis on theoretical foundations compared to stanford-cs-230-deep-learning
Code Comparison
tensorflow-deep-learning:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
stanford-cs-230-deep-learning:
# No direct code examples provided
# Focuses on theoretical concepts and mathematical foundations
The tensorflow-deep-learning repository provides practical code implementations, while stanford-cs-230-deep-learning emphasizes theoretical concepts without extensive code examples.
tensorflow-deep-learning is better suited for hands-on learners and those looking to build practical deep learning projects with TensorFlow. stanford-cs-230-deep-learning is ideal for students seeking a strong theoretical foundation in deep learning concepts, regardless of the specific framework used.
A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in Python using Scikit-Learn, Keras and TensorFlow 2.
Pros of handson-ml3
- More comprehensive coverage of machine learning topics, including traditional ML and deep learning
- Includes practical, hands-on examples and exercises using popular libraries like scikit-learn and TensorFlow
- Regularly updated with new content and improvements
Cons of handson-ml3
- May be overwhelming for beginners due to its extensive scope
- Focuses more on practical implementation rather than in-depth theoretical explanations
Code Comparison
stanford-cs-230-deep-learning:
# No code samples available in the repository
handson-ml3:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=100, random_state=42)
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
Summary
handson-ml3 offers a more comprehensive and practical approach to machine learning, covering a wide range of topics with hands-on examples. It's regularly updated but may be challenging for beginners. stanford-cs-230-deep-learning focuses specifically on deep learning concepts from Stanford's CS230 course, providing concise summaries and cheat sheets. While it lacks code examples, it offers a more focused and theoretical approach to deep learning topics.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Deep Learning cheatsheets for Stanford's CS 230
Available in English - ÙØ§Ø±Ø³Û - Français - æ¥æ¬èª - íêµì´ - Türkçe - Tiếng Viá»t
Goal
This repository aims at summing up in the same place all the important notions that are covered in Stanford's CS 230 Deep Learning course, and include:
- Cheatsheets detailing everything about convolutional neural networks, recurrent neural networks, as well as the tips and tricks to have in mind when training a deep learning model.
- All elements of the above combined in an ultimate compilation of concepts, to have with you at all times!
Content
VIP Cheatsheets
 | 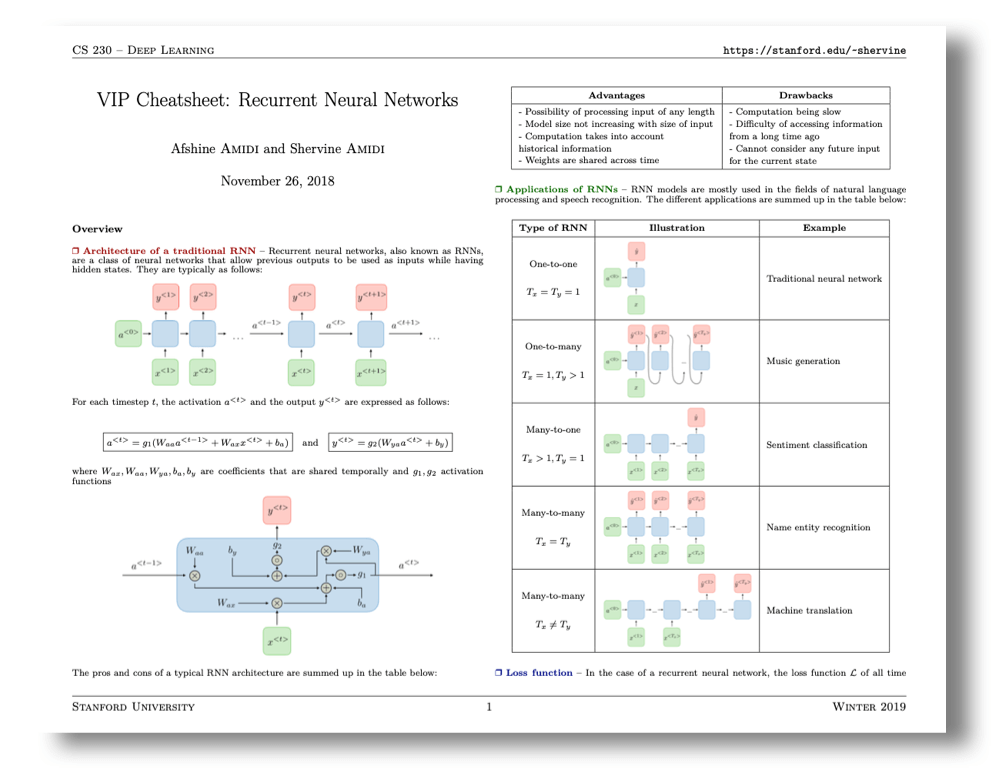 |  |
|---|---|---|
| Convolutional Neural Networks | Recurrent Neural Networks | Tips and tricks |
Super VIP Cheatsheet
 |
|---|
| All the above gathered in one place |
Website
This material is also available on a dedicated website, so that you can enjoy reading it from any device.
Translation
Would you like to see these cheatsheets in your native language? You can help us translating them on this dedicated repo!
Authors
Afshine Amidi (Ecole Centrale Paris, MIT) and Shervine Amidi (Ecole Centrale Paris, Stanford University)
Top Related Projects
Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.
12 weeks, 26 lessons, 52 quizzes, classic Machine Learning for all
🎓 Sharing machine learning course / lecture notes.
12 Weeks, 24 Lessons, AI for All!
All course materials for the Zero to Mastery Deep Learning with TensorFlow course.
A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in Python using Scikit-Learn, Keras and TensorFlow 2.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot