 mxnet
mxnet
Lightweight, Portable, Flexible Distributed/Mobile Deep Learning with Dynamic, Mutation-aware Dataflow Dep Scheduler; for Python, R, Julia, Scala, Go, Javascript and more
Top Related Projects

An Open Source Machine Learning Framework for Everyone

Tensors and Dynamic neural networks in Python with strong GPU acceleration

ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator

Deep Learning for humans

Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more

Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Quick Overview
Apache MXNet is an open-source deep learning framework used for training and deploying deep neural networks. It is designed to be flexible, efficient, and scalable, supporting multiple programming languages and running on various hardware platforms, including CPUs, GPUs, and distributed environments.
Pros
- Highly scalable and efficient, supporting distributed training across multiple GPUs and machines
- Supports multiple programming languages, including Python, C++, R, and Julia
- Offers a hybrid frontend that combines declarative and imperative programming styles
- Provides a rich ecosystem of tools and libraries for various deep learning tasks
Cons
- Smaller community compared to more popular frameworks like TensorFlow and PyTorch
- Documentation can be inconsistent or outdated in some areas
- Less frequent updates and releases compared to other major deep learning frameworks
- Steeper learning curve for beginners due to its flexibility and multiple programming paradigms
Code Examples
- Creating a simple neural network:
import mxnet as mx
from mxnet import gluon, autograd
# Define the network
net = gluon.nn.Sequential()
with net.name_scope():
net.add(gluon.nn.Dense(128, activation='relu'))
net.add(gluon.nn.Dense(64, activation='relu'))
net.add(gluon.nn.Dense(10))
# Initialize parameters
net.initialize(mx.init.Xavier())
- Training a model:
# Define loss and optimizer
loss_fn = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': 0.01})
# Training loop
for epoch in range(num_epochs):
for batch in train_data:
with autograd.record():
output = net(batch.data)
loss = loss_fn(output, batch.label)
loss.backward()
trainer.step(batch.data.shape[0])
- Inference with a trained model:
# Load test data
test_data = mx.gluon.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# Perform inference
for batch in test_data:
data = batch.data.as_in_context(mx.cpu())
pred = net(data)
# Process predictions
Getting Started
To get started with Apache MXNet, follow these steps:
- Install MXNet:
pip install mxnet
- Import the library and create a simple neural network:
import mxnet as mx
from mxnet import gluon
net = gluon.nn.Sequential()
with net.name_scope():
net.add(gluon.nn.Dense(64, activation='relu'))
net.add(gluon.nn.Dense(10))
net.initialize(mx.init.Xavier())
- Prepare data and train the model:
# Prepare data (example using MNIST dataset)
train_data = mx.gluon.data.DataLoader(mx.gluon.data.vision.MNIST(train=True), batch_size=32, shuffle=True)
# Define loss and optimizer
loss_fn = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': 0.01})
# Train the model
for epoch in range(5):
for batch in train_data:
with mx.autograd.record():
output = net(batch.data)
loss = loss_fn(output, batch.label)
loss.backward()
trainer.step(batch.data.shape[0])
Competitor Comparisons
An Open Source Machine Learning Framework for Everyone
Pros of TensorFlow
- Larger community and ecosystem, with more resources and third-party libraries
- Better support for production deployment and mobile/edge devices
- More comprehensive documentation and tutorials
Cons of TensorFlow
- Steeper learning curve, especially for beginners
- Less flexible and dynamic compared to MXNet's imperative programming model
- Slower development cycle for new features
Code Comparison
MXNet:
import mxnet as mx
from mxnet import nd, autograd, gluon
x = nd.array([[1, 2], [3, 4]])
y = nd.array([[5, 6], [7, 8]])
z = x + y
TensorFlow:
import tensorflow as tf
x = tf.constant([[1, 2], [3, 4]])
y = tf.constant([[5, 6], [7, 8]])
z = tf.add(x, y)
Both frameworks offer similar functionality for basic operations, but TensorFlow's syntax is slightly more verbose. MXNet's NDArray is more similar to NumPy, which may be more intuitive for some users. However, TensorFlow's eager execution mode has bridged this gap in recent versions.
Tensors and Dynamic neural networks in Python with strong GPU acceleration
Pros of PyTorch
- More intuitive and Pythonic API, easier for beginners to learn
- Dynamic computational graphs allow for more flexible model architectures
- Stronger community support and faster adoption in research
Cons of PyTorch
- Slightly slower performance in some production environments
- Less mature deployment options compared to MXNet's optimized inference engines
- Smaller ecosystem of pre-trained models and tools for mobile/edge devices
Code Comparison
MXNet example:
import mxnet as mx
data = mx.symbol.Variable('data')
fc1 = mx.symbol.FullyConnected(data, name='fc1', num_hidden=128)
act1 = mx.symbol.Activation(fc1, name='relu1', act_type="relu")
PyTorch example:
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.relu = nn.ReLU()
Both frameworks offer powerful deep learning capabilities, but PyTorch's ease of use and flexibility have contributed to its growing popularity in research and academia. MXNet, backed by Amazon, provides strong performance and scalability for production environments, especially in cloud and edge computing scenarios.
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
Pros of ONNX Runtime
- Broader ecosystem support and compatibility with various ML frameworks
- Optimized for inference performance across different hardware platforms
- Extensive support for quantization and model optimization techniques
Cons of ONNX Runtime
- Less focus on training capabilities compared to MXNet
- Steeper learning curve for developers familiar with traditional deep learning frameworks
- Limited support for certain advanced research-oriented features
Code Comparison
MXNet example:
import mxnet as mx
data = mx.symbol.Variable('data')
fc1 = mx.symbol.FullyConnected(data, name='fc1', num_hidden=128)
act1 = mx.symbol.Activation(fc1, name='relu1', act_type="relu")
ONNX Runtime example:
import onnxruntime as ort
session = ort.InferenceSession("model.onnx")
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
result = session.run([output_name], {input_name: input_data})
Deep Learning for humans
Pros of Keras
- More user-friendly and intuitive API, making it easier for beginners to get started
- Excellent documentation and community support
- Flexibility to use different backend engines (TensorFlow, Theano, CNTK)
Cons of Keras
- Less fine-grained control over low-level operations compared to MXNet
- Potentially slower performance for complex models due to higher-level abstractions
Code Comparison
Keras:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
MXNet:
import mxnet as mx
data = mx.symbol.Variable('data')
fc1 = mx.symbol.FullyConnected(data=data, num_hidden=64)
act1 = mx.symbol.Activation(data=fc1, act_type="relu")
fc2 = mx.symbol.FullyConnected(data=act1, num_hidden=10)
mlp = mx.symbol.SoftmaxOutput(data=fc2, name='softmax')
The code comparison shows that Keras offers a more concise and readable syntax for defining neural networks, while MXNet provides a more symbolic approach with greater flexibility for advanced users.
Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
Pros of JAX
- Designed for high-performance numerical computing and machine learning
- Supports automatic differentiation and GPU/TPU acceleration
- Offers a more functional programming style, making it easier to write and debug complex algorithms
Cons of JAX
- Smaller ecosystem and fewer pre-built models compared to MXNet
- Steeper learning curve for developers not familiar with functional programming concepts
- Less focus on production deployment and serving of models
Code Comparison
MXNet example:
import mxnet as mx
from mxnet import nd, autograd, gluon
x = nd.array([[1, 2], [3, 4]])
y = nd.array([[5, 6], [7, 8]])
z = mx.nd.dot(x, y)
JAX example:
import jax.numpy as jnp
from jax import grad, jit
x = jnp.array([[1, 2], [3, 4]])
y = jnp.array([[5, 6], [7, 8]])
z = jnp.dot(x, y)
Both examples demonstrate basic matrix multiplication, but JAX's syntax is more similar to NumPy, while MXNet uses its own array library.
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Pros of Horovod
- Simpler distributed training setup, especially for TensorFlow and PyTorch
- Better performance scaling across multiple GPUs and nodes
- Easier integration with existing deep learning frameworks
Cons of Horovod
- Limited to specific deep learning frameworks (TensorFlow, PyTorch, Keras)
- Less flexible than MXNet for custom operations and architectures
- Smaller ecosystem and community compared to MXNet
Code Comparison
MXNet example:
import mxnet as mx
from mxnet import gluon, autograd
net = gluon.nn.Dense(10)
loss = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.1})
Horovod example:
import tensorflow as tf
import horovod.tensorflow as hvd
hvd.init()
model = tf.keras.Sequential([tf.keras.layers.Dense(10)])
optimizer = tf.keras.optimizers.SGD(0.1 * hvd.size())
optimizer = hvd.DistributedOptimizer(optimizer)
Both examples show basic model and optimizer setup, but Horovod simplifies distributed training with minimal code changes.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
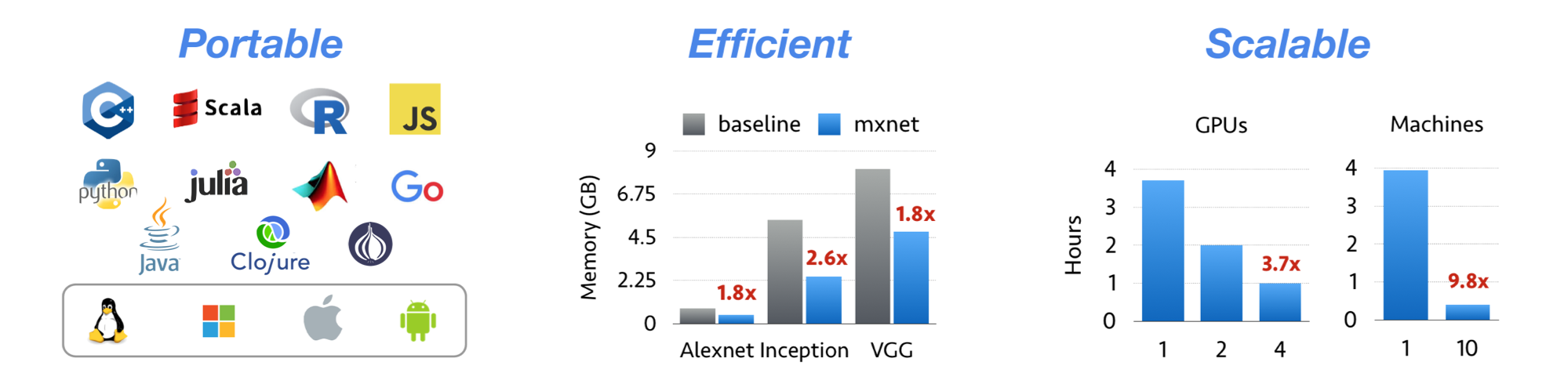
Apache MXNet for Deep Learning










Apache MXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scalable to many GPUs and machines.
Apache MXNet is more than a deep learning project. It is a community on a mission of democratizing AI. It is a collection of blue prints and guidelines for building deep learning systems, and interesting insights of DL systems for hackers.
Licensed under an Apache-2.0 license.
| Branch | Build Status |
|---|---|
| master | |
| v1.x |
Features
- NumPy-like programming interface, and is integrated with the new, easy-to-use Gluon 2.0 interface. NumPy users can easily adopt MXNet and start in deep learning.
- Automatic hybridization provides imperative programming with the performance of traditional symbolic programming.
- Lightweight, memory-efficient, and portable to smart devices through native cross-compilation support on ARM, and through ecosystem projects such as TVM, TensorRT, OpenVINO.
- Scales up to multi GPUs and distributed setting with auto parallelism through ps-lite, Horovod, and BytePS.
- Extensible backend that supports full customization, allowing integration with custom accelerator libraries and in-house hardware without the need to maintain a fork.
- Support for Python, Java, C++, R, Scala, Clojure, Go, Javascript, Perl, and Julia.
- Cloud-friendly and directly compatible with AWS and Azure.
Contents
What's New
- 1.9.1 Release - MXNet 1.9.1 Release.
- 1.8.0 Release - MXNet 1.8.0 Release.
- 1.7.0 Release - MXNet 1.7.0 Release.
- 1.6.0 Release - MXNet 1.6.0 Release.
- 1.5.1 Release - MXNet 1.5.1 Patch Release.
- 1.5.0 Release - MXNet 1.5.0 Release.
- 1.4.1 Release - MXNet 1.4.1 Patch Release.
- 1.4.0 Release - MXNet 1.4.0 Release.
- 1.3.1 Release - MXNet 1.3.1 Patch Release.
- 1.3.0 Release - MXNet 1.3.0 Release.
- 1.2.0 Release - MXNet 1.2.0 Release.
- 1.1.0 Release - MXNet 1.1.0 Release.
- 1.0.0 Release - MXNet 1.0.0 Release.
- 0.12.1 Release - MXNet 0.12.1 Patch Release.
- 0.12.0 Release - MXNet 0.12.0 Release.
- 0.11.0 Release - MXNet 0.11.0 Release.
- Apache Incubator - We are now an Apache Incubator project.
- 0.10.0 Release - MXNet 0.10.0 Release.
- 0.9.3 Release - First 0.9 official release.
- 0.9.1 Release (NNVM refactor) - NNVM branch is merged into master now. An official release will be made soon.
- 0.8.0 Release
Ecosystem News
- oneDNN for Faster CPU Performance
- MXNet Memory Monger, Training Deeper Nets with Sublinear Memory Cost
- Tutorial for NVidia GTC 2016
- MXNet.js: Javascript Package for Deep Learning in Browser (without server)
- Guide to Creating New Operators (Layers)
- Go binding for inference
Stay Connected
| Channel | Purpose |
|---|---|
| Follow MXNet Development on Github | See what's going on in the MXNet project. |
| MXNet Confluence Wiki for Developers | MXNet developer wiki for information related to project development, maintained by contributors and developers. To request write access, send an email to send request to the dev list . |
| dev@mxnet.apache.org mailing list | The "dev list". Discussions about the development of MXNet. To subscribe, send an email to dev-subscribe@mxnet.apache.org . |
| discuss.mxnet.io | Asking & answering MXNet usage questions. |
| Apache Slack #mxnet Channel | Connect with MXNet and other Apache developers. To join the MXNet slack channel send request to the dev list . |
| Follow MXNet on Social Media | Get updates about new features and events. |
Social Media
Keep connected with the latest MXNet news and updates.
 Apache MXNet on Twitter
Apache MXNet on Twitter
 Contributor and user blogs about MXNet
Contributor and user blogs about MXNet
 Discuss MXNet on r/mxnet
Discuss MXNet on r/mxnet Apache MXNet YouTube channel
Apache MXNet YouTube channel Apache MXNet on LinkedIn
Apache MXNet on LinkedInHistory
MXNet emerged from a collaboration by the authors of cxxnet, minerva, and purine2. The project reflects what we have learned from the past projects. MXNet combines aspects of each of these projects to achieve flexibility, speed, and memory efficiency.
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015
Top Related Projects
An Open Source Machine Learning Framework for Everyone
Tensors and Dynamic neural networks in Python with strong GPU acceleration
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
Deep Learning for humans
Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot