
Top Related Projects

Quick Overview
Apache Pinot is a real-time distributed OLAP datastore designed to deliver scalable real-time analytics with low latency. It is particularly well-suited for user-facing analytical applications that require fast analytics on freshly ingested data.
Pros
- High performance and low latency for real-time analytics
- Scalable and distributed architecture
- Supports both batch and streaming data ingestion
- Flexible query language (PQL) and SQL support
Cons
- Steep learning curve for beginners
- Limited support for complex joins compared to traditional databases
- Requires careful schema design for optimal performance
- Resource-intensive for large-scale deployments
Code Examples
- Creating a Pinot table:
Schema schema = new Schema.SchemaBuilder()
.setSchemaName("myTable")
.addSingleValueDimension("dimension1", FieldSpec.DataType.STRING)
.addMetric("metric1", FieldSpec.DataType.LONG)
.build();
TableConfig tableConfig = new TableConfig.Builder(TableType.OFFLINE)
.setTableName("myTable")
.setSchemaName("myTable")
.build();
_pinotAdmin.addSchema(schema, true);
_pinotAdmin.addTable(tableConfig);
- Querying data using PQL:
Connection connection = DriverManager.getConnection("jdbc:pinot://localhost:9000");
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT COUNT(*) FROM myTable WHERE dimension1 = 'value'");
- Ingesting data using Kafka:
StreamConfig streamConfig = new StreamConfig();
streamConfig.setStreamType("kafka");
streamConfig.setStreamKafkaConsumerType("highLevel");
streamConfig.setStreamKafkaConsumerFactory("org.apache.pinot.plugin.stream.kafka.KafkaConsumerFactory");
streamConfig.setStreamKafkaConsumerProps(kafkaConsumerProps);
tableConfig.setIngestionConfig(new IngestionConfig(null, streamConfig, null, null));
_pinotAdmin.addTable(tableConfig);
Getting Started
- Download and install Apache Pinot:
wget https://downloads.apache.org/pinot/apache-pinot-0.10.0/apache-pinot-0.10.0-bin.tar.gz
tar -xvf apache-pinot-0.10.0-bin.tar.gz
cd apache-pinot-0.10.0-bin
- Start Pinot components:
bin/quick-start-offline.sh
- Create a table and ingest data:
bin/pinot-admin.sh AddTable -schemaFile examples/batch/airlineStats/airlineStats_schema.json -tableConfigFile examples/batch/airlineStats/airlineStats_offline_table_config.json -exec
bin/pinot-admin.sh LaunchDataIngestionJob -jobSpecFile examples/batch/airlineStats/airlineStats_job_spec.yml
- Query data using Pinot Query Console at
http://localhost:9000
Competitor Comparisons
Distributed object store
Pros of Ambry
- Specialized for blob storage, offering efficient handling of large binary objects
- Simpler architecture, potentially easier to set up and maintain for specific use cases
- Designed with a focus on durability and availability of stored data
Cons of Ambry
- More limited in scope compared to Pinot's broader analytical capabilities
- Less active community and development compared to Pinot's Apache project status
- Fewer built-in features for real-time data ingestion and querying
Code Comparison
Ambry (Java):
BlobId blobId = new BlobId(version, BlobIdType.NATIVE, datacenterId, accountId, containerId, partitionId, isEncrypted, blobDataType);
BlobProperties blobProperties = new BlobProperties(blobSize, serviceId);
MessageFormatInputStream messageFormatInputStream = new PutMessageFormatInputStream(blobId, blobProperties, userMetadata, blobStream);
Pinot (Java):
Schema schema = new Schema.SchemaBuilder().setSchemaName("mySchema")
.addSingleValueDimension("dimension", FieldSpec.DataType.STRING)
.addMetric("metric", FieldSpec.DataType.LONG)
.build();
TableConfig tableConfig = new TableConfigBuilder(TableType.OFFLINE).setTableName("myTable")
.setSchemaName("mySchema").build();
Both projects use Java, but their APIs reflect their different purposes. Ambry focuses on blob storage operations, while Pinot's code emphasizes schema and table configurations for analytical processing.
Apache Druid: a high performance real-time analytics database.
Pros of Druid
- More mature project with a longer history and larger community
- Better support for complex aggregations and multi-dimensional analytics
- More flexible query language (SQL-like DruidSQL)
Cons of Druid
- Higher resource consumption and complexity in setup
- Steeper learning curve for configuration and optimization
- Less efficient for real-time ingestion of high-volume data streams
Code Comparison
Druid query example:
SELECT COUNT(*) AS count,
SUM(price) AS total_price
FROM transactions
WHERE timestamp >= CURRENT_TIMESTAMP - INTERVAL '1' DAY
GROUP BY product_id
HAVING count > 100
ORDER BY total_price DESC
LIMIT 10
Pinot query example:
SELECT COUNT(*) AS count,
SUM(price) AS total_price
FROM transactions
WHERE timestamp >= NOW() - 1d
GROUP BY product_id
HAVING count > 100
ORDER BY total_price DESC
LIMIT 10
Both systems support SQL-like queries, but Druid's query language offers more advanced features and flexibility. Pinot's syntax is generally simpler and more focused on real-time analytics use cases.
Apache HBase
Pros of HBase
- Mature and widely adopted in big data ecosystems
- Strong support for random read/write operations
- Excellent scalability for handling large datasets
Cons of HBase
- Higher latency for real-time queries
- More complex setup and maintenance
- Less optimized for analytical workloads
Code Comparison
HBase example (Java):
Put put = new Put(Bytes.toBytes("row1"));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("qual1"), Bytes.toBytes("value1"));
table.put(put);
Pinot example (Java):
GenericRow row = new GenericRow();
row.putField("dimension1", "value1");
row.putField("metric1", 100);
segmentWriter.index(row);
Key Differences
- HBase is a distributed, column-oriented database, while Pinot is a real-time distributed OLAP datastore
- Pinot is optimized for low-latency analytical queries, whereas HBase excels in random access scenarios
- HBase provides strong consistency, while Pinot focuses on eventual consistency for better query performance
Use Cases
- HBase: Large-scale data storage, random read/write operations, and applications requiring strong consistency
- Pinot: Real-time analytics, user-facing dashboards, and scenarios demanding low-latency queries on large datasets
Both projects are part of the Apache Software Foundation and have active communities, but they serve different purposes in the big data ecosystem.
Apache Cassandra®
Pros of Cassandra
- Highly scalable and distributed architecture, suitable for large-scale deployments
- Strong support for write-heavy workloads and high availability
- Mature ecosystem with extensive tooling and community support
Cons of Cassandra
- Complex query language (CQL) compared to SQL-like queries in Pinot
- Less efficient for real-time analytics and low-latency queries
- Requires more manual tuning and optimization for optimal performance
Code Comparison
Cassandra (CQL):
CREATE TABLE users (
id UUID PRIMARY KEY,
name TEXT,
email TEXT
);
Pinot:
CREATE TABLE users (
id STRING,
name STRING,
email STRING
) WITH (
"segmentName": "users"
);
Both systems use different approaches for table creation. Cassandra uses CQL, which is similar to SQL but with some differences, while Pinot uses a SQL-like syntax with additional configuration options.
Cassandra is well-suited for large-scale, distributed databases with high write throughput, while Pinot excels in real-time analytics and low-latency queries. The choice between the two depends on specific use cases and requirements.
Apache Hadoop
Pros of Hadoop
- Mature ecosystem with extensive tooling and community support
- Highly scalable for processing massive datasets across distributed clusters
- Flexible for both batch and real-time data processing
Cons of Hadoop
- Complex setup and configuration process
- Higher latency for real-time analytics compared to Pinot
- Steeper learning curve for developers and administrators
Code Comparison
Hadoop MapReduce job:
public class WordCount extends Configured implements Tool {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// ... (mapper implementation)
}
// ... (reducer and main method)
}
Pinot query:
SELECT COUNT(*) AS count, word
FROM myTable
GROUP BY word
ORDER BY count DESC
LIMIT 10
Summary
Hadoop excels in processing large-scale batch data and offers a comprehensive ecosystem. Pinot, on the other hand, is designed for real-time analytics with lower latency. Hadoop's MapReduce paradigm requires more complex Java code, while Pinot uses SQL-like queries for data analysis. Choose Hadoop for diverse big data processing needs, and Pinot for fast, real-time analytics on specific use cases.
Apache Spark - A unified analytics engine for large-scale data processing
Pros of Spark
- More mature and widely adopted ecosystem with extensive libraries and integrations
- Supports a broader range of data processing tasks, including batch processing, streaming, and machine learning
- Offers multiple language APIs (Scala, Java, Python, R) for flexibility in development
Cons of Spark
- Higher resource consumption and longer startup times, especially for small tasks
- Steeper learning curve due to its extensive feature set and distributed computing concepts
- Can be overkill for simpler data processing tasks or smaller datasets
Code Comparison
Spark (PySpark):
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Example").getOrCreate()
df = spark.read.csv("data.csv", header=True)
result = df.groupBy("column").count()
result.show()
Pinot:
Connection connection = DriverManager.getConnection("jdbc:pinot://localhost:8000");
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT column, COUNT(*) FROM myTable GROUP BY column");
while (resultSet.next()) {
System.out.println(resultSet.getString(1) + ": " + resultSet.getInt(2));
}
Note: Pinot is primarily used as a real-time distributed OLAP datastore, while Spark is a more general-purpose data processing engine. The code comparison showcases basic data querying in both systems, but their use cases and typical implementations can differ significantly.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

![]()

![]()


![]()
What is Apache Pinot?
Apache Pinot is a real-time distributed OLAP datastore, built to deliver scalable real-time analytics with low latency. It can ingest from batch data sources (such as Hadoop HDFS, Amazon S3, Azure ADLS, Google Cloud Storage) as well as stream data sources (such as Apache Kafka).
Pinot was built by engineers at LinkedIn and Uber and is designed to scale up and out with no upper bound. Performance always remains constant based on the size of your cluster and an expected query per second (QPS) threshold.
For getting started guides, deployment recipes, tutorials, and more, please visit our project documentation at https://docs.pinot.apache.org.

Features
Pinot was originally built at LinkedIn to power rich interactive real-time analytic applications such as Who Viewed Profile, Company Analytics, Talent Insights, and many more. UberEats Restaurant Manager is another example of a customer facing Analytics App. At LinkedIn, Pinot powers 50+ user-facing products, ingesting millions of events per second and serving 100k+ queries per second at millisecond latency.
-
Fast Queries: Filter and aggregate petabyte data sets with P90 latencies in the tens of millisecondsâfast enough to return live results interactively in the UI.
-
High Concurrency: With user-facing applications querying Pinot directly, it can serve hundreds of thousands of concurrent queries per second.
-
SQL Query Interface: The highly standard SQL query interface is accessible through a built-in query editor and a REST API.
-
Versatile Joins: Perform arbitrary fact/dimension and fact/fact joins on petabyte data sets.
-
Column-oriented: a column-oriented database with various compression schemes such as Run Length, Fixed Bit Length.
-
Pluggable indexing: pluggable indexing technologies including timestamp, inverted, StarTree, Bloom filter, range, text, JSON, and geospatial options.
-
Stream and batch ingest: Ingest from Apache Kafka, Apache Pulsar, and AWS Kinesis in real time. Batch ingest from Hadoop, Spark, AWS S3, and more. Combine batch and streaming sources into a single table for querying.
-
Upsert during real-time ingestion: update the data at-scale with consistency
-
Built-in Multitenancy: Manage and secure data in isolated logical namespaces for cloud-friendly resource management.
-
Built for Scale: Pinot is horizontally scalable and fault-tolerant, adaptable to workloads across the storage and throughput spectrum.
-
Cloud-native on Kubernetes: Helm chart provides a horizontally scalable and fault-tolerant clustered deployment that is easy to manage using Kubernetes.
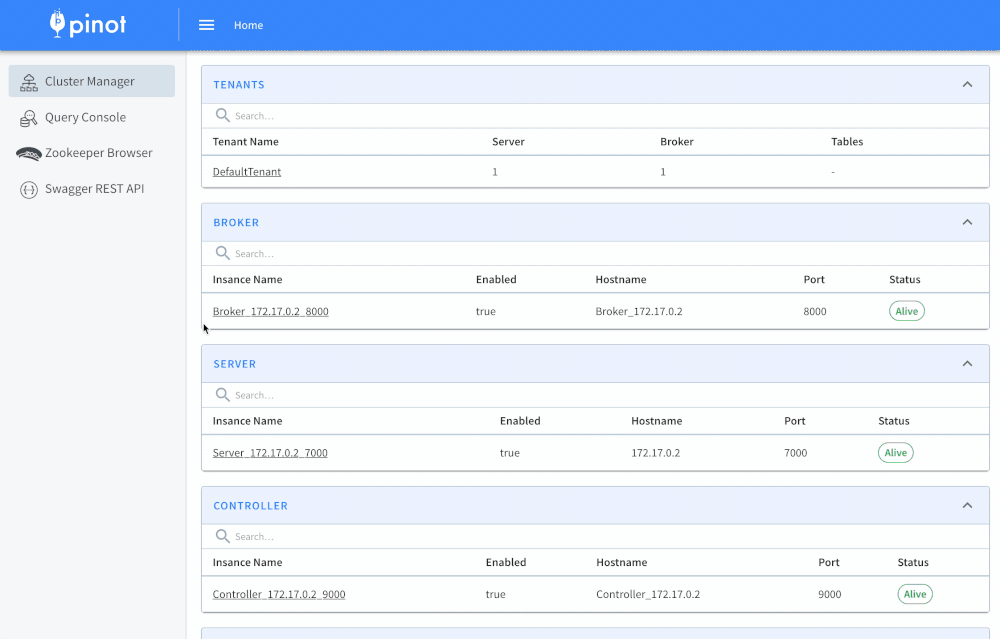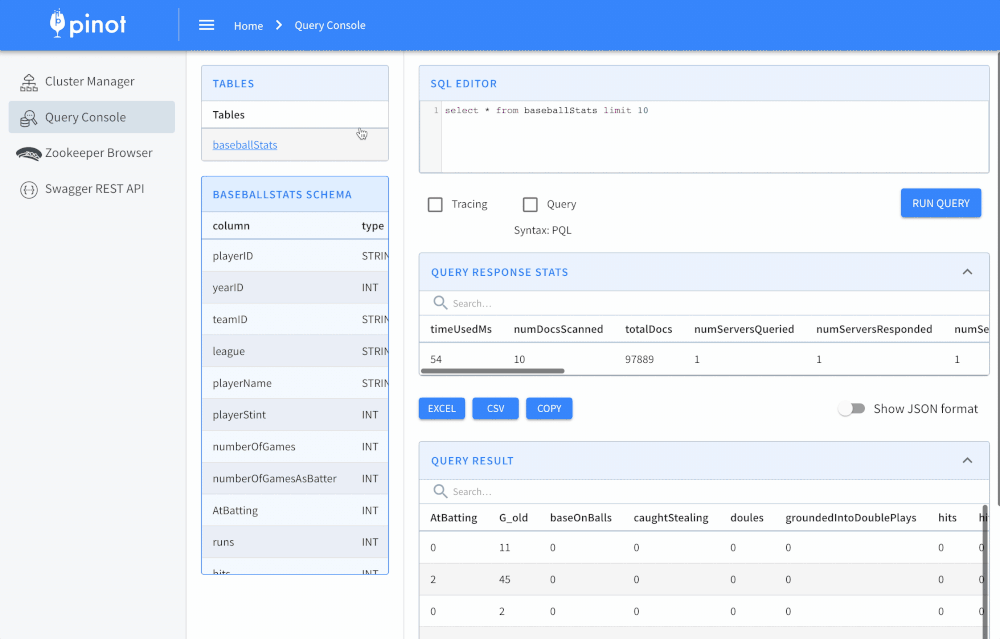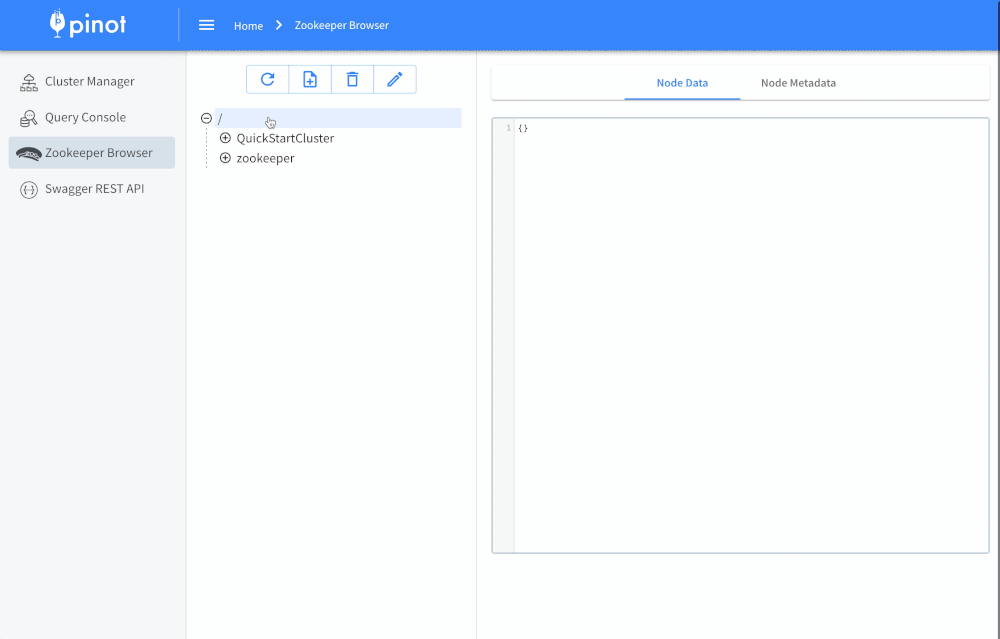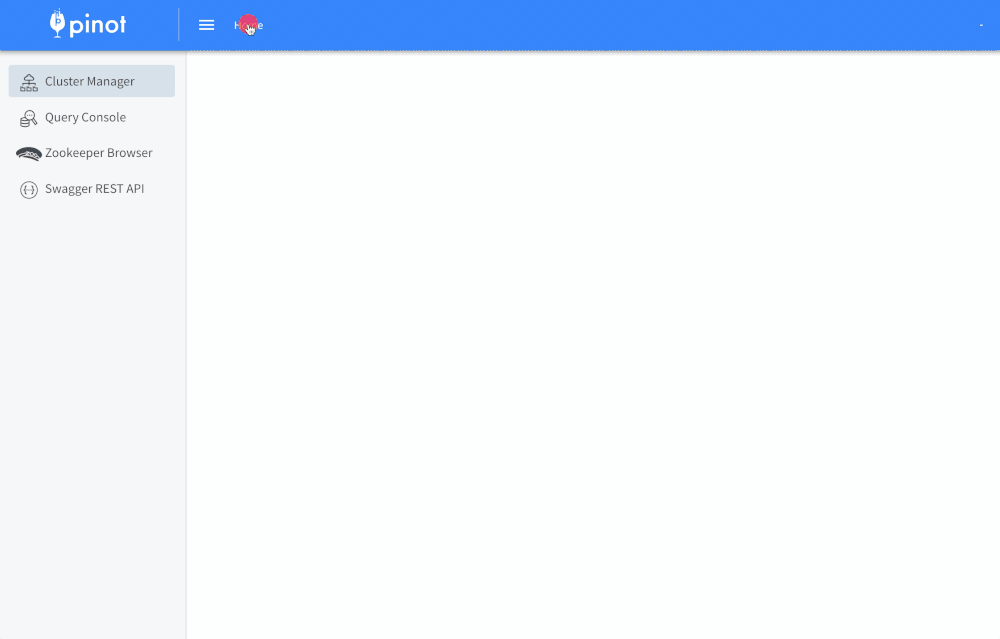
When should I use Pinot?
Pinot is designed to execute real-time OLAP queries with low latency on massive amounts of data and events. In addition to real-time stream ingestion, Pinot also supports batch use cases with the same low latency guarantees. It is suited in contexts where fast analytics, such as aggregations, are needed on immutable data, possibly, with real-time data ingestion. Pinot works very well for querying time series data with lots of dimensions and metrics.
Example query:
SELECT sum(clicks), sum(impressions) FROM AdAnalyticsTable
WHERE
((daysSinceEpoch >= 17849 AND daysSinceEpoch <= 17856)) AND
accountId IN (123456789)
GROUP BY
daysSinceEpoch TOP 100
Contributing to Pinot
Want to contribute to Apache Pinot? ðð·
Want to join the ranks of open source committers to Apache Pinot? Then check out the Contribution Guide for how you can get involved in the code.
If you have a bug or an idea for a new feature, browse the open issues to see what weâre already working on before opening a new one.
We also tagged some beginner issues new contributors can tackle.
Apache Pinot YouTube Channel
Share Your Pinot Videos with the Community!
Have a Pinot use case, tutorial, or conference/meetup recording to share? Weâd love to feature it on the Pinot OSS YouTube channel! Drop your video or a link to your session in the #pinot-youtube-channel on Pinot Slack, and weâll showcase it for the community!
Building Pinot
# Clone a repo
$ git clone https://github.com/apache/pinot.git
$ cd pinot
# Build Pinot
# -Pbin-dist is required to build the binary distribution
# -Pbuild-shaded-jar is required to build the shaded jar, which is necessary for some features like spark connectors
$ ./mvnw clean install -DskipTests -Pbin-dist -Pbuild-shaded-jar
# Run the Quick Demo
$ cd build/
$ bin/quick-start-batch.sh
For UI development setup refer this doc.
Normal Pinot builds are done using the ./mvnw clean install command.
However this command can take a long time to run.
For faster builds it is recommended to use ./mvnw verify -Ppinot-fastdev, which disables some plugins that are not actually needed for development.
More detailed instructions can be found at Quick Demo section in the documentation.
Deploying Pinot to Kubernetes
Please refer to Running Pinot on Kubernetes in our project documentation. Pinot also provides Kubernetes integrations with the interactive query engine, Trino Presto, and the data visualization tool, Apache Superset.
Join the Community
- Ask questions on Apache Pinot Slack
- Please join Apache Pinot mailing lists
dev-subscribe@pinot.apache.org (subscribe to pinot-dev mailing list)
dev@pinot.apache.org (posting to pinot-dev mailing list)
users-subscribe@pinot.apache.org (subscribe to pinot-user mailing list)
users@pinot.apache.org (posting to pinot-user mailing list) - Apache Pinot Meetup Group: https://www.meetup.com/apache-pinot/
Documentation
Check out Pinot documentation for a complete description of Pinot's features.
License
Apache Pinot is under Apache License, Version 2.0
Top Related Projects
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot