
Top Related Projects

An Open-Source Package for Neural Relation Extraction (NRE)

Stanford NLP Python library for tokenization, sentence segmentation, NER, and parsing of many human languages

结巴中文分词

Python library for processing Chinese text

中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理

百度NLP:分词,词性标注,命名实体识别,词重要性
Quick Overview
HarvestText is a Chinese text processing toolkit designed for information extraction and text analysis. It provides a range of functionalities including word segmentation, named entity recognition, sentiment analysis, and text classification. The library is particularly useful for processing Chinese text and extracting structured information from unstructured data.
Pros
- Comprehensive toolkit for Chinese text processing
- Easy-to-use API with intuitive methods
- Supports various NLP tasks such as entity recognition, sentiment analysis, and text classification
- Integrates well with other popular NLP libraries and tools
Cons
- Primarily focused on Chinese language, limiting its use for other languages
- Documentation is mostly in Chinese, which may be challenging for non-Chinese speakers
- Limited community support compared to more established NLP libraries
- May require additional dependencies for certain functionalities
Code Examples
- Basic text processing:
from harvesttext import HarvestText
ht = HarvestText()
text = "我们在北京天安门广场看升旗仪式"
print(ht.seg(text))
This example demonstrates basic word segmentation for a Chinese sentence.
- Named Entity Recognition:
entities = ht.named_entity_recognition(text)
print(entities)
This code performs named entity recognition on the given text.
- Sentiment Analysis:
sentiment = ht.sentiment(text)
print(sentiment)
This example shows how to perform sentiment analysis on the input text.
Getting Started
To get started with HarvestText, follow these steps:
-
Install the library using pip:
pip install harvesttext -
Import the library and create an instance:
from harvesttext import HarvestText ht = HarvestText() -
Process text using various methods:
text = "你好,我来自中国北京" segmented = ht.seg(text) entities = ht.named_entity_recognition(text) sentiment = ht.sentiment(text)
For more advanced usage and additional features, refer to the documentation on the GitHub repository.
Competitor Comparisons
An Open-Source Package for Neural Relation Extraction (NRE)
Pros of OpenNRE
- Focuses specifically on neural relation extraction tasks
- Provides pre-trained models and datasets for quick start
- Supports multiple neural network architectures (CNN, RNN, etc.)
Cons of OpenNRE
- Limited to relation extraction, less versatile for general NLP tasks
- Steeper learning curve for users not familiar with relation extraction
Code Comparison
HarvestText example:
from harvesttext import HarvestText
ht = HarvestText()
text = "今天天气不错,适合出去游玩"
words = ht.seg(text)
print(words)
OpenNRE example:
import opennre
model = opennre.get_model('wiki80_cnn_softmax')
text = 'He was the son of Máel Dúin mac Máele Fithrich, and grandson of the high king Áed Uaridnach (died 612).'
result = model.infer({'text': text, 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})
print(result)
Summary
HarvestText is a general-purpose Chinese NLP toolkit, while OpenNRE specializes in relation extraction tasks. HarvestText offers broader functionality for text processing, while OpenNRE provides deeper capabilities for specific relation extraction use cases. The choice between them depends on the specific NLP requirements of your project.
Stanford NLP Python library for tokenization, sentence segmentation, NER, and parsing of many human languages
Pros of Stanza
- Supports a wide range of languages (over 60) for various NLP tasks
- Provides state-of-the-art performance for many NLP tasks
- Offers a Python interface and seamless integration with PyTorch
Cons of Stanza
- Requires more computational resources due to its comprehensive nature
- Has a steeper learning curve for beginners compared to HarvestText
- Focuses on general NLP tasks rather than specialized text mining features
Code Comparison
Stanza:
import stanza
nlp = stanza.Pipeline('en')
doc = nlp("Hello world!")
print([(word.text, word.lemma, word.pos) for sent in doc.sentences for word in sent.words])
HarvestText:
from harvesttext import HarvestText
ht = HarvestText()
para = "Hello world!"
print(ht.seg(para))
print(ht.pos(para))
Stanza provides more detailed linguistic analysis out-of-the-box, while HarvestText offers simpler, task-specific functions for Chinese text processing. Stanza's code demonstrates its ability to perform multiple NLP tasks in one pipeline, whereas HarvestText shows separate methods for segmentation and part-of-speech tagging.
结巴中文分词
Pros of jieba
- More mature and widely adopted Chinese text segmentation tool
- Faster processing speed for large-scale text segmentation tasks
- Extensive documentation and community support
Cons of jieba
- Limited functionality beyond word segmentation
- Less flexibility in customizing dictionaries and rules
- Fewer advanced features for text analysis and information extraction
Code comparison
jieba:
import jieba
text = "我来到北京清华大学"
words = jieba.cut(text)
print(" ".join(words))
HarvestText:
from harvesttext import HarvestText
ht = HarvestText()
text = "我来到北京清华大学"
words = ht.seg(text)
print(" ".join(words))
Summary
jieba is a well-established Chinese text segmentation tool with excellent performance and widespread adoption. It excels in speed and simplicity for basic word segmentation tasks. HarvestText, on the other hand, offers a more comprehensive suite of text processing tools, including named entity recognition, sentiment analysis, and customizable rules. While jieba may be preferred for large-scale, straightforward segmentation tasks, HarvestText provides greater flexibility and advanced features for more complex text analysis requirements.
Python library for processing Chinese text
Pros of SnowNLP
- Lightweight and easy to use for basic Chinese NLP tasks
- Includes sentiment analysis functionality out of the box
- Supports text summarization
Cons of SnowNLP
- Less actively maintained (last update in 2020)
- Limited documentation and examples
- Fewer advanced features compared to HarvestText
Code Comparison
SnowNLP:
from snownlp import SnowNLP
s = SnowNLP(u'这个东西真心很赞')
print(s.sentiments) # Sentiment analysis
print(s.keywords(3)) # Extract keywords
HarvestText:
from harvesttext import HarvestText
ht = HarvestText()
text = "这个东西真心很赞"
print(ht.sentiment.classify(text)) # Sentiment analysis
print(ht.extract_keywords(text, 3)) # Extract keywords
Both libraries offer similar basic functionality for Chinese text processing, but HarvestText provides more advanced features and is more actively maintained. SnowNLP is simpler to use for basic tasks, while HarvestText offers greater flexibility and customization options for more complex NLP tasks in Chinese.
中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发�现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理
Pros of HanLP
- More comprehensive NLP toolkit with a wider range of features
- Better performance and efficiency for large-scale text processing
- Stronger community support and more frequent updates
Cons of HanLP
- Steeper learning curve due to its complexity
- Requires more system resources for installation and operation
- Less focused on specific text harvesting tasks
Code Comparison
HanLP:
from pyhanlp import *
text = "我爱北京天安门"
print(HanLP.segment(text))
HarvestText:
from harvesttext import HarvestText
ht = HarvestText()
print(ht.seg(text))
Both libraries offer Chinese text segmentation, but HanLP provides a more comprehensive set of NLP tools, while HarvestText focuses on specific text harvesting tasks. HanLP's code is generally more concise, but may require more setup. HarvestText offers a simpler API for basic text processing tasks, making it easier to use for beginners or specific harvesting needs.
百度NLP:分词,词性标注,命名实体识别,词重要性
Pros of LAC
- More comprehensive NLP toolkit with advanced features like named entity recognition and part-of-speech tagging
- Better performance and efficiency, especially for large-scale text processing tasks
- Stronger support for Chinese language processing
Cons of LAC
- Less user-friendly for beginners, with a steeper learning curve
- More complex setup and installation process
- Limited flexibility for customization compared to HarvestText
Code Comparison
HarvestText:
from harvesttext import HarvestText
ht = HarvestText()
text = "今天天气真好,适合出去玩。"
words = ht.seg(text)
print(words)
LAC:
from LAC import LAC
lac = LAC(mode='seg')
text = "今天天气真好,适合出去玩。"
words = lac.run(text)
print(words)
Both libraries offer similar basic functionality for text segmentation, but LAC provides more advanced features and is generally more suitable for large-scale or professional NLP tasks. HarvestText, on the other hand, is more user-friendly and easier to customize, making it a good choice for smaller projects or beginners in NLP.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
# HarvestText
HarvestText : A Toolkit for Text Mining and Preprocessing

![]()

![]()
![]()
å¨Githubåç äºGiteeä¸åæ¥ãå¦æå¨Githubä¸æµè§/ä¸è½½éåº¦æ ¢çè¯å¯ä»¥è½¬å°ç äºä¸æä½ã
ç¨é
HarvestTextæ¯ä¸ä¸ªä¸æ³¨æ ï¼å¼±ï¼çç£æ¹æ³ï¼è½å¤æ´åé¢åç¥è¯ï¼å¦ç±»åï¼å«åï¼å¯¹ç¹å®é¢åææ¬è¿è¡ç®åé«æå°å¤çååæçåºãéç¨äºè®¸å¤ææ¬é¢å¤çååæ¥æ¢ç´¢æ§åæä»»å¡ï¼å¨å°è¯´åæï¼ç½ç»ææ¬ï¼ä¸ä¸æç®çé¢åé½ææ½å¨åºç¨ä»·å¼ã
使ç¨æ¡ä¾:
- åæãä¸å½æ¼ä¹ãä¸ç社交ç½ç»ï¼å®ä½åè¯ï¼ææ¬æè¦ï¼å
³ç³»ç½ç»çï¼
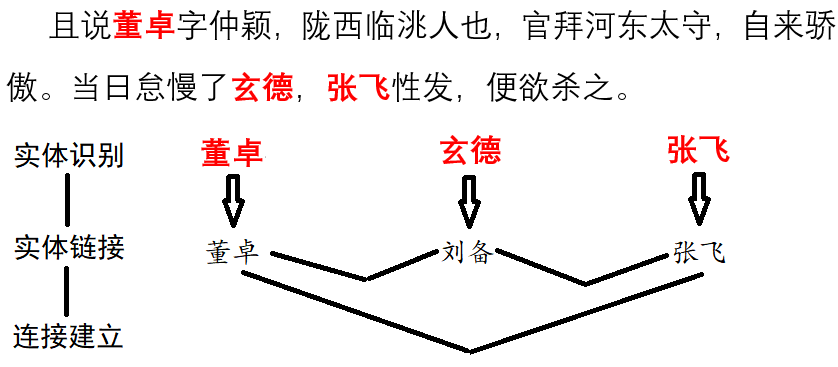
- 2018ä¸è¶
èæ
å±ç¤ºç³»ç»ï¼å®ä½åè¯ï¼æ
æåæï¼æ°è¯åç°[è¾
å©ç»°å·è¯å«]çï¼
ç¸å
³æç« ï¼ä¸æçè¯è®ºéçä¸è¶
é£äº
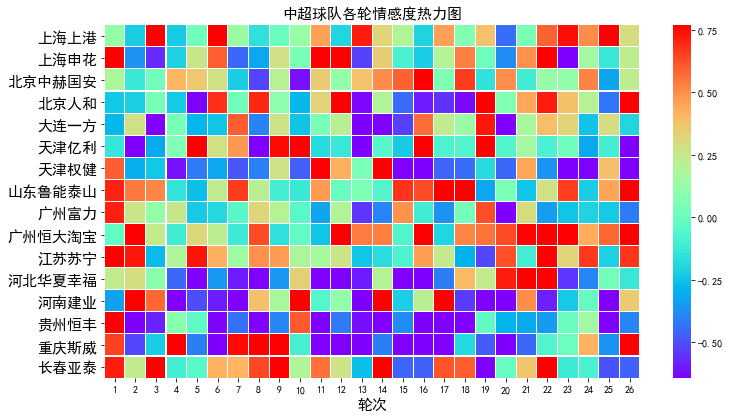
ã注ï¼æ¬åºä» å®æå®ä½åè¯åæ æåæï¼å¯è§å使ç¨matplotlibã
- è¿ä»£å²çº²è¦ä¿¡æ¯æ½ååé®çç³»ç»(å½åå®ä½è¯å«ï¼ä¾åå¥æ³åæï¼ç®æé®çç³»ç»)
æ¬READMEå å«å个åè½çå ¸åä¾åï¼é¨åå½æ°ç详ç»ç¨æ³å¯å¨ææ¡£ä¸æ¾å°ï¼
å ·ä½åè½å¦ä¸ï¼
-
åºæ¬å¤ç
- ç²¾ç»åè¯åå¥
- å¯å å«æå®è¯åç±»å«çåè¯ãå åèèçç¥å·ï¼åå¼å·çç¹æ®æ ç¹çåå¥ã
- ææ¬æ¸
æ´
- å¤çURL, email, å¾®åçææ¬ä¸çç¹æ®ç¬¦å·åæ ¼å¼ï¼å»é¤æææ ç¹ç
- å®ä½é¾æ¥
- æå«åï¼ç¼©åä¸ä»ä»¬çæ ååè系起æ¥ã
- å½åå®ä½è¯å«
- æ¾å°ä¸å¥å¥åä¸ç人åï¼å°åï¼æºæåçå½åå®ä½ã
- å®ä½å«åèªå¨è¯å«(æ´æ°ï¼)
- ä»å¤§éææ¬ä¸èªå¨è¯å«åºå®ä½åå ¶å¯è½å«åï¼ç´æ¥ç¨äºå®ä½é¾æ¥ãä¾åè§è¿é
- ä¾åå¥æ³åæ
- åæè¯å¥ä¸å个è¯è¯ï¼å æ¬é¾æ¥å°çå®ä½ï¼ç主è°å®¾è¯ä¿®é¥°çè¯æ³å ³ç³»ï¼
- å
ç½®èµæº
- éç¨åç¨è¯ï¼éç¨æ æè¯ï¼ITãè´¢ç»ã饮é£ãæ³å¾çé¢åè¯å ¸ãå¯ç´æ¥ç¨äºä»¥ä¸ä»»å¡ã
- ä¿¡æ¯æ£ç´¢
- ç»è®¡ç¹å®å®ä½åºç°çä½ç½®ï¼æ¬¡æ°çã
- æ°è¯åç°
- å©ç¨ç»è®¡è§å¾ï¼æè§åï¼åç°è¯æä¸å¯è½ä¼è¢«ä¼ ç»åè¯éæ¼çç¹æ®è¯æ±ãä¹ä¾¿äºä»ææ¬ä¸å¿«éçéåºå ³é®è¯ã
- å符æ¼é³çº é(è°æ´)
- æè¯å¥ä¸æå¯è½æ¯å·²ç¥å®ä½çé误æ¼åï¼è¯¯å·®ä¸ä¸ªå符ææ¼é³ï¼çè¯è¯é¾æ¥å°å¯¹åºå®ä½ã
- èªå¨å段
- 使ç¨TextTilingç®æ³ï¼å¯¹æ²¡æå段çææ¬èªå¨å段ï¼æè åºäºå·²æ段è½è¿ä¸æ¥ç»ç»/éæ°å段
- ååæ¶é¤
- å¯ä»¥æ¬å°ä¿å模åå读åå¤ç¨ï¼ä¹å¯ä»¥æ¶é¤å½å模åçè®°å½ã
- è±è¯æ¯æ
- æ¬åºä¸»è¦æ¨å¨æ¯æ对ä¸æçæ°æ®ææï¼ä½æ¯å å ¥äºå æ¬æ æåæå¨å çå°éè±è¯æ¯æ
- ç²¾ç»åè¯åå¥
-
é«å±åºç¨
- æ
æåæ
- ç»åºå°éç§åè¯ï¼éç¨çè¤è´¬ä¹è¯è¯ï¼ï¼å¾å°è¯æä¸å个è¯è¯åè¯æ®µçè¤è´¬åº¦ã
- å
³ç³»ç½ç»
- å©ç¨å ±ç°å ³ç³»ï¼è·å¾å ³é®è¯ä¹é´çç½ç»ãæè 以ä¸ä¸ªç»å®è¯è¯ä¸ºä¸å¿ï¼æ¢ç´¢ä¸å ¶ç¸å ³çè¯è¯ç½ç»ã
- ææ¬æè¦
- åºäºTextrankç®æ³ï¼å¾å°ä¸ç³»åå¥åä¸ç代表æ§å¥åã
- å
³é®è¯æ½å
- åºäºTextrank, tfidfçç®æ³ï¼è·å¾ä¸æ®µææ¬ä¸çå ³é®è¯
- äºå®æ½å
- å©ç¨å¥æ³åæï¼æåå¯è½è¡¨ç¤ºäºä»¶çä¸å ç»ã
- ç®æé®çç³»ç»
- ä»ä¸å ç»ä¸å»ºç«ç¥è¯å¾è°±å¹¶åºç¨äºé®çï¼å¯ä»¥å®å¶ä¸äºé®é¢æ¨¡æ¿ãæææå¾ æåï¼ä» ä½ä¸ºç¤ºä¾ã
- æ
æåæ
ç¨æ³
é¦å å®è£ ï¼ ä½¿ç¨pip
pip install --upgrade harvesttext
æè¿å ¥setup.pyæå¨ç®å½ï¼ç¶åå½ä»¤è¡:
python setup.py install
éåå¨ä»£ç ä¸ï¼
from harvesttext import HarvestText
ht = HarvestText()
å³å¯è°ç¨æ¬åºçåè½æ¥å£ã
注æï¼é¨ååè½éè¦å®è£ é¢å¤çåºï¼ä½æä¸å®å¯è½å®è£ 失败ï¼æ éè¦çè¯è¯·æå¨å®è£
# é¨åè±è¯åè½
pip install pattern
# å½åå®ä½è¯å«ãå¥æ³åæçåè½ï¼éè¦python <= 3.8
pip install pyhanlp
å®ä½é¾æ¥
ç»å®æäºå®ä½åå ¶å¯è½ç代称ï¼ä»¥åå®ä½å¯¹åºç±»åãå°å ¶ç»å½å°è¯å ¸ä¸ï¼å¨åè¯æ¶ä¼å åååºæ¥ï¼å¹¶ä¸ä»¥å¯¹åºç±»åä½ä¸ºè¯æ§ãä¹å¯ä»¥åç¬è·å¾è¯æä¸çææå®ä½åå ¶ä½ç½®ï¼
para = "ä¸æ¸¯çæ¦ç£åæ大çéæï¼è°æ¯ä¸å½æ好çåéï¼é£å½ç¶æ¯æ¦ç£æ¦ççäºï¼ä»æ¯å°ææ¦ç¬¬ä¸ï¼åæ¥æ¯å¼±ç¹çååä¹æäºè¿æ¥"
entity_mention_dict = {'æ¦ç£':['æ¦ç£','æ¦çç'],'éæ':['éæ','éé£æº'],'åé':['åé'],'ä¸æµ·ä¸æ¸¯':['ä¸æ¸¯'],'广å·æ大':['æ大'],'ååç':['åå']}
entity_type_dict = {'æ¦ç£':'çå','éæ':'çå','åé':'ä½ç½®','ä¸æµ·ä¸æ¸¯':'çé','广å·æ大':'çé','ååç':'æ¯è¯'}
ht.add_entities(entity_mention_dict,entity_type_dict)
print("\nSentence segmentation")
print(ht.seg(para,return_sent=True)) # return_sent=Falseæ¶ï¼åè¿åè¯è¯å表
ä¸æ¸¯ ç æ¦ç£ å æ大 ç éæ ï¼ è° æ¯ ä¸å½ æ好 ç åé ï¼ é£ å½ç¶ æ¯ æ¦ç£ æ¦çç äºï¼ ä» æ¯ å°ææ¦ ç¬¬ä¸ ï¼ åæ¥ æ¯ å¼±ç¹ ç åå ä¹ æ äº è¿æ¥
éç¨ä¼ ç»çåè¯å·¥å ·å¾å®¹ææâæ¦ççâæå为âæ¦ ççâ
è¯æ§æ 注ï¼å æ¬æå®çç¹æ®ç±»åã
print("\nPOS tagging with entity types")
for word, flag in ht.posseg(para):
print("%s:%s" % (word, flag),end = " ")
ä¸æ¸¯:çé ç:uj æ¦ç£:çå å:c æ大:çé ç:uj éæ:çå ï¼:x è°:r æ¯:v ä¸å½:ns æ好:a ç:uj åé:ä½ç½® ï¼:x é£:r å½ç¶:d æ¯:v æ¦ç£:çå æ¦çç:çå äº:ul ï¼:x ä»:r æ¯:v å°ææ¦:n 第ä¸:m ï¼:x åæ¥:d æ¯:v å¼±ç¹:n ç:uj åå:æ¯è¯ ä¹:d æ:v äº:ul è¿æ¥:d
for span, entity in ht.entity_linking(para):
print(span, entity)
[0, 2] ('ä¸æµ·ä¸æ¸¯', '#çé#') [3, 5] ('æ¦ç£', '#çå#') [6, 8] ('广å·æ大', '#çé#') [9, 11] ('éæ', '#çå#') [19, 21] ('åé', '#ä½ç½®#') [26, 28] ('æ¦ç£', '#çå#') [28, 31] ('æ¦ç£', '#çå#') [47, 49] ('ååç', '#æ¯è¯#')
è¿éæâæ¦ççâ转å为äºæ åæ称âæ¦ç£âï¼å¯ä»¥ä¾¿äºæ åç»ä¸çç»è®¡å·¥ä½ã
åå¥ï¼
print(ht.cut_sentences(para))
['ä¸æ¸¯çæ¦ç£åæ大çéæï¼è°æ¯ä¸å½æ好çåéï¼', 'é£å½ç¶æ¯æ¦ç£æ¦ççäºï¼ä»æ¯å°ææ¦ç¬¬ä¸ï¼åæ¥æ¯å¼±ç¹çååä¹æäºè¿æ¥']
å¦ææ头ææ¶æ²¡æå¯ç¨çè¯å ¸ï¼ä¸å¦¨ççæ¬åºå ç½®èµæºä¸çé¢åè¯å ¸æ¯å¦éåä½ çéè¦ã
å¦æåä¸ä¸ªååæå¤ä¸ªå¯è½å¯¹åºçå®ä½ï¼"æççæå¨åå±æçæå¨ä¸æ¯ä¸ä¸ªäºº"ï¼ï¼å¯ä»¥è®¾ç½®keep_all=Trueæ¥ä¿çå¤ä¸ªåéï¼åé¢å¯ä»¥åéç¨å«ççç¥æ¶æ§ï¼è§el_keep_all()
å¦æè¿æ¥å°çå®ä½è¿å¤ï¼å ¶ä¸æä¸äºææ¾ä¸åçï¼å¯ä»¥éç¨ä¸äºçç¥æ¥è¿æ»¤ï¼è¿éç»åºäºä¸ä¸ªä¾åfilter_el_with_rule()
æ¬åºè½å¤ä¹ç¨ä¸äºåºæ¬çç¥æ¥å¤çå¤æçå®ä½æ¶æ§ä»»å¡ï¼æ¯å¦ä¸è¯å¤ä¹ã"èå¸"æ¯æ"Aèå¸"è¿æ¯"Bèå¸"ï¼ããåéè¯éå ãxxå¸é¿/æ±yyï¼ãxxå¸é¿/æ±yyï¼ãï¼ã å ·ä½å¯è§linking_strategy()
ææ¬æ¸ æ´
å¯ä»¥å¤çææ¬ä¸çç¹æ®å符ï¼æè å»æææ¬ä¸ä¸å¸æåºç°çä¸äºç¹æ®æ ¼å¼ã
å æ¬ï¼å¾®åç@ï¼è¡¨æ 符ï¼ç½åï¼emailï¼html代ç ä¸ç ä¸ç±»çç¹æ®å符ï¼ç½åå ç%20ä¸ç±»çç¹æ®å符ï¼ç¹ä½å转ç®ä½å
ä¾åå¦ä¸ï¼
print("åç§æ¸
æ´ææ¬")
ht0 = HarvestText()
# é»è®¤ç设置å¯ç¨äºæ¸
æ´å¾®åææ¬
text1 = "åå¤@é±ææQXM:[å»å»][å»å»] //@é±ææQXM:æ¨å¤§å¥[good][good]"
print("æ¸
æ´å¾®åã@å表æ
符çã")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1))
åç§æ¸
æ´ææ¬
æ¸
æ´å¾®åã@å表æ
符çã
åï¼ åå¤@é±ææQXM:[å»å»][å»å»] //@é±ææQXM:æ¨å¤§å¥[good][good]
æ¸
æ´åï¼ æ¨å¤§å¥
# URLçæ¸
ç
text1 = "ã#èµµè#ï¼æ£ç¹å¤ä¸ä¸é¨çµå½± ä½ä¸æ¯éæ¥ç....http://t.cn/8FLopdQ"
print("æ¸
æ´ç½åURL")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, remove_url=True))
æ¸
æ´ç½åURL
åï¼ ã#èµµè#ï¼æ£ç¹å¤ä¸ä¸é¨çµå½± ä½ä¸æ¯éæ¥ç....http://t.cn/8FLopdQ
æ¸
æ´åï¼ ã#èµµè#ï¼æ£ç¹å¤ä¸ä¸é¨çµå½± ä½ä¸æ¯éæ¥ç....
# æ¸
æ´é®ç®±
text1 = "æçé®ç®±æ¯abc@demo.comï¼æ¬¢è¿èç³»"
print("æ¸
æ´é®ç®±")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, email=True))
æ¸
æ´é®ç®±
åï¼ æçé®ç®±æ¯abc@demo.comï¼æ¬¢è¿èç³»
æ¸
æ´åï¼ æçé®ç®±æ¯ï¼æ¬¢è¿èç³»
# å¤çURL转ä¹å符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL转æ£å¸¸å符")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, norm_url=True, remove_url=False))
URL转æ£å¸¸å符
åï¼ www.%E4%B8%AD%E6%96%87%20and%20space.com
æ¸
æ´åï¼ www.ä¸æ and space.com
text1 = "www.ä¸æ and space.com"
print("æ£å¸¸å符转URL[å«æä¸æåç©ºæ ¼çrequestéè¦æ³¨æ]")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, to_url=True, remove_url=False))
æ£å¸¸å符转URL[å«æä¸æåç©ºæ ¼çrequestéè¦æ³¨æ]
åï¼ www.ä¸æ and space.com
æ¸
æ´åï¼ www.%E4%B8%AD%E6%96%87%20and%20space.com
# å¤çHTML转ä¹å符
text1 = "<a c> ''"
print("HTML转æ£å¸¸å符")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, norm_html=True))
HTML转æ£å¸¸å符
åï¼ <a c> ''
æ¸
æ´åï¼ <a c> ''
# ç¹ä½å转ç®ä½
text1 = "å¿ç¢èª°è²·å®"
print("ç¹ä½å转ç®ä½")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, t2s=True))
ç¹ä½å转ç®ä½
åï¼ å¿ç¢èª°è²·å®
æ¸
æ´åï¼ å¿ç¢è°ä¹°å
# markdownè¶
é¾æ¥æåææ¬
text1 = "欢è¿ä½¿ç¨[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)è¿ä¸ªåº"
print("markdownè¶
é¾æ¥æåææ¬")
print("åï¼", text1)
print("æ¸
æ´åï¼", ht0.clean_text(text1, t2s=True))
markdownè¶
é¾æ¥æåææ¬
åï¼ æ¬¢è¿ä½¿ç¨[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)è¿ä¸ªåº
æ¸
æ´åï¼ æ¬¢è¿ä½¿ç¨HarvestText : A Toolkit for Text Mining and Preprocessingè¿ä¸ªåº
å½åå®ä½è¯å«
æ¾å°ä¸å¥å¥åä¸ç人åï¼å°åï¼æºæåçå½åå®ä½ã使ç¨äº pyhanLP çæ¥å£å®ç°ã
ht0 = HarvestText()
sent = "ä¸æµ·ä¸æ¸¯è¶³çéçæ¦ç£æ¯ä¸å½æ好çåéã"
print(ht0.named_entity_recognition(sent))
{'ä¸æµ·ä¸æ¸¯è¶³çé': 'æºæå', 'æ¦ç£': '人å', 'ä¸å½': 'å°å'}
ä¾åå¥æ³åæ
åæè¯å¥ä¸å个è¯è¯ï¼å æ¬é¾æ¥å°çå®ä½ï¼ç主è°å®¾è¯ä¿®é¥°çè¯æ³å ³ç³»ï¼å¹¶ä»¥æ¤æåå¯è½çäºä»¶ä¸å ç»ã使ç¨äº pyhanLP çæ¥å£å®ç°ã
ht0 = HarvestText()
para = "ä¸æ¸¯çæ¦ç£æ¦ççæ¯ä¸å½æ好çåéã"
entity_mention_dict = {'æ¦ç£': ['æ¦ç£', 'æ¦çç'], "ä¸æµ·ä¸æ¸¯":["ä¸æ¸¯"]}
entity_type_dict = {'æ¦ç£': 'çå', "ä¸æµ·ä¸æ¸¯":"çé"}
ht0.add_entities(entity_mention_dict, entity_type_dict)
for arc in ht0.dependency_parse(para):
print(arc)
print(ht0.triple_extraction(para))
[0, 'ä¸æ¸¯', 'çé', 'å®ä¸å
³ç³»', 3]
[1, 'ç', 'u', 'å³éå å
³ç³»', 0]
[2, 'æ¦ç£', 'çå', 'å®ä¸å
³ç³»', 3]
[3, 'æ¦çç', 'çå', '主è°å
³ç³»', 4]
[4, 'æ¯', 'v', 'æ ¸å¿å
³ç³»', -1]
[5, 'ä¸å½', 'ns', 'å®ä¸å
³ç³»', 8]
[6, 'æ好', 'd', 'å®ä¸å
³ç³»', 8]
[7, 'ç', 'u', 'å³éå å
³ç³»', 6]
[8, 'åé', 'n', 'å¨å®¾å
³ç³»', 4]
[9, 'ã', 'w', 'æ ç¹ç¬¦å·', 4]
print(ht0.triple_extraction(para))
[['ä¸æ¸¯æ¦ç£æ¦çç', 'æ¯', 'ä¸å½æ好åé']]
å符æ¼é³çº é
å¨V0.7çä¿®æ¹ï¼ä½¿ç¨toleranceæ¯ææ¼é³ç¸åçæ£æ¥
æè¯å¥ä¸æå¯è½æ¯å·²ç¥å®ä½çé误æ¼åï¼è¯¯å·®ä¸ä¸ªå符ææ¼é³ï¼çè¯è¯é¾æ¥å°å¯¹åºå®ä½ã
def entity_error_check():
ht0 = HarvestText()
typed_words = {"人å":["æ¦ç£"]}
ht0.add_typed_words(typed_words)
sent0 = "æ¦ç£åå´ç£æ¼é³ç¸å"
print(sent0)
print(ht0.entity_linking(sent0, pinyin_tolerance=0))
"""
æ¦ç£åå´ç£æ¼é³ç¸å
[([0, 2], ('æ¦ç£', '#人å#')), [(3, 5), ('æ¦ç£', '#人å#')]]
"""
sent1 = "æ¦ç£åå´ååªå·®ä¸ä¸ªæ¼é³"
print(sent1)
print(ht0.entity_linking(sent1, pinyin_tolerance=1))
"""
æ¦ç£åå´ååªå·®ä¸ä¸ªæ¼é³
[([0, 2], ('æ¦ç£', '#人å#')), [(3, 5), ('æ¦ç£', '#人å#')]]
"""
sent2 = "æ¦ç£åå´ç£åªå·®ä¸ä¸ªå"
print(sent2)
print(ht0.entity_linking(sent2, char_tolerance=1))
"""
æ¦ç£åå´ç£åªå·®ä¸ä¸ªå
[([0, 2], ('æ¦ç£', '#人å#')), [(3, 5), ('æ¦ç£', '#人å#')]]
"""
sent3 = "å´ç£åå´åé½å¯è½æ¯æ¦ç£ç代称"
print(sent3)
print(ht0.get_linking_mention_candidates(sent3, pinyin_tolerance=1, char_tolerance=1))
"""
å´ç£åå´åé½å¯è½æ¯æ¦ç£ç代称
('å´ç£åå´åé½å¯è½æ¯æ¦ç£ç代称', defaultdict(<class 'list'>, {(0, 2): {'æ¦ç£'}, (3, 5): {'æ¦ç£'}}))
"""
æ æåæ
æ¬åºéç¨æ æè¯å ¸æ¹æ³è¿è¡æ æåæï¼éè¿æä¾å°éæ åçè¤è´¬ä¹è¯è¯ï¼âç§åè¯âï¼ï¼ä»è¯æä¸èªå¨å¦ä¹ å ¶ä»è¯è¯çæ æå¾åï¼å½¢ææ æè¯å ¸ã对å¥ä¸æ æè¯çå æ»å¹³ååç¨äºå¤æå¥åçæ æå¾åï¼
print("\nsentiment dictionary")
sents = ["æ¦ç£å¨æ¦ï¼ä¸è¶
第ä¸å°æï¼",
"æ¦ç£å¼ºï¼ä¸è¶
æ第ä¸æ¬åçåï¼",
"éæä¸è¡ï¼åªä¼æ±æ¨ççå注å®ä¸éäº",
"éæçæ¥ä¸è¡ï¼å·²ç»å°ä¸éäº"]
sent_dict = ht.build_sent_dict(sents,min_times=1,pos_seeds=["第ä¸"],neg_seeds=["ä¸è¡"])
print("%s:%f" % ("å¨æ¦",sent_dict["å¨æ¦"]))
print("%s:%f" % ("çå",sent_dict["çå"]))
print("%s:%f" % ("ä¸é",sent_dict["ä¸é"]))
sentiment dictionary å¨æ¦:1.000000 çå:0.000000 ä¸é:-1.000000
print("\nsentence sentiment")
sent = "æ¦ççå¨æ¦ï¼ä¸è¶
æ强çåï¼"
print("%f:%s" % (ht.analyse_sent(sent),sent))
0.600000:æ¦ççå¨æ¦ï¼ä¸è¶ æ强çåï¼
å¦æ没æ³å¥½éæ©åªäºè¯è¯ä½ä¸ºâç§åè¯âï¼æ¬åºä¸ä¹å ç½®äºä¸ä¸ªéç¨æ æè¯å ¸å ç½®èµæºï¼å¨ä¸æå®æ æè¯æ¶ä½ä¸ºé»è®¤çéæ©ï¼ä¹å¯ä»¥æ ¹æ®éè¦ä»ä¸æéã
é»è®¤ä½¿ç¨çSO-PMIç®æ³å¯¹äºæ æå¼æ²¡æä¸ä¸ç约æï¼å¦æéè¦éå¶å¨[0,1]æè [-1,1]è¿æ ·çåºé´çè¯ï¼å¯ä»¥è°æ´scaleåæ°ï¼ä¾åå¦ä¸ï¼
print("\nsentiment dictionary using default seed words")
docs = ["å¼ å¸ç¹è®¾å
´åå®ä¸å
¬å¸å¤åºèµæ¬å®¶è¸è·æèµæå¯åè¾¹åºå
´åå®ä¸å
¬å¸ï¼èªç¹å¤æç«ä»¥æ¥ï¼è§£æ¾åºå
å¤ä¼ä¸ç人士åä¸è¬åæ°ï¼åè¸è·è®¤è¡æèµ",
"æåä¸æ¶çèµæ¬å®¶",
"该å
¬å¸åå®èµæ¬æ»é¢ä¸ºäºåäºä¸ä¸å
ï¼ç°å·²ç±åçå认达äºåä¸ä¸å
ï¼æå±ååãåå
¬å¸äº¦åå¾è¡éä¸ä¸ä¸ä½å
",
"è¿æ¥æ¥è§£æ¾åºä»¥å¤åå·¥å人士ï¼æå½å该å
¬å¸è¯¢é®ç»è¥æ§è´¨ä¸èå´ä»¥åè¡ä¸æéçé®é¢è
çå¤ï¼ç»ç»æµæ¤ç许å¤èµæ¬å®¶ï¼äºåè§è¯¥å
¬å¸æå±ååç»è¥ç¶åµåï¼å¯¹æ°ä¸»æ¿åºæ¶å©ä¸å¥å±ç§è¥ä¼ä¸åå±çæ¿çï¼åæ表èµåï¼æäºèµæ¬å®¶å 款项æªè½å³å»æ±æ¥ï¼å¤åç¹å¤å¤é¢è®¤æèµçé¢æ°ãç±å¹³æ´¥æ¥å¼ çæææ£å
çï¼ä¸æ¬¡å³ä»¥ç°æ¬¾å
¥è¡å
åä½ä¸å
"
]
# scale: å°ææè¯è¯çæ
æå¼èå´è°æ´å°[-1,1]
# çç¥pos_seeds, neg_seeds,å°éç¨é»è®¤çæ
æè¯å
¸ get_qh_sent_dict()
print("scale=\"0-1\", æç
§æ大为1ï¼æå°ä¸º0è¿è¡çº¿æ§ä¼¸ç¼©ï¼0.5æªå¿
æ¯ä¸æ§")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="0-1")
print("%s:%f" % ("èµå",sent_dict["èµå"]))
print("%s:%f" % ("äºåä¸",sent_dict["äºåä¸"]))
print("%s:%f" % ("ä¸æ¶",sent_dict["ä¸æ¶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
sentiment dictionary using default seed words
scale="0-1", æç
§æ大为1ï¼æå°ä¸º0è¿è¡çº¿æ§ä¼¸ç¼©ï¼0.5æªå¿
æ¯ä¸æ§
èµå:1.000000
äºåä¸:0.153846
ä¸æ¶:0.000000
0.449412:å¼ å¸ç¹è®¾å
´åå®ä¸å
¬å¸å¤åºèµæ¬å®¶è¸è·æèµæå¯åè¾¹åºå
´åå®ä¸å
¬å¸ï¼èªç¹å¤æç«ä»¥æ¥ï¼è§£æ¾åºå
å¤ä¼ä¸ç人士åä¸è¬åæ°ï¼åè¸è·è®¤è¡æèµ
0.364910:æåä¸æ¶çèµæ¬å®¶
print("scale=\"+-1\", å¨æ£è´åºé´å
åå«ä¼¸ç¼©ï¼ä¿ç0ä½ä¸ºä¸æ§çè¯ä¹")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("èµå",sent_dict["èµå"]))
print("%s:%f" % ("äºåä¸",sent_dict["äºåä¸"]))
print("%s:%f" % ("ä¸æ¶",sent_dict["ä¸æ¶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", å¨æ£è´åºé´å
åå«ä¼¸ç¼©ï¼ä¿ç0ä½ä¸ºä¸æ§çè¯ä¹
èµå:1.000000
äºåä¸:0.000000
ä¸æ¶:-1.000000
0.349305:å¼ å¸ç¹è®¾å
´åå®ä¸å
¬å¸å¤åºèµæ¬å®¶è¸è·æèµæå¯åè¾¹åºå
´åå®ä¸å
¬å¸ï¼èªç¹å¤æç«ä»¥æ¥ï¼è§£æ¾åºå
å¤ä¼ä¸ç人士åä¸è¬åæ°ï¼åè¸è·è®¤è¡æèµ
-0.159652:æåä¸æ¶çèµæ¬å®¶
ä¿¡æ¯æ£ç´¢
å¯ä»¥ä»ææ¡£å表ä¸æ¥æ¾åºå å«å¯¹åºå®ä½ï¼åå ¶å«ç§°ï¼çææ¡£ï¼ä»¥åç»è®¡å å«æå®ä½çææ¡£æ°ã使ç¨åæç´¢å¼çæ°æ®ç»æå®æå¿«éæ£ç´¢ã
以ä¸ä»£ç 为çç¥äºæ·»å å®ä½è¿ç¨çèéï¼è¯·å 使ç¨add_entitiesçå½æ°æ·»å å¸æå ³æ³¨çå®ä½ï¼åè¿è¡ç´¢å¼åæ£ç´¢ã
docs = ["æ¦ç£å¨æ¦ï¼ä¸è¶
第ä¸å°æï¼",
"éæçæ¥ä¸è¡ï¼å·²ç»å°ä¸éäºã",
"æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼",
"æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼"]
inv_index = ht.build_index(docs)
print(ht.get_entity_counts(docs, inv_index)) # è·å¾ææ¡£ä¸ææå®ä½çåºç°æ¬¡æ°
# {'æ¦ç£': 3, 'éæ': 2, 'åé': 2}
print(ht.search_entity("æ¦ç£", docs, inv_index)) # åå®ä½æ¥æ¾
# ['æ¦ç£å¨æ¦ï¼ä¸è¶
第ä¸å°æï¼', 'æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼', 'æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼']
print(ht.search_entity("æ¦ç£ éæ", docs, inv_index)) # å¤å®ä½å
±ç°
# ['æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼']
# è°æ¯æ被人们çè®®çåéï¼ç¨è¿éçæ¥å£å¯ä»¥å¾ç®ä¾¿å°åçè¿ä¸ªé®é¢
subdocs = ht.search_entity("#çå# åé", docs, inv_index)
print(subdocs) # å®ä½ãå®ä½ç±»åæ··åæ¥æ¾
# ['æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼', 'æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼']
inv_index2 = ht.build_index(subdocs)
print(ht.get_entity_counts(subdocs, inv_index2, used_type=["çå"])) # å¯ä»¥éå®ç±»å
# {'æ¦ç£': 2, 'éæ': 1}
å ³ç³»ç½ç»
(使ç¨networkxå®ç°) å©ç¨è¯å ±ç°å ³ç³»ï¼å»ºç«å ¶å®ä½é´å¾ç»æçç½ç»å ³ç³»(è¿ånetworkx.Graphç±»å)ãå¯ä»¥ç¨æ¥å»ºç«äººç©ä¹é´ç社交ç½ç»çã
# å¨ç°æå®ä½åºçåºç¡ä¸éæ¶æ°å¢ï¼æ¯å¦ä»æ°è¯åç°ä¸å¾å°çæ¼ç½ä¹é±¼
ht.add_new_entity("é¢éªå", "é¢éªå", "çå")
docs = ["æ¦ç£åé¢éªåæ¯éå",
"æ¦ç£åéæé½æ¯å½å
顶å°åé"]
G = ht.build_entity_graph(docs)
print(dict(G.edges.items()))
G = ht.build_entity_graph(docs, used_types=["çå"])
print(dict(G.edges.items()))
è·å¾ä»¥ä¸ä¸ªè¯è¯ä¸ºä¸å¿çè¯è¯ç½ç»ï¼ä¸é¢ä»¥ä¸å½ç¬¬ä¸ç« 为ä¾ï¼æ¢ç´¢ä¸»äººå ¬åå¤çééï¼ä¸ä¸ºä¸»è¦ä»£ç ï¼ä¾åè§build_word_ego_graph()ï¼ã
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
ht0.add_entities(entity_mention_dict, entity_type_dict)
sanguo1 = get_sanguo()[0]
stopwords = get_baidu_stopwords()
docs = ht0.cut_sentences(sanguo1)
G = ht0.build_word_ego_graph(docs,"åå¤",min_freq=3,other_min_freq=2,stopwords=stopwords)

åå ³å¼ ä¹æ è°ï¼åå¤æå¥çé å±±ï¼ä»¥ååå¤è®¨è´¼ä¹ç»åå°½å¨äºæ¤ã
ææ¬æè¦
(使ç¨networkxå®ç°) 使ç¨Textrankç®æ³ï¼å¾å°ä»ææ¡£éåä¸æ½å代表å¥ä½ä¸ºæè¦ä¿¡æ¯ï¼å¯ä»¥è®¾ç½®æ©ç½éå¤çå¥åï¼ä¹å¯ä»¥è®¾ç½®åæ°éå¶(maxlenåæ°)ï¼
print("\nText summarization")
docs = ["æ¦ç£å¨æ¦ï¼ä¸è¶
第ä¸å°æï¼",
"éæçæ¥ä¸è¡ï¼å·²ç»å°ä¸éäºã",
"æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼",
"æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼"]
for doc in ht.get_summary(docs, topK=2):
print(doc)
print("\nText summarization(é¿å
éå¤)")
for doc in ht.get_summary(docs, topK=3, avoid_repeat=True):
print(doc)
Text summarization
æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼
æ¦ç£å¨æ¦ï¼ä¸è¶
第ä¸å°æï¼
Text summarization(é¿å
éå¤)
æ¦ççå¨æ¦ï¼ä¸è¶
æ强åéï¼
éæçæ¥ä¸è¡ï¼å·²ç»å°ä¸éäºã
æ¦ç£åéæï¼è°æ¯ä¸å½æ好çåéï¼
å ³é®è¯æ½å
ç®åæä¾å
æ¬textrankåHarvestTextå°è£
jieba并é
置好åæ°ååç¨è¯çjieba_tfidfï¼é»è®¤ï¼ä¸¤ç§ç®æ³ã
示ä¾(å®æ´è§example)ï¼
# text为æä¿æ°ãå
³é®è¯ãæè¯
print("ãå
³é®è¯ãéçå
³é®è¯")
kwds = ht.extract_keywords(text, 5, method="jieba_tfidf")
print("jieba_tfidf", kwds)
kwds = ht.extract_keywords(text, 5, method="textrank")
print("textrank", kwds)
ãå
³é®è¯ãéçå
³é®è¯
jieba_tfidf ['èªç§', 'æ
·æ
¨', 'è½å¶', 'æ¶é', 'æ
äº']
textrank ['èªç§', 'è½å¶', 'æ
·æ
¨', 'æ
äº', 'ä½ç½®']
CSL.ipynbæä¾äºä¸åç®æ³ï¼ä»¥åæ¬åºçå®ç°ä¸textrank4zhçå¨CSLæ°æ®éä¸çæ¯è¾ãç±äºä» æä¸ä¸ªæ°æ®éä¸æ°æ®é对äºä»¥ä¸ç®æ³é½å¾ä¸å好ï¼è¡¨ç°ä» ä¾åèã
| ç®æ³ | P@5 | R@5 | F@5 |
|---|---|---|---|
| textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_textrank | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
å ç½®èµæº
ç°å¨æ¬åºå éæäºä¸äºèµæºï¼æ¹ä¾¿ä½¿ç¨å建ç«demoã
èµæºå æ¬ï¼
get_qh_sent_dict: è¤è´¬ä¹è¯å ¸ æ¸ åå¤§å¦ æå æ´çèªhttp://nlp.csai.tsinghua.edu.cn/site2/index.php/13-smsget_baidu_stopwords: ç¾åº¦åç¨è¯è¯å ¸ æ¥èªç½ç»ï¼https://wenku.baidu.com/view/98c46383e53a580216fcfed9.htmlget_qh_typed_words: é¢åè¯å ¸ æ¥èªæ¸ åTHUNLPï¼ http://thuocl.thunlp.org/ å ¨é¨ç±»å['IT', 'å¨ç©', 'å»è¯', 'åå²äººå', 'å°å', 'æè¯', 'æ³å¾', 'è´¢ç»', 'é£ç©']get_english_senti_lexicon: è±è¯æ æè¯å ¸get_jieba_dict: ï¼éè¦ä¸è½½ï¼jiebaè¯é¢è¯å ¸
æ¤å¤ï¼è¿æä¾äºä¸ä¸ªç¹æ®èµæºââãä¸å½æ¼ä¹ãï¼å æ¬ï¼
- ä¸å½æ¼ä¹æè¨æææ¬
- ä¸å½æ¼ä¹äººåãå·åãå¿åç¥è¯åº
大家å¯ä»¥æ¢ç´¢ä»å ¶ä¸è½å¤å¾å°ä»ä¹æ趣åç°ðã
def load_resources():
from harvesttext.resources import get_qh_sent_dict,get_baidu_stopwords,get_sanguo,get_sanguo_entity_dict
sdict = get_qh_sent_dict() # {"pos":[积æè¯...],"neg":[æ¶æè¯...]}
print("pos_words:",list(sdict["pos"])[10:15])
print("neg_words:",list(sdict["neg"])[5:10])
stopwords = get_baidu_stopwords()
print("stopwords:", list(stopwords)[5:10])
docs = get_sanguo() # ææ¬å表ï¼æ¯ä¸ªå
ç´ ä¸ºä¸ç« çææ¬
print("ä¸å½æ¼ä¹æåä¸ç« æ«16å:\n",docs[-1][-16:])
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
print("åå¤ æ称ï¼",entity_mention_dict["åå¤"])
print("åå¤ ç±»å«ï¼",entity_type_dict["åå¤"])
print("è ç±»å«ï¼", entity_type_dict["è"])
print("çå· ç±»å«ï¼", entity_type_dict["çå·"])
load_resources()
pos_words: ['å®°ç¸èé好æè¹', 'æ¥å®', 'å¿ å®', 'åæ', 'èªæ']
neg_words: ['æ£æ¼«', 'è°è¨', 'è¿æ§', 'è è¥è满', 'åºå']
stopwords: ['apart', 'å·¦å³', 'ç»æ', 'probably', 'think']
ä¸å½æ¼ä¹æåä¸ç« æ«16å:
é¼è¶³ä¸åå·²æ梦ï¼å人åå空ç¢éªã
åå¤ æç§°ï¼ ['åå¤', 'åçå¾·', 'çå¾·']
åå¤ ç±»å«ï¼ 人å
è ç±»å«ï¼ å¿å
çå· ç±»å«ï¼ å·å
å è½½æ¸ åé¢åè¯å ¸ï¼å¹¶ä½¿ç¨åç¨è¯ã
def using_typed_words():
from harvesttext.resources import get_qh_typed_words,get_baidu_stopwords
ht0 = HarvestText()
typed_words, stopwords = get_qh_typed_words(), get_baidu_stopwords()
ht0.add_typed_words(typed_words)
sentence = "THUOCLæ¯èªç¶è¯è¨å¤ççä¸å¥ä¸æè¯åºï¼è¯è¡¨æ¥èªä¸»æµç½ç«ç社ä¼æ ç¾ãæç´¢çè¯ãè¾å
¥æ³è¯åºçã"
print(sentence)
print(ht0.posseg(sentence,stopwords=stopwords))
using_typed_words()
THUOCLæ¯èªç¶è¯è¨å¤ççä¸å¥ä¸æè¯åºï¼è¯è¡¨æ¥èªä¸»æµç½ç«ç社ä¼æ ç¾ãæç´¢çè¯ãè¾å
¥æ³è¯åºçã
[('THUOCL', 'eng'), ('èªç¶è¯è¨å¤ç', 'IT'), ('ä¸å¥', 'm'), ('ä¸æ', 'nz'), ('è¯åº', 'n'), ('è¯è¡¨', 'n'), ('æ¥èª', 'v'), ('主æµ', 'b'), ('ç½ç«', 'n'), ('社ä¼', 'n'), ('æ ç¾', 'è´¢ç»'), ('æç´¢', 'v'), ('çè¯', 'n'), ('è¾å
¥æ³', 'IT'), ('è¯åº', 'n')]
ä¸äºè¯è¯è¢«èµäºç¹æ®ç±»åIT,èâæ¯âçè¯è¯è¢«çåºã
æ°è¯åç°
ä»æ¯è¾å¤§éçææ¬ä¸å©ç¨ä¸äºç»è®¡ææ åç°æ°è¯ãï¼å¯éï¼éè¿æä¾ä¸äºç§åè¯è¯æ¥ç¡®å®ææ ·ç¨åº¦è´¨éçè¯è¯å¯ä»¥è¢«åç°ãï¼å³è³å°ææçç§åè¯ä¼è¢«åç°ï¼å¨æ»¡è¶³ä¸å®çåºç¡è¦æ±çåæä¸ãï¼
para = "ä¸æ¸¯çæ¦ç£åæ大çéæï¼è°æ¯ä¸å½æ好çåéï¼é£å½ç¶æ¯æ¦ç£æ¦ççäºï¼ä»æ¯å°ææ¦ç¬¬ä¸ï¼åæ¥æ¯å¼±ç¹çååä¹æäºè¿æ¥"
#è¿åå
³äºæ°è¯è´¨éçä¸ç³»åä¿¡æ¯ï¼å
许æå·¥æ¹è¿çé(pd.DataFrameå)
new_words_info = ht.word_discover(para)
#new_words_info = ht.word_discover(para, threshold_seeds=["æ¦ç£"])
new_words = new_words_info.index.tolist()
print(new_words)
["æ¦ç£"]
é«çº§è®¾ç½®ï¼å±å¼æ¥çï¼
å¯ä»¥ä½¿ç¨`excluding_words`åæ°æ¥å»é¤èªå·±ä¸æ³è¦çç»æï¼é»è®¤å æ¬äºåç¨è¯ãç®æ³ä½¿ç¨äºé»è®¤çç»éªåæ°ï¼å¦æ对ç»ææ°éä¸æ»¡æï¼å¯ä»¥è®¾ç½®auto_param=Falseèªå·±è°æ´åæ°ï¼è°æ´æç»è·å¾çç»æçæ°éï¼ç¸å
³åæ°å¦ä¸ï¼
:param max_word_len: å
许被åç°çæé¿çæ°è¯é¿åº¦
:param min_freq: 被åç°çæ°è¯ï¼å¨ç»å®ææ¬ä¸éè¦è¾¾å°çæä½é¢ç
:param min_entropy: 被åç°çæ°è¯ï¼å¨ç»å®ææ¬ä¸éè¦è¾¾å°çæä½å·¦å³äº¤åçµ
:param min_aggregation: 被åç°çæ°è¯ï¼å¨ç»å®ææ¬ä¸éè¦è¾¾å°çæä½åè度
æ¯å¦ï¼å¦ææ³è·å¾æ¯é»è®¤æ åµæ´å¤çç»æï¼æ¯å¦æäºæ°è¯æ²¡æ被åç°ï¼ï¼å¯ä»¥å¨é»è®¤åæ°çåºç¡ä¸å¾ä¸è°ï¼ä¸é¢çé»è®¤çåæ°ï¼
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
å ·ä½çç®æ³ç»èååæ°å«ä¹ï¼åèï¼http://www.matrix67.com/blog/archives/5044
使ç¨ç»å·´è¯å ¸è¿æ»¤æ§è¯ï¼å±å¼æ¥çï¼
``` from harvesttext.resources import get_jieba_dict jieba_dict = get_jieba_dict(min_freq=100) print("jiabaè¯å ¸ä¸çè¯é¢>100çè¯è¯æ°ï¼", len(jieba_dict)) text = "1979-1998-2020çåå®ä»¬ æç°å¨è®°å¿ä¸å¤ªå¥½ï¼å¤§æ¦æ¯æææ¶æåäº~æä»ä¹ç¬è®°é½è¦å½ä¸åä¸æ¥ãåå 天翻çï¼æ¾çäºå½æ¶è®°ä¸çè¯.æè§å¾åå®æ¢ä¸å¨±ä¹ä¹ä¸å¯ç¤º,ä½è¿å°±æ¯ç活就æ¯äººç,10/16æ¥çåå®å§" new_words_info = ht.word_discover(text, excluding_words=set(jieba_dict), # æé¤è¯å ¸å·²æè¯è¯ exclude_number=True) # æé¤æ°åï¼é»è®¤Trueï¼ new_words = new_words_info.index.tolist() print(new_words) # ['åå®'] ```æ ¹æ®åé¦æ´æ° åæ¬é»è®¤æ¥åä¸ä¸ªåç¬çå符串ï¼ç°å¨ä¹å¯ä»¥æ¥åå符串å表è¾å ¥ï¼ä¼èªå¨è¿è¡æ¼æ¥
æ ¹æ®åé¦æ´æ° ç°å¨é»è®¤æç
§è¯é¢éåºæåºï¼ä¹å¯ä»¥ä¼ å
¥sort_by='score'åæ°ï¼æç
§ç»¼åè´¨éè¯åæåºã
åç°çæ°è¯å¾å¤é½å¯è½æ¯ææ¬ä¸çç¹æ®å ³é®è¯ï¼æ å¯ä»¥ææ¾å°çæ°è¯ç»å½ï¼ä½¿åç»çåè¯ä¼å ååºè¿äºè¯ã
def new_word_register():
new_words = ["è½å¶ç","666"]
ht.add_new_words(new_words) # ä½ä¸ºå¹¿ä¹ä¸ç"æ°è¯"ç»å½
ht.add_new_entity("è½å¶ç", mention0="è½å¶ç", type0="æ¯è¯") # ä½ä¸ºç¹å®ç±»åç»å½
print(ht.seg("è¿ä¸ªè½å¶ç踢å¾çæ¯666", return_sent=True))
for word, flag in ht.posseg("è¿ä¸ªè½å¶ç踢å¾çæ¯666"):
print("%s:%s" % (word, flag), end=" ")
è¿ä¸ª è½å¶ç 踢 å¾ çæ¯ 666
è¿ä¸ª:r è½å¶ç:æ¯è¯ 踢:v å¾:ud çæ¯:d 666:æ°è¯
ä¹å¯ä»¥ä½¿ç¨ä¸äºç¹æ®çè§åæ¥æ¾å°æéçå ³é®è¯ï¼å¹¶ç´æ¥èµäºç±»åï¼æ¯å¦å ¨è±æï¼æè æçç¹å®çååç¼çã
# find_with_rules()
from harvesttext.match_patterns import UpperFirst, AllEnglish, Contains, StartsWith, EndsWith
text0 = "æå欢Pythonï¼å 为requestsåºå¾éåç¬è«"
ht0 = HarvestText()
found_entities = ht0.find_entity_with_rule(text0, rulesets=[AllEnglish()], type0="è±æå")
print(found_entities)
print(ht0.posseg(text0))
{'Python', 'requests'}
[('æ', 'r'), ('å欢', 'v'), ('Python', 'è±æå'), ('ï¼', 'x'), ('å 为', 'c'), ('requests', 'è±æå'), ('åº', 'n'), ('å¾', 'd'), ('éå', 'v'), ('ç¬è«', 'n')]
èªå¨å段
使ç¨TextTilingç®æ³ï¼å¯¹æ²¡æå段çææ¬èªå¨å段ï¼æè åºäºå·²æ段è½è¿ä¸æ¥ç»ç»/éæ°å段ã
ht0 = HarvestText()
text = """å¤å社ä¼å
³æ³¨çæ¹å常德滴滴å¸æºé害æ¡ï¼å°äº1æ3æ¥9æ¶è®¸ï¼å¨æ±å¯¿å¿äººæ°æ³é¢å¼åºå®¡çãæ¤åï¼ç¯ç½ªå«ç人ã19å²å¤§å¦çæ¨ææ·è¢«é´å®ä¸ºä½æ¡æ¶æ£ææéçï¼ä¸ºâæéå®åäºè´£ä»»è½åâã
æ°äº¬æ¥æ¤åæ¥éï¼2019å¹´3æ24æ¥åæ¨ï¼æ»´æ»´å¸æºéå¸å
ï¼æè½½19å²å¤§å¦çæ¨ææ·å°å¸¸å汽车æ»ç«éè¿ãåå¨åæçæ¨ææ·è¶éæä¸å¤ï¼æéæè¿æ
æ°åè´å
¶æ»äº¡ãäºåçæ§æ¾ç¤ºï¼æ¨ææ·æ人åä¸è½¦ç¦»å¼ãéåï¼æ¨ææ·å°å
¬å®æºå
³èªé¦ï¼å¹¶ä¾è¿°ç§°âå æ²è§åä¸ï¼ç²¾ç¥å´©æºï¼æ æ
å°å¸æºæ害âãæ®æ¨ææ·å°±è¯»å¦æ ¡çå·¥ä½äººå称ï¼ä»å®¶æåå£äººï¼å§å§æ¯èå人ã
ä»æ¥ä¸åï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ææ¥å¼åºæ¶é´ä¸åï¼æ¤åå·²æåºåäºé带æ°äºèµå¿ï¼ä½éè¿ä¸æ³é¢çæ²éåè·ç¥ï¼å¯¹æ¹ç¶æ¯å·²ç»æ²¡æèµå¿çææ¿ãå½æ¶æç
§äººèº«æ»äº¡èµå¿é计ç®å
±è®¡80å¤ä¸å
ï¼é£æ¶ä¹æ³èè对æ¹å®¶åºçç»æµç¶åµã
ç°å¥³å£«è¯´ï¼å¥¹ç¸ä¿¡æ³å¾ï¼å¯¹æåçç»æä¹å好å¿çåå¤ã对æ¹ä¸å®¶ä»æªéæï¼æ¤ååºåä¼è®®ä¸ï¼å¯¹æ¹æåºäºå«ç人æ¨ææ·ä½æ¡æ¶æ£ææéçç辩æ¤æè§ãå¦å
·è¦æ¹åºå
·çé´å®ä¹¦æ¾ç¤ºï¼å«ç人ä½æ¡æ¶æéå®åäºè´£ä»»è½åã
æ°äº¬æ¥è®°è
ä»éå¸å
ç家å±å¤è·ç¥ï¼éå¸å
æ两个å¿åï¼å¤§å¿åä»å¹´18å²ï¼å°å¿åè¿ä¸å°5å²ãâè¿å¯¹ææ¥è¯´æ¯ä¸èµ·æ²å§ï¼å¯¹æ们çæ´»çå½±åï¼è¯å®æ¯å¾å¤§çâï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ä¸å¤«é害åï¼ä»ä»¬ä¸å®¶ç主å³å¨å没æäºï¼å¥¹èªå·±å¸¦ç两个å©åå两个è人ä¸èµ·è¿ï¼âçæ´»å¾è°è¾âï¼å¥¹è¯´ï¼âè¿å¥½æ妹妹çéªä¼´ï¼ç°å¨å·²ç»å¥½äºäºãâ"""
print("åå§ææ¬[5段]")
print(text+"\n")
print("é¢æµææ¬[æå¨è®¾ç½®å3段]")
predicted_paras = ht0.cut_paragraphs(text, num_paras=3)
print("\n".join(predicted_paras)+"\n")
åå§ææ¬[5段]
å¤å社ä¼å
³æ³¨çæ¹å常德滴滴å¸æºé害æ¡ï¼å°äº1æ3æ¥9æ¶è®¸ï¼å¨æ±å¯¿å¿äººæ°æ³é¢å¼åºå®¡çãæ¤åï¼ç¯ç½ªå«ç人ã19å²å¤§å¦çæ¨ææ·è¢«é´å®ä¸ºä½æ¡æ¶æ£ææéçï¼ä¸ºâæéå®åäºè´£ä»»è½åâã
æ°äº¬æ¥æ¤åæ¥éï¼2019å¹´3æ24æ¥åæ¨ï¼æ»´æ»´å¸æºéå¸å
ï¼æè½½19å²å¤§å¦çæ¨ææ·å°å¸¸å汽车æ»ç«éè¿ãåå¨åæçæ¨ææ·è¶éæä¸å¤ï¼æéæè¿æ
æ°åè´å
¶æ»äº¡ãäºåçæ§æ¾ç¤ºï¼æ¨ææ·æ人åä¸è½¦ç¦»å¼ãéåï¼æ¨ææ·å°å
¬å®æºå
³èªé¦ï¼å¹¶ä¾è¿°ç§°âå æ²è§åä¸ï¼ç²¾ç¥å´©æºï¼æ æ
å°å¸æºæ害âãæ®æ¨ææ·å°±è¯»å¦æ ¡çå·¥ä½äººå称ï¼ä»å®¶æåå£äººï¼å§å§æ¯èå人ã
ä»æ¥ä¸åï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ææ¥å¼åºæ¶é´ä¸åï¼æ¤åå·²æåºåäºé带æ°äºèµå¿ï¼ä½éè¿ä¸æ³é¢çæ²éåè·ç¥ï¼å¯¹æ¹ç¶æ¯å·²ç»æ²¡æèµå¿çææ¿ãå½æ¶æç
§äººèº«æ»äº¡èµå¿é计ç®å
±è®¡80å¤ä¸å
ï¼é£æ¶ä¹æ³èè对æ¹å®¶åºçç»æµç¶åµã
ç°å¥³å£«è¯´ï¼å¥¹ç¸ä¿¡æ³å¾ï¼å¯¹æåçç»æä¹å好å¿çåå¤ã对æ¹ä¸å®¶ä»æªéæï¼æ¤ååºåä¼è®®ä¸ï¼å¯¹æ¹æåºäºå«ç人æ¨ææ·ä½æ¡æ¶æ£ææéçç辩æ¤æè§ãå¦å
·è¦æ¹åºå
·çé´å®ä¹¦æ¾ç¤ºï¼å«ç人ä½æ¡æ¶æéå®åäºè´£ä»»è½åã
æ°äº¬æ¥è®°è
ä»éå¸å
ç家å±å¤è·ç¥ï¼éå¸å
æ两个å¿åï¼å¤§å¿åä»å¹´18å²ï¼å°å¿åè¿ä¸å°5å²ãâè¿å¯¹ææ¥è¯´æ¯ä¸èµ·æ²å§ï¼å¯¹æ们çæ´»çå½±åï¼è¯å®æ¯å¾å¤§çâï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ä¸å¤«é害åï¼ä»ä»¬ä¸å®¶ç主å³å¨å没æäºï¼å¥¹èªå·±å¸¦ç两个å©åå两个è人ä¸èµ·è¿ï¼âçæ´»å¾è°è¾âï¼å¥¹è¯´ï¼âè¿å¥½æ妹妹çéªä¼´ï¼ç°å¨å·²ç»å¥½äºäºãâ
é¢æµææ¬[æå¨è®¾ç½®å3段]
å¤å社ä¼å
³æ³¨çæ¹å常德滴滴å¸æºé害æ¡ï¼å°äº1æ3æ¥9æ¶è®¸ï¼å¨æ±å¯¿å¿äººæ°æ³é¢å¼åºå®¡çãæ¤åï¼ç¯ç½ªå«ç人ã19å²å¤§å¦çæ¨ææ·è¢«é´å®ä¸ºä½æ¡æ¶æ£ææéçï¼ä¸ºâæéå®åäºè´£ä»»è½åâã
æ°äº¬æ¥æ¤åæ¥éï¼2019å¹´3æ24æ¥åæ¨ï¼æ»´æ»´å¸æºéå¸å
ï¼æè½½19å²å¤§å¦çæ¨ææ·å°å¸¸å汽车æ»ç«éè¿ãåå¨åæçæ¨ææ·è¶éæä¸å¤ï¼æéæè¿æ
æ°åè´å
¶æ»äº¡ãäºåçæ§æ¾ç¤ºï¼æ¨ææ·æ人åä¸è½¦ç¦»å¼ãéåï¼æ¨ææ·å°å
¬å®æºå
³èªé¦ï¼å¹¶ä¾è¿°ç§°âå æ²è§åä¸ï¼ç²¾ç¥å´©æºï¼æ æ
å°å¸æºæ害âãæ®æ¨ææ·å°±è¯»å¦æ ¡çå·¥ä½äººå称ï¼ä»å®¶æåå£äººï¼å§å§æ¯èå人ã
ä»æ¥ä¸åï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ææ¥å¼åºæ¶é´ä¸åï¼æ¤åå·²æåºåäºé带æ°äºèµå¿ï¼ä½éè¿ä¸æ³é¢çæ²éåè·ç¥ï¼å¯¹æ¹ç¶æ¯å·²ç»æ²¡æèµå¿çææ¿ãå½æ¶æç
§äººèº«æ»äº¡èµå¿é计ç®å
±è®¡80å¤ä¸å
ï¼é£æ¶ä¹æ³èè对æ¹å®¶åºçç»æµç¶åµãç°å¥³å£«è¯´ï¼å¥¹ç¸ä¿¡æ³å¾ï¼å¯¹æåçç»æä¹å好å¿çåå¤ã对æ¹ä¸å®¶ä»æªéæï¼æ¤ååºåä¼è®®ä¸ï¼å¯¹æ¹æåºäºå«ç人æ¨ææ·ä½æ¡æ¶æ£ææéçç辩æ¤æè§ãå¦å
·è¦æ¹åºå
·çé´å®ä¹¦æ¾ç¤ºï¼å«ç人ä½æ¡æ¶æéå®åäºè´£ä»»è½åãæ°äº¬æ¥è®°è
ä»éå¸å
ç家å±å¤è·ç¥ï¼éå¸å
æ两个å¿åï¼å¤§å¿åä»å¹´18å²ï¼å°å¿åè¿ä¸å°5å²ãâè¿å¯¹ææ¥è¯´æ¯ä¸èµ·æ²å§ï¼å¯¹æ们çæ´»çå½±åï¼è¯å®æ¯å¾å¤§çâï¼ç°å¥³å£«åè¯æ°äº¬æ¥è®°è
ï¼ä¸å¤«é害åï¼ä»ä»¬ä¸å®¶ç主å³å¨å没æäºï¼å¥¹èªå·±å¸¦ç两个å©åå两个è人ä¸èµ·è¿ï¼âçæ´»å¾è°è¾âï¼å¥¹è¯´ï¼âè¿å¥½æ妹妹çéªä¼´ï¼ç°å¨å·²ç»å¥½äºäºãâ
ä¸åå§è®ºæä¸ä¸åï¼è¿é以åå¥ç»æä½ä¸ºåºæ¬åå
ï¼è使ç¨ä¸æ¯åºå®æ°ç®çå符ï¼è¯ä¹ä¸æ´å æ¸
æ°ï¼ä¸çå»äºè®¾ç½®åæ°ç麻ç¦ãå æ¤ï¼é»è®¤è®¾å®ä¸çç®æ³ä¸æ¯æ没ææ ç¹çææ¬ãä½æ¯å¯ä»¥éè¿æseq_chars设置为ä¸æ£æ´æ°ï¼æ¥ä½¿ç¨åå§è®ºæç设置ï¼ä¸ºæ²¡ææ ç¹çææ¬æ¥è¿è¡å段ï¼å¦æä¹æ²¡æ段è½æ¢è¡ï¼è¯·è®¾ç½®align_boundary=Falseãä¾è§examples/basic.pyä¸çcut_paragraph()ï¼
print("å»é¤æ ç¹ä»¥åçå段")
text2 = extract_only_chinese(text)
predicted_paras2 = ht0.cut_paragraphs(text2, num_paras=5, seq_chars=10, align_boundary=False)
print("\n".join(predicted_paras2)+"\n")
å»é¤æ ç¹ä»¥åçå段
å¤å社ä¼å
³æ³¨çæ¹å常德滴滴å¸æºé害æ¡å°äºææ¥æ¶è®¸å¨æ±å¯¿å¿äººæ°æ³é¢å¼åºå®¡çæ¤åç¯ç½ªå«ç人å²å¤§å¦çæ¨ææ·è¢«é´å®ä¸ºä½æ¡æ¶æ£ææéç为æ
éå®åäºè´£ä»»è½åæ°äº¬æ¥æ¤åæ¥éå¹´
ææ¥åæ¨æ»´æ»´å¸æºéå¸
å
æè½½å²å¤§å¦çæ¨ææ·å°å¸¸å汽车æ»ç«éè¿åå¨åæçæ¨ææ·è¶éæä¸å¤æéæè¿æ
æ°åè´å
¶æ»äº¡äºåçæ§æ¾ç¤ºæ¨ææ·æ人åä¸è½¦ç¦»å¼éåæ¨ææ·
å°å
¬å®æºå
³èªé¦å¹¶ä¾è¿°ç§°å æ²è§åä¸ç²¾ç¥å´©æºæ æ
å°å¸æºæ害æ®æ¨ææ·å°±è¯»å¦æ ¡çå·¥ä½äººå称ä»å®¶æåå£äººå§å§æ¯èå人ä»æ¥ä¸åç°å¥³å£«åè¯æ°äº¬
æ¥è®°è
ææ¥å¼åºæ¶é´ä¸åæ¤åå·²æåºåäºé带æ°äºèµå¿ä½éè¿ä¸æ³é¢çæ²éåè·ç¥å¯¹æ¹ç¶æ¯å·²ç»æ²¡æèµå¿çææ¿å½æ¶æç
§äººèº«æ»äº¡èµå¿é计ç®å
±è®¡
å¤ä¸å
é£æ¶ä¹æ³èè对æ¹å®¶åºçç»æµç¶åµç°å¥³å£«è¯´å¥¹ç¸ä¿¡æ³å¾å¯¹æåçç»æä¹å好å¿çåå¤å¯¹æ¹ä¸å®¶ä»æªéææ¤ååºåä¼è®®ä¸å¯¹æ¹æ
åºäºå«ç人æ¨ææ·ä½æ¡æ¶æ£ææéçç辩æ¤æè§å¦å
·è¦æ¹åºå
·çé´å®ä¹¦æ¾ç¤ºå«ç人ä½æ¡æ¶æéå®åäºè´£ä»»è½åæ°äº¬
æ¥è®°è
ä»éå¸å
ç家å±å¤è·ç¥éå¸å
æ两个å¿å大å¿åä»å¹´å²å°å¿åè¿ä¸å°å²è¿å¯¹ææ¥è¯´æ¯ä¸èµ·æ²å§å¯¹æ们çæ´»çå½±åè¯å®æ¯å¾å¤§çç°å¥³å£«åè¯æ°
京æ¥è®°è
ä¸å¤«é害åä»ä»¬ä¸å®¶ç主å³å¨å没æäºå¥¹èªå·±å¸¦ç两个å©åå两个è人ä¸èµ·è¿çæ´»å¾è°è¾å¥¹è¯´è¿å¥½æ妹妹çéªä¼´ç°å¨å·²ç»å¥½äºäº
ååæ¶é¤
å¯ä»¥æ¬å°ä¿å模åå读åå¤ç¨ï¼ä¹å¯ä»¥æ¶é¤å½å模åçè®°å½ã
from harvesttext import loadHT,saveHT
para = "ä¸æ¸¯çæ¦ç£åæ大çéæï¼è°æ¯ä¸å½æ好çåéï¼é£å½ç¶æ¯æ¦ç£æ¦ççäºï¼ä»æ¯å°ææ¦ç¬¬ä¸ï¼åæ¥æ¯å¼±ç¹çååä¹æäºè¿æ¥"
saveHT(ht,"ht_model1")
ht2 = loadHT("ht_model1")
# æ¶é¤è®°å½
ht2.clear()
print("cut with cleared model")
print(ht2.seg(para))
ç®æé®çç³»ç»
å ·ä½å®ç°åä¾åå¨naiveKGQA.pyä¸ï¼ä¸é¢ç»åºé¨å示æï¼
QA = NaiveKGQA(SVOs, entity_type_dict=entity_type_dict)
questions = ["ä½ å¥½","åä¸å±±å¹²äºä»ä¹äºï¼","è°åå¨äºä»ä¹ï¼","æ¸
æ¿åºç¾è®¢äºåªäºæ¡çº¦ï¼",
"è±å½ä¸é¸¦çæäºçå
³ç³»æ¯ä»ä¹ï¼","è°å¤è¾äºå¸å¶ï¼"]
for question0 in questions:
print("é®ï¼"+question0)
print("çï¼"+QA.answer(question0))
é®ï¼åä¸å±±å¹²äºä»ä¹äºï¼
çï¼å°±ä»»ä¸´æ¶å¤§æ»ç»ãåå¨æ¤æ³è¿å¨ã让ä½äºè¢ä¸å¯
é®ï¼è°åå¨äºä»ä¹ï¼
çï¼è±æ³èåä¾µç¥ä¸å½ãå½æ°å
人äºæ¬¡é©å½ãè±å½é¸¦çæäºãæ¥æ¬ä¾µç¥æé²ãåä¸å±±æ¤æ³è¿å¨ãæ³å½ä¾µç¥è¶åãè±å½ä¾µç¥ä¸å½è¥¿èæäºãæ
禧太åæææ¿å
é®ï¼æ¸
æ¿åºç¾è®¢äºåªäºæ¡çº¦ï¼
çï¼å京æ¡çº¦ã天津æ¡çº¦
é®ï¼è±å½ä¸é¸¦çæäºçå
³ç³»æ¯ä»ä¹ï¼
çï¼åå¨
é®ï¼è°å¤è¾äºå¸å¶ï¼
çï¼è¢ä¸å¯
è±è¯æ¯æ
æ¬åºä¸»è¦æ¨å¨æ¯æ对ä¸æçæ°æ®ææï¼ä½æ¯å å ¥äºå æ¬æ æåæå¨å çå°éè±è¯æ¯æã
éè¦ä½¿ç¨è¿äºåè½ï¼éè¦å建ä¸ä¸ªä¸é¨è±è¯æ¨¡å¼çHarvestText对象ã
# ⪠"Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""".lower()
ht_eng = HarvestText(language="en")
sentences = ht_eng.cut_sentences(test_text) # åå¥
print("\n".join(sentences))
print(ht_eng.seg(sentences[-1])) # åè¯[åè¯æ§æ 注]
print(ht_eng.posseg(sentences[0], stopwords={"in"}))
# æ
æåæ
sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=["familiar"], neg_seeds=["lonely"],
min_times=1, stopwords={'in', 'to'})
print("sentiment analysis")
for sent0 in sentences:
print(sent0, "%.3f" % ht_eng.analyse_sent(sent0))
# èªå¨å段
print("Segmentation")
print("\n".join(ht_eng.cut_paragraphs(test_text, num_paras=2)))
# æ
æåæä¹æä¾äºä¸ä¸ªå
ç½®è±æè¯å
¸èµæº
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1)
in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
ç®å对è±è¯çæ¯æ并ä¸å®åï¼é¤å»ä¸è¿°ç¤ºä¾ä¸çåè½ï¼å ¶ä»åè½ä¸ä¿è¯è½å¤ä½¿ç¨ã
å¼ç¨
å¦æä½ åç°è¿ä¸ªåºå¯¹ä½ çå¦æ¯å·¥ä½ææ帮å©ï¼è¯·æç §ä¸é¢çæ ¼å¼å¼ç¨
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {\url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
More
æ¬åºæ£å¨å¼åä¸ï¼å ³äºç°æåè½çæ¹ååæ´å¤åè½çæ·»å å¯è½ä¼éç»å°æ¥ã欢è¿å¨issueséæä¾æè§å»ºè®®ãè§å¾å¥½ç¨çè¯ï¼ä¹ä¸å¦¨æ¥ä¸ªStar~
æ谢以ä¸repo带æ¥çå¯åï¼
Top Related Projects
An Open-Source Package for Neural Relation Extraction (NRE)
Stanford NLP Python library for tokenization, sentence segmentation, NER, and parsing of many human languages
结巴中文分词
Python library for processing Chinese text
中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理
百度NLP:分词,词性标注,命名实体识别,词重要性
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot