
Top Related Projects

PyTorch code and models for the DINOv2 self-supervised learning method.
PyTorch implementation of MAE https//arxiv.org/abs/2111.06377

Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities

TensorFlow code and pre-trained models for BERT

🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Quick Overview
DINO (DIstribution of Nearby Objects) is a self-supervised learning method for vision transformers. It enables the training of vision transformers without labels, producing high-quality features that can be used for various downstream tasks such as image classification, object detection, and segmentation.
Pros
- Achieves state-of-the-art performance on various computer vision tasks without using labels
- Produces features that are highly transferable to different downstream tasks
- Works well with vision transformers, which have shown great potential in computer vision
- Enables self-supervised learning on large-scale datasets
Cons
- Requires significant computational resources for training, especially on large datasets
- May not be as effective for smaller datasets or specific domain tasks
- Complexity of the method may make it challenging to implement and fine-tune for some users
- Potential overfitting on certain types of visual patterns or textures
Code Examples
# Load pre-trained DINO model
import torch
import torchvision.models as models
model = torch.hub.load('facebookresearch/dino:main', 'dino_vits16')
model.eval()
# Extract features from an image
from PIL import Image
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img = Image.open('path/to/image.jpg')
img_tensor = transform(img).unsqueeze(0)
with torch.no_grad():
features = model(img_tensor)
# Perform self-attention visualization
import numpy as np
import matplotlib.pyplot as plt
def get_attention_map(model, img_tensor):
w_qkv = model.blocks[-1].attn.qkv.weight
w_q, w_k, w_v = w_qkv.chunk(3, dim=0)
with torch.no_grad():
feat = model.get_intermediate_layers(img_tensor, n=1)[0]
q = torch.matmul(feat, w_q.t())
k = torch.matmul(feat, w_k.t())
attn = torch.bmm(q, k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
return attn.squeeze().cpu().numpy()
attn_map = get_attention_map(model, img_tensor)
plt.imshow(attn_map)
plt.show()
Getting Started
To get started with DINO, follow these steps:
-
Install the required dependencies:
pip install torch torchvision -
Load the pre-trained DINO model:
import torch model = torch.hub.load('facebookresearch/dino:main', 'dino_vits16') model.eval() -
Use the model for feature extraction or fine-tuning on your specific task. Refer to the code examples above for guidance on how to extract features and visualize self-attention maps.
For more detailed information and advanced usage, refer to the official DINO repository and documentation.
Competitor Comparisons
PyTorch code and models for the DINOv2 self-supervised learning method.
Pros of DINOv2
- More advanced and up-to-date implementation of self-supervised learning
- Includes pre-trained models and evaluation scripts for various tasks
- Offers better performance on downstream tasks like image classification
Cons of DINOv2
- Higher computational requirements for training and inference
- More complex codebase, potentially harder to understand and modify
- Less flexibility for customization compared to the original DINO
Code Comparison
DINO:
class DINOLoss(nn.Module):
def __init__(self, out_dim, ncrops, warmup_teacher_temp, teacher_temp,
warmup_teacher_temp_epochs, nepochs, student_temp=0.1,
center_momentum=0.9):
super().__init__()
self.student_temp = student_temp
self.center_momentum = center_momentum
self.register_buffer("center", torch.zeros(1, out_dim))
DINOv2:
class DINOLoss(nn.Module):
def __init__(
self,
out_dim,
teacher_temp: float = 0.04,
student_temp: float = 0.1,
center_momentum: float = 0.9,
):
super().__init__()
self.teacher_temp = teacher_temp
self.student_temp = student_temp
self.center_momentum = center_momentum
self.register_buffer("center", torch.zeros(1, out_dim))
PyTorch implementation of MAE https//arxiv.org/abs/2111.06377
Pros of MAE
- More efficient self-supervised learning approach with masked autoencoders
- Better performance on downstream tasks like image classification and object detection
- Extensive documentation and experimental results provided in the repository
Cons of MAE
- More complex architecture and training process compared to DINO
- Requires more computational resources for training due to the reconstruction task
- Less focus on contrastive learning, which may be beneficial for certain applications
Code Comparison
MAE (encoder-decoder architecture):
def forward_encoder(self, x, mask_ratio):
# mask tokens
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# encode tokens
x = self.encoder(x)
return x, mask, ids_restore
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] - x.shape[1], 1)
x_ = torch.cat([x, mask_tokens], dim=1)
# unshuffle
x = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2]))
# decode tokens
x = self.decoder(x)
return x
DINO (contrastive learning approach):
def forward(self, im_q, im_k):
q = self.student_encoder(im_q)
q = self.student_head(q)
with torch.no_grad():
k = self.teacher_encoder(im_k)
k = self.teacher_head(k)
return q, k
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Pros of UniLM
- Broader scope: Supports various NLP tasks including text generation, summarization, and question answering
- Extensive documentation and examples for different use cases
- Larger community and more frequent updates
Cons of UniLM
- More complex setup and usage due to its broader feature set
- Heavier resource requirements for training and inference
- Steeper learning curve for newcomers to NLP
Code Comparison
UniLM example (text generation):
from transformers import UniLMTokenizer, UniLMForConditionalGeneration
tokenizer = UniLMTokenizer.from_pretrained("microsoft/unilm-base-cased")
model = UniLMForConditionalGeneration.from_pretrained("microsoft/unilm-base-cased")
input_text = "Generate a story about a robot:"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=100, num_return_sequences=1)
DINO example (object detection):
import torch
from models import build_model
from util.slconfig import SLConfig
args = SLConfig.fromfile("config.py")
model, _, _ = build_model(args)
checkpoint = torch.load("checkpoint.pth", map_location="cpu")
model.load_state_dict(checkpoint["model"])
TensorFlow code and pre-trained models for BERT
Pros of BERT
- Widely adopted and well-established in the NLP community
- Extensive pre-trained models available for various languages and tasks
- Robust documentation and community support
Cons of BERT
- Larger model size and higher computational requirements
- Less suitable for real-time or resource-constrained applications
- Limited to text-based tasks, not designed for multimodal learning
Code Comparison
BERT example:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
DINO example:
import torch
from torchvision import transforms as pth_transforms
from dino import utils, vision_transformer as vits
model = vits.__dict__['vit_small'](patch_size=16, num_classes=0)
utils.load_pretrained_weights(model, '', 'teacher', 'vit_small', 16)
model.eval()
Both repositories offer powerful pre-trained models, but BERT focuses on natural language processing tasks, while DINO is designed for self-supervised visual representation learning. BERT has a larger ecosystem and more widespread adoption, whereas DINO provides a more specialized approach for computer vision applications.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of Transformers
- Extensive library of pre-trained models for various NLP tasks
- Active community and frequent updates
- Comprehensive documentation and tutorials
Cons of Transformers
- Larger codebase and potentially steeper learning curve
- Higher computational requirements for some models
- May be overkill for simpler NLP tasks
Code Comparison
Transformers:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I love this product!")[0]
print(f"Label: {result['label']}, Score: {result['score']:.4f}")
Dino:
import dino
model = dino.load("dino_vits16")
image = dino.preprocess_image("image.jpg")
features = model.get_features(image)
Key Differences
- Transformers focuses on NLP tasks, while Dino is primarily for computer vision
- Transformers offers a wider range of models and tasks
- Dino has a simpler API and is more specialized for self-supervised learning in vision
Use Cases
- Transformers: Ideal for complex NLP projects requiring state-of-the-art models
- Dino: Better suited for computer vision tasks, especially when working with limited labeled data
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Dino
Dino is an XMPP messaging app for Linux using GTK and Vala. It supports calls, encryption, file transfers, group chats and more.
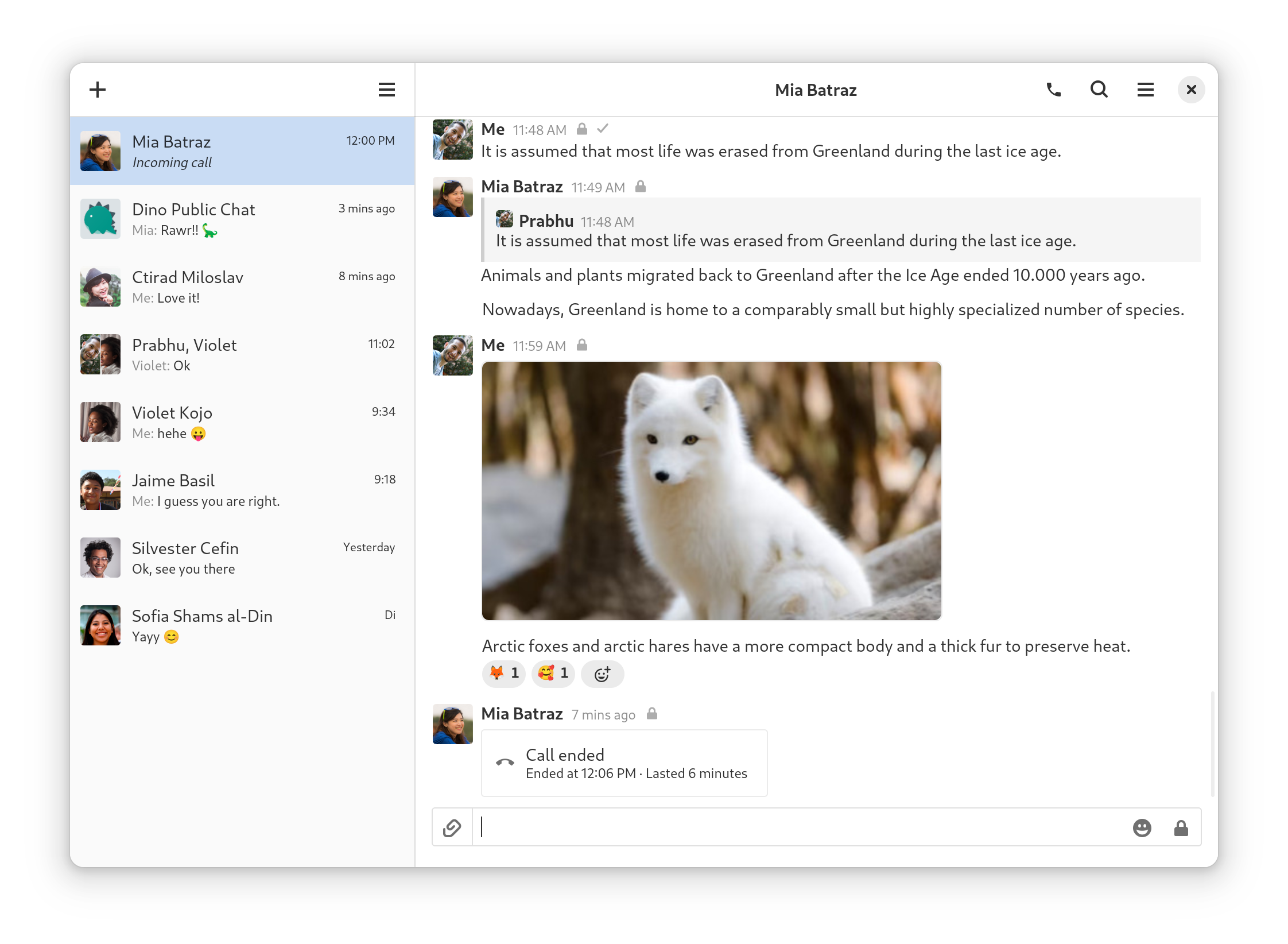
Installation
Have a look at the prebuilt packages.
Build
Make sure to install all dependencies.
meson setup build
meson compile -C build
build/main/dino
Resources
- Check out the Dino website.
- Join our XMPP channel at
chat@dino.im. - The wiki provides additional information.
Contribute
- Pull requests are welcome. These might be good first issues. Please discuss bigger changes in our channel first.
- Look at how to debug Dino before you report a bug.
- Help translating Dino into your language.
- Make a donation.
License
Dino - XMPP messaging app using GTK/Vala
Copyright (C) 2016-2025 Dino contributors
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Top Related Projects
PyTorch code and models for the DINOv2 self-supervised learning method.
PyTorch implementation of MAE https//arxiv.org/abs/2111.06377
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
TensorFlow code and pre-trained models for BERT
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot