
Top Related Projects

CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image



🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
TensorFlow code and pre-trained models for BERT
Quick Overview
ImageBind is a project by Facebook Research that introduces a novel approach to joint embedding across six modalities: images, text, audio, depth, thermal, and IMU data. It enables zero-shot classification and retrieval across these modalities, allowing for tasks like audio-to-image retrieval or text-to-thermal generation without explicit training on these tasks.
Pros
- Enables cross-modal understanding and generation without task-specific training
- Supports a wide range of modalities (six in total)
- Demonstrates strong performance in zero-shot classification and retrieval tasks
- Open-source implementation available for research and development
Cons
- Requires significant computational resources for training and inference
- May have limitations in handling complex or highly specialized domain-specific data
- Potential privacy concerns when dealing with multi-modal personal data
- Limited documentation and examples for some advanced use cases
Code Examples
- Loading pre-trained ImageBind models:
from imagebind import data
from imagebind.models import imagebind_model
# Load pre-trained model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
- Preparing inputs for different modalities:
# Prepare inputs for image, text, and audio
inputs = {
"image": data.load_and_transform_vision_data(["path/to/image.jpg"]),
"text": data.load_and_transform_text(["A description of the image"]),
"audio": data.load_and_transform_audio_data(["path/to/audio.wav"]),
}
- Generating embeddings for multiple modalities:
# Generate embeddings
with torch.no_grad():
embeddings = model(inputs)
# Access embeddings for each modality
image_embeddings = embeddings["image"]
text_embeddings = embeddings["text"]
audio_embeddings = embeddings["audio"]
Getting Started
To get started with ImageBind:
- Install the required dependencies:
pip install torch torchvision torchaudio
pip install git+https://github.com/facebookresearch/ImageBind.git
- Import the necessary modules and load the pre-trained model:
from imagebind import data
from imagebind.models import imagebind_model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
- Prepare your inputs and generate embeddings:
inputs = {
"image": data.load_and_transform_vision_data(["path/to/image.jpg"]),
"text": data.load_and_transform_text(["A description of the image"]),
}
with torch.no_grad():
embeddings = model(inputs)
Competitor Comparisons
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
Pros of CLIP
- More established and widely adopted in the research community
- Extensive documentation and examples available
- Supports a broader range of pre-trained models
Cons of CLIP
- Limited to image-text pairs, while ImageBind supports multiple modalities
- May require more computational resources for training and inference
- Less flexible for custom modality combinations
Code Comparison
CLIP:
import torch
from PIL import Image
import clip
model, preprocess = clip.load("ViT-B/32", device="cuda")
image = preprocess(Image.open("image.jpg")).unsqueeze(0).to("cuda")
text = clip.tokenize(["a photo of a cat"]).to("cuda")
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
ImageBind:
import torch
from imagebind import data
from imagebind.models import imagebind_model
inputs = {
ModalityType.VISION: data.load_and_transform_vision_data(["image.jpg"], device),
ModalityType.TEXT: data.load_and_transform_text(["a photo of a cat"], device),
}
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
with torch.no_grad():
embeddings = model(inputs)
Pros of Vision Transformer
- Focused specifically on image classification tasks
- Implements the original Vision Transformer (ViT) architecture
- Provides pre-trained models for various ViT configurations
Cons of Vision Transformer
- Limited to visual data processing
- Less versatile for multi-modal applications
- Requires more computational resources for training large models
Code Comparison
Vision Transformer:
import tensorflow as tf
from vit_jax import models
model = models.vit_b16(
num_classes=1000,
representation_size=None,
)
ImageBind:
import torch
from imagebind import data
from imagebind.models import imagebind_model
model = imagebind_model.imagebind_huge(pretrained=True)
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
}
The Vision Transformer code focuses on initializing a ViT model for image classification, while ImageBind's code demonstrates its multi-modal capabilities by loading both text and vision data for processing.
Pros of BioGPT
- Specialized for biomedical text processing and generation
- Trained on large-scale biomedical literature datasets
- Supports domain-specific tasks like named entity recognition and relation extraction
Cons of BioGPT
- Limited to text-based inputs and outputs
- Focused on a specific domain, potentially less versatile for general applications
- May require more domain expertise to utilize effectively
Code Comparison
BioGPT:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("microsoft/biogpt")
model = AutoModelForCausalLM.from_pretrained("microsoft/biogpt")
input_text = "The BRCA1 gene is associated with"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=50)
ImageBind:
import torch
from imagebind import data
from imagebind.models import imagebind_model
inputs = {
ModalityType.TEXT: data.load_and_transform_text(["A dog", "A cat"], device),
ModalityType.VISION: data.load_and_transform_vision_data(["dog.jpg", "cat.jpg"], device),
}
model = imagebind_model.imagebind_huge(pretrained=True)
embeddings = model(inputs)
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of transformers
- Broader scope: Supports a wide range of NLP tasks and models
- Extensive documentation and community support
- Regular updates and new model implementations
Cons of transformers
- Steeper learning curve due to its extensive features
- Potentially higher computational requirements for some models
- Less focused on multimodal learning compared to ImageBind
Code Comparison
transformers:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello world!", return_tensors="pt")
outputs = model(**inputs)
ImageBind:
from imagebind import data
from imagebind.models import imagebind_model
inputs = {
ModalityType.TEXT: data.load_and_transform_text(["A dog", "A cat"], device),
ModalityType.VISION: data.load_and_transform_vision_data(["dog.jpg", "cat.jpg"], device),
}
model = imagebind_model.imagebind_huge(pretrained=True)
embeddings = model(inputs)
Both repositories offer powerful tools for working with machine learning models, but they focus on different aspects. transformers provides a comprehensive suite for various NLP tasks, while ImageBind specializes in multimodal learning across different types of data.
PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Pros of BLIP
- Focuses specifically on vision-language tasks like image captioning and visual question answering
- Provides pre-trained models for immediate use in various vision-language applications
- Offers a more streamlined approach for developers working primarily with image-text interactions
Cons of BLIP
- Limited to image and text modalities, lacking support for audio or other sensory inputs
- May require more domain-specific knowledge for optimal use in vision-language tasks
- Less versatile for projects requiring multi-modal integration beyond image and text
Code Comparison
BLIP example:
from PIL import Image
import requests
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
ImageBind example:
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text = data.load_and_transform_text(["A dog", "A cat"], device)
image = data.load_and_transform_vision_data(["dog.jpg", "cat.jpg"], device)
audio = data.load_and_transform_audio_data(["dog.wav", "cat.wav"], device)
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
with torch.no_grad():
embeddings = model({
ModalityType.TEXT: text,
ModalityType.VISION: image,
ModalityType.AUDIO: audio,
})
TensorFlow code and pre-trained models for BERT
Pros of BERT
- Widely adopted and well-established in NLP tasks
- Extensive documentation and community support
- Pre-trained models available for various languages
Cons of BERT
- Limited to text modalities only
- Requires fine-tuning for specific tasks
- Computationally intensive for large-scale applications
Code Comparison
BERT example:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
ImageBind example:
from imagebind import data
from imagebind.models import imagebind_model
model = imagebind_model.imagebind_huge(pretrained=True)
Key Differences
- ImageBind focuses on multi-modal learning, while BERT specializes in text processing
- BERT has a larger ecosystem of pre-trained models and fine-tuning scripts
- ImageBind offers a more unified approach to handling different data types (text, image, audio)
- BERT is more suitable for pure NLP tasks, while ImageBind excels in cross-modal applications
Use Cases
- BERT: Text classification, named entity recognition, question answering
- ImageBind: Multi-modal retrieval, cross-modal generation, audio-visual understanding
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
ImageBind: One Embedding Space To Bind Them All
Rohit Girdhar*, Alaaeldin El-Nouby*, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra*
To appear at CVPR 2023 (Highlighted paper)
[Paper] [Blog] [Demo] [Supplementary Video] [BibTex]
PyTorch implementation and pretrained models for ImageBind. For details, see the paper: ImageBind: One Embedding Space To Bind Them All.
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications âout-of-the-boxâ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation.
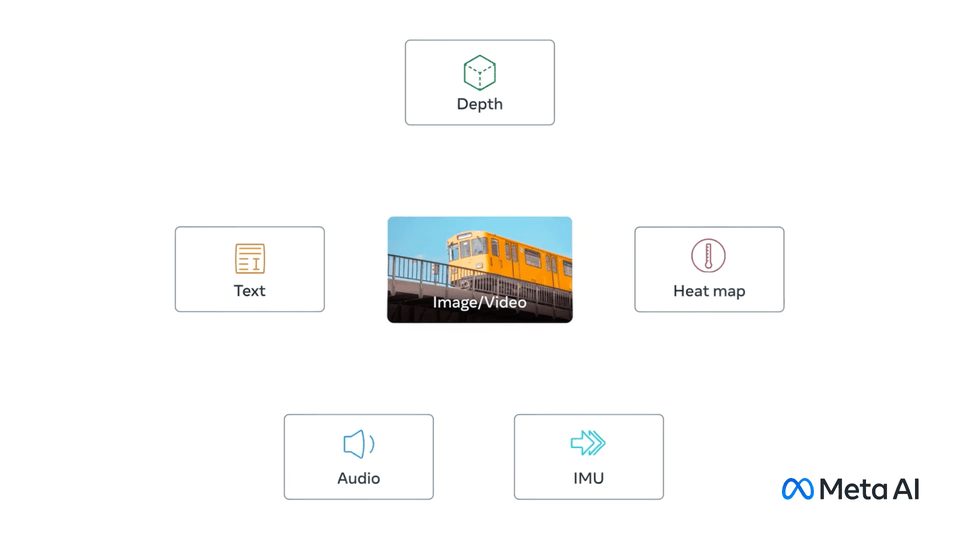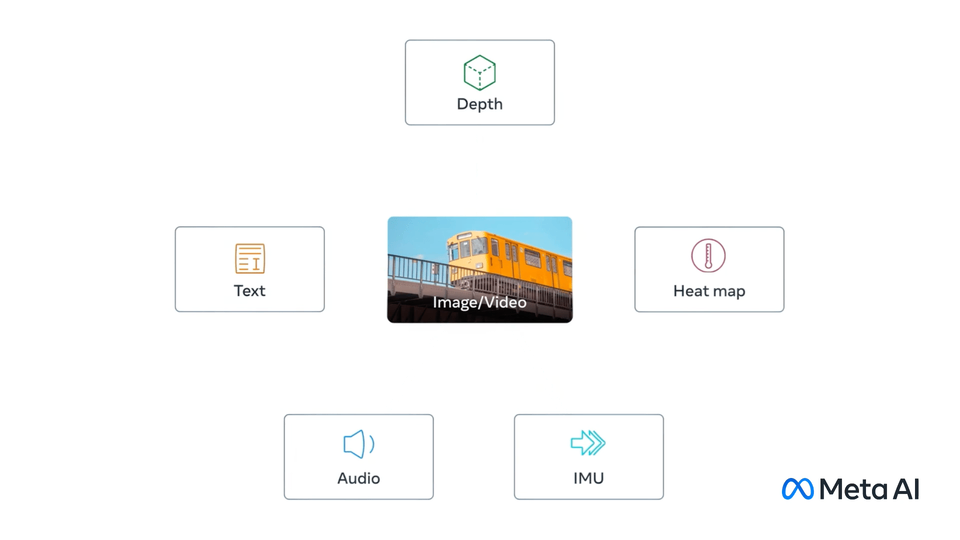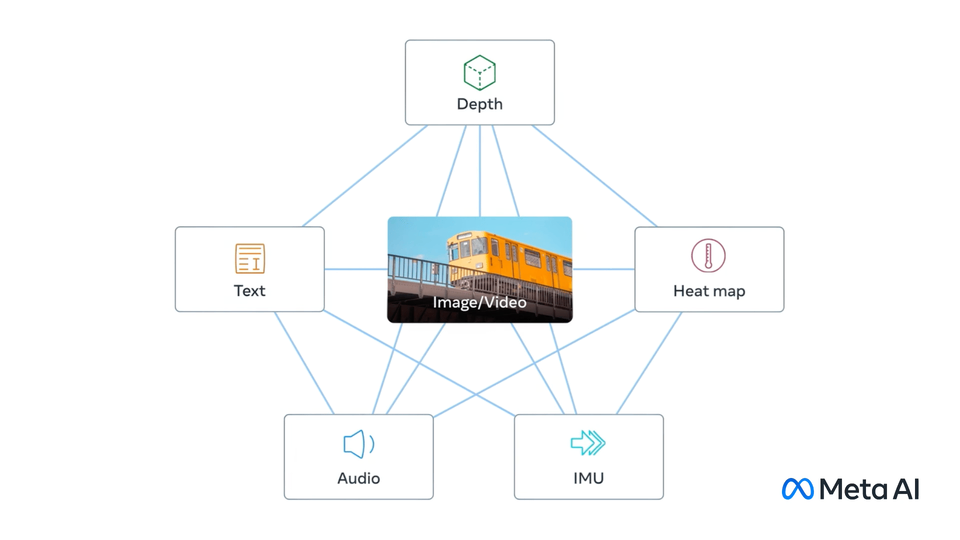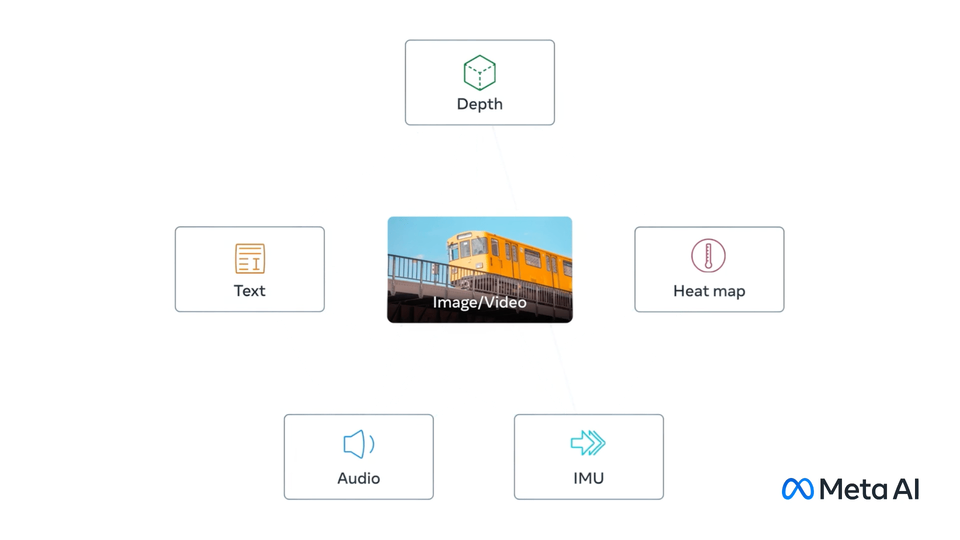
ImageBind model
Emergent zero-shot classification performance.
| Model | IN1k | K400 | NYU-D | ESC | LLVIP | Ego4D | download |
|---|---|---|---|---|---|---|---|
| imagebind_huge | 77.7 | 50.0 | 54.0 | 66.9 | 63.4 | 25.0 | checkpoint |
Usage
Install pytorch 1.13+ and other 3rd party dependencies.
conda create --name imagebind python=3.10 -y
conda activate imagebind
pip install .
For windows users, you might need to install soundfile for reading/writing audio files. (Thanks @congyue1977)
pip install soundfile
Extract and compare features across modalities (e.g. Image, Text and Audio).
from imagebind import data
import torch
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])
Model card
Please see the model card for details.
License
ImageBind code and model weights are released under the CC-BY-NC 4.0 license. See LICENSE for additional details.
Contributing
See contributing and the code of conduct.
Citing ImageBind
If you find this repository useful, please consider giving a star :star: and citation
@inproceedings{girdhar2023imagebind,
title={ImageBind: One Embedding Space To Bind Them All},
author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang
and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
booktitle={CVPR},
year={2023}
}
Top Related Projects
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
TensorFlow code and pre-trained models for BERT
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot