 segment-anything
segment-anything
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
Top Related Projects

Segment Anything in High Quality [NeurIPS 2023]

Grounded SAM: Marrying Grounding DINO with Segment Anything & Stable Diffusion & Recognize Anything - Automatically Detect , Segment and Generate Anything

This is the official code for MobileSAM project that makes SAM lightweight for mobile applications and beyond!

Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything (SAM+SAM2), MobileSAM!!

Fast Segment Anything
Quick Overview
The Segment Anything project by Meta AI Research is an advanced image segmentation model and dataset. It introduces a new task, foundation model, and dataset for image segmentation, aiming to segment any object in an image based on various types of prompts.
Pros
- Highly versatile and can segment almost any object in an image
- Supports multiple types of prompts (points, boxes, text, masks)
- Large-scale dataset with over 1 billion masks on 11 million licensed and privacy-preserving images
- Fast inference times, suitable for real-time applications
Cons
- Requires significant computational resources for training and fine-tuning
- May struggle with very small objects or highly complex scenes
- Potential for biases in the dataset, which could affect performance in certain scenarios
- Limited to 2D image segmentation, not applicable to 3D or video data
Code Examples
- Loading the model and making predictions:
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
predictor.set_image(image)
masks, _, _ = predictor.predict(point_coords=input_point, point_labels=input_label)
- Automatic mask generation:
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
- Using the model with a GUI:
from segment_anything import sam_model_registry, SamPredictor
import cv2
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
image = cv2.imread("path/to/image.jpg")
predictor.set_image(image)
# GUI code to get input points and generate masks
Getting Started
- Install the package:
pip install git+https://github.com/facebookresearch/segment-anything.git
- Download the model checkpoint:
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
- Use the model in your Python script:
from segment_anything import sam_model_registry, SamPredictor
import cv2
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
image = cv2.imread("path/to/image.jpg")
predictor.set_image(image)
# Add your segmentation logic here
Competitor Comparisons
Segment Anything in High Quality [NeurIPS 2023]
Pros of SAM-HQ
- Improved boundary quality and fine-grained details in segmentation masks
- Better performance on high-resolution images
- Maintains efficiency with similar inference speed to original SAM
Cons of SAM-HQ
- Requires additional training and fine-tuning
- May have higher computational requirements for training
- Limited availability of pre-trained models compared to original SAM
Code Comparison
SAM:
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
masks, _, _ = predictor.predict(point_coords, point_labels, box=input_box)
SAM-HQ:
from sam_hq import sam_model_registry, SamPredictor
sam_hq = sam_model_registry["vit_h"](checkpoint="sam_hq_vit_h.pth")
predictor = SamPredictor(sam_hq)
masks, _, _ = predictor.predict(point_coords, point_labels, box=input_box)
The code usage is similar, with the main difference being the import statement and the checkpoint file used. SAM-HQ requires its specific model weights for optimal performance.
Grounded SAM: Marrying Grounding DINO with Segment Anything & Stable Diffusion & Recognize Anything - Automatically Detect , Segment and Generate Anything
Pros of Grounded-Segment-Anything
- Integrates object detection and grounding capabilities, allowing for more precise segmentation based on text prompts
- Supports multi-modal inputs (image + text) for enhanced segmentation tasks
- Offers additional features like automatic labeling and panoptic segmentation
Cons of Grounded-Segment-Anything
- More complex setup and dependencies compared to Segment-Anything
- Potentially slower inference time due to additional processing steps
- May require more computational resources for running the full pipeline
Code Comparison
Segment-Anything:
from segment_anything import sam_model_registry, SamPredictor
predictor = SamPredictor(sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth"))
predictor.set_image(image)
masks, _, _ = predictor.predict(point_coords=input_point, point_labels=input_label)
Grounded-Segment-Anything:
from groundingdino.util.inference import load_model, load_image, predict
from segment_anything import sam_model_registry, SamPredictor
grounding_dino_model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "groundingdino/weights/groundingdino_swint_ogc.pth")
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
This is the official code for MobileSAM project that makes SAM lightweight for mobile applications and beyond!
Pros of MobileSAM
- Significantly smaller model size, making it more suitable for mobile and edge devices
- Faster inference time, allowing for real-time segmentation on resource-constrained hardware
- Maintains comparable accuracy to the original SAM model despite its reduced size
Cons of MobileSAM
- May have slightly lower performance on complex or highly detailed images
- Limited to a single encoder architecture, while segment-anything offers multiple options
- Potentially less robust to diverse input prompts compared to the full SAM model
Code Comparison
segment-anything:
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
MobileSAM:
from mobile_sam import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_t"](checkpoint="mobile_sam.pt")
predictor = SamPredictor(sam)
Both repositories use similar APIs, making it easy to switch between them. The main difference lies in the model architecture and checkpoint used.
Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything (SAM+SAM2), MobileSAM!!
Pros of anylabeling
- More versatile: Supports multiple AI models and labeling tasks beyond segmentation
- User-friendly interface: Provides a GUI for easier interaction and labeling
- Extensible: Allows users to add custom labeling functions and AI models
Cons of anylabeling
- Less specialized: May not offer the same level of segmentation performance as Segment Anything
- Smaller community: Has fewer contributors and stars on GitHub compared to Segment Anything
Code comparison
segment-anything:
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
predictor.set_image(image)
masks, _, _ = predictor.predict(point_coords=input_point, point_labels=input_label)
anylabeling:
from anylabeling.models import ModelManager
model_manager = ModelManager()
model = model_manager.get_model('segment_anything')
results = model.predict(image, points=input_points, labels=input_labels)
Both repositories offer powerful image segmentation capabilities, but anylabeling provides a more user-friendly and versatile approach, while Segment Anything focuses on high-performance segmentation using a specific model.
Fast Segment Anything
Pros of FastSAM
- Significantly faster inference speed (up to 50x faster than SAM)
- Smaller model size, requiring less computational resources
- Supports real-time segmentation on consumer-grade hardware
Cons of FastSAM
- Slightly lower accuracy compared to SAM in some scenarios
- Less extensive documentation and community support
- Fewer pre-trained models available
Code Comparison
FastSAM:
from fastsam import FastSAM, FastSAMPrompt
model = FastSAM('FastSAM-x.pt')
everything_results = model(image, device='cuda')
prompt_process = FastSAMPrompt(image, everything_results, device='cuda')
Segment Anything:
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
predictor = SamPredictor(sam)
predictor.set_image(image)
masks, _, _ = predictor.predict(point_coords=input_point, point_labels=input_label)
Both repositories provide powerful segmentation capabilities, but FastSAM focuses on speed and efficiency, while Segment Anything offers higher accuracy and more extensive features. The choice between them depends on the specific use case and available resources.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Latest updates -- SAM 2: Segment Anything in Images and Videos
Please check out our new release on Segment Anything Model 2 (SAM 2).
- SAM 2 code: https://github.com/facebookresearch/segment-anything-2
- SAM 2 demo: https://sam2.metademolab.com/
- SAM 2 paper: https://arxiv.org/abs/2408.00714
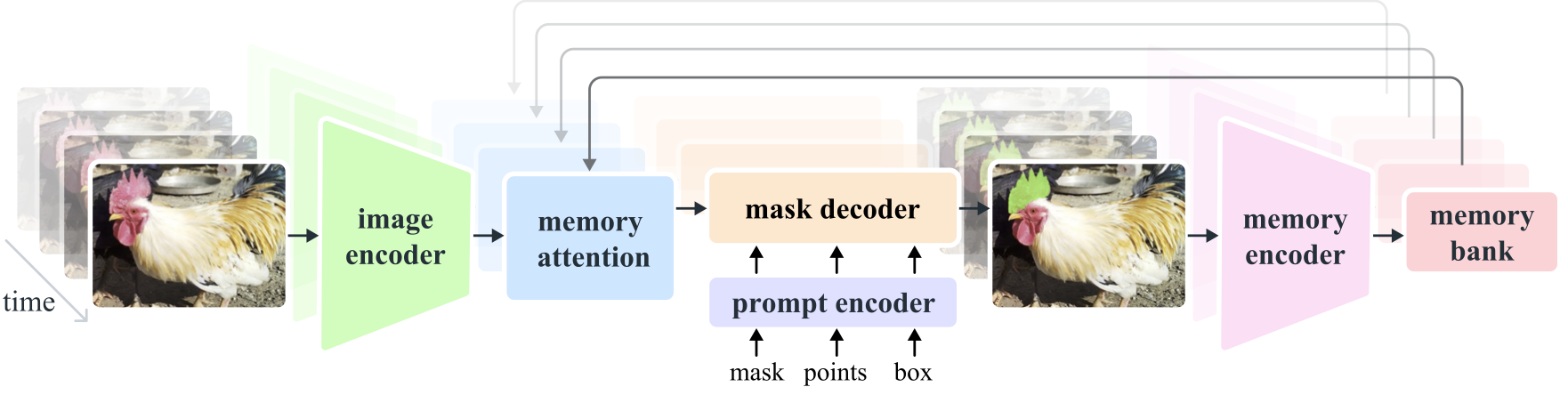
Segment Anything Model 2 (SAM 2) is a foundation model towards solving promptable visual segmentation in images and videos. We extend SAM to video by considering images as a video with a single frame. The model design is a simple transformer architecture with streaming memory for real-time video processing. We build a model-in-the-loop data engine, which improves model and data via user interaction, to collect our SA-V dataset, the largest video segmentation dataset to date. SAM 2 trained on our data provides strong performance across a wide range of tasks and visual domains.
Segment Anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[Paper] [Project] [Demo] [Dataset] [Blog] [BibTeX]

The Segment Anything Model (SAM) produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.


Installation
The code requires python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8. Please follow the instructions here to install both PyTorch and TorchVision dependencies. Installing both PyTorch and TorchVision with CUDA support is strongly recommended.
Install Segment Anything:
pip install git+https://github.com/facebookresearch/segment-anything.git
or clone the repository locally and install with
git clone git@github.com:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
The following optional dependencies are necessary for mask post-processing, saving masks in COCO format, the example notebooks, and exporting the model in ONNX format. jupyter is also required to run the example notebooks.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Getting Started
First download a model checkpoint. Then the model can be used in just a few lines to get masks from a given prompt:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
or generate masks for an entire image:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Additionally, masks can be generated for images from the command line:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
See the examples notebooks on using SAM with prompts and automatically generating masks for more details.


ONNX Export
SAM's lightweight mask decoder can be exported to ONNX format so that it can be run in any environment that supports ONNX runtime, such as in-browser as showcased in the demo. Export the model with
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
See the example notebook for details on how to combine image preprocessing via SAM's backbone with mask prediction using the ONNX model. It is recommended to use the latest stable version of PyTorch for ONNX export.
Web demo
The demo/ folder has a simple one page React app which shows how to run mask prediction with the exported ONNX model in a web browser with multithreading. Please see demo/README.md for more details.
Model Checkpoints
Three model versions of the model are available with different backbone sizes. These models can be instantiated by running
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Click the links below to download the checkpoint for the corresponding model type.
defaultorvit_h: ViT-H SAM model.vit_l: ViT-L SAM model.vit_b: ViT-B SAM model.
Dataset
See here for an overview of the datastet. The dataset can be downloaded here. By downloading the datasets you agree that you have read and accepted the terms of the SA-1B Dataset Research License.
We save masks per image as a json file. It can be loaded as a dictionary in python in the below format.
{
"image" : image_info,
"annotations" : [annotation],
}
image_info {
"image_id" : int, # Image id
"width" : int, # Image width
"height" : int, # Image height
"file_name" : str, # Image filename
}
annotation {
"id" : int, # Annotation id
"segmentation" : dict, # Mask saved in COCO RLE format.
"bbox" : [x, y, w, h], # The box around the mask, in XYWH format
"area" : int, # The area in pixels of the mask
"predicted_iou" : float, # The model's own prediction of the mask's quality
"stability_score" : float, # A measure of the mask's quality
"crop_box" : [x, y, w, h], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[x, y]], # The point coordinates input to the model to generate the mask
}
Image ids can be found in sa_images_ids.txt which can be downloaded using the above link as well.
To decode a mask in COCO RLE format into binary:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
See here for more instructions to manipulate masks stored in RLE format.
License
The model is licensed under the Apache 2.0 license.
Contributing
See contributing and the code of conduct.
Contributors
The Segment Anything project was made possible with the help of many contributors (alphabetical):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Citing Segment Anything
If you use SAM or SA-1B in your research, please use the following BibTeX entry.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
Top Related Projects
Segment Anything in High Quality [NeurIPS 2023]
Grounded SAM: Marrying Grounding DINO with Segment Anything & Stable Diffusion & Recognize Anything - Automatically Detect , Segment and Generate Anything
This is the official code for MobileSAM project that makes SAM lightweight for mobile applications and beyond!
Effortless AI-assisted data labeling with AI support from YOLO, Segment Anything (SAM+SAM2), MobileSAM!!
Fast Segment Anything
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot