
Top Related Projects

Hosting read-only SQLite databases on static file hosters like Github Pages

AlaSQL.js - JavaScript SQL database for browser and Node.js. Handles both traditional relational tables and nested JSON data (NoSQL). Export, store, and import data from localStorage, IndexedDB, or Excel.
Quick Overview
AbsurdSQL is a project that brings SQLite to the browser by compiling it to WebAssembly and providing a custom virtual file system. It allows for persistent storage of large amounts of data in the browser, with the ability to run SQL queries directly on this data.
Pros
- Enables large-scale data storage and querying in the browser
- Provides a familiar SQL interface for working with data
- Offers better performance than traditional web storage solutions for large datasets
- Supports both in-memory and persistent storage options
Cons
- Requires loading a relatively large WebAssembly module
- May have a steeper learning curve compared to simpler storage solutions
- Limited browser support for some of the underlying technologies
- Potential for increased memory usage in the browser
Code Examples
- Initializing the database:
import { initBackend } from '@jlongster/absurd-sql';
import initSqlJs from '@jlongster/sql.js';
async function init() {
const SQL = await initSqlJs({ locateFile: file => `/${file}` });
initBackend(SQL);
const db = new SQL.Database();
return db;
}
- Executing a query:
const db = await init();
db.exec(`
CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, email TEXT);
INSERT INTO users (name, email) VALUES ('John Doe', 'john@example.com');
`);
const result = db.exec('SELECT * FROM users');
console.log(result);
- Using prepared statements:
const stmt = db.prepare('INSERT INTO users (name, email) VALUES (?, ?)');
stmt.run(['Jane Smith', 'jane@example.com']);
stmt.free();
const selectStmt = db.prepare('SELECT * FROM users WHERE name = ?');
const rows = selectStmt.getAsObject(['Jane Smith']);
console.log(rows);
selectStmt.free();
Getting Started
To use AbsurdSQL in your project:
-
Install the required packages:
npm install @jlongster/absurd-sql @jlongster/sql.js -
Initialize the database in your code:
import { initBackend } from '@jlongster/absurd-sql'; import initSqlJs from '@jlongster/sql.js'; async function initDB() { const SQL = await initSqlJs({ locateFile: file => `/${file}` }); initBackend(SQL); return new SQL.Database(); } const db = await initDB(); // Now you can use 'db' to execute SQL queries -
Make sure to serve the required WebAssembly files (
sql-wasm.wasmandabsurd-sql-optimized.wasm) from your web server's root directory.
Competitor Comparisons
Hosting read-only SQLite databases on static file hosters like Github Pages
Pros of sql.js-httpvfs
- Supports virtual file system (VFS) for efficient remote database access
- Allows partial loading of large databases, reducing initial load times
- Provides a more flexible approach for handling remote SQLite databases
Cons of sql.js-httpvfs
- May have a steeper learning curve due to its VFS implementation
- Requires additional setup for remote database hosting and configuration
- Potentially higher complexity for simple use cases
Code Comparison
absurd-sql:
import initSqlJs from '@jlongster/sql.js';
import { SQLiteFS } from 'absurd-sql';
import IndexedDBBackend from 'absurd-sql/dist/indexeddb-backend';
const SQL = await initSqlJs({ locateFile: file => `/${file}` });
const sqlFS = new SQLiteFS(SQL.FS, new IndexedDBBackend());
SQL.register_for_idb(sqlFS);
sql.js-httpvfs:
import { createDbWorker } from 'sql.js-httpvfs';
const worker = await createDbWorker(
[{ from: 'inline', config: { serverMode: 'full' } }],
'/sqlite-wasm-worker.js',
'/sqlite-wasm.wasm',
'/database.sqlite3'
);
Both projects aim to enhance SQLite functionality in web browsers, but they take different approaches. absurd-sql focuses on persistent storage using IndexedDB, while sql.js-httpvfs emphasizes efficient remote database access through a virtual file system. The choice between them depends on specific project requirements and use cases.
AlaSQL.js - JavaScript SQL database for browser and Node.js. Handles both traditional relational tables and nested JSON data (NoSQL). Export, store, and import data from localStorage, IndexedDB, or Excel.
Pros of AlaSQL
- More comprehensive SQL support, including complex queries and joins
- Broader database compatibility (SQL, localStorage, IndexedDB, etc.)
- Active development and larger community support
Cons of AlaSQL
- Larger file size and potentially higher memory usage
- May be overkill for simple use cases or small datasets
- Performance might be slower for certain operations compared to AbsurdSQL
Code Comparison
AbsurdSQL:
import { initBackend } from 'absurd-sql/dist/indexeddb-main-thread';
initBackend();
const db = await sqlite3Worker1.open('mydb');
await db.exec('CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT)');
await db.exec('INSERT INTO users (name) VALUES (?)', ['John']);
AlaSQL:
import alasql from 'alasql';
alasql('CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY, name STRING)');
alasql('INSERT INTO users (name) VALUES (?)', ['John']);
const result = alasql('SELECT * FROM users');
Both libraries provide SQL-like functionality in JavaScript environments, but AbsurdSQL focuses on SQLite compatibility and performance for large datasets, while AlaSQL offers a more versatile and feature-rich SQL implementation at the cost of potentially higher resource usage.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
This is an absurd project.
It implements a backend for sql.js (sqlite3 compiled for the web) that treats IndexedDB like a disk and stores data in blocks there. That means your sqlite3 database is persisted. And not in the terrible way of reading and writing the whole image at once -- it reads and writes your db in small chunks.
It basically stores a whole database into another database. Which is absurd.
See the demo. You can also view an entire app using this here.
You should also read this blog post which explains the project in great detail.
If you like my work, feel free to buy me a coffee!
How do I use it?
You can check out the example project to get started. Or follow the steps below:
First you install the packages:
yarn add @jlongster/sql.js absurd-sql
Right now you need to use my fork of sql.js, but I'm going to open a PR and hopefully get it merged. The changes are minimal.
absurd-sql must run in a worker. This is fine because you really shouldn't be blocking the main thread anyway. So on the main thread, do this:
import { initBackend } from 'absurd-sql/dist/indexeddb-main-thread';
function init() {
let worker = new Worker(new URL('./index.worker.js', import.meta.url));
// This is only required because Safari doesn't support nested
// workers. This installs a handler that will proxy creating web
// workers through the main thread
initBackend(worker);
}
init();
Then in index.worker.js do this:
import initSqlJs from '@jlongster/sql.js';
import { SQLiteFS } from 'absurd-sql';
import IndexedDBBackend from 'absurd-sql/dist/indexeddb-backend';
async function run() {
let SQL = await initSqlJs({ locateFile: file => file });
let sqlFS = new SQLiteFS(SQL.FS, new IndexedDBBackend());
SQL.register_for_idb(sqlFS);
SQL.FS.mkdir('/sql');
SQL.FS.mount(sqlFS, {}, '/sql');
const path = '/sql/db.sqlite';
if (typeof SharedArrayBuffer === 'undefined') {
let stream = SQL.FS.open(path, 'a+');
await stream.node.contents.readIfFallback();
SQL.FS.close(stream);
}
let db = new SQL.Database(path, { filename: true });
// You might want to try `PRAGMA page_size=8192;` too!
db.exec(`
PRAGMA journal_mode=MEMORY;
`);
// Your code
}
Requirements
Because this uses SharedArrayBuffer and the Atomics API, there are some requirement for code to run.
- It must be run in a worker thread (you shouldn't block the main thread with queries anyway)
- Your server must respond with the following headers:
Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: require-corp
Those headers are required because browsers only enable SharedArrayBuffer if you tell it to isolate the process. There are potential security problems if SharedArrayBuffer was available everywhere.
Fallback mode
We do support browsers without SharedArrayBuffer (only Safari). Read more about it here: https://jlongster.com/future-sql-web#fallback-mode-without-sharedarraybuffer
There are some limitations in this mode: only one tab can be writing the database at a time. The database will never be corrupted; if multiple tabs try to write it will just throw an error (in the future it should call a handler that you provide so you can notify the user).
Performance
It consistently beats IndexedDB performance up to 10x:
Read performance: doing something like SELECT SUM(value) FROM kv:

Write performance: doing a bulk insert:
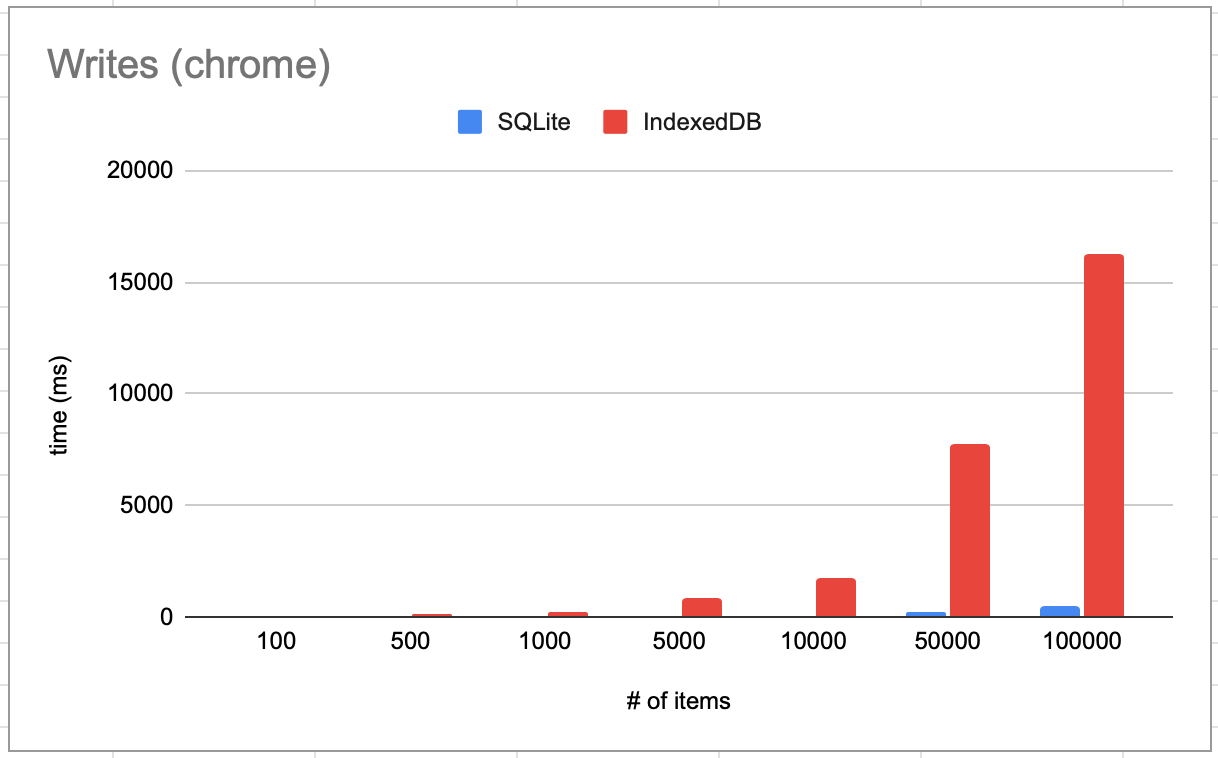
These are all on a 2015 macbook pro. Benchmark code is in src/examples/bench.
How does it work?
Read this blog post for more details.
Where you can help
There are several things that could be done:
- Add a bunch more tests
- Implement a
webkitFileSystembackend- I already started it here, but initial results showed that it was way slower?
- Bug fixes
Top Related Projects
Hosting read-only SQLite databases on static file hosters like Github Pages
AlaSQL.js - JavaScript SQL database for browser and Node.js. Handles both traditional relational tables and nested JSON data (NoSQL). Export, store, and import data from localStorage, IndexedDB, or Excel.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot