 tacotron
tacotron
A TensorFlow implementation of Google's Tacotron speech synthesis with pre-trained model (unofficial)
Top Related Projects

:robot: :speech_balloon: Deep learning for Text to Speech (Discussion forum: https://discourse.mozilla.org/c/tts)

Tacotron 2 - PyTorch implementation with faster-than-realtime inference

Clone a voice in 5 seconds to generate arbitrary speech in real-time

WaveRNN Vocoder + TTS

WaveNet vocoder

DeepMind's Tacotron-2 Tensorflow implementation
Quick Overview
Keithito/tacotron is an implementation of Google's Tacotron speech synthesis model in TensorFlow. It aims to produce high-quality speech synthesis directly from text input, utilizing a sequence-to-sequence model with attention mechanism. This project provides a complete pipeline for training and inference of text-to-speech models.
Pros
- Implements a state-of-the-art text-to-speech model with high-quality output
- Provides a complete pipeline for training and inference
- Includes pre-trained models and sample audio for quick testing
- Well-documented codebase with clear instructions for setup and usage
Cons
- Requires significant computational resources for training
- May be challenging for beginners due to the complexity of the model
- Limited language support (primarily focused on English)
- Dependency on specific versions of libraries may cause compatibility issues
Code Examples
- Synthesizing speech from text:
from synthesizer import Synthesizer
synthesizer = Synthesizer()
wav = synthesizer.synthesize("Hello, world!")
- Loading a custom model:
from synthesizer import Synthesizer
synthesizer = Synthesizer(checkpoint_path='path/to/model.ckpt')
- Adjusting synthesis parameters:
from synthesizer import Synthesizer
synthesizer = Synthesizer()
wav = synthesizer.synthesize("Hello, world!", hparams={"max_iters": 1000, "griffin_lim_iters": 60})
Getting Started
-
Clone the repository:
git clone https://github.com/keithito/tacotron.git cd tacotron -
Install dependencies:
pip install -r requirements.txt -
Download pre-trained model:
python3 demo_server.py --checkpoint pretrained -
Run the demo server:
python3 demo_server.py -
Open
localhost:9000in a web browser to interact with the model.
Competitor Comparisons
:robot: :speech_balloon: Deep learning for Text to Speech (Discussion forum: https://discourse.mozilla.org/c/tts)
Pros of TTS
- More comprehensive and actively maintained project
- Supports multiple TTS models and voice conversion techniques
- Offers pre-trained models and easy-to-use inference scripts
Cons of TTS
- More complex setup and configuration process
- Steeper learning curve for beginners
- Requires more computational resources due to its extensive features
Code Comparison
TTS:
from TTS.utils.synthesizer import Synthesizer
synthesizer = Synthesizer(
tts_checkpoint="path/to/model.pth",
tts_config_path="path/to/config.json",
vocoder_checkpoint="path/to/vocoder.pth",
vocoder_config="path/to/vocoder_config.json"
)
wav = synthesizer.tts("Hello world!")
Tacotron:
from synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.load('path/to/model.ckpt')
wav = synthesizer.synthesize('Hello world!')
TTS offers a more modular approach with separate configurations for TTS and vocoder models, while Tacotron provides a simpler interface for quick synthesis. TTS's flexibility comes at the cost of increased complexity, whereas Tacotron's simplicity may limit advanced customization options.
Tacotron 2 - PyTorch implementation with faster-than-realtime inference
Pros of Tacotron2
- Improved audio quality with WaveNet vocoder integration
- Better handling of long sentences and complex pronunciations
- Faster inference time due to optimizations
Cons of Tacotron2
- More complex architecture, requiring more computational resources
- Potentially harder to train and fine-tune for specific use cases
- May require larger datasets for optimal performance
Code Comparison
Tacotron:
def griffin_lim(spectrogram):
X_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
X_t = invert_spectrogram(X_best)
est = librosa.stft(X_t, n_fft, hop_length, win_length=win_length)
phase = est / np.maximum(1e-8, np.abs(est))
X_best = spectrogram * phase
X_t = invert_spectrogram(X_best)
y = np.real(X_t)
return y
Tacotron2:
def griffin_lim(magnitudes, n_iters=30, n_fft=1024, hop_length=256):
phase = np.exp(2j * np.pi * np.random.rand(*magnitudes.shape))
for i in range(n_iters):
stft = magnitudes * phase
y = librosa.istft(stft, hop_length=hop_length)
stft = librosa.stft(y, n_fft=n_fft, hop_length=hop_length)
phase = np.exp(1j * np.angle(stft))
return y
Both implementations use the Griffin-Lim algorithm for phase reconstruction, but Tacotron2's version is more concise and potentially more efficient.
Clone a voice in 5 seconds to generate arbitrary speech in real-time
Pros of Real-Time-Voice-Cloning
- Offers real-time voice cloning capabilities
- Includes a user-friendly interface for easy interaction
- Supports multi-speaker voice synthesis
Cons of Real-Time-Voice-Cloning
- More complex setup and dependencies
- Requires more computational resources
- May have longer processing times for voice synthesis
Code Comparison
Tacotron (Python):
def griffin_lim(spectrogram):
X_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
X_t = invert_spectrogram(X_best)
est = librosa.stft(X_t, n_fft, hop_length, win_length=win_length)
phase = est / np.maximum(1e-8, np.abs(est))
X_best = spectrogram * phase
X_t = invert_spectrogram(X_best)
y = np.real(X_t)
return y
Real-Time-Voice-Cloning (Python):
def load_model(model_dir: Path):
json_config = model_dir.joinpath("config.json")
with json_config.open() as f:
config = json.load(f)
model = SpeakerEncoder(config["model"]["hidden_size"], config["model"]["num_layers"])
checkpoint = torch.load(model_dir.joinpath("model.pt"))
model.load_state_dict(checkpoint["model_state"])
return model
WaveRNN Vocoder + TTS
Pros of WaveRNN
- Faster inference time due to efficient neural network architecture
- Higher quality audio output, especially for longer sequences
- More flexible and adaptable to different languages and accents
Cons of WaveRNN
- Requires more computational resources for training
- Less documentation and community support compared to Tacotron
- May be more challenging to fine-tune for specific use cases
Code Comparison
WaveRNN:
def forward(self, x, h):
h = self.I(x) + self.H(h)
h = F.relu(h)
return self.O(h)
Tacotron:
def forward(self, inputs, input_lengths, mel_targets=None):
embedded_inputs = self.embedding(inputs).transpose(1, 2)
encoder_outputs = self.encoder(embedded_inputs, input_lengths)
mel_outputs, alignments = self.decoder(encoder_outputs, mel_targets)
return mel_outputs, alignments
The WaveRNN code snippet shows a simpler forward pass, focusing on efficient waveform generation. In contrast, the Tacotron code demonstrates a more complex encoder-decoder architecture for text-to-speech synthesis. WaveRNN's approach allows for faster inference, while Tacotron's structure provides more control over the generated speech characteristics.
WaveNet vocoder
Pros of wavenet_vocoder
- Produces higher quality audio output with more natural-sounding speech
- Offers more flexibility in voice characteristics and speaking styles
- Supports multi-speaker synthesis out of the box
Cons of wavenet_vocoder
- Slower inference time compared to Tacotron
- Requires more computational resources for training and generation
- More complex architecture, potentially harder to fine-tune or modify
Code Comparison
Tacotron (Python):
def griffin_lim(spectrogram):
X_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
X_t = invert_spectrogram(X_best)
est = librosa.stft(X_t, n_fft, hop_length, win_length=win_length)
phase = est / np.maximum(1e-8, np.abs(est))
X_best = spectrogram * phase
X_t = invert_spectrogram(X_best)
y = np.real(X_t)
return y
wavenet_vocoder (Python):
def wavenet(x, h):
"""WaveNet layer"""
tanh_out = tf.tanh(conv1d(x, self.filter_width, self.residual_channels))
sigm_out = tf.sigmoid(conv1d(x, self.filter_width, self.residual_channels))
return tf.multiply(tanh_out, sigm_out)
The code snippets showcase different approaches: Tacotron uses the Griffin-Lim algorithm for spectrogram inversion, while wavenet_vocoder implements the core WaveNet layer for direct waveform generation.
DeepMind's Tacotron-2 Tensorflow implementation
Pros of Tacotron-2
- Implements the full Tacotron 2 architecture, including the WaveNet vocoder
- Supports both phoneme and grapheme inputs
- Includes pre-trained models and detailed documentation
Cons of Tacotron-2
- More complex setup and dependencies
- Requires more computational resources for training and inference
- May have a steeper learning curve for beginners
Code Comparison
Tacotron:
def create_hparams(hparams_string=None, verbose=False):
hparams = tf.contrib.training.HParams(
# Comma-separated list of cleaners to run on text prior to training and eval.
cleaners='english_cleaners',
# ...
)
Tacotron-2:
def create_hparams(hparams_string=None, verbose=False):
hparams = tf.contrib.training.HParams(
################################
# Experiment Parameters #
################################
epochs=500,
iters_per_checkpoint=1000,
# ...
)
Both repositories provide implementations of Tacotron for text-to-speech synthesis. Tacotron offers a simpler, more accessible implementation, while Tacotron-2 provides a more advanced and complete architecture. The choice between them depends on the user's specific requirements, available resources, and level of expertise in the field.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Tacotron
An implementation of Tacotron speech synthesis in TensorFlow.
Audio Samples
- Audio Samples from models trained using this repo.
- The first set was trained for 441K steps on the LJ Speech Dataset
- Speech started to become intelligible around 20K steps.
- The second set was trained by @MXGray for 140K steps on the Nancy Corpus.
- The first set was trained for 441K steps on the LJ Speech Dataset
Recent Updates
-
@npuichigo fixed a bug where dropout was not being applied in the prenet.
-
@begeekmyfriend created a fork that adds location-sensitive attention and the stop token from the Tacotron 2 paper. This can greatly reduce the amount of data required to train a model.
Background
In April 2017, Google published a paper, Tacotron: Towards End-to-End Speech Synthesis, where they present a neural text-to-speech model that learns to synthesize speech directly from (text, audio) pairs. However, they didn't release their source code or training data. This is an independent attempt to provide an open-source implementation of the model described in their paper.
The quality isn't as good as Google's demo yet, but hopefully it will get there someday :-). Pull requests are welcome!
Quick Start
Installing dependencies
-
Install Python 3.
-
Install the latest version of TensorFlow for your platform. For better performance, install with GPU support if it's available. This code works with TensorFlow 1.3 and later.
-
Install requirements:
pip install -r requirements.txt
Using a pre-trained model
-
Download and unpack a model:
curl https://data.keithito.com/data/speech/tacotron-20180906.tar.gz | tar xzC /tmp -
Run the demo server:
python3 demo_server.py --checkpoint /tmp/tacotron-20180906/model.ckpt -
Point your browser at localhost:9000
- Type what you want to synthesize
Training
Note: you need at least 40GB of free disk space to train a model.
-
Download a speech dataset.
The following are supported out of the box:
- LJ Speech (Public Domain)
- Blizzard 2012 (Creative Commons Attribution Share-Alike)
You can use other datasets if you convert them to the right format. See TRAINING_DATA.md for more info.
-
Unpack the dataset into
~/tacotronAfter unpacking, your tree should look like this for LJ Speech:
tacotron |- LJSpeech-1.1 |- metadata.csv |- wavsor like this for Blizzard 2012:
tacotron |- Blizzard2012 |- ATrampAbroad | |- sentence_index.txt | |- lab | |- wav |- TheManThatCorruptedHadleyburg |- sentence_index.txt |- lab |- wav -
Preprocess the data
python3 preprocess.py --dataset ljspeech- Use
--dataset blizzardfor Blizzard data
- Use
-
Train a model
python3 train.pyTunable hyperparameters are found in hparams.py. You can adjust these at the command line using the
--hparamsflag, for example--hparams="batch_size=16,outputs_per_step=2". Hyperparameters should generally be set to the same values at both training and eval time. The default hyperparameters are recommended for LJ Speech and other English-language data. See TRAINING_DATA.md for other languages. -
Monitor with Tensorboard (optional)
tensorboard --logdir ~/tacotron/logs-tacotronThe trainer dumps audio and alignments every 1000 steps. You can find these in
~/tacotron/logs-tacotron. -
Synthesize from a checkpoint
python3 demo_server.py --checkpoint ~/tacotron/logs-tacotron/model.ckpt-185000Replace "185000" with the checkpoint number that you want to use, then open a browser to
localhost:9000and type what you want to speak. Alternately, you can run eval.py at the command line:python3 eval.py --checkpoint ~/tacotron/logs-tacotron/model.ckpt-185000If you set the
--hparamsflag when training, set the same value here.
Notes and Common Issues
-
TCMalloc seems to improve training speed and avoids occasional slowdowns seen with the default allocator. You can enable it by installing it and setting
LD_PRELOAD=/usr/lib/libtcmalloc.so. With TCMalloc, you can get around 1.1 sec/step on a GTX 1080Ti. -
You can train with CMUDict by downloading the dictionary to ~/tacotron/training and then passing the flag
--hparams="use_cmudict=True"to train.py. This will allow you to pass ARPAbet phonemes enclosed in curly braces at eval time to force a particular pronunciation, e.g.Turn left on {HH AW1 S S T AH0 N} Street. -
If you pass a Slack incoming webhook URL as the
--slack_urlflag to train.py, it will send you progress updates every 1000 steps. -
Occasionally, you may see a spike in loss and the model will forget how to attend (the alignments will no longer make sense). Although it will recover eventually, it may save time to restart at a checkpoint prior to the spike by passing the
--restore_step=150000flag to train.py (replacing 150000 with a step number prior to the spike). Update: a recent fix to gradient clipping by @candlewill may have fixed this. -
During eval and training, audio length is limited to
max_iters * outputs_per_step * frame_shift_msmilliseconds. With the defaults (max_iters=200, outputs_per_step=5, frame_shift_ms=12.5), this is 12.5 seconds.If your training examples are longer, you will see an error like this:
Incompatible shapes: [32,1340,80] vs. [32,1000,80]To fix this, you can set a larger value of
max_itersby passing--hparams="max_iters=300"to train.py (replace "300" with a value based on how long your audio is and the formula above). -
Here is the expected loss curve when training on LJ Speech with the default hyperparameters:
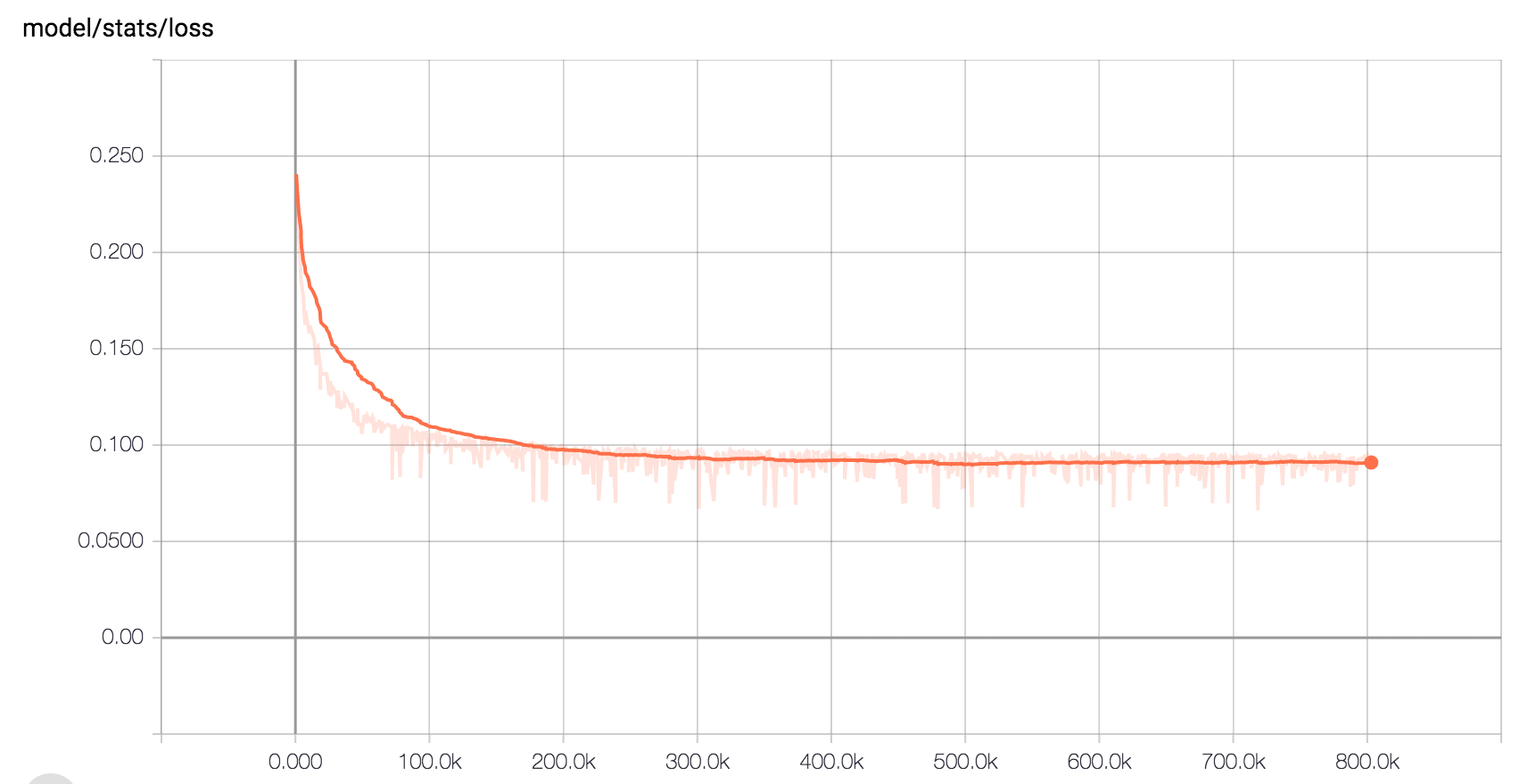
Other Implementations
- By Alex Barron: https://github.com/barronalex/Tacotron
- By Kyubyong Park: https://github.com/Kyubyong/tacotron
Top Related Projects
:robot: :speech_balloon: Deep learning for Text to Speech (Discussion forum: https://discourse.mozilla.org/c/tts)
Tacotron 2 - PyTorch implementation with faster-than-realtime inference
Clone a voice in 5 seconds to generate arbitrary speech in real-time
WaveRNN Vocoder + TTS
WaveNet vocoder
DeepMind's Tacotron-2 Tensorflow implementation
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot