
Top Related Projects

A game theoretic approach to explain the output of any machine learning model.

Fit interpretable models. Explain blackbox machine learning.

A collection of infrastructure and tools for research in neural network interpretability.

Model interpretability and understanding for PyTorch
Quick Overview
LIME (Local Interpretable Model-agnostic Explanations) is a Python library that explains the predictions of any machine learning classifier. It helps users understand complex models by providing local explanations for individual predictions, making it easier to interpret and debug machine learning models.
Pros
- Model-agnostic: Works with any machine learning model
- Provides intuitive explanations for individual predictions
- Supports various data types (text, images, tabular data)
- Helps in building trust and transparency in AI systems
Cons
- Can be computationally expensive for large datasets
- Explanations are local and may not capture global model behavior
- Results can be sensitive to the choice of parameters
- May struggle with highly non-linear models
Code Examples
- Explaining a text classifier:
from lime.lime_text import LimeTextExplainer
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
# Train a simple text classifier
vectorizer = TfidfVectorizer(lowercase=False)
clf = make_pipeline(vectorizer, MultinomialNB())
clf.fit(train_texts, train_labels)
# Create a LIME explainer
explainer = LimeTextExplainer(class_names=class_names)
# Explain a prediction
exp = explainer.explain_instance(test_text, clf.predict_proba, num_features=6)
exp.show_in_notebook()
- Explaining an image classifier:
from lime.lime_image import LimeImageExplainer
import numpy as np
# Assuming you have a trained image classifier 'model'
explainer = LimeImageExplainer()
# Explain a prediction
explanation = explainer.explain_instance(image, model.predict, top_labels=5, hide_color=0, num_samples=1000)
# Display the explanation
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
- Explaining a tabular data classifier:
from lime.lime_tabular import LimeTabularExplainer
import numpy as np
# Assuming you have a trained tabular data classifier 'model'
explainer = LimeTabularExplainer(train_data, feature_names=feature_names, class_names=class_names, discretize_continuous=True)
# Explain a prediction
exp = explainer.explain_instance(test_instance, model.predict_proba, num_features=10)
exp.show_in_notebook()
Getting Started
To get started with LIME, install it using pip:
pip install lime
Then, import the appropriate explainer for your data type:
from lime.lime_text import LimeTextExplainer
from lime.lime_image import LimeImageExplainer
from lime.lime_tabular import LimeTabularExplainer
# Choose the appropriate explainer based on your data type
explainer = LimeTextExplainer() # or LimeImageExplainer() or LimeTabularExplainer()
# Explain a prediction
explanation = explainer.explain_instance(data_instance, classifier.predict_proba, num_features=10)
explanation.show_in_notebook()
Competitor Comparisons
A game theoretic approach to explain the output of any machine learning model.
Pros of SHAP
- More theoretically grounded, based on Shapley values from game theory
- Provides both local and global explanations for model predictions
- Supports a wider range of model types, including tree-based models
Cons of SHAP
- Generally slower computation time, especially for large datasets
- Can be more complex to interpret and implement for beginners
- May require more computational resources for certain model types
Code Comparison
LIME example:
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(X_train)
exp = explainer.explain_instance(X_test[0], clf.predict_proba)
SHAP example:
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X)
Both LIME and SHAP are popular libraries for explaining machine learning model predictions. LIME focuses on local interpretability and is generally faster and easier to use, while SHAP offers a more comprehensive approach with stronger theoretical foundations. The choice between them often depends on the specific use case, model type, and desired level of explanation detail.
Fit interpretable models. Explain blackbox machine learning.
Pros of Interpret
- Offers a wider range of interpretability techniques beyond LIME, including SHAP, EBM, and more
- Provides a unified API for various explainable AI methods, making it easier to compare different approaches
- Includes interactive visualizations and dashboards for exploring model explanations
Cons of Interpret
- May have a steeper learning curve due to its more comprehensive feature set
- Could be considered "heavier" in terms of dependencies and installation compared to LIME
Code Comparison
LIME:
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(X_train)
exp = explainer.explain_instance(X_test[0], clf.predict_proba)
Interpret:
from interpret import set_visualize_provider
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)
ebm_global = ebm.explain_global()
Both libraries aim to provide model interpretability, but Interpret offers a broader range of techniques and a more unified approach. LIME focuses specifically on local interpretable model-agnostic explanations, while Interpret provides various methods for both local and global explanations. The choice between them depends on the specific needs of the project and the desired level of complexity in the interpretability analysis.
A collection of infrastructure and tools for research in neural network interpretability.
Pros of Lucid
- Focuses on neural network interpretability and visualization
- Provides advanced tools for exploring and understanding deep learning models
- Integrates well with TensorFlow and other deep learning frameworks
Cons of Lucid
- Steeper learning curve due to its focus on advanced visualization techniques
- More specialized, primarily for deep learning model interpretation
- May require more computational resources for complex visualizations
Code Comparison
LIME example:
from lime import lime_image
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(image, classifier_fn)
Lucid example:
import lucid.modelzoo.vision_models as models
import lucid.optvis.render as render
model = models.InceptionV1()
obj = model.mixed4a_3x3_pre_relu_channel_143
render.render_vis(model, obj)
Summary
LIME is a more general-purpose tool for explaining machine learning models, while Lucid specializes in deep learning model interpretation and visualization. LIME offers broader applicability across various model types, whereas Lucid provides more advanced techniques specifically for neural networks. LIME may be easier to use for beginners, while Lucid offers more powerful visualization capabilities for deep learning experts.
Model interpretability and understanding for PyTorch
Pros of Captum
- Specifically designed for PyTorch models, offering seamless integration
- Provides a wider range of interpretability methods beyond LIME
- Supports both vision and text models out of the box
Cons of Captum
- Steeper learning curve due to more complex API
- Limited to PyTorch models, less flexible for other frameworks
- Requires more computational resources for some methods
Code Comparison
LIME example:
from lime import lime_image
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(image, classifier_fn)
Captum example:
from captum.attr import IntegratedGradients
ig = IntegratedGradients(model)
attributions = ig.attribute(input, target=target_class)
Both libraries aim to provide model interpretability, but Captum offers a more comprehensive suite of tools specifically for PyTorch models. LIME is simpler to use and more framework-agnostic, while Captum provides deeper integration with PyTorch and a broader range of advanced interpretability methods. The choice between them depends on the specific use case, model framework, and desired level of analysis.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
lime

![]()
This project is about explaining what machine learning classifiers (or models) are doing. At the moment, we support explaining individual predictions for text classifiers or classifiers that act on tables (numpy arrays of numerical or categorical data) or images, with a package called lime (short for local interpretable model-agnostic explanations). Lime is based on the work presented in this paper (bibtex here for citation). Here is a link to the promo video:

Our plan is to add more packages that help users understand and interact meaningfully with machine learning.
Lime is able to explain any black box classifier, with two or more classes. All we require is that the classifier implements a function that takes in raw text or a numpy array and outputs a probability for each class. Support for scikit-learn classifiers is built-in.
Installation
The lime package is on PyPI. Simply run:
pip install lime
Or clone the repository and run:
pip install .
We dropped python2 support in 0.2.0, 0.1.1.37 was the last version before that.
Screenshots
Below are some screenshots of lime explanations. These are generated in html, and can be easily produced and embedded in ipython notebooks. We also support visualizations using matplotlib, although they don't look as nice as these ones.
Two class case, text
Negative (blue) words indicate atheism, while positive (orange) words indicate christian. The way to interpret the weights by applying them to the prediction probabilities. For example, if we remove the words Host and NNTP from the document, we expect the classifier to predict atheism with probability 0.58 - 0.14 - 0.11 = 0.31.

Multiclass case

Tabular data

Images (explaining prediction of 'Cat' in pros and cons)

Tutorials and API
For example usage for text classifiers, take a look at the following two tutorials (generated from ipython notebooks):
For classifiers that use numerical or categorical data, take a look at the following tutorial (this is newer, so please let me know if you find something wrong):
For image classifiers:
For regression:
Submodular Pick:
The raw (non-html) notebooks for these tutorials are available here.
The API reference is available here.
What are explanations?
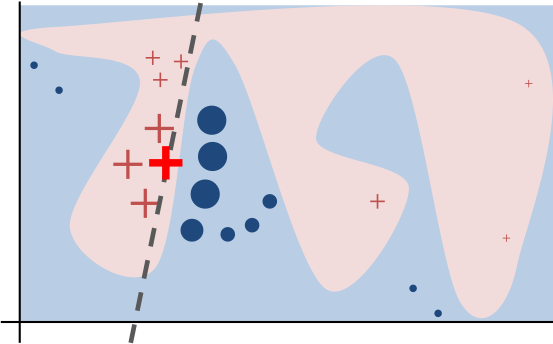
Intuitively, an explanation is a local linear approximation of the model's behaviour. While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance. While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation. The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear. The bright red cross is the instance being explained (let's call it X). We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size). We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, read our paper, or take a look at this blog post.
Contributing
Please read this.
Top Related Projects
A game theoretic approach to explain the output of any machine learning model.
Fit interpretable models. Explain blackbox machine learning.
A collection of infrastructure and tools for research in neural network interpretability.
Model interpretability and understanding for PyTorch
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot