 VIBE
VIBE
Official implementation of CVPR2020 paper "VIBE: Video Inference for Human Body Pose and Shape Estimation"
Top Related Projects

Efficient 3D human pose estimation in video using 2D keypoint trajectories

OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
Quick Overview
VIBE (Video Inference for Human Body Pose and Shape Estimation) is an open-source project for estimating 3D human pose and shape from video sequences. It combines convolutional neural networks and temporal information to produce accurate and temporally consistent 3D human body reconstructions from monocular video input.
Pros
- High accuracy in 3D human pose and shape estimation
- Temporal consistency across video frames
- Supports both single-image and video inputs
- Provides pre-trained models for easy use
Cons
- Requires significant computational resources for real-time processing
- Limited to single-person scenarios
- Dependency on external libraries and frameworks
- May struggle with complex poses or occlusions
Code Examples
- Loading and running VIBE on a video:
from lib.models.vibe import VIBE_Demo
from lib.utils.demo_utils import download_youtube_clip
vibe_demo = VIBE_Demo(
vibert_model_path='data/vibe_data/vibe_model_w_3dpw.pth.tar'
)
input_video = download_youtube_clip('https://www.youtube.com/watch?v=wPZP8Bwxplo')
output_path = 'vibe_output.mp4'
vibe_demo.run_on_video(input_video, output_path)
- Extracting SMPL parameters from a single image:
from lib.models.vibe import VIBE_Demo
from lib.utils.demo_utils import images_to_video
vibe_demo = VIBE_Demo(
vibert_model_path='data/vibe_data/vibe_model_w_3dpw.pth.tar'
)
image_path = 'path/to/your/image.jpg'
output_path = 'vibe_output_image.mp4'
images_to_video([image_path], output_path, fps=1)
vibe_output = vibe_demo.run_on_video(output_path, extract_only=True)
smpl_params = vibe_output['pred_cam'], vibe_output['pred_verts'], vibe_output['pred_pose'], vibe_output['pred_betas']
- Visualizing VIBE output:
from lib.utils.renderer import Renderer
from lib.models.smpl import SMPL
smpl = SMPL(model_path='data/vibe_data/smpl_model.pkl')
renderer = Renderer(resolution=(1024, 1024))
vertices = smpl(
global_orient=vibe_output['pred_pose'][:, :3],
body_pose=vibe_output['pred_pose'][:, 3:],
betas=vibe_output['pred_betas']
)
rendered_image = renderer.render(
vertices,
camera_translation=vibe_output['pred_cam'],
image=input_image
)
Getting Started
-
Clone the repository:
git clone https://github.com/mkocabas/VIBE.git -
Install dependencies:
cd VIBE pip install -r requirements.txt -
Download pre-trained models:
source scripts/prepare_data.sh -
Run VIBE on a video:
from lib.models.vibe import VIBE_Demo vibe_demo = VIBE_Demo() vibe_demo.run_on_video('path/to/video.mp4', 'output.mp4')
Competitor Comparisons
Efficient 3D human pose estimation in video using 2D keypoint trajectories
Pros of VideoPose3D
- Designed specifically for 3D human pose estimation from video
- Supports both 2D-to-3D pose lifting and end-to-end 3D pose estimation
- Provides pre-trained models for various datasets (Human3.6M, HumanEva)
Cons of VideoPose3D
- Requires 2D pose detections as input for some methods
- May struggle with complex motions or occlusions
- Limited to single-person pose estimation
Code Comparison
VideoPose3D:
from common.model import TemporalModel
model = TemporalModel(num_joints_in, in_features, num_joints_out, filter_widths, causal=args.causal)
VIBE:
from lib.models.vibe import VIBE
model = VIBE(
n_layers=cfg.MODEL.TGRU.NUM_LAYERS,
batch_size=cfg.TRAIN.BATCH_SIZE,
seqlen=cfg.DATASET.SEQLEN,
hidden_size=cfg.MODEL.TGRU.HIDDEN_SIZE,
pretrained=cfg.TRAIN.PRETRAINED_REGRESSOR
)
Both repositories focus on 3D human pose estimation, but VIBE offers a more end-to-end approach with temporal modeling and SMPL integration. VideoPose3D provides flexibility in input formats and supports both 2D-to-3D lifting and direct 3D estimation. The code snippets show the different model initialization approaches, with VIBE using a more complex configuration structure.
OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
Pros of OpenPose
- Real-time multi-person keypoint detection
- Supports 2D and 3D pose estimation
- Extensive documentation and community support
Cons of OpenPose
- Higher computational requirements
- Limited to keypoint detection, not full 3D mesh reconstruction
- Requires careful setup and dependencies management
Code Comparison
OpenPose:
#include <openpose/pose/poseExtractor.hpp>
auto poseExtractor = op::PoseExtractorCaffe::getInstance(poseModel, netInputSize, outputSize, keypointScaleMode, num_gpu_start);
poseExtractor->forwardPass(netInputArray, imageSize, scaleInputToNetInputs);
VIBE:
from lib.models.vibe import VIBE_Demo
vibe_model = VIBE_Demo(
seqlen=16,
n_layers=2,
hidden_size=1024,
)
pred_cam, pred_verts, pred_pose, pred_betas, pred_joints3d, smpl_joints2d = vibe_model(input_img)
OpenPose focuses on keypoint detection using C++, while VIBE provides a more comprehensive 3D human pose and shape estimation using Python. OpenPose offers real-time performance and multi-person detection, but VIBE excels in producing full 3D mesh reconstructions. The choice between them depends on the specific requirements of the project, such as real-time capabilities, 3D mesh needs, and computational resources available.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
VIBE: Video Inference for Human Body Pose and Shape Estimation [CVPR-2020]
![]()
![]()


Check our YouTube videos below for more details.
| Paper Video | Qualitative Results |
|---|---|
 |  |
VIBE: Video Inference for Human Body Pose and Shape Estimation,
Muhammed Kocabas, Nikos Athanasiou, Michael J. Black,
IEEE Computer Vision and Pattern Recognition, 2020
Features
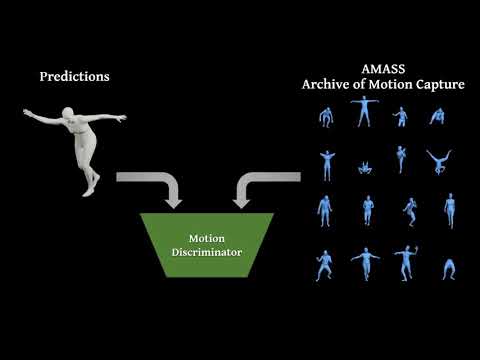
Video Inference for Body Pose and Shape Estimation (VIBE) is a video pose and shape estimation method. It predicts the parameters of SMPL body model for each frame of an input video. Pleaser refer to our arXiv report for further details.
This implementation:
- has the demo and training code for VIBE implemented purely in PyTorch,
- can work on arbitrary videos with multiple people,
- supports both CPU and GPU inference (though GPU is way faster),
- is fast, up-to 30 FPS on a RTX2080Ti (see this table),
- achieves SOTA results on 3DPW and MPI-INF-3DHP datasets,
- includes Temporal SMPLify implementation.
- includes the training code and detailed instruction on how to train it from scratch.
- can create an FBX/glTF output to be used with major graphics softwares.


Updates
- 05/01/2021: Windows installation tutorial is added thanks to amazing @carlosedubarreto
- 06/10/2020: Support OneEuroFilter smoothing.
- 14/09/2020: FBX/glTF conversion script is released.
Getting Started
VIBE has been implemented and tested on Ubuntu 18.04 with python >= 3.7. It supports both GPU and CPU inference. If you don't have a suitable device, try running our Colab demo.
Clone the repo:
git clone https://github.com/mkocabas/VIBE.git
Install the requirements using virtualenv or conda:
# pip
source scripts/install_pip.sh
# conda
source scripts/install_conda.sh
Running the Demo
We have prepared a nice demo code to run VIBE on arbitrary videos. First, you need download the required data(i.e our trained model and SMPL model parameters). To do this you can just run:
source scripts/prepare_data.sh
Then, running the demo is as simple as:
# Run on a local video
python demo.py --vid_file sample_video.mp4 --output_folder output/ --display
# Run on a YouTube video
python demo.py --vid_file https://www.youtube.com/watch?v=wPZP8Bwxplo --output_folder output/ --display
Refer to doc/demo.md for more details about the demo code.
Sample demo output with the --sideview flag:

FBX and glTF output (New Feature!)
We provide a script to convert VIBE output to standalone FBX/glTF files to be used in 3D graphics tools like Blender, Unity etc. You need to follow steps below to be able to run the conversion script.
- You need to download FBX files for SMPL body model
- Go to SMPL website and create an account.
- Download the Unity-compatible FBX file through the link
- Unzip the contents and locate them
data/SMPL_unity_v.1.0.0.
- Install Blender python API
- Note that we tested our script with Blender v2.8.0 and v2.8.3.
- Run the command below to convert VIBE output to FBX:
python lib/utils/fbx_output.py \
--input output/sample_video/vibe_output.pkl \
--output output/sample_video/fbx_output.fbx \ # specify the file extension as *.glb for glTF
--fps_source 30 \
--fps_target 30 \
--gender <male or female> \
--person_id <tracklet id from VIBE output>
Windows Installation Tutorial
You can follow the instructions provided by @carlosedubarreto to install and run VIBE on a Windows machine:
- VIBE windows installation tutorial: https://youtu.be/3qhs5IRJ1LI
- FBX conversion: https://youtu.be/w1biKeiQThY
- Helper github repo: https://github.com/carlosedubarreto/vibe_win_install
Google Colab
If you do not have a suitable environment to run this project then you could give Google Colab a try.
It allows you to run the project in the cloud, free of charge. You may try our Colab demo using the notebook we have prepared:
![]()
Training
Run the commands below to start training:
source scripts/prepare_training_data.sh
python train.py --cfg configs/config.yaml
Note that the training datasets should be downloaded and prepared before running data processing script.
Please see doc/train.md for details on how to prepare them.
Evaluation
Here we compare VIBE with recent state-of-the-art methods on 3D pose estimation datasets. Evaluation metric is Procrustes Aligned Mean Per Joint Position Error (PA-MPJPE) in mm.
| Models | 3DPW ↓ | MPI-INF-3DHP ↓ | H36M ↓ |
|---|---|---|---|
| SPIN | 59.2 | 67.5 | 41.1 |
| Temporal HMR | 76.7 | 89.8 | 56.8 |
| VIBE | 56.5 | 63.4 | 41.5 |
See doc/eval.md to reproduce the results in this table or
evaluate a pretrained model.
Correction: Due to a mistake in dataset preprocessing, VIBE trained with 3DPW results in Table 1 of the original paper are not correct. Besides, even though training with 3DPW guarantees better quantitative performance, it does not give good qualitative results. ArXiv version will be updated with the corrected results.
Citation
@inproceedings{kocabas2019vibe,
title={VIBE: Video Inference for Human Body Pose and Shape Estimation},
author={Kocabas, Muhammed and Athanasiou, Nikos and Black, Michael J.},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
License
This code is available for non-commercial scientific research purposes as defined in the LICENSE file. By downloading and using this code you agree to the terms in the LICENSE. Third-party datasets and software are subject to their respective licenses.
References
We indicate if a function or script is borrowed externally inside each file. Here are some great resources we benefit:
- Pretrained HMR and some functions are borrowed from SPIN.
- SMPL models and layer is from SMPL-X model.
- Some functions are borrowed from Temporal HMR.
- Some functions are borrowed from HMR-pytorch.
- Some functions are borrowed from Kornia.
- Pose tracker is from STAF.
Top Related Projects
Efficient 3D human pose estimation in video using 2D keypoint trajectories
OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot