
Top Related Projects

An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.

Adaptive Experimentation Platform

Ray is an AI compute engine. Ray consists of a core distributed runtime and a set of AI Libraries for accelerating ML workloads.

Distributed Asynchronous Hyperparameter Optimization in Python

Sequential model-based optimization with a `scipy.optimize` interface

Open source platform for the machine learning lifecycle
Quick Overview
Optuna is an open-source hyperparameter optimization framework for machine learning, designed to automate the process of finding optimal hyperparameters for various algorithms. It employs state-of-the-art Bayesian optimization techniques and provides a simple, efficient, and versatile interface for researchers and practitioners.
Pros
- Efficient optimization algorithms, including Tree-structured Parzen Estimator (TPE) and Hyperband
- Easy integration with popular machine learning frameworks like PyTorch, TensorFlow, and scikit-learn
- Supports multi-objective optimization and distributed optimization
- Extensive visualization tools for analyzing optimization results
Cons
- Learning curve for advanced features and customization
- May require more computational resources compared to manual tuning for simple problems
- Limited support for certain specialized machine learning domains
- Occasional stability issues in distributed environments
Code Examples
- Basic usage with scikit-learn:
import optuna
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
def objective(trial):
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
C = trial.suggest_loguniform('C', 1e-5, 1e5)
gamma = trial.suggest_loguniform('gamma', 1e-5, 1e5)
clf = SVC(C=C, gamma=gamma)
clf.fit(X_train, y_train)
return clf.score(X_test, y_test)
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print('Best trial:')
trial = study.best_trial
print(' Value: ', trial.value)
print(' Params: ')
for key, value in trial.params.items():
print(' {}: {}'.format(key, value))
- Multi-objective optimization:
import optuna
def objective(trial):
x = trial.suggest_float('x', -5, 5)
y = trial.suggest_float('y', -5, 5)
return x**2, (y - 2)**2
study = optuna.create_study(directions=['minimize', 'minimize'])
study.optimize(objective, n_trials=50)
print('Pareto front:')
for trial in study.best_trials:
print(f' x={trial.params["x"]:.3f}, y={trial.params["y"]:.3f}')
print(f' Objectives: {trial.values}')
- Pruning unpromising trials:
import optuna
def objective(trial):
for i in range(100):
intermediate_value = (i - 50) ** 2
trial.report(intermediate_value, i)
if trial.should_prune():
raise optuna.TrialPruned()
return intermediate_value
study = optuna.create_study()
study.optimize(objective, n_trials=20)
print('Best trial:')
print(' Value: ', study.best_trial.value)
print(' Params: ', study.best_trial.params)
Getting Started
To get started with Optuna, follow these steps:
- Install Optuna:
pip install optuna
- Import Optuna and define an objective function:
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
print('Best value: ', study.best_value)
print('Best params: ', study.best_params)
- Run the optimization and analyze the results using Optuna's built-in visualization tools or custom analysis.
Competitor Comparisons
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
Pros of NNI
- Offers a wider range of built-in tuning algorithms and supports neural architecture search
- Provides a web UI for experiment management and visualization
- Includes features for model compression and feature engineering
Cons of NNI
- Steeper learning curve due to more complex architecture and features
- Less integration with popular ML frameworks compared to Optuna
- Requires more setup and configuration for basic usage
Code Comparison
Optuna example:
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
NNI example:
import nni
@nni.trial
def trial(params):
x = params['x']
return {'default': (x - 2) ** 2}
if __name__ == '__main__':
nni.run(search_space={'x': {'_type': 'uniform', '_value': [-10, 10]}})
Both libraries aim to simplify hyperparameter optimization, but NNI offers a broader range of features at the cost of increased complexity. Optuna focuses on simplicity and ease of use, making it more accessible for beginners and straightforward optimization tasks.
Adaptive Experimentation Platform
Pros of Ax
- More advanced Bayesian optimization algorithms, including multi-objective optimization
- Integrated with PyTorch for neural network tuning
- Robust visualization tools for experiment results
Cons of Ax
- Steeper learning curve due to more complex API
- Less flexible for non-machine learning optimization tasks
- Fewer built-in pruning algorithms compared to Optuna
Code Comparison
Optuna:
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
Ax:
from ax import optimize
def evaluation_function(parameters):
x = parameters['x']
return {'objective': (x - 2) ** 2}
best_parameters, _, _ = optimize(
parameters=[{'name': 'x', 'type': 'range', 'bounds': [-10, 10]}],
evaluation_function=evaluation_function,
minimize=True,
)
Both libraries offer powerful optimization capabilities, but Ax focuses more on advanced Bayesian techniques and integration with PyTorch, while Optuna provides a more flexible and user-friendly approach for general hyperparameter optimization tasks.
Ray is an AI compute engine. Ray consists of a core distributed runtime and a set of AI Libraries for accelerating ML workloads.
Pros of Ray
- Broader scope: Ray is a general-purpose distributed computing framework, offering more functionality beyond hyperparameter optimization
- Scalability: Designed for large-scale distributed computing, making it suitable for big data and machine learning tasks
- Ecosystem: Extensive library of tools and integrations for various ML and AI tasks
Cons of Ray
- Complexity: Steeper learning curve due to its broader feature set and distributed nature
- Resource requirements: May be overkill for smaller projects or single-machine optimization tasks
- Setup overhead: Requires more configuration and infrastructure setup compared to Optuna
Code Comparison
Ray (distributed hyperparameter tuning):
import ray
from ray import tune
def objective(config):
return config["x"] ** 2
analysis = tune.run(
objective,
config={"x": tune.uniform(0, 10)}
)
Optuna (simple hyperparameter optimization):
import optuna
def objective(trial):
x = trial.suggest_uniform('x', 0, 10)
return x ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
Distributed Asynchronous Hyperparameter Optimization in Python
Pros of Hyperopt
- More mature project with longer history and established user base
- Supports distributed optimization across multiple machines
- Flexible search space definition with a powerful domain-specific language
Cons of Hyperopt
- Less active development and fewer recent updates
- Steeper learning curve and more complex API
- Limited built-in visualization tools
Code Comparison
Hyperopt:
from hyperopt import fmin, tpe, hp
def objective(x):
return x**2
best = fmin(
fn=objective,
space=hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=100
)
Optuna:
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return x**2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
Both Hyperopt and Optuna are powerful hyperparameter optimization libraries, but they differ in their approach and features. Hyperopt offers more flexibility in search space definition and distributed optimization, while Optuna provides a more user-friendly API and better visualization tools. The choice between the two depends on specific project requirements and user preferences.
Sequential model-based optimization with a `scipy.optimize` interface
Pros of scikit-optimize
- More focused on Bayesian optimization techniques
- Provides a wider range of acquisition functions
- Integrates well with scikit-learn ecosystem
Cons of scikit-optimize
- Less active development and community support
- Limited support for distributed optimization
- Fewer built-in visualization tools
Code Comparison
scikit-optimize:
from skopt import gp_minimize
def objective(x):
return (x[0] - 3)**2 + (x[1] + 2)**2
res = gp_minimize(objective, [(-5.0, 5.0), (-5.0, 5.0)], n_calls=50)
Optuna:
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -5, 5)
y = trial.suggest_uniform('y', -5, 5)
return (x - 3)**2 + (y + 2)**2
study = optuna.create_study()
study.optimize(objective, n_trials=50)
Both libraries offer powerful optimization capabilities, but Optuna provides a more user-friendly API and better support for hyperparameter optimization in machine learning workflows. scikit-optimize excels in Bayesian optimization scenarios and offers more control over the optimization process. The choice between the two depends on the specific requirements of your project and your familiarity with the respective ecosystems.
Open source platform for the machine learning lifecycle
Pros of MLflow
- Comprehensive end-to-end ML lifecycle management
- Strong integration with various ML frameworks and tools
- Robust experiment tracking and model versioning capabilities
Cons of MLflow
- Steeper learning curve due to broader feature set
- Heavier setup and infrastructure requirements
- Less focused on hyperparameter optimization compared to Optuna
Code Comparison
MLflow example:
import mlflow
with mlflow.start_run():
mlflow.log_param("alpha", 0.5)
mlflow.log_metric("accuracy", 0.85)
mlflow.sklearn.log_model(model, "model")
Optuna example:
import optuna
def objective(trial):
alpha = trial.suggest_float("alpha", 0.0, 1.0)
# Train model and return accuracy
return accuracy
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
MLflow provides a more comprehensive approach to ML experiment tracking and model management, while Optuna focuses specifically on hyperparameter optimization. MLflow's code emphasizes logging parameters, metrics, and models, whereas Optuna's code demonstrates its strength in defining and optimizing hyperparameters through trials.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Optuna: A hyperparameter optimization framework


![]()
![]()
:link: Website | :page_with_curl: Docs | :gear: Install Guide | :pencil: Tutorial | :bulb: Examples | Twitter | LinkedIn | Medium
Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning. It features an imperative, define-by-run style user API. Thanks to our define-by-run API, the code written with Optuna enjoys high modularity, and the user of Optuna can dynamically construct the search spaces for the hyperparameters.
:loudspeaker: News
Help us create the next version of Optuna!
Optuna 5.0 Roadmap published for review. Please take a look at the planned improvements to Optuna, and share your feedback in the github issues. PR contributions also welcome!
Please take a few minutes to fill in this survey, and let us know how you use Optuna now and what improvements you'd like.ð¤ All questions are optional. ðââï¸
- Jun 16, 2025: Optuna 4.4.0 has been released! Check out the release blog.
- May 26, 2025: Optuna 5.0 roadmap has been published! See the blog for more details.
- Apr 14, 2025: Optuna 4.3.0 are out! Check out the release note for details.
- Mar 24, 2025: A new article Distributed Optimization in Optuna and gRPC Storage Proxy has been published.
- Mar 11, 2025: A new article [Optuna v4.2] Gaussian Process-Based Sampler Can Now Handle Inequality Constraints has been published.
- Feb 17, 2025: A new article SMAC3 Registered on OptunaHub has been published.
:fire: Key Features
Optuna has modern functionalities as follows:
- Lightweight, versatile, and platform agnostic architecture
- Handle a wide variety of tasks with a simple installation that has few requirements.
- Pythonic search spaces
- Define search spaces using familiar Python syntax including conditionals and loops.
- Efficient optimization algorithms
- Adopt state-of-the-art algorithms for sampling hyperparameters and efficiently pruning unpromising trials.
- Easy parallelization
- Scale studies to tens or hundreds of workers with little or no changes to the code.
- Quick visualization
- Inspect optimization histories from a variety of plotting functions.
Basic Concepts
We use the terms study and trial as follows:
- Study: optimization based on an objective function
- Trial: a single execution of the objective function
Please refer to the sample code below. The goal of a study is to find out the optimal set of
hyperparameter values (e.g., regressor and svr_c) through multiple trials (e.g.,
n_trials=100). Optuna is a framework designed for automation and acceleration of
optimization studies.
Sample code with scikit-learn
![]()
import optuna
import sklearn
# Define an objective function to be minimized.
def objective(trial):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial.suggest_categorical("regressor", ["SVR", "RandomForest"])
if regressor_name == "SVR":
svr_c = trial.suggest_float("svr_c", 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32)
regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth)
X, y = sklearn.datasets.fetch_california_housing(return_X_y=True)
X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0)
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
error = sklearn.metrics.mean_squared_error(y_val, y_pred)
return error # An objective value linked with the Trial object.
study = optuna.create_study() # Create a new study.
study.optimize(objective, n_trials=100) # Invoke optimization of the objective function.
[!NOTE] More examples can be found in optuna/optuna-examples.
The examples cover diverse problem setups such as multi-objective optimization, constrained optimization, pruning, and distributed optimization.
Installation
Optuna is available at the Python Package Index and on Anaconda Cloud.
# PyPI
$ pip install optuna
# Anaconda Cloud
$ conda install -c conda-forge optuna
[!IMPORTANT] Optuna supports Python 3.8 or newer.
Also, we provide Optuna docker images on DockerHub.
Integrations
Optuna has integration features with various third-party libraries. Integrations can be found in optuna/optuna-integration and the document is available here.
Supported integration libraries
Web Dashboard
Optuna Dashboard is a real-time web dashboard for Optuna. You can check the optimization history, hyperparameter importance, etc. in graphs and tables. You don't need to create a Python script to call Optuna's visualization functions. Feature requests and bug reports are welcome!
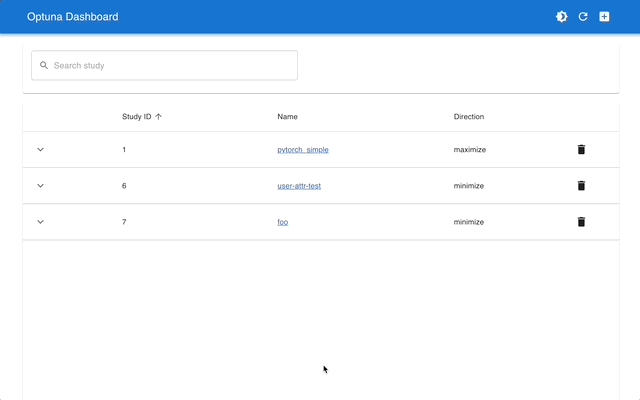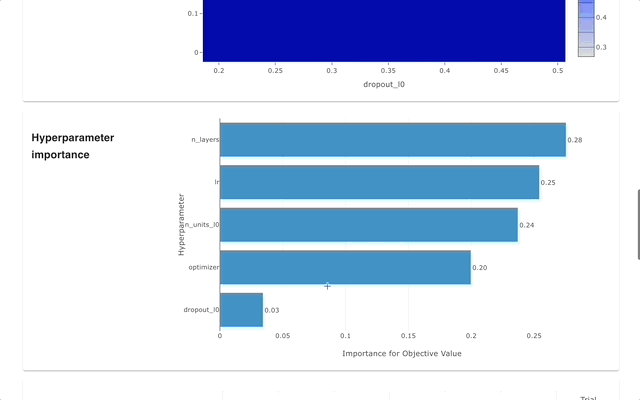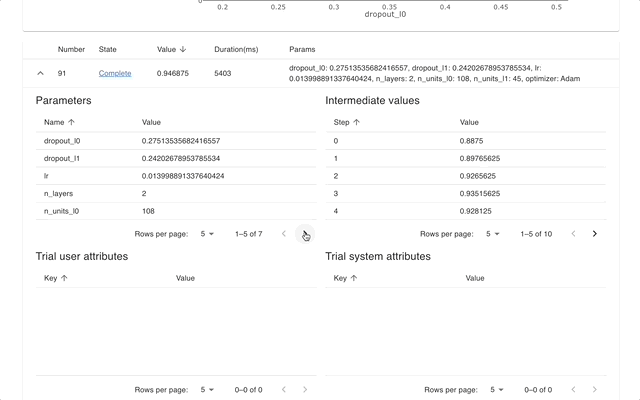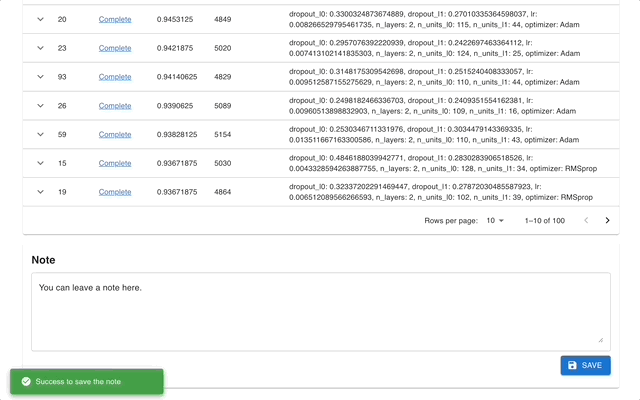
optuna-dashboard can be installed via pip:
$ pip install optuna-dashboard
[!TIP] Please check out the convenience of Optuna Dashboard using the sample code below.
Sample code to launch Optuna Dashboard
Save the following code as optimize_toy.py.
import optuna
def objective(trial):
x1 = trial.suggest_float("x1", -100, 100)
x2 = trial.suggest_float("x2", -100, 100)
return x1**2 + 0.01 * x2**2
study = optuna.create_study(storage="sqlite:///db.sqlite3") # Create a new study with database.
study.optimize(objective, n_trials=100)
Then try the commands below:
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.
OptunaHub
OptunaHub is a feature-sharing platform for Optuna. You can use the registered features and publish your packages.
Use registered features
optunahub can be installed via pip:
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu
You can load registered module with optunahub.load_module.
import optuna
import optunahub
def objective(trial: optuna.Trial) -> float:
x = trial.suggest_float("x", -5, 5)
y = trial.suggest_float("y", -5, 5)
return x**2 + y**2
module = optunahub.load_module(package="samplers/auto_sampler")
study = optuna.create_study(sampler=module.AutoSampler())
study.optimize(objective, n_trials=10)
print(study.best_trial.value, study.best_trial.params)
For more details, please refer to the optunahub documentation.
Publish your packages
You can publish your package via optunahub-registry. See the Tutorials for Contributors in OptunaHub.
Communication
- GitHub Discussions for questions.
- GitHub Issues for bug reports and feature requests.
Contribution
Any contributions to Optuna are more than welcome!
If you are new to Optuna, please check the good first issues. They are relatively simple, well-defined, and often good starting points for you to get familiar with the contribution workflow and other developers.
If you already have contributed to Optuna, we recommend the other contribution-welcome issues.
For general guidelines on how to contribute to the project, take a look at CONTRIBUTING.md.
Reference
If you use Optuna in one of your research projects, please cite our KDD paper "Optuna: A Next-generation Hyperparameter Optimization Framework":
BibTeX
@inproceedings{akiba2019optuna,
title={{O}ptuna: A Next-Generation Hyperparameter Optimization Framework},
author={Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori},
booktitle={The 25th ACM SIGKDD International Conference on Knowledge Discovery \& Data Mining},
pages={2623--2631},
year={2019}
}
License
MIT License (see LICENSE).
Optuna uses the codes from SciPy and fdlibm projects (see LICENSE_THIRD_PARTY).
Top Related Projects
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
Adaptive Experimentation Platform
Ray is an AI compute engine. Ray consists of a core distributed runtime and a set of AI Libraries for accelerating ML workloads.
Distributed Asynchronous Hyperparameter Optimization in Python
Sequential model-based optimization with a `scipy.optimize` interface
Open source platform for the machine learning lifecycle
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot