 httpx
httpx
httpx is a fast and multi-purpose HTTP toolkit that allows running multiple probes using the retryablehttp library.
Top Related Projects

Take a list of domains and probe for working HTTP and HTTPS servers

Directory/File, DNS and VHost busting tool written in Go

Fast web fuzzer written in Go

A Tool for Domain Flyovers

Gospider - Fast web spider written in Go

Simple, fast web crawler designed for easy, quick discovery of endpoints and assets within a web application
Quick Overview
httpx is a fast and multi-purpose HTTP toolkit that allows running multiple probes using the retryablehttp library. It is designed to maintain the result reliability with increased threads. httpx is used to run multiple probes and is optimized for speed and reliability in large-scale scanning scenarios.
Pros
- Fast and efficient, capable of handling large-scale HTTP probing
- Supports multiple probe types and customizable output formats
- Actively maintained with regular updates and improvements
- Cross-platform compatibility (Windows, Linux, macOS)
Cons
- Steep learning curve for advanced features
- May trigger security alerts or be blocked by some web servers due to its scanning nature
- Limited documentation for some advanced use cases
- Potential for misuse if not used responsibly
Getting Started
To install httpx, you can use Go's package manager:
go install -v github.com/projectdiscovery/httpx/cmd/httpx@latest
Basic usage example:
echo example.com | httpx
# Or for multiple URLs:
cat urls.txt | httpx
For more advanced usage, you can use various flags:
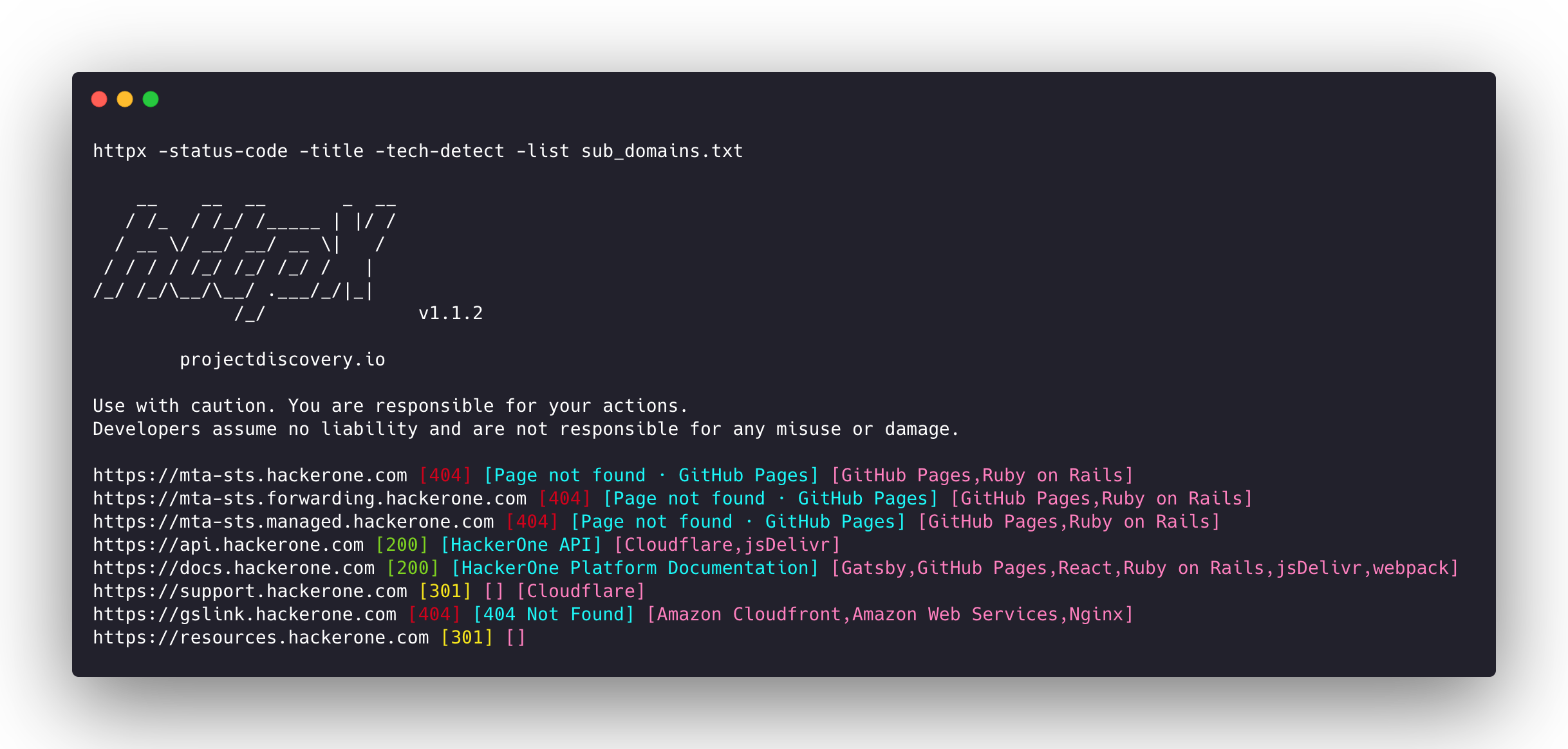
httpx -l urls.txt -title -content-length -status-code -silent
This command will probe the URLs from the file, displaying the title, content length, and status code of each response in silent mode.
Competitor Comparisons
Take a list of domains and probe for working HTTP and HTTPS servers
Pros of httprobe
- Lightweight and fast, with minimal dependencies
- Simple to use with straightforward command-line options
- Efficient for quick probing of large lists of domains
Cons of httprobe
- Limited feature set compared to httpx
- Lacks advanced probing capabilities and customization options
- No built-in support for additional protocols or advanced HTTP features
Code Comparison
httprobe:
func probeHttp(domain string, timeout time.Duration) (string, error) {
client := &http.Client{
Timeout: timeout,
Transport: &http.Transport{
TLSClientConfig: &tls.Config{InsecureSkipVerify: true},
},
}
// ... (rest of the function)
}
httpx:
func (r *Runner) DoHTTP(ctx context.Context, req *retryablehttp.Request, host string) (*httpx.Response, error) {
var resp *http.Response
var err error
if r.options.Unsafe {
resp, err = r.unsafeClient.Do(req)
} else {
resp, err = r.client.Do(req)
}
// ... (rest of the function)
}
Both tools serve similar purposes but differ in complexity and feature set. httprobe is more focused on simplicity and speed for basic HTTP probing, while httpx offers a wider range of features and customization options for more advanced use cases in web reconnaissance and security testing.
Directory/File, DNS and VHost busting tool written in Go
Pros of gobuster
- More focused on directory and file brute-forcing
- Supports DNS subdomain enumeration
- Offers VHost discovery functionality
Cons of gobuster
- Less versatile in terms of HTTP probing capabilities
- Slower performance for large-scale scanning
- Limited output format options
Code Comparison
gobuster:
func main() {
flag.Parse()
globalopts := libgobuster.ParseGlobalOptions()
plugin, err := libgobuster.GetPlugin(globalopts)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
}
httpx:
func main() {
options := runner.ParseOptions()
runner, err := runner.New(options)
if err != nil {
gologger.Fatal().Msgf("Could not create runner: %s\n", err)
}
runner.Run()
}
Both tools use a similar structure for parsing options and running the main functionality. However, httpx focuses on HTTP probing and analysis, while gobuster is more specialized in brute-forcing directories and subdomains. httpx offers more extensive HTTP-related features and faster performance for large-scale scanning, whereas gobuster provides specific functionalities like DNS subdomain enumeration and VHost discovery.
Fast web fuzzer written in Go
Pros of ffuf
- Faster performance for large-scale fuzzing tasks
- More customizable output formats and filtering options
- Built-in wordlist management and mutation features
Cons of ffuf
- Limited protocol support (primarily HTTP/HTTPS)
- Less comprehensive probe and analysis capabilities
- Steeper learning curve for advanced features
Code Comparison
ffuf:
matcher := ffuf.NewMatcher(options.Matchers, options.Filters, false)
for result := range results {
if matcher.Filter(result) {
printResult(result, options)
}
}
httpx:
for _, target := range targets {
resp, err := httpx.Do(target, httpx.Options{})
if err != nil {
continue
}
printResult(resp)
}
ffuf is primarily designed for web fuzzing and directory brute-forcing, offering advanced features for these specific tasks. It excels in performance and customization for fuzzing workflows.
httpx, on the other hand, is a more versatile HTTP toolkit with broader protocol support and analysis capabilities. It's better suited for general-purpose HTTP probing and information gathering across diverse targets.
While ffuf provides more specialized fuzzing features, httpx offers a more accessible and flexible approach for various HTTP-related tasks, making it easier to integrate into diverse security workflows and automation pipelines.
A Tool for Domain Flyovers
Pros of Aquatone
- Provides visual screenshots of web pages, useful for quick visual analysis
- Offers a more comprehensive web fingerprinting approach
- Includes domain takeover checks as part of its functionality
Cons of Aquatone
- Less actively maintained compared to httpx
- Slower performance when scanning large numbers of targets
- Limited customization options for output formats
Code Comparison
Aquatone (Ruby):
def run_scan(targets)
targets.each do |target|
screenshot = take_screenshot(target)
fingerprint = fingerprint_web_technology(target)
check_domain_takeover(target)
end
end
httpx (Go):
func runScan(targets []string) {
for _, target := range targets {
resp, err := httpx.Do(httpx.Request{URL: target})
if err != nil {
continue
}
// Process response
}
}
Both tools serve different purposes within the web reconnaissance domain. Aquatone focuses on visual analysis and comprehensive fingerprinting, while httpx prioritizes speed and efficiency for large-scale HTTP probing. The choice between them depends on specific use cases and requirements.
Gospider - Fast web spider written in Go
Pros of gospider
- More comprehensive web crawling and spidering capabilities
- Built-in support for extracting various types of data (e.g., subdomains, JavaScript files, AWS S3 buckets)
- Concurrent crawling for improved performance
Cons of gospider
- Less focused on HTTP probing and analysis compared to httpx
- May require more configuration for specific use cases
- Potentially slower for simple HTTP probing tasks
Code Comparison
gospider:
crawler := colly.NewCollector(
colly.AllowedDomains(domain),
colly.MaxDepth(depth),
colly.Async(true),
)
httpx:
options := httpx.DefaultOptions
options.RetryMax = 2
runner, err := httpx.New(&options)
gospider focuses on web crawling with the Colly library, while httpx is designed for efficient HTTP probing and analysis. gospider offers more extensive crawling features, making it suitable for comprehensive web scraping tasks. On the other hand, httpx excels in quick HTTP probing and information gathering from web servers.
gospider's strength lies in its ability to extract various types of data during crawling, which can be valuable for reconnaissance. However, this broader focus may make it less efficient for simple HTTP probing tasks compared to httpx.
httpx's streamlined approach to HTTP analysis makes it more suitable for rapid scanning and probing of multiple targets, while gospider's crawling capabilities are better suited for in-depth exploration of specific websites or domains.
Simple, fast web crawler designed for easy, quick discovery of endpoints and assets within a web application
Pros of hakrawler
- Focuses on crawling and discovering URLs, making it more specialized for web crawling tasks
- Supports JavaScript rendering for dynamic content discovery
- Includes features like custom headers and cookies for authenticated crawling
Cons of hakrawler
- Less versatile compared to httpx, which offers a broader range of HTTP-related functionalities
- May have slower performance when dealing with large-scale scanning due to its crawling nature
- Limited to web crawling and doesn't provide extensive HTTP probing capabilities
Code Comparison
hakrawler:
func crawl(url string, depth int, c chan string) {
if depth >= *maxDepth {
return
}
// ... (crawling logic)
}
httpx:
func (s *Store) URL(url string) (*urlutil.URL, error) {
// ... (URL processing logic)
}
The code snippets highlight the different focus areas of the two tools. hakrawler's code revolves around crawling functionality, while httpx emphasizes URL processing and HTTP interactions.
Both tools are valuable for different aspects of web reconnaissance and security testing. hakrawler excels in discovering and mapping web application structures, while httpx provides a more comprehensive set of HTTP-related features for probing and analyzing web servers and applications.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()




Features ⢠Installation ⢠Usage ⢠Documentation ⢠Notes ⢠Join Discord
httpx is a fast and multi-purpose HTTP toolkit that allows running multiple probes using the retryablehttp library. It is designed to maintain result reliability with an increased number of threads.
Features
- Simple and modular code base making it easy to contribute.
- Fast And fully configurable flags to probe multiple elements.
- Supports multiple HTTP based probings.
- Smart auto fallback from https to http as default.
- Supports hosts, URLs and CIDR as input.
- Handles edge cases doing retries, backoffs etc for handling WAFs.
Supported probes
| Probes | Default check | Probes | Default check |
|---|---|---|---|
| URL | true | IP | true |
| Title | true | CNAME | true |
| Status Code | true | Raw HTTP | false |
| Content Length | true | HTTP2 | false |
| TLS Certificate | true | HTTP Pipeline | false |
| CSP Header | true | Virtual host | false |
| Line Count | true | Word Count | true |
| Location Header | true | CDN | false |
| Web Server | true | Paths | false |
| Web Socket | true | Ports | false |
| Response Time | true | Request Method | true |
| Favicon Hash | false | Probe Status | false |
| Body Hash | true | Header Hash | true |
| Redirect chain | false | URL Scheme | true |
| JARM Hash | false | ASN | false |
Installation Instructions
httpx requires go1.21 to install successfully. Run the following command to get the repo:
go install -v github.com/projectdiscovery/httpx/cmd/httpx@latest
To learn more about installing httpx, see https://docs.projectdiscovery.io/tools/httpx/install.
| :exclamation: Disclaimer |
|---|
| This project is in active development. Expect breaking changes with releases. Review the changelog before updating. |
| This project was primarily built to be used as a standalone CLI tool. Running it as a service may pose security risks. It's recommended to use with caution and additional security measures. |
Usage
httpx -h
This will display help for the tool. Here are all the switches it supports.
Usage:
./httpx [flags]
Flags:
httpx is a fast and multi-purpose HTTP toolkit that allows running multiple probes using the retryablehttp library.
Usage:
./httpx [flags]
Flags:
INPUT:
-l, -list string input file containing list of hosts to process
-rr, -request string file containing raw request
-u, -target string[] input target host(s) to probe
PROBES:
-sc, -status-code display response status-code
-cl, -content-length display response content-length
-ct, -content-type display response content-type
-location display response redirect location
-favicon display mmh3 hash for '/favicon.ico' file
-hash string display response body hash (supported: md5,mmh3,simhash,sha1,sha256,sha512)
-jarm display jarm fingerprint hash
-rt, -response-time display response time
-lc, -line-count display response body line count
-wc, -word-count display response body word count
-title display page title
-bp, -body-preview display first N characters of response body (default 100)
-server, -web-server display server name
-td, -tech-detect display technology in use based on wappalyzer dataset
-method display http request method
-websocket display server using websocket
-ip display host ip
-cname display host cname
-extract-fqdn, -efqdn get domain and subdomains from response body and header in jsonl/csv output
-asn display host asn information
-cdn display cdn/waf in use (default true)
-probe display probe status
HEADLESS:
-ss, -screenshot enable saving screenshot of the page using headless browser
-system-chrome enable using local installed chrome for screenshot
-ho, -headless-options string[] start headless chrome with additional options
-esb, -exclude-screenshot-bytes enable excluding screenshot bytes from json output
-no-screenshot-full-page disable saving full page screenshot
-ehb, -exclude-headless-body enable excluding headless header from json output
-st, -screenshot-timeout value set timeout for screenshot in seconds (default 10s)
-sid, -screenshot-idle value set idle time before taking screenshot in seconds (default 1s)
MATCHERS:
-mc, -match-code string match response with specified status code (-mc 200,302)
-ml, -match-length string match response with specified content length (-ml 100,102)
-mlc, -match-line-count string match response body with specified line count (-mlc 423,532)
-mwc, -match-word-count string match response body with specified word count (-mwc 43,55)
-mfc, -match-favicon string[] match response with specified favicon hash (-mfc 1494302000)
-ms, -match-string string[] match response with specified string (-ms admin)
-mr, -match-regex string[] match response with specified regex (-mr admin)
-mcdn, -match-cdn string[] match host with specified cdn provider (cloudfront, fastly, google)
-mrt, -match-response-time string match response with specified response time in seconds (-mrt '< 1')
-mdc, -match-condition string match response with dsl expression condition
EXTRACTOR:
-er, -extract-regex string[] display response content with matched regex
-ep, -extract-preset string[] display response content matched by a pre-defined regex (url,ipv4,mail)
FILTERS:
-fc, -filter-code string filter response with specified status code (-fc 403,401)
-fep, -filter-error-page filter response with ML based error page detection
-fd, -filter-duplicates filter out near-duplicate responses (only first response is retained)
-fl, -filter-length string filter response with specified content length (-fl 23,33)
-flc, -filter-line-count string filter response body with specified line count (-flc 423,532)
-fwc, -filter-word-count string filter response body with specified word count (-fwc 423,532)
-ffc, -filter-favicon string[] filter response with specified favicon hash (-ffc 1494302000)
-fs, -filter-string string[] filter response with specified string (-fs admin)
-fe, -filter-regex string[] filter response with specified regex (-fe admin)
-fcdn, -filter-cdn string[] filter host with specified cdn provider (cloudfront, fastly, google)
-frt, -filter-response-time string filter response with specified response time in seconds (-frt '> 1')
-fdc, -filter-condition string filter response with dsl expression condition
-strip strips all tags in response. supported formats: html,xml (default html)
RATE-LIMIT:
-t, -threads int number of threads to use (default 50)
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minute
MISCELLANEOUS:
-pa, -probe-all-ips probe all the ips associated with same host
-p, -ports string[] ports to probe (nmap syntax: eg http:1,2-10,11,https:80)
-path string path or list of paths to probe (comma-separated, file)
-tls-probe send http probes on the extracted TLS domains (dns_name)
-csp-probe send http probes on the extracted CSP domains
-tls-grab perform TLS(SSL) data grabbing
-pipeline probe and display server supporting HTTP1.1 pipeline
-http2 probe and display server supporting HTTP2
-vhost probe and display server supporting VHOST
-ldv, -list-dsl-variables list json output field keys name that support dsl matcher/filter
UPDATE:
-up, -update update httpx to latest version
-duc, -disable-update-check disable automatic httpx update check
OUTPUT:
-o, -output string file to write output results
-oa, -output-all filename to write output results in all formats
-sr, -store-response store http response to output directory
-srd, -store-response-dir string store http response to custom directory
-ob, -omit-body omit response body in output
-csv store output in csv format
-csvo, -csv-output-encoding string define output encoding
-j, -json store output in JSONL(ines) format
-irh, -include-response-header include http response (headers) in JSON output (-json only)
-irr, -include-response include http request/response (headers + body) in JSON output (-json only)
-irrb, -include-response-base64 include base64 encoded http request/response in JSON output (-json only)
-include-chain include redirect http chain in JSON output (-json only)
-store-chain include http redirect chain in responses (-sr only)
-svrc, -store-vision-recon-cluster include visual recon clusters (-ss and -sr only)
-pr, -protocol string protocol to use (unknown, http11)
-fepp, -filter-error-page-path string path to store filtered error pages (default "filtered_error_page.json")
CONFIGURATIONS:
-config string path to the httpx configuration file (default $HOME/.config/httpx/config.yaml)
-r, -resolvers string[] list of custom resolver (file or comma separated)
-allow string[] allowed list of IP/CIDR's to process (file or comma separated)
-deny string[] denied list of IP/CIDR's to process (file or comma separated)
-sni, -sni-name string custom TLS SNI name
-random-agent enable Random User-Agent to use (default true)
-H, -header string[] custom http headers to send with request
-http-proxy, -proxy string http proxy to use (eg http://127.0.0.1:8080)
-unsafe send raw requests skipping golang normalization
-resume resume scan using resume.cfg
-fr, -follow-redirects follow http redirects
-maxr, -max-redirects int max number of redirects to follow per host (default 10)
-fhr, -follow-host-redirects follow redirects on the same host
-rhsts, -respect-hsts respect HSTS response headers for redirect requests
-vhost-input get a list of vhosts as input
-x string request methods to probe, use 'all' to probe all HTTP methods
-body string post body to include in http request
-s, -stream stream mode - start elaborating input targets without sorting
-sd, -skip-dedupe disable dedupe input items (only used with stream mode)
-ldp, -leave-default-ports leave default http/https ports in host header (eg. http://host:80 - https://host:443
-ztls use ztls library with autofallback to standard one for tls13
-no-decode avoid decoding body
-tlsi, -tls-impersonate enable experimental client hello (ja3) tls randomization
-no-stdin Disable Stdin processing
-hae, -http-api-endpoint string experimental http api endpoint
DEBUG:
-health-check, -hc run diagnostic check up
-debug display request/response content in cli
-debug-req display request content in cli
-debug-resp display response content in cli
-version display httpx version
-stats display scan statistic
-profile-mem string optional httpx memory profile dump file
-silent silent mode
-v, -verbose verbose mode
-si, -stats-interval int number of seconds to wait between showing a statistics update (default: 5)
-nc, -no-color disable colors in cli output
-tr, -trace trace
OPTIMIZATIONS:
-nf, -no-fallback display both probed protocol (HTTPS and HTTP)
-nfs, -no-fallback-scheme probe with protocol scheme specified in input
-maxhr, -max-host-error int max error count per host before skipping remaining path/s (default 30)
-e, -exclude string[] exclude host matching specified filter ('cdn', 'private-ips', cidr, ip, regex)
-retries int number of retries
-timeout int timeout in seconds (default 10)
-delay value duration between each http request (eg: 200ms, 1s) (default -1ns)
-rsts, -response-size-to-save int max response size to save in bytes (default 2147483647)
-rstr, -response-size-to-read int max response size to read in bytes (default 2147483647)
CLOUD:
-auth configure projectdiscovery cloud (pdcp) api key (default true)
-ac, -auth-config string configure projectdiscovery cloud (pdcp) api key credential file
-pd, -dashboard upload / view output in projectdiscovery cloud (pdcp) UI dashboard
-tid, -team-id string upload asset results to given team id (optional)
-aid, -asset-id string upload new assets to existing asset id (optional)
-aname, -asset-name string assets group name to set (optional)
-pdu, -dashboard-upload string upload httpx output file (jsonl) in projectdiscovery cloud (pdcp) UI dashboard
Running httpx
For details about running httpx, see https://docs.projectdiscovery.io/tools/httpx/running.
Using httpx as a library
httpx can be used as a library by creating an instance of the Option struct and populating it with the same options that would be specified via CLI. Once validated, the struct should be passed to a runner instance (to be closed at the end of the program) and the RunEnumeration method should be called. A minimal example of how to do it is in the examples folder
Notes
- As default,
httpxprobe with HTTPS scheme and fall-back to HTTP only if HTTPS is not reachable. - The
-no-fallbackflag can be used to probe and display both HTTP and HTTPS result. - Custom scheme for ports can be defined, for example
-ports http:443,http:80,https:8443 - Custom resolver supports multiple protocol (doh|tcp|udp) in form of
protocol:resolver:port(e.g.udp:127.0.0.1:53) - The following flags should be used for specific use cases instead of running them as default with other probes:
-ports-path-vhost-screenshot-csp-probe-tls-probe-favicon-http2-pipeline-tls-impersonate
Acknowledgement
Probing feature is inspired by @tomnomnom/httprobe work â¤ï¸
httpx is made with ð by the projectdiscovery team and distributed under MIT License.

Top Related Projects
Take a list of domains and probe for working HTTP and HTTPS servers
Directory/File, DNS and VHost busting tool written in Go
Fast web fuzzer written in Go
A Tool for Domain Flyovers
Gospider - Fast web spider written in Go
Simple, fast web crawler designed for easy, quick discovery of endpoints and assets within a web application
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot