 LLMs-from-scratch
LLMs-from-scratch
Implement a ChatGPT-like LLM in PyTorch from scratch, step by step
Top Related Projects

The simplest, fastest repository for training/finetuning medium-sized GPTs.

���🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.

Code for the paper "Language Models are Unsupervised Multitask Learners"

TensorFlow code and pre-trained models for BERT

DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.

Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Quick Overview
"LLMs-from-scratch" is a GitHub repository by Sebastian Raschka that provides a comprehensive guide to building Large Language Models (LLMs) from scratch. It offers a step-by-step approach to understanding and implementing LLMs, covering various aspects from basic concepts to advanced techniques.
Pros
- Detailed explanations and implementations of LLM concepts
- Hands-on approach with practical code examples
- Covers a wide range of topics, from basics to advanced techniques
- Regularly updated with new content and improvements
Cons
- May be challenging for absolute beginners in machine learning
- Requires significant computational resources for some advanced models
- Focuses primarily on PyTorch, which may not suit users of other frameworks
- Some advanced topics might require additional background knowledge
Code Examples
- Tokenization example:
import torch
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(WordLevel(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
trainer = WordLevelTrainer(special_tokens=["[UNK]", "[PAD]", "[BOS]", "[EOS]"])
tokenizer.train_from_iterator(["Hello world", "How are you"], trainer=trainer)
encoded = tokenizer.encode("Hello how are you")
print(encoded.tokens)
- Simple language model training:
import torch
import torch.nn as nn
class SimpleLanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
embedded = self.embedding(x)
output, _ = self.rnn(embedded)
return self.fc(output)
model = SimpleLanguageModel(vocab_size=1000, embedding_dim=128, hidden_dim=256)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
- Attention mechanism implementation:
import torch
import torch.nn as nn
class Attention(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.attn = nn.Linear(hidden_dim * 2, hidden_dim)
self.v = nn.Linear(hidden_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs):
batch_size = encoder_outputs.shape[0]
src_len = encoder_outputs.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
attention = self.v(energy).squeeze(2)
return torch.softmax(attention, dim=1)
attention = Attention(hidden_dim=256)
Getting Started
To get started with the LLMs-from-scratch project:
-
Clone the repository:
git clone https://github.com/rasbt/LLMs-from-scratch.git cd LLMs-from-scratch -
Install the required dependencies:
pip install -r requirements.txt -
Navigate through the notebooks in the repository, starting with the introductory ones and progressing to more advanced topics.
-
Run the Jupyter notebooks to interact with the code and experiments:
jupyter notebook
Competitor Comparisons
The simplest, fastest repository for training/finetuning medium-sized GPTs.
Pros of nanoGPT
- More focused on performance and efficiency, suitable for production use
- Implements advanced features like flash attention and rotary embeddings
- Provides a complete training pipeline, including data preparation and model evaluation
Cons of nanoGPT
- Less educational focus, may be harder for beginners to understand
- Fewer explanatory comments and documentation compared to LLMs-from-scratch
- More complex codebase with additional optimizations and features
Code Comparison
nanoGPT:
class LayerNorm(nn.Module):
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
LLMs-from-scratch:
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-5):
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(d_model))
self.bias = nn.Parameter(torch.zeros(d_model))
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.alpha * (x - mean) / (std + self.eps) + self.bias
Both implementations showcase a LayerNorm module, but nanoGPT's version is more concise and uses PyTorch's built-in layer_norm function for efficiency.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of transformers
- Comprehensive library with support for numerous pre-trained models
- Extensive documentation and community support
- Seamless integration with popular deep learning frameworks
Cons of transformers
- Steeper learning curve for beginners
- Larger codebase and dependencies
- May be overkill for simple projects or educational purposes
Code comparison
LLMs-from-scratch:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
transformers:
class BertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
Code for the paper "Language Models are Unsupervised Multitask Learners"
Pros of GPT-2
- Fully trained and ready-to-use model
- Extensive documentation and community support
- Proven performance in various NLP tasks
Cons of GPT-2
- Large model size, requiring significant computational resources
- Less flexibility for customization and experimentation
- Potential for misuse due to its powerful generation capabilities
Code Comparison
GPT-2:
import tensorflow as tf
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
LLMs-from-scratch:
import torch
from scratch_llm import LLM
model = LLM(vocab_size=10000, d_model=512, nhead=8, num_layers=6)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
The GPT-2 repository provides a pre-trained model that can be easily loaded and used, while LLMs-from-scratch offers a more educational approach, allowing users to build and train language models from the ground up. GPT-2 is better suited for production use and advanced NLP tasks, whereas LLMs-from-scratch is ideal for learning and experimentation with model architectures and training processes.
TensorFlow code and pre-trained models for BERT
Pros of BERT
- Highly optimized and production-ready implementation
- Extensive documentation and pre-trained models available
- Widely adopted in industry and research communities
Cons of BERT
- More complex codebase, potentially harder for beginners to understand
- Focused specifically on BERT architecture, less flexible for exploring other LLM types
- Requires more computational resources to train and fine-tune
Code Comparison
BERT (TensorFlow):
import tensorflow as tf
from bert import modeling
input_ids = tf.placeholder(tf.int32, shape=[None, max_seq_length])
input_mask = tf.placeholder(tf.int32, shape=[None, max_seq_length])
segment_ids = tf.placeholder(tf.int32, shape=[None, max_seq_length])
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
LLMs-from-scratch (PyTorch):
import torch
from model import GPT
model = GPT(
vocab_size=vocab_size,
n_embd=n_embd,
n_head=n_head,
n_layer=n_layer,
block_size=block_size,
dropout=dropout
)
logits, loss = model(x, y)
The BERT repository provides a more comprehensive implementation, while LLMs-from-scratch offers a simpler, educational approach to building language models from the ground up.
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
Pros of DeepSpeed
- Highly optimized for large-scale distributed training
- Supports various optimization techniques like ZeRO, pipeline parallelism, and 3D parallelism
- Integrates well with popular deep learning frameworks like PyTorch and Hugging Face
Cons of DeepSpeed
- Steeper learning curve due to its complexity and advanced features
- May be overkill for smaller projects or individual researchers
- Requires more setup and configuration compared to simpler implementations
Code Comparison
LLMs-from-scratch:
class SimpleLLM(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = TransformerBlock(d_model)
DeepSpeed:
model = MyLargeModel()
model_engine, optimizer, _, _ = deepspeed.initialize(
args=args,
model=model,
model_parameters=model.parameters(),
config=ds_config
)
LLMs-from-scratch focuses on educational purposes, providing a clear and simple implementation of LLM components. It's ideal for learning and understanding the fundamentals of language models.
DeepSpeed, on the other hand, is designed for production-level, large-scale training of deep learning models. It offers advanced optimization techniques and distributed training capabilities, making it suitable for training massive language models efficiently across multiple GPUs or nodes.
Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Pros of fairseq
- More comprehensive and feature-rich, supporting a wide range of NLP tasks
- Highly optimized for performance and scalability
- Extensive documentation and community support
Cons of fairseq
- Steeper learning curve due to its complexity
- Requires more computational resources
- Less focused on educational purposes or step-by-step implementation
Code Comparison
fairseq:
from fairseq.models.transformer import TransformerModel
model = TransformerModel.from_pretrained('/path/to/model', 'checkpoint.pt')
tokens = model.encode('Hello world!')
output = model.generate(tokens)
LLMs-from-scratch:
from llms_from_scratch import Transformer
model = Transformer(vocab_size=10000, d_model=512, nhead=8)
output = model.forward(input_ids)
fairseq offers a more production-ready approach with pre-trained models and high-level APIs, while LLMs-from-scratch provides a more educational, ground-up implementation. fairseq is better suited for large-scale projects and research, whereas LLMs-from-scratch is ideal for learning and understanding the fundamentals of language models.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Build a Large Language Model (From Scratch)
This repository contains the code for developing, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch).

In Build a Large Language Model (From Scratch), you'll learn and understand how large language models (LLMs) work from the inside out by coding them from the ground up, step by step. In this book, I'll guide you through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT. In addition, this book includes code for loading the weights of larger pretrained models for finetuning.
- Link to the official source code repository
- Link to the book at Manning (the publisher's website)
- Link to the book page on Amazon.com
- ISBN 9781633437166

To download a copy of this repository, click on the Download ZIP button or execute the following command in your terminal:
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git
(If you downloaded the code bundle from the Manning website, please consider visiting the official code repository on GitHub at https://github.com/rasbt/LLMs-from-scratch for the latest updates.)
Table of Contents
Please note that this README.md file is a Markdown (.md) file. If you have downloaded this code bundle from the Manning website and are viewing it on your local computer, I recommend using a Markdown editor or previewer for proper viewing. If you haven't installed a Markdown editor yet, MarkText is a good free option.
You can alternatively view this and other files on GitHub at https://github.com/rasbt/LLMs-from-scratch in your browser, which renders Markdown automatically.
Tip: If you're seeking guidance on installing Python and Python packages and setting up your code environment, I suggest reading the README.md file located in the setup directory.
![]()
![]()
![]()
| Chapter Title | Main Code (for Quick Access) | All Code + Supplementary |
|---|---|---|
| Setup recommendations | - | - |
| Ch 1: Understanding Large Language Models | No code | - |
| Ch 2: Working with Text Data | - ch02.ipynb - dataloader.ipynb (summary) - exercise-solutions.ipynb | ./ch02 |
| Ch 3: Coding Attention Mechanisms | - ch03.ipynb - multihead-attention.ipynb (summary) - exercise-solutions.ipynb | ./ch03 |
| Ch 4: Implementing a GPT Model from Scratch | - ch04.ipynb - gpt.py (summary) - exercise-solutions.ipynb | ./ch04 |
| Ch 5: Pretraining on Unlabeled Data | - ch05.ipynb - gpt_train.py (summary) - gpt_generate.py (summary) - exercise-solutions.ipynb | ./ch05 |
| Ch 6: Finetuning for Text Classification | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb | ./ch06 |
| Ch 7: Finetuning to Follow Instructions | - ch07.ipynb - gpt_instruction_finetuning.py (summary) - ollama_evaluate.py (summary) - exercise-solutions.ipynb | ./ch07 |
| Appendix A: Introduction to PyTorch | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb | ./appendix-A |
| Appendix B: References and Further Reading | No code | - |
| Appendix C: Exercise Solutions | No code | - |
| Appendix D: Adding Bells and Whistles to the Training Loop | - appendix-D.ipynb | ./appendix-D |
| Appendix E: Parameter-efficient Finetuning with LoRA | - appendix-E.ipynb | ./appendix-E |
The mental model below summarizes the contents covered in this book.
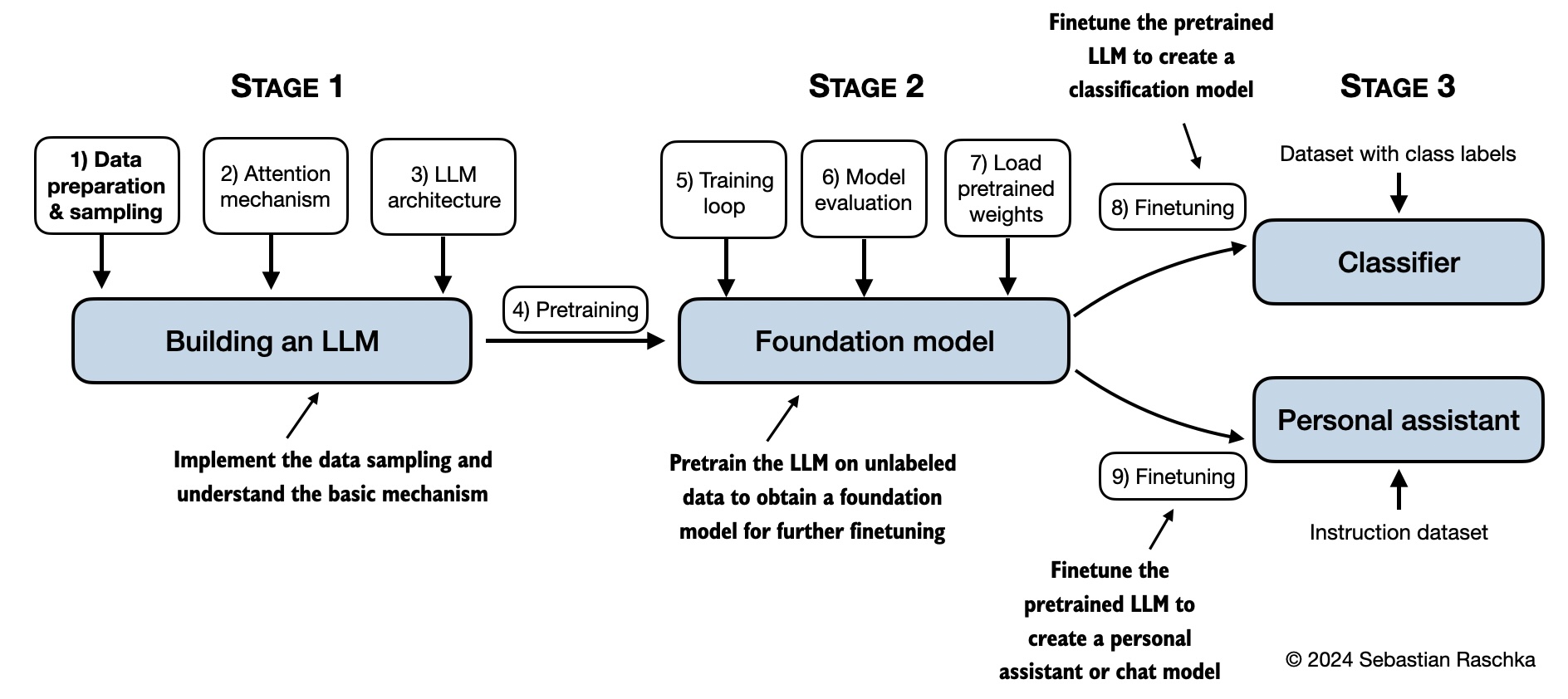
Hardware Requirements
The code in the main chapters of this book is designed to run on conventional laptops within a reasonable timeframe and does not require specialized hardware. This approach ensures that a wide audience can engage with the material. Additionally, the code automatically utilizes GPUs if they are available. (Please see the setup doc for additional recommendations.)
Exercises
Each chapter of the book includes several exercises. The solutions are summarized in Appendix C, and the corresponding code notebooks are available in the main chapter folders of this repository (for example, ./ch02/01_main-chapter-code/exercise-solutions.ipynb.
In addition to the code exercises, you can download a free 170-page PDF titled Test Yourself On Build a Large Language Model (From Scratch) from the Manning website. It contains approximately 30 quiz questions and solutions per chapter to help you test your understanding.

Bonus Material
Several folders contain optional materials as a bonus for interested readers:
- Setup
- Chapter 2: Working with text data
- Chapter 3: Coding attention mechanisms
- Chapter 4: Implementing a GPT model from scratch
- Chapter 5: Pretraining on unlabeled data:
- Alternative Weight Loading Methods
- Pretraining GPT on the Project Gutenberg Dataset
- Adding Bells and Whistles to the Training Loop
- Optimizing Hyperparameters for Pretraining
- Building a User Interface to Interact With the Pretrained LLM
- Converting GPT to Llama
- Llama 3.2 From Scratch
- Qwen3 From Scratch
- Memory-efficient Model Weight Loading
- Extending the Tiktoken BPE Tokenizer with New Tokens
- PyTorch Performance Tips for Faster LLM Training
- Chapter 6: Finetuning for classification
- Chapter 7: Finetuning to follow instructions
- Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries
- Evaluating Instruction Responses Using the OpenAI API and Ollama
- Generating a Dataset for Instruction Finetuning
- Improving a Dataset for Instruction Finetuning
- Generating a Preference Dataset with Llama 3.1 70B and Ollama
- Direct Preference Optimization (DPO) for LLM Alignment
- Building a User Interface to Interact With the Instruction Finetuned GPT Model
Questions, Feedback, and Contributing to This Repository
I welcome all sorts of feedback, best shared via the Manning Forum or GitHub Discussions. Likewise, if you have any questions or just want to bounce ideas off others, please don't hesitate to post these in the forum as well.
Please note that since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book. Keeping it consistent helps ensure a smooth experience for everyone.
Citation
If you find this book or code useful for your research, please consider citing it.
Chicago-style citation:
Raschka, Sebastian. Build A Large Language Model (From Scratch). Manning, 2024. ISBN: 978-1633437166.
BibTeX entry:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Large Language Model (From Scratch)},
publisher = {Manning},
year = {2024},
isbn = {978-1633437166},
url = {https://www.manning.com/books/build-a-large-language-model-from-scratch},
github = {https://github.com/rasbt/LLMs-from-scratch}
}
Top Related Projects
The simplest, fastest repository for training/finetuning medium-sized GPTs.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Code for the paper "Language Models are Unsupervised Multitask Learners"
TensorFlow code and pre-trained models for BERT
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot