
Top Related Projects

🤗 The largest hub of ready-to-use datasets for AI models with fast, easy-to-use and efficient data manipulation tools

Python package built to ease deep learning on graph, on top of existing DL frameworks.

Graph Neural Network Library for PyTorch

Build Graph Nets in Tensorflow

Generate embeddings from large-scale graph-structured data.
Quick Overview
The snap-stanford/ogb repository is a collection of benchmark datasets and tasks for graph machine learning, provided by the Stanford Network Analysis Project (SNAP). It aims to facilitate research and development in the field of graph neural networks and other graph-based machine learning techniques.
Pros
- Comprehensive Benchmark Datasets: The repository offers a wide range of benchmark datasets covering various graph-related tasks, such as node classification, link prediction, and graph-level prediction.
- Standardized Evaluation Protocols: The project provides standardized evaluation protocols and metrics, ensuring fair and consistent comparisons between different models and approaches.
- Active Community and Leaderboard: The project has an active community of researchers and developers, and maintains a public leaderboard to track the performance of different models on the benchmark tasks.
- Ease of Use: The project provides clear documentation and easy-to-use APIs, making it accessible for both novice and experienced researchers.
Cons
- Limited to Graph-based Tasks: The project is primarily focused on graph-based machine learning tasks, which may not be suitable for researchers working on other types of machine learning problems.
- Potential Bias in Datasets: As with any benchmark dataset, there may be inherent biases or limitations in the data that could affect the generalizability of the models trained on them.
- Dependency on External Libraries: The project relies on several external libraries, such as PyTorch and NetworkX, which may introduce additional complexity and potential compatibility issues.
- Ongoing Maintenance Effort: Maintaining a comprehensive benchmark suite and keeping it up-to-date with the latest research and developments can be a significant ongoing effort.
Code Examples
from ogb.nodeproppred import NodePropPredDataset
# Load a node property prediction dataset
dataset = NodePropPredDataset(name='ogbn-arxiv')
print(dataset)
This code demonstrates how to load a node property prediction dataset from the OGB repository.
from ogb.linkprep import LinkPropPredDataset
# Load a link property prediction dataset
dataset = LinkPropPredDataset(name='ogbl-ppa')
print(dataset)
This code demonstrates how to load a link property prediction dataset from the OGB repository.
from ogb.graphproppred import GraphPropPredDataset
# Load a graph property prediction dataset
dataset = GraphPropPredDataset(name='ogbg-molhiv')
print(dataset)
This code demonstrates how to load a graph property prediction dataset from the OGB repository.
Getting Started
To get started with the OGB repository, follow these steps:
- Install the required dependencies:
pip install ogb
- Explore the available datasets and tasks:
from ogb.utils.url import decide_download_url
print(decide_download_url())
This will print a list of the available datasets and tasks in the OGB repository.
- Load and preprocess a dataset:
from ogb.nodeproppred import NodePropPredDataset
dataset = NodePropPredDataset(name='ogbn-arxiv')
split_idx = dataset.get_split_idx('valid')
This code loads the ogbn-arxiv dataset and retrieves the validation split indices.
- Train a model on the dataset:
import torch
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, 128)
self.conv2 = GCNConv(128, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = self.conv2(x, edge_index)
return x
model = GCN(dataset.num_features, dataset.num_classes)
This code defines a simple Graph Convolutional Network (GCN) model and initializes it with the appropriate input and output dimensions for the ogbn-arxiv dataset.
Competitor Comparisons
🤗 The largest hub of ready-to-use datasets for AI models with fast, easy-to-use and efficient data manipulation tools
Pros of datasets
- Broader scope, covering various domains beyond graph data
- Extensive community support and regular updates
- Seamless integration with popular machine learning libraries
Cons of datasets
- Less specialized for graph-specific tasks
- May require more preprocessing for graph-related applications
Code comparison
datasets:
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc")
train_data = dataset["train"]
ogb:
from ogb.nodeproppred import NodePropPredDataset
dataset = NodePropPredDataset(name="ogbn-arxiv")
graph, labels = dataset[0]
Key differences
- datasets focuses on a wide range of data types, while ogb specializes in graph benchmarks
- datasets provides a unified API for various tasks, whereas ogb offers graph-specific tools
- ogb includes built-in evaluators and standardized splits for graph learning tasks
Use cases
- datasets: General machine learning tasks, NLP, computer vision
- ogb: Graph neural networks, node classification, link prediction
Community and ecosystem
- datasets: Large community, extensive documentation, and integration with Hugging Face ecosystem
- ogb: Focused community of graph learning researchers, ties to Stanford's SNAP project
Python package built to ease deep learning on graph, on top of existing DL frameworks.
Pros of DGL
- More comprehensive graph neural network library with a wider range of functionalities
- Better integration with popular deep learning frameworks like PyTorch and TensorFlow
- More active development and larger community support
Cons of DGL
- Steeper learning curve due to its broader scope and more complex API
- Potentially higher computational overhead for simpler graph tasks
Code Comparison
DGL example:
import dgl
import torch
g = dgl.graph(([0, 1], [1, 2]))
g.ndata['h'] = torch.ones(3, 5)
g.edata['w'] = torch.ones(2, 3)
OGB example:
from ogb.nodeproppred import NodePropPredDataset
dataset = NodePropPredDataset(name="ogbn-arxiv")
graph, label = dataset[0]
DGL offers more flexibility in creating and manipulating graph structures, while OGB focuses on providing standardized datasets and evaluation protocols for graph machine learning tasks. DGL is better suited for researchers and practitioners who need fine-grained control over graph operations, while OGB is ideal for those looking to benchmark their models on well-established datasets.
Graph Neural Network Library for PyTorch
Pros of PyTorch Geometric
- More comprehensive library with a wider range of graph neural network models and operations
- Actively maintained with frequent updates and a larger community
- Seamless integration with PyTorch ecosystem and GPU acceleration
Cons of PyTorch Geometric
- Steeper learning curve due to its extensive functionality
- May be overkill for simpler graph-based tasks
- Potentially higher computational overhead for basic operations
Code Comparison
OGB (Open Graph Benchmark):
from ogb.nodeproppred import PygNodePropPredDataset
dataset = PygNodePropPredDataset(name='ogbn-arxiv')
graph, labels = dataset[0]
PyTorch Geometric:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
data = dataset[0]
Both libraries provide easy access to graph datasets, but PyTorch Geometric offers a broader range of datasets and more flexible data handling. OGB focuses on standardized benchmarks, while PyTorch Geometric provides a more general-purpose toolkit for graph-based machine learning tasks.
Build Graph Nets in Tensorflow
Pros of graph_nets
- More focused on graph neural network implementations and research
- Provides a flexible framework for building custom graph neural networks
- Integrates well with TensorFlow and Sonnet libraries
Cons of graph_nets
- Less comprehensive in terms of benchmark datasets and evaluation metrics
- Smaller community and fewer contributors compared to OGB
- May require more domain knowledge to use effectively
Code Comparison
graph_nets example:
import graph_nets as gn
import sonnet as snt
graph = gn.graphs.GraphsTuple(...)
model = gn.modules.GraphNetwork(
edge_model_fn=lambda: snt.nets.MLP([32, 32]),
node_model_fn=lambda: snt.nets.MLP([32, 32]),
global_model_fn=lambda: snt.nets.MLP([32, 32])
)
output_graphs = model(graph)
OGB example:
from ogb.nodeproppred import PygNodePropPredDataset, Evaluator
from torch_geometric.nn import GCNConv
dataset = PygNodePropPredDataset(name='ogbn-arxiv')
evaluator = Evaluator(name='ogbn-arxiv')
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
Generate embeddings from large-scale graph-structured data.
Pros of PyTorch-BigGraph
- Scalability: PyTorch-BigGraph is designed to handle large-scale graph data, making it suitable for working with massive datasets.
- Flexibility: The framework supports various graph types, including bipartite, multirelational, and heterogeneous graphs.
- Performance: PyTorch-BigGraph leverages PyTorch's efficient tensor operations, resulting in improved performance compared to some other graph embedding frameworks.
Cons of PyTorch-BigGraph
- Complexity: The framework has a steeper learning curve compared to OGB, as it requires a deeper understanding of graph embeddings and PyTorch.
- Limited Documentation: The documentation for PyTorch-BigGraph is not as comprehensive as OGB, which may make it more challenging for beginners to get started.
Code Comparison
Here's a brief code comparison between the two repositories:
OGB:
from ogb.lsc import MAG240MDataset
dataset = MAG240MDataset(root='./data')
PyTorch-BigGraph:
from torchbiggraph.config import EntitySchema, RelationSchema, ConfigSchema
config = ConfigSchema(
entities={
'paper': EntitySchema(num_partitions=100),
'author': EntitySchema(num_partitions=100),
},
relations=[
RelationSchema('writes', 'paper', 'author', is_symmetric=False),
],
)
The OGB code snippet demonstrates the simplicity of loading a large-scale dataset, while the PyTorch-BigGraph code shows the more complex configuration required to set up the graph structure.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME


![]()
Overview
The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover a variety of graph machine learning tasks and real-world applications. The OGB data loaders are fully compatible with popular graph deep learning frameworks, including PyTorch Geometric and Deep Graph Library (DGL). They provide automatic dataset downloading, standardized dataset splits, and unified performance evaluation.

OGB aims to provide graph datasets that cover important graph machine learning tasks, diverse dataset scale, and rich domains.
Graph ML Tasks: We cover three fundamental graph machine learning tasks: prediction at the level of nodes, links, and graphs.
Diverse scale: Small-scale graph datasets can be processed within a single GPU, while medium- and large-scale graphs might require multiple GPUs or clever sampling/partition techniques.
Rich domains: Graph datasets come from diverse domains ranging from scientific ones to social/information networks, and also include heterogeneous knowledge graphs.
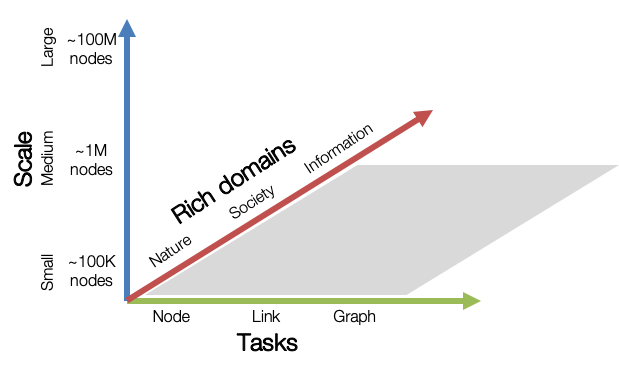
OGB is an on-going effort, and we are planning to increase our coverage in the future.
Installation
You can install OGB using Python's package manager pip.
If you have previously installed ogb, please make sure you update the version to 1.3.6.
The release note is available here.
Requirements
- Python>=3.6
- PyTorch>=1.6
- DGL>=0.5.0 or torch-geometric>=2.0.2
- Numpy>=1.16.0
- pandas>=0.24.0
- urllib3>=1.24.0
- scikit-learn>=0.20.0
- outdated>=0.2.0
Pip install
The recommended way to install OGB is using Python's package manager pip:
pip install ogb
python -c "import ogb; print(ogb.__version__)"
# This should print "1.3.6". Otherwise, please update the version by
pip install -U ogb
From source
You can also install OGB from source. This is recommended if you want to contribute to OGB.
git clone https://github.com/snap-stanford/ogb
cd ogb
pip install -e .
Package Usage
We highlight two key features of OGB, namely, (1) easy-to-use data loaders, and (2) standardized evaluators.
(1) Data loaders
We prepare easy-to-use PyTorch Geometric and DGL data loaders. We handle dataset downloading as well as standardized dataset splitting. Below, on PyTorch Geometric, we see that a few lines of code is sufficient to prepare and split the dataset! Needless to say, you can enjoy the same convenience for DGL!
from ogb.graphproppred import PygGraphPropPredDataset
from torch_geometric.loader import DataLoader
# Download and process data at './dataset/ogbg_molhiv/'
dataset = PygGraphPropPredDataset(name = 'ogbg-molhiv')
split_idx = dataset.get_idx_split()
train_loader = DataLoader(dataset[split_idx['train']], batch_size=32, shuffle=True)
valid_loader = DataLoader(dataset[split_idx['valid']], batch_size=32, shuffle=False)
test_loader = DataLoader(dataset[split_idx['test']], batch_size=32, shuffle=False)
(2) Evaluators
We also prepare standardized evaluators for easy evaluation and comparison of different methods. The evaluator takes input_dict (a dictionary whose format is specified in evaluator.expected_input_format) as input, and returns a dictionary storing the performance metric appropriate for the given dataset.
The standardized evaluation protocol allows researchers to reliably compare their methods.
from ogb.graphproppred import Evaluator
evaluator = Evaluator(name = 'ogbg-molhiv')
# You can learn the input and output format specification of the evaluator as follows.
# print(evaluator.expected_input_format)
# print(evaluator.expected_output_format)
input_dict = {'y_true': y_true, 'y_pred': y_pred}
result_dict = evaluator.eval(input_dict) # E.g., {'rocauc': 0.7321}
Citing OGB / OGB-LSC
If you use OGB or OGB-LSC datasets in your work, please cite our papers (Bibtex below).
@article{hu2020ogb,
title={Open Graph Benchmark: Datasets for Machine Learning on Graphs},
author={Hu, Weihua and Fey, Matthias and Zitnik, Marinka and Dong, Yuxiao and Ren, Hongyu and Liu, Bowen and Catasta, Michele and Leskovec, Jure},
journal={arXiv preprint arXiv:2005.00687},
year={2020}
}
@article{hu2021ogblsc,
title={OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs},
author={Hu, Weihua and Fey, Matthias and Ren, Hongyu and Nakata, Maho and Dong, Yuxiao and Leskovec, Jure},
journal={arXiv preprint arXiv:2103.09430},
year={2021}
}
Top Related Projects
🤗 The largest hub of ready-to-use datasets for AI models with fast, easy-to-use and efficient data manipulation tools
Python package built to ease deep learning on graph, on top of existing DL frameworks.
Graph Neural Network Library for PyTorch
Build Graph Nets in Tensorflow
Generate embeddings from large-scale graph-structured data.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot