





- Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip [mirror]
- Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip [mirror]
- Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download): glove.6B.zip [mirror]
- Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download): glove.twitter.27B.zip [mirror]
 GloVe
GloVe
Software in C and data files for the popular GloVe model for distributed word representations, a.k.a. word vectors or embeddings
7,060
1,539
7,060
81
Top Related Projects
26,297
Library for fast text representation and classification.
31,840
💫 Industrial-strength Natural Language Processing (NLP) in Python
16,122
Topic Modelling for Humans
39,267
TensorFlow code and pre-trained models for BERT
146,142
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
190,523
An Open Source Machine Learning Framework for Everyone
Quick Overview
GloVe (Global Vectors for Word Representation) is an unsupervised learning algorithm for obtaining vector representations for words. Developed by Stanford NLP, it combines the advantages of global matrix factorization and local context window methods to create efficient word embeddings.
Pros
- Captures both global and local statistics of word occurrences
- Performs well on word analogy tasks and named entity recognition
- Efficient training on large corpora
- Pre-trained word vectors available for immediate use
Cons
- Requires a large corpus for optimal performance
- May struggle with out-of-vocabulary words
- Not as widely adopted as some other word embedding techniques (e.g., Word2Vec)
- Limited support for languages other than English
Code Examples
import numpy as np
# Load pre-trained word vectors
def load_glove_vectors(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
words = {}
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], dtype='float32')
words[word] = vector
return words
glove_vectors = load_glove_vectors('glove.6B.100d.txt')
This code loads pre-trained GloVe vectors from a file into a dictionary.
# Find most similar words
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def find_similar_words(word, vectors, n=5):
word_vector = vectors[word]
similarities = [(w, cosine_similarity(word_vector, v)) for w, v in vectors.items()]
return sorted(similarities, key=lambda x: x[1], reverse=True)[1:n+1]
similar_words = find_similar_words('king', glove_vectors)
print(similar_words)
This code finds the most similar words to a given word using cosine similarity.
# Perform word analogy
def word_analogy(word1, word2, word3, vectors):
v1, v2, v3 = vectors[word1], vectors[word2], vectors[word3]
v4 = v2 - v1 + v3
similarities = [(w, cosine_similarity(v4, v)) for w, v in vectors.items()]
return max(similarities, key=lambda x: x[1])[0]
result = word_analogy('king', 'man', 'woman', glove_vectors)
print(f"king - man + woman = {result}")
This code performs word analogy using GloVe vectors.
Getting Started
- Download pre-trained GloVe vectors from the Stanford NLP website.
- Install required libraries:
pip install numpy - Use the code examples above to load vectors and perform operations.
To train your own GloVe vectors:
- Clone the repository:
git clone https://github.com/stanfordnlp/GloVe.git - Compile the source:
cd GloVe && make - Prepare your corpus and run the demo script:
./demo.sh
For more detailed instructions, refer to the repository's README file.
Competitor Comparisons
26,297
Library for fast text representation and classification.
Pros of fastText
- Supports subword information, allowing it to handle out-of-vocabulary words better
- Faster training and inference times due to hierarchical softmax
- Includes a supervised text classification model
Cons of fastText
- May struggle with capturing complex word relationships compared to GloVe
- Requires more memory during training due to subword information storage
- Less effective for tasks requiring fine-grained semantic understanding
Code Comparison
GloVe:
from glove import Corpus, Glove
corpus = Corpus()
corpus.fit(sentences, window=10)
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
fastText:
import fasttext
model = fasttext.train_unsupervised('data.txt', model='skipgram')
vector = model.get_word_vector('word')
Both GloVe and fastText are popular word embedding techniques, but they differ in their approaches. GloVe focuses on global word-word co-occurrence statistics, while fastText uses subword information and a skip-gram model. fastText is generally faster and better at handling rare words, but GloVe may capture more nuanced relationships between words. The choice between them depends on the specific requirements of your natural language processing task.
31,840
💫 Industrial-strength Natural Language Processing (NLP) in Python
Pros of spaCy
- Comprehensive NLP library with end-to-end processing capabilities
- Efficient and optimized for production use
- Extensive documentation and community support
Cons of spaCy
- Steeper learning curve due to its extensive feature set
- Larger memory footprint compared to GloVe
- May be overkill for simple word embedding tasks
Code Comparison
spaCy:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence.")
for token in doc:
print(token.text, token.pos_, token.dep_)
GloVe:
from gensim.models import KeyedVectors
glove_vectors = KeyedVectors.load_word2vec_format("glove.6B.100d.txt")
vector = glove_vectors["word"]
similar_words = glove_vectors.most_similar("word")
16,122
Topic Modelling for Humans
Pros of Gensim
- Broader range of NLP tasks and algorithms beyond word embeddings
- More active development and community support
- Python-based, making it easier to integrate with other data science tools
Cons of Gensim
- Generally slower performance for large-scale word embedding tasks
- Requires more memory for processing large corpora
- Less optimized for specific word embedding tasks compared to GloVe
Code Comparison
GloVe (C implementation):
for (a = 0; a < num_threads; a++)
pthread_create(&threads[a], NULL, glove_thread, (void *)a);
for (a = 0; a < num_threads; a++)
pthread_join(threads[a], NULL);
Gensim (Python implementation):
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
model.train(sentences, total_examples=model.corpus_count, epochs=model.epochs)
Both repositories offer word embedding capabilities, but Gensim provides a more comprehensive toolkit for various NLP tasks. GloVe, being focused solely on word embeddings, offers better performance and optimization for that specific task. Gensim's Python-based implementation makes it more accessible and easier to integrate into data science workflows, while GloVe's C implementation provides better performance for large-scale word embedding tasks.
39,267
TensorFlow code and pre-trained models for BERT
Pros of BERT
- Contextual word embeddings, capturing context-dependent meanings
- Pre-trained on large corpora, enabling fine-tuning for various NLP tasks
- Supports bidirectional context, improving understanding of language nuances
Cons of BERT
- Computationally expensive to train and use, requiring significant resources
- More complex architecture, potentially harder to implement and fine-tune
- Larger model size, which can be challenging for deployment in resource-constrained environments
Code Comparison
GloVe:
from glove import Corpus, Glove
corpus = Corpus()
corpus.fit(sentences, window=10)
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
BERT:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
146,142
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of transformers
- Supports a wide range of state-of-the-art models for various NLP tasks
- Offers easy-to-use APIs for fine-tuning and inference
- Regularly updated with new models and features
Cons of transformers
- Larger library size and potentially higher computational requirements
- Steeper learning curve for beginners due to its extensive functionality
- May be overkill for simple word embedding tasks
Code comparison
GloVe:
from glove import Corpus, Glove
corpus = Corpus()
corpus.fit(sentences, window=10)
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
transformers:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
190,523
An Open Source Machine Learning Framework for Everyone
Pros of TensorFlow
- Comprehensive deep learning framework with support for various neural network architectures
- Large ecosystem with extensive documentation, tutorials, and community support
- Flexible deployment options across different platforms and devices
Cons of TensorFlow
- Steeper learning curve compared to GloVe's focused approach
- Higher computational requirements for training and inference
- More complex setup and configuration process
Code Comparison
GloVe:
CREC *cr = malloc(sizeof(CREC) * MAX_PRODUCT);
HASHREC **vocab_hash = inithashtable();
long long *token_counts = malloc(sizeof(long long) * vocab_size);
TensorFlow:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
Summary
GloVe is a focused tool for creating word embeddings, while TensorFlow is a comprehensive deep learning framework. GloVe offers simplicity and efficiency for specific word embedding tasks, whereas TensorFlow provides flexibility and scalability for a wide range of machine learning applications. The choice between them depends on the specific requirements of your project and your familiarity with deep learning concepts.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
GloVe: Global Vectors for Word Representation
| nearest neighbors of frog | Litoria | Leptodactylidae | Rana | Eleutherodactylus |
|---|---|---|---|---|
| Pictures |  |  |  |  |
| Comparisons | man -> woman | city -> zip | comparative -> superlative |
|---|---|---|---|
| GloVe Geometry | 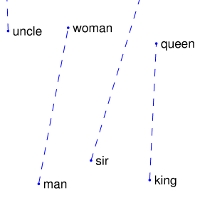 | 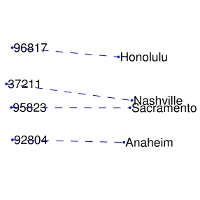 | 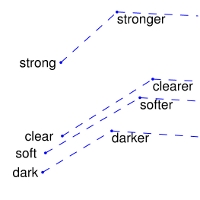 |
We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the project page or the paper for more information on glove vectors.
Download pre-trained word vectors
The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
Train word vectors on a new corpus

If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
$ git clone https://github.com/stanfordnlp/glove
$ cd glove && make
$ ./demo.sh
Make sure you have the following prerequisites installed when running the steps above:
- GNU Make
- GCC (Clang pretending to be GCC is fine)
- Python and NumPy
The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading demo.sh or the src/README.md
License
All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
Top Related Projects
26,297
Library for fast text representation and classification.
31,840
💫 Industrial-strength Natural Language Processing (NLP) in Python
16,122
Topic Modelling for Humans
39,267
TensorFlow code and pre-trained models for BERT
146,142
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
190,523
An Open Source Machine Learning Framework for Everyone
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot