 vaex
vaex
Out-of-Core hybrid Apache Arrow/NumPy DataFrame for Python, ML, visualization and exploration of big tabular data at a billion rows per second 🚀
Top Related Projects

Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more

Parallel computing with task scheduling

Modin: Scale your Pandas workflows by changing a single line of code

A Python package for manipulating 2-dimensional tabular data structures

Dataframes powered by a multithreaded, vectorized query engine, written in Rust

cuDF - GPU DataFrame Library
Quick Overview
Vaex is a high-performance Python library for lazy out-of-core DataFrames, enabling the visualization, exploration, and analysis of big tabular datasets. It can handle datasets larger than memory, processing billions of rows per second on a single computer.
Pros
- Extremely fast processing of large datasets (billions of rows)
- Memory-efficient with out-of-core computation
- Compatible with pandas API for easy integration
- Supports various file formats including HDF5, Arrow, and CSV
Cons
- Steeper learning curve compared to pandas for advanced features
- Limited support for certain operations compared to pandas
- May require more setup and configuration for optimal performance
- Less extensive documentation and community support compared to more established libraries
Code Examples
- Creating a DataFrame and performing basic operations:
import vaex
# Create a DataFrame from a CSV file
df = vaex.from_csv('large_dataset.csv')
# Display basic information about the DataFrame
print(df.info())
# Perform a simple calculation on a column
mean_value = df.column_name.mean()
print(f"Mean value: {mean_value}")
- Filtering and grouping data:
# Filter the DataFrame
filtered_df = df[df.age > 30]
# Group by a column and calculate statistics
grouped = df.groupby('category').agg({'value': 'mean', 'count': 'count'})
print(grouped)
- Visualizing data with Vaex:
import vaex.viz
# Create a scatter plot
df.viz.scatter('x', 'y')
# Create a histogram
df.viz.histogram('age', bins=50)
# Show the plot
import matplotlib.pyplot as plt
plt.show()
Getting Started
To get started with Vaex, follow these steps:
-
Install Vaex using pip:
pip install vaex -
Import Vaex in your Python script:
import vaex -
Load your data:
df = vaex.from_csv('your_data.csv') # or use other file formats -
Start exploring and analyzing your data using Vaex's methods and operations.
For more detailed information and advanced usage, refer to the official Vaex documentation at https://vaex.io/docs/index.html.
Competitor Comparisons
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more
Pros of pandas
- Widely adopted and well-established in the data science community
- Extensive documentation and large ecosystem of third-party extensions
- Powerful and flexible data manipulation capabilities
Cons of pandas
- Memory-intensive for large datasets, as it loads all data into RAM
- Performance can be slow for operations on very large datasets
- Limited support for out-of-memory processing
Code Comparison
pandas:
import pandas as pd
df = pd.read_csv('large_file.csv')
result = df.groupby('category').mean()
Vaex:
import vaex
df = vaex.open('large_file.csv')
result = df.groupby('category').mean().to_pandas_df()
Vaex is designed to handle large datasets efficiently by using memory mapping and lazy evaluation. It can process datasets larger than RAM, making it suitable for big data analysis. Pandas, on the other hand, is more versatile and widely used but may struggle with very large datasets due to its in-memory processing approach.
Vaex aims to provide a pandas-like API for out-of-core DataFrames, making it easier for pandas users to transition to working with larger datasets. However, pandas still has a more comprehensive set of features and a larger community, which can be beneficial for complex data manipulation tasks and finding solutions to specific problems.
Parallel computing with task scheduling
Pros of Dask
- More mature and widely adopted in the data science community
- Supports a broader range of data processing tasks beyond dataframes
- Integrates well with other Python libraries in the scientific ecosystem
Cons of Dask
- Can be more complex to set up and configure for distributed computing
- May have higher memory overhead for certain operations
- Performance can vary depending on the specific use case and data structure
Code Comparison
Dask:
import dask.dataframe as dd
df = dd.read_csv('large_file.csv')
result = df.groupby('column').mean().compute()
Vaex:
import vaex
df = vaex.open('large_file.csv')
result = df.groupby('column').mean().to_pandas_df()
Both Dask and Vaex are powerful libraries for handling large datasets in Python. Dask offers a more comprehensive suite of tools for parallel computing, while Vaex specializes in memory-efficient dataframe operations. The choice between them often depends on specific project requirements and the nature of the data being processed.
Modin: Scale your Pandas workflows by changing a single line of code
Pros of Modin
- Seamless integration with pandas API, allowing easy adoption for existing pandas users
- Supports both Ray and Dask as execution engines, providing flexibility in distributed computing
- Actively maintained with frequent updates and improvements
Cons of Modin
- Performance gains may be limited for smaller datasets compared to pandas
- Some pandas functions are not yet fully supported or optimized
- Requires additional setup and dependencies for distributed computing
Code Comparison
Modin:
import modin.pandas as pd
df = pd.read_csv("large_file.csv")
result = df.groupby("column").mean()
Vaex:
import vaex
df = vaex.open("large_file.csv")
result = df.groupby("column").mean().to_pandas_df()
Key Differences
- Modin aims to be a drop-in replacement for pandas, while Vaex has its own API
- Vaex is designed specifically for out-of-core processing of large datasets, whereas Modin focuses on distributed computing
- Modin supports both in-memory and out-of-core processing, while Vaex primarily targets out-of-core operations
Both libraries offer solutions for handling large datasets, but they differ in their approach and target use cases. Modin is ideal for users looking to scale existing pandas code, while Vaex may be better suited for working with extremely large datasets that don't fit in memory.
A Python package for manipulating 2-dimensional tabular data structures
Pros of datatable
- Faster performance for certain operations, especially on large datasets
- More memory-efficient for handling big data
- Better integration with H2O.ai's machine learning ecosystem
Cons of datatable
- Smaller community and less extensive documentation compared to Vaex
- Fewer built-in visualization capabilities
- More limited support for distributed computing
Code Comparison
datatable:
import datatable as dt
df = dt.fread("data.csv")
result = df[:, dt.sum(f.numeric_column), by("category")]
Vaex:
import vaex
df = vaex.open("data.csv")
result = df.groupby("category").agg({'numeric_column': 'sum'})
Both libraries offer efficient data manipulation for large datasets, but their syntax and specific functionalities differ. datatable focuses on high-performance operations, while Vaex provides a more pandas-like interface with additional features for out-of-core processing and visualization.
Dataframes powered by a multithreaded, vectorized query engine, written in Rust
Pros of Polars
- Faster performance for many operations due to Rust implementation
- More memory-efficient, especially for large datasets
- Better support for Arrow data format
Cons of Polars
- Smaller ecosystem and fewer integrations compared to Vaex
- Less mature, with potential for more breaking changes
- Steeper learning curve for users not familiar with Rust concepts
Code Comparison
Vaex:
import vaex
df = vaex.from_csv('data.csv')
result = df[df.age > 30].mean(df.salary)
Polars:
import polars as pl
df = pl.read_csv('data.csv')
result = df.filter(pl.col('age') > 30).select(pl.col('salary').mean())
Both libraries aim to provide efficient data manipulation for large datasets, but they differ in implementation and syntax. Vaex focuses on out-of-core processing and lazy evaluation, while Polars emphasizes speed and memory efficiency through its Rust core. The choice between them depends on specific use cases, performance requirements, and ecosystem needs.
cuDF - GPU DataFrame Library
Pros of cuDF
- Leverages GPU acceleration for faster data processing
- Seamless integration with other RAPIDS ecosystem libraries
- Supports larger-than-memory datasets through Dask integration
Cons of cuDF
- Requires NVIDIA GPU hardware
- Limited to Python programming language
- Steeper learning curve due to GPU-specific concepts
Code Comparison
cuDF:
import cudf
df = cudf.read_csv('data.csv')
result = df.groupby('category').agg({'value': 'mean'})
Vaex:
import vaex
df = vaex.open('data.csv')
result = df.groupby('category', agg={'mean_value': vaex.agg.mean('value')})
Both libraries aim to handle large datasets efficiently, but they take different approaches. cuDF focuses on GPU acceleration, while Vaex uses memory-mapping and lazy evaluation techniques. cuDF is part of the RAPIDS ecosystem, offering integration with other GPU-accelerated tools. Vaex, on the other hand, is more flexible in terms of hardware requirements and supports multiple data formats.
cuDF excels in scenarios where GPU hardware is available and processing speed is crucial. Vaex shines in situations where memory efficiency is paramount, and when working with various data sources without specialized hardware.
The choice between these libraries depends on specific project requirements, available hardware, and the broader data processing ecosystem in use.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

![]()
What is Vaex?
Vaex is a high performance Python library for lazy Out-of-Core DataFrames
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates statistics such as mean, sum, count, standard deviation etc, on an
N-dimensional grid for more than a billion (10^9) samples/rows per
second. Visualization is done using histograms, density plots and 3d
volume rendering, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
Installing
With pip:
$ pip install vaex
Or conda:
$ conda install -c conda-forge vaex
For more details, see the documentation
Key features
Instant opening of Huge data files (memory mapping)
HDF5 and Apache Arrow supported.

Read the documentation on how to efficiently convert your data from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.
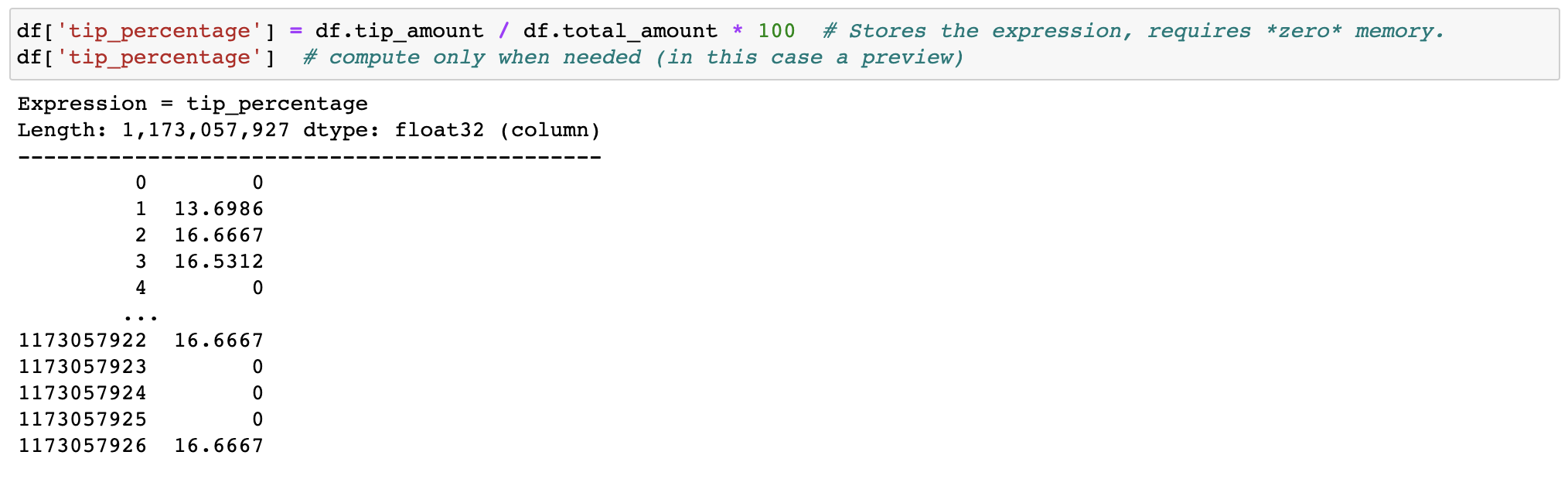
Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

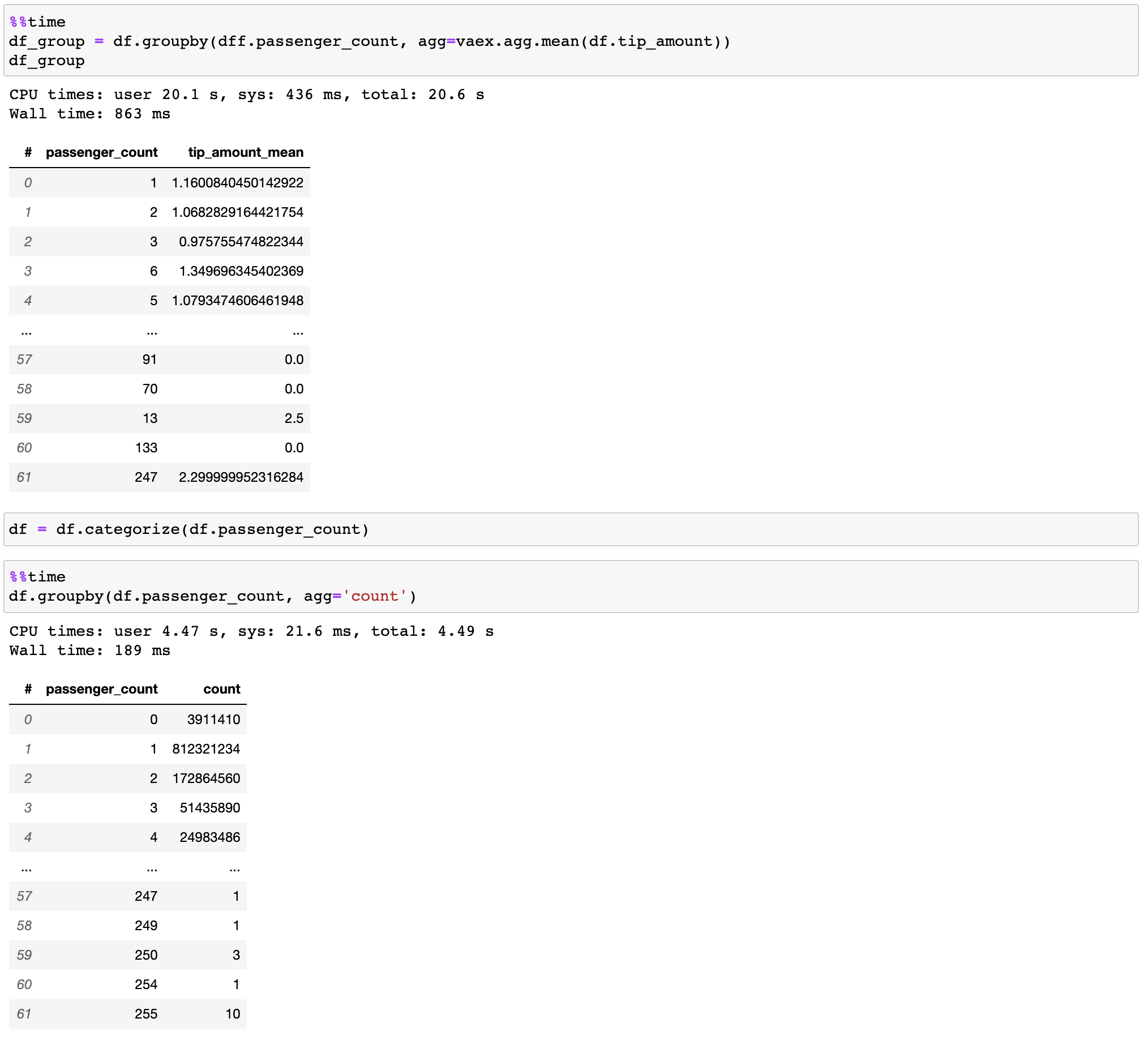
Fast groupby / aggregations
Vaex implements parallelized, highly performant groupby operations, especially when using categories (>1 billion/second).
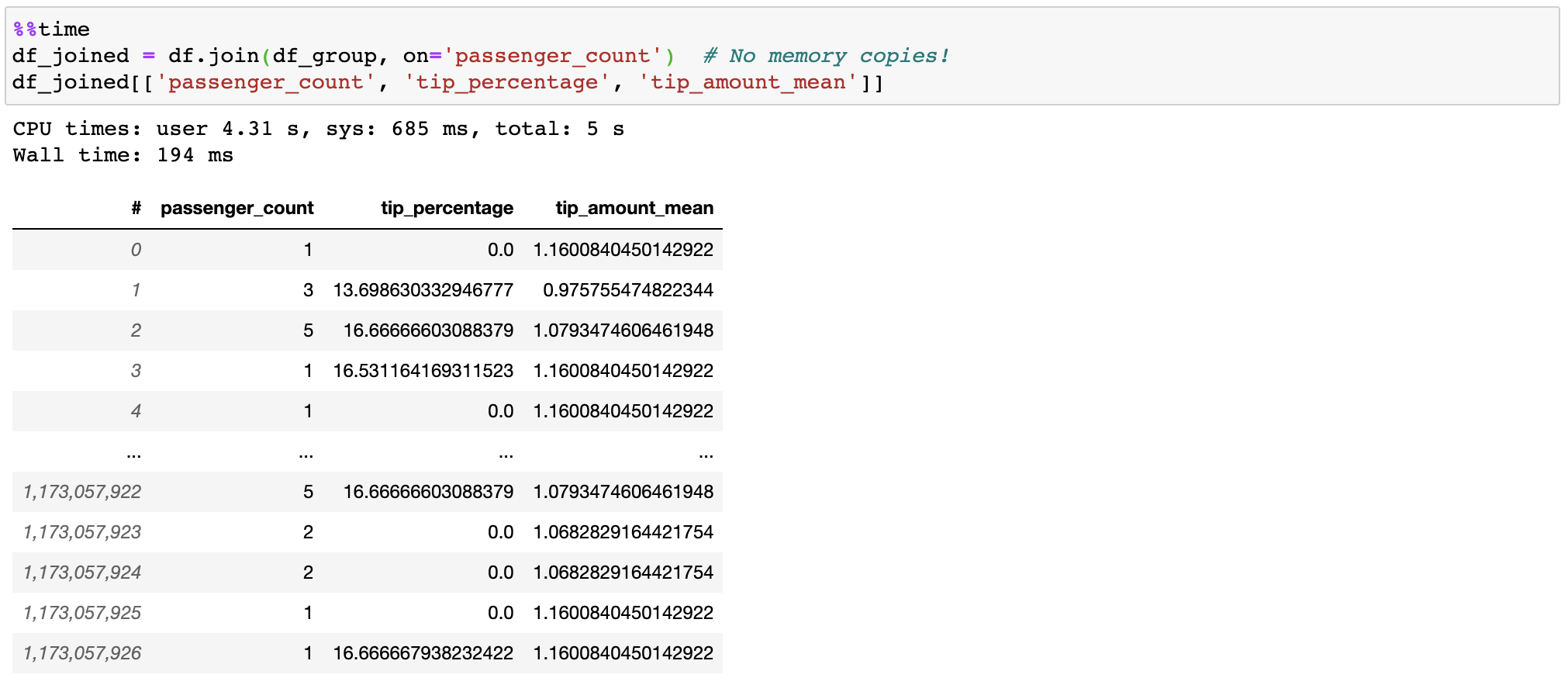
Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!
More features
- Remote DataFrames (documentation coming soon)
- Integration into Jupyter and Voila for interactive notebooks and dashboards
- Machine Learning without (explicit) pipelines
Contributing
See contributing page.
Slack
Join the discussion in our Slack channel!
Learn more about Vaex
-
Articles
- Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head (includes benchmarks)
- 7 reasons why I love Vaex for data science (tips and trics)
- ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn
- How to analyse 100 GB of data on your laptop with Python
- Flying high with Vaex: analysis of over 30 years of flight data in Python
- Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
- Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop
-
Watch our more recent talks:
-
Contact us for data science solutions, training, or enterprise support at https://vaex.io/
Top Related Projects
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more
Parallel computing with task scheduling
Modin: Scale your Pandas workflows by changing a single line of code
A Python package for manipulating 2-dimensional tabular data structures
Dataframes powered by a multithreaded, vectorized query engine, written in Rust
cuDF - GPU DataFrame Library
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot