 nebula
nebula
A distributed, fast open-source graph database featuring horizontal scalability and high availability
Top Related Projects

TiDB - the open-source, cloud-native, distributed SQL database designed for modern applications.

CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.

🥑 ArangoDB is a native multi-model database with flexible data models for documents, graphs, and key-values. Build high performance applications using a convenient SQL-like query language or JavaScript extensions.

OrientDB is the most versatile DBMS supporting Graph, Document, Reactive, Full-Text and Geospatial models in one Multi-Model product. OrientDB can run distributed (Multi-Master), supports SQL, ACID Transactions, Full-Text indexing and Reactive Queries.

high-performance graph database for real-time use cases

Graphs for Everyone
Quick Overview
Nebula is an open-source, distributed graph database designed for managing large-scale graphs with billions of vertices and trillions of edges. It offers high performance, scalability, and fault tolerance for handling complex graph-related queries and analytics in real-time.
Pros
- High performance and low latency for graph queries and traversals
- Scalable architecture supporting horizontal scaling
- Strong consistency and ACID transactions
- Flexible schema design and support for property graphs
Cons
- Steep learning curve for users new to graph databases
- Limited ecosystem compared to more established graph databases
- Documentation can be improved in some areas
- Requires careful tuning for optimal performance in large-scale deployments
Code Examples
- Creating a space and tags:
CREATE SPACE my_graph(partition_num=10, replica_factor=1);
USE my_graph;
CREATE TAG person(name string, age int);
CREATE TAG movie(title string, released int);
- Creating edges and inserting data:
CREATE EDGE acted_in(role string);
INSERT VERTEX person(name, age) VALUES "1":("Tom Hanks", 64);
INSERT VERTEX movie(title, released) VALUES "101":("Forrest Gump", 1994);
INSERT EDGE acted_in(role) VALUES "1"->"101":("Forrest Gump");
- Querying the graph:
MATCH (p:person)-[r:acted_in]->(m:movie)
WHERE p.name == "Tom Hanks"
RETURN p.name, r.role, m.title;
Getting Started
-
Install Nebula Graph:
wget https://github.com/vesoft-inc/nebula/releases/download/v3.3.0/nebula-graph-3.3.0.ubuntu2004.amd64.deb sudo dpkg -i nebula-graph-3.3.0.ubuntu2004.amd64.deb -
Start Nebula services:
sudo /usr/local/nebula/scripts/nebula.service start all -
Connect to Nebula:
nebula-console -addr 127.0.0.1 -port 9669 -u root -p nebula -
Create a space and start using Nebula:
CREATE SPACE my_graph(partition_num=10, replica_factor=1); USE my_graph;
Competitor Comparisons
TiDB - the open-source, cloud-native, distributed SQL database designed for modern applications.
Pros of TiDB
- Mature SQL-based distributed database with strong ACID compliance
- Horizontal scalability and high availability out of the box
- Compatibility with MySQL protocol, allowing easy migration
Cons of TiDB
- Higher resource consumption compared to Nebula
- Steeper learning curve for graph-specific operations
- Less efficient for complex graph traversals and analytics
Code Comparison
TiDB (SQL-based query):
SELECT * FROM users
JOIN orders ON users.id = orders.user_id
WHERE orders.total > 100;
Nebula (Graph-based query):
MATCH (u:User)-[:PLACED]->(o:Order)
WHERE o.total > 100
RETURN u, o;
Key Differences
- TiDB is a distributed SQL database, while Nebula is a distributed graph database
- TiDB excels in transactional workloads, Nebula in graph-based operations
- TiDB uses SQL syntax, Nebula uses its own query language (NGQL)
- TiDB offers better support for complex JOIN operations, Nebula for graph traversals
- TiDB provides stronger ACID guarantees, Nebula focuses on scalability for graph data
Both databases offer distributed architecture and horizontal scalability, but they target different use cases and data models. Choose based on your specific requirements and data structure.
CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.
Pros of Cockroach
- Mature SQL database with strong ACID compliance and distributed architecture
- Excellent horizontal scalability and high availability features
- Large and active community with extensive documentation and support
Cons of Cockroach
- Higher resource consumption compared to traditional databases
- Steeper learning curve for developers unfamiliar with distributed systems
- Limited support for graph-based queries and relationships
Code Comparison
Nebula (Graph Query):
MATCH (p:Person)-[:KNOWS]->(f:Person)
WHERE p.name = 'Alice'
RETURN f.name
Cockroach (SQL Query):
SELECT f.name
FROM persons p
JOIN knows k ON p.id = k.person_id
JOIN persons f ON k.friend_id = f.id
WHERE p.name = 'Alice';
Key Differences
- Nebula is a native graph database, while Cockroach is a distributed SQL database
- Cockroach offers stronger ACID guarantees and SQL compatibility
- Nebula provides more efficient graph traversal and relationship queries
- Cockroach has a larger ecosystem and broader adoption in enterprise environments
- Nebula is better suited for graph-centric applications and complex relationship modeling
🥑 ArangoDB is a native multi-model database with flexible data models for documents, graphs, and key-values. Build high performance applications using a convenient SQL-like query language or JavaScript extensions.
Pros of ArangoDB
- Multi-model database supporting key/value, document, and graph data models
- Powerful query language (AQL) for complex data operations
- Strong consistency and ACID transactions
Cons of ArangoDB
- Higher memory consumption compared to Nebula
- Less specialized for large-scale graph processing
- Steeper learning curve due to multi-model nature
Code Comparison
ArangoDB (AQL):
FOR v, e, p IN 1..3 OUTBOUND 'users/john' GRAPH 'social'
RETURN {
user: v.name,
friend: p.vertices[-1].name,
connection: p.edges[*].type
}
Nebula:
MATCH (user:User {name: "john"})-[e:FRIEND*1..3]->(friend:User)
RETURN user.name, friend.name, e.type
Key Differences
- ArangoDB offers a more versatile data model, while Nebula focuses on graph processing
- Nebula provides better performance for large-scale graph operations
- ArangoDB's query language (AQL) is more flexible, but Nebula's nGQL is optimized for graph queries
- Nebula has a distributed architecture designed for horizontal scalability
- ArangoDB offers a wider range of indexing options and data consistency guarantees
OrientDB is the most versatile DBMS supporting Graph, Document, Reactive, Full-Text and Geospatial models in one Multi-Model product. OrientDB can run distributed (Multi-Master), supports SQL, ACID Transactions, Full-Text indexing and Reactive Queries.
Pros of OrientDB
- Mature project with a longer history and larger community
- Supports multiple data models (document, graph, key-value, object)
- Built-in support for SQL-like query language
Cons of OrientDB
- Less scalable for large-scale distributed scenarios
- Higher memory consumption for complex queries
- Steeper learning curve due to multiple data models
Code Comparison
OrientDB query example:
SELECT FROM Person
WHERE name = 'John'
AND age > 30
Nebula query example:
MATCH (p:Person)
WHERE p.name == 'John' AND p.age > 30
RETURN p
Key Differences
- OrientDB uses a SQL-like syntax, while Nebula uses a Cypher-inspired language (nGQL)
- Nebula is designed specifically for large-scale graph scenarios, while OrientDB is more versatile
- OrientDB offers multi-model support, whereas Nebula focuses solely on graph data
Use Cases
- OrientDB: Suitable for projects requiring flexibility in data models and SQL-like querying
- Nebula: Ideal for large-scale graph processing and analytics in distributed environments
Both databases have their strengths, and the choice depends on specific project requirements, scalability needs, and preferred query language.
high-performance graph database for real-time use cases
Pros of Dgraph
- More mature project with a larger community and ecosystem
- Supports GraphQL natively, making it easier to integrate with modern web applications
- Offers a cloud-hosted option (Dgraph Cloud) for easier deployment and management
Cons of Dgraph
- Less flexible schema design compared to Nebula's property graph model
- May have higher resource requirements for large-scale deployments
- Learning curve can be steeper for users new to GraphQL
Code Comparison
Dgraph query example:
{
user(func: eq(name, "Alice")) {
name
age
friends {
name
}
}
}
Nebula query example:
MATCH (u:User {name: "Alice"})-[:FRIEND]->(f:User)
RETURN u.name, u.age, f.name
Both examples demonstrate querying a user named Alice and their friends, but Dgraph uses GraphQL syntax while Nebula uses a Cypher-like language.
Graphs for Everyone
Pros of Neo4j
- Mature and widely adopted graph database with a large community
- Robust ecosystem of tools, drivers, and integrations
- ACID-compliant transactions and strong consistency guarantees
Cons of Neo4j
- Can be resource-intensive for large-scale deployments
- Limited horizontal scalability compared to distributed systems
- Proprietary query language (Cypher) may have a steeper learning curve
Code Comparison
Neo4j (Cypher query):
MATCH (n:Person)-[:KNOWS]->(m:Person)
WHERE n.name = 'Alice'
RETURN m.name
Nebula (nGQL query):
MATCH (n:Person)-[:KNOWS]->(m:Person)
WHERE n.name == 'Alice'
RETURN m.name
Key Differences
- Nebula is designed for distributed storage and processing, offering better scalability for large datasets
- Neo4j provides a more mature ecosystem and broader industry adoption
- Nebula uses nGQL, which is similar to Cypher but with some syntax differences
- Neo4j offers a more feature-rich enterprise edition, while Nebula focuses on open-source development
Both projects aim to provide efficient graph database solutions, with Neo4j excelling in traditional enterprise environments and Nebula targeting large-scale distributed scenarios.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()
English | ä¸æ
A distributed, scalable, lightning-fast graph database

![]()



NebulaGraph
Introduction
NebulaGraph is a popular open-source graph database that can handle large volumes of data with milliseconds of latency, scale up quickly, and have the ability to perform fast graph analytics. NebulaGraph has been widely used for social media, recommendation systems, knowledge graphs, security, capital flows, AI, etc. See our users.
The following lists some of NebulaGraph features:
- Symmetrically distributed
- Storage and computing separation
- Horizontal scalability
- Strong data consistency by RAFT protocol
- OpenCypher-compatible query language
- Role-based access control for higher-level security
- Different types of graph analytics algorithms
The following figure shows the architecture of the NebulaGraph core.
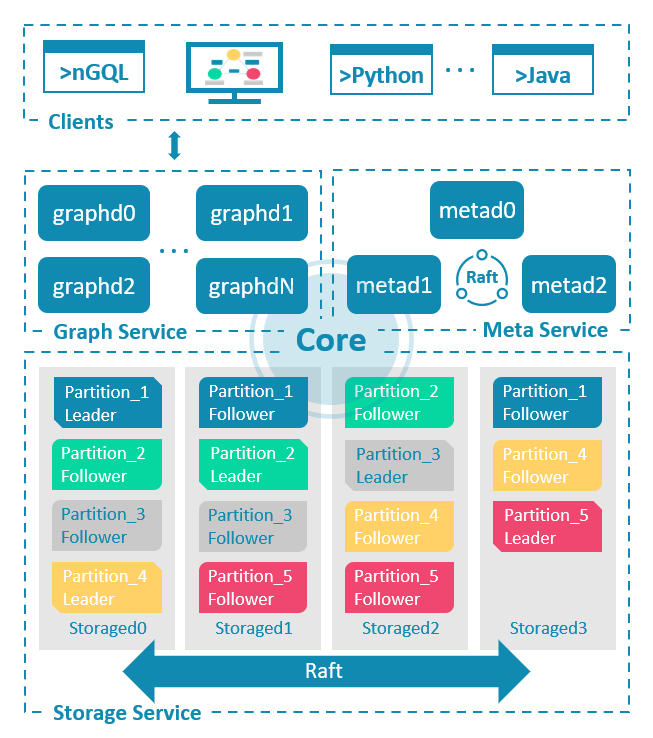
Learn more on NebulaGraph website.
Quick start
Read the getting started docs for a quick start.
Using NebulaGraph
NebulaGraph is a distributed graph database with multiple components. You can download or try in following ways:
-
In the cloud: AWS
Getting help
In case you encounter any problems playing around NebulaGraph, please reach out for help:
DevTools
NebulaGraph comes with a set of tools to help you manage and monitor your graph database. See Ecosystem.
Contributing
Contributions are warmly welcomed and greatly appreciated. And here are a few ways you can contribute:
- Start by some issues
- Submit Pull Requests to us. See how-to-contribute.
Landscape

NebulaGraph enriches the CNCF Database Landscape.
Licensing
NebulaGraph is under Apache 2.0 license, so you can freely download, modify, and deploy the source code to meet your needs.
You can also freely deploy NebulaGraph as a back-end service to support your SaaS deployment.
Contact
- Community Chat
- Slack Channel
- Stack Overflow
- X(Twitter): @NebulaGraph
- LinkedIn Page
- Email: info@vesoft.com
Community
| Join NebulaGraph Community | Where to Find us |
|---|---|
| Asking Questions | |
| Chat with Community Members | |
| NebulaGraph Meetup | |
| Chat, Asking, or Meeting in Chinese |
If you find NebulaGraph interesting, please âï¸ Star it at the top of the GitHub page.
Top Related Projects
TiDB - the open-source, cloud-native, distributed SQL database designed for modern applications.
CockroachDB — the cloud native, distributed SQL database designed for high availability, effortless scale, and control over data placement.
🥑 ArangoDB is a native multi-model database with flexible data models for documents, graphs, and key-values. Build high performance applications using a convenient SQL-like query language or JavaScript extensions.
OrientDB is the most versatile DBMS supporting Graph, Document, Reactive, Full-Text and Geospatial models in one Multi-Model product. OrientDB can run distributed (Multi-Master), supports SQL, ACID Transactions, Full-Text indexing and Reactive Queries.
high-performance graph database for real-time use cases
Graphs for Everyone
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot