 ugrep
ugrep
🔍 ugrep 7.5 file pattern searcher -- a user-friendly, faster, more capable grep replacement. Includes a TUI, Google-like Boolean search with AND/OR/NOT, fuzzy search, hexdumps, searches (nested) archives (zip, 7z, tar, pax, cpio), compressed files (gz, Z, bz2, lzma, xz, lz4, zstd, brotli), pdfs, docs, and more
Top Related Projects

ripgrep recursively searches directories for a regex pattern while respecting your gitignore

A simple, fast and user-friendly alternative to 'find'

:cherry_blossom: A command-line fuzzy finder

A code-searching tool similar to ack, but faster.

A code search tool similar to ack and the_silver_searcher(ag). It supports multi platforms and multi encodings.
Quick Overview
Ugrep is a ultra-fast, user-friendly, and feature-rich grep search tool for the command line. It combines the power of traditional grep with modern enhancements, offering improved performance and a wide range of search capabilities for files, directories, and compressed archives.
Pros
- Ultra-fast search performance, especially for large files and directories
- Rich feature set, including fuzzy search, binary file search, and compressed file search
- User-friendly interface with color-coded output and intuitive command-line options
- Cross-platform compatibility (Linux, macOS, Windows)
Cons
- May require learning new syntax for advanced features compared to traditional grep
- Larger binary size compared to standard grep
- Some users may find the extensive feature set overwhelming at first
Getting Started
To get started with ugrep, follow these steps:
-
Install ugrep:
- On macOS:
brew install ugrep - On Linux: Check your package manager or build from source
- On Windows: Download the binary from the GitHub releases page
- On macOS:
-
Basic usage:
ugrep "pattern" file.txt ugrep -r "pattern" directory/ -
Fuzzy search:
ugrep -Z "approximate pattern" file.txt -
Search in compressed files:
ugrep -z "pattern" archive.zip
For more advanced usage and options, refer to the ugrep documentation or run ugrep --help.
Competitor Comparisons
ripgrep recursively searches directories for a regex pattern while respecting your gitignore
Pros of ripgrep
- Faster performance, especially for large codebases
- Better handling of binary files and gitignore rules
- More widespread adoption and community support
Cons of ripgrep
- Limited Unicode support compared to ugrep
- Fewer advanced features and search options
- Less flexible output formatting capabilities
Code Comparison
ripgrep:
pub fn search<R: io::Read>(reader: R) -> io::Result<()> {
let mut grep = grep::Config::new();
grep.line_number(true);
grep.search_zip(false);
grep.run(&mut io::BufReader::new(reader))
}
ugrep:
void search(const char *pattern, const char *filename) {
ugrep::Grep grep(pattern);
grep.set_files(filename);
grep.set_color("auto");
grep.set_line_number(true);
grep.run();
}
Both ripgrep and ugrep are powerful search tools, but they have different strengths. ripgrep excels in speed and handling large codebases, while ugrep offers more advanced features and better Unicode support. The code comparison shows that ripgrep uses Rust, which may contribute to its performance advantages, while ugrep is written in C++. Ultimately, the choice between the two depends on specific use cases and requirements.
A simple, fast and user-friendly alternative to 'find'
Pros of fd
- Written in Rust, offering better performance and memory safety
- Simpler syntax and easier to use for basic file finding tasks
- Colorized output by default, enhancing readability
Cons of fd
- Limited to file finding, lacks advanced text search capabilities
- Does not support complex regex patterns or multi-line matching
- Less versatile for advanced search and replace operations
Code Comparison
fd:
fd -e txt
ugrep:
ugrep -l '.' **/*.txt
fd focuses on simplicity for file finding, while ugrep offers more advanced text searching capabilities. fd's syntax is more intuitive for basic tasks, but ugrep provides greater flexibility for complex search operations.
fd is ideal for users who primarily need quick file location, while ugrep is better suited for those requiring powerful text search and manipulation features. fd's Rust implementation may offer performance benefits in certain scenarios, but ugrep's C++ codebase provides a wider range of functionality.
Both tools have their strengths, and the choice between them depends on the specific needs of the user. For simple file finding, fd may be preferable, while ugrep is more appropriate for advanced text searching and processing tasks.
:cherry_blossom: A command-line fuzzy finder
Pros of fzf
- Interactive and real-time fuzzy search capabilities
- Highly versatile, can be integrated with various tools and workflows
- Lightweight and fast, with minimal system resource usage
Cons of fzf
- Limited to fuzzy finding and doesn't offer advanced text search features
- Requires additional setup for complex use cases or integrations
- Less suitable for searching through large codebases or multiple files simultaneously
Code comparison
fzf (interactive fuzzy finder):
find * -type f | fzf > selected
ugrep (advanced grep-like search):
ugrep -Q 'pattern' --include='*.txt' .
Key differences
- fzf focuses on interactive fuzzy finding, while ugrep is a powerful grep alternative
- ugrep offers more advanced search capabilities, including regex and multi-file search
- fzf is better suited for quick file navigation, while ugrep excels in complex text searches
Use cases
- fzf: Command-line history search, file navigation, and interactive filtering
- ugrep: Code search, log analysis, and advanced text pattern matching across multiple files
Both tools have their strengths and can complement each other in a developer's toolkit, depending on the specific task at hand.
A code-searching tool similar to ack, but faster.
Pros of the_silver_searcher
- Faster performance for searching large codebases
- Lower memory usage, especially for large projects
- Simpler command-line interface, easier for beginners
Cons of the_silver_searcher
- Limited file type support compared to ugrep
- Fewer advanced search options and features
- Less frequent updates and maintenance
Code Comparison
the_silver_searcher:
ag "pattern" /path/to/search
ugrep:
ugrep "pattern" /path/to/search
Both tools offer similar basic usage, but ugrep provides more advanced options:
ugrep -Q "pattern" --include="*.{cpp,h}" /path/to/search
This example demonstrates ugrep's ability to use fuzzy matching (-Q) and specify file types to include in the search, which are not available in the_silver_searcher.
While the_silver_searcher excels in speed and simplicity, ugrep offers more powerful features and flexibility. the_silver_searcher is ideal for quick searches in large codebases, while ugrep is better suited for complex search tasks and working with various file types. The choice between the two depends on the specific needs of the user and the nature of the project.
A code search tool similar to ack and the_silver_searcher(ag). It supports multi platforms and multi encodings.
Pros of the_platinum_searcher
- Written in Go, which can offer better cross-platform compatibility
- Supports multiple file types and encodings out of the box
- Simple and straightforward command-line interface
Cons of the_platinum_searcher
- Less feature-rich compared to ugrep
- May have slower performance for certain search operations
- Limited regular expression support compared to ugrep's extensive options
Code Comparison
the_platinum_searcher:
cmd := exec.Command("pt", "pattern", "directory")
output, err := cmd.Output()
if err != nil {
log.Fatal(err)
}
ugrep:
UGrep grep;
grep.addPattern("pattern");
grep.searchFiles("directory");
if (grep.getCount() > 0) {
std::cout << grep.getResults() << std::endl;
}
The code snippets demonstrate basic usage for each tool. the_platinum_searcher uses a command-line execution approach, while ugrep provides a more integrated C++ API for searching. ugrep offers more fine-grained control over search operations and result handling, whereas the_platinum_searcher relies on command-line arguments for configuration.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()
![]()
The ugrep file pattern searcher
[ README | User Guide | Indexing | Benchmarks | Q&A ]
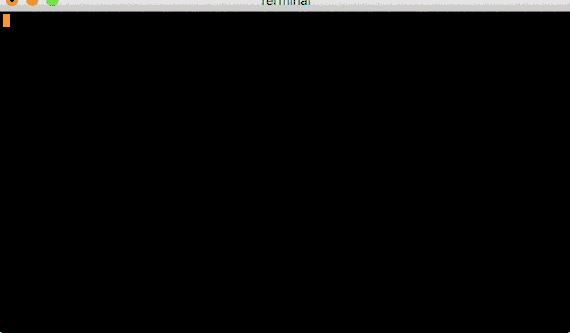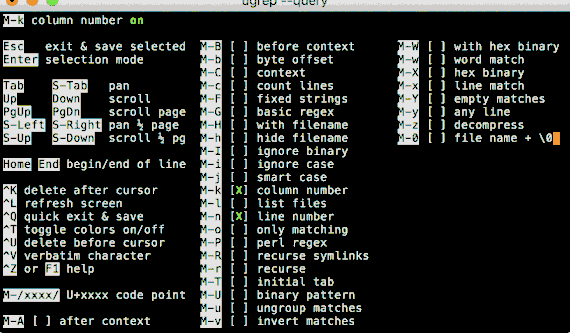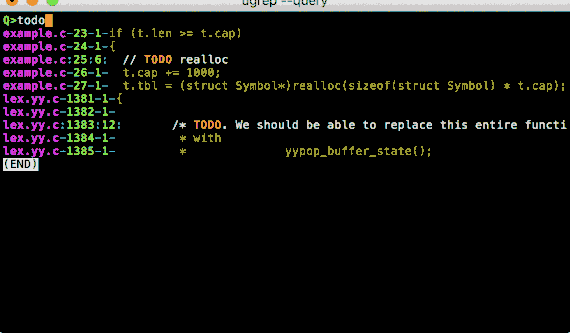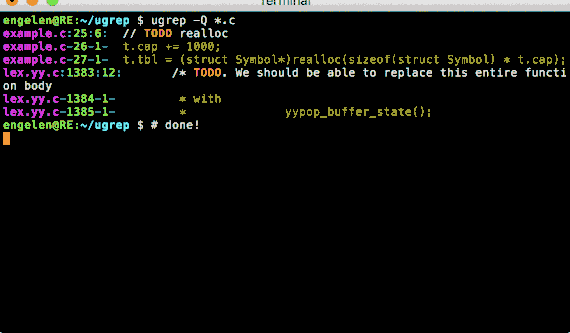
option -Q opens a query TUI to search files as you type!
Why use ugrep?
-
ugrep is compatible to GNU/BSD grep, but much faster and with a ton of new features
-
ugrep is a drop-in replacement for BSD and GNU grep (copy or symlink
ugtogrep, and toegrepand tofgrep), unlike other popular grep claiming to be "grep alternatives" or "replacements" when those actually implement incompatible command-line options and use an incompatible regex matcher, i.e. Perl regex only versus POSIX BRE (grep) and ERE (egrep) when ugrep supports all regex modes -
ugrep is typically faster than rg, ag, and GNU grep using the high-performance regex engine RE/flex
-
full Unicode extended regex pattern syntax with multi-line pattern matching without any special command-line options
-
includes an interactive TUI with built-in help, Google-like search with AND/OR/NOT patterns, fuzzy search, search (nested) zip/7z/tar/pax/cpio archives, tarballs and compressed files gz/Z/bz/bz2/lzma/xz/lz4/zstd/brotli, search and hexdump binary files, search documents such as PDF, doc, docx, and output in JSON, XML, CSV or your own customized format
-
includes a file indexer to speed up searching slow and cold file systems
Development roadmap
if something should be improved or added to ugrep, then let me know!
-
#1 priority is quality assurance to make sure ugrep is reliable, see testing and validation
-
make ugrep run even faster and share reproducible performance results
Overview
Commands
-
ugis for interactive use, which loads an optional .ugrep configuration file with your preferences located in the working directory or home directory,ug+also searches pdfs, documents, e-books, image metadata -
ugrepfor batch use like GNU grep without a .ugrep configuration file,ugrep+also searches pdfs, documents, e-books, image metadata
What does ugrep add that GNU grep does not support?
-
Matches Unicode patterns by default and automatically searches UTF-8, UTF-16 and UTF-32 encoded files
-
Matches multiple lines with
\nor\Rin regex patterns, no special options are required to do so! -
Built-in help:
ug --help, whereug --help WHATdisplays options related toWHATyou are looking forð¡
ug --help regex,ug --help globs,ug --help fuzzy,ug --help format. -
User-friendly with customizable configuration files used by the
ugcommand intended for interactive use that loads a .ugrep configuration file with your preferencesug PATTERN ... ugrep --config PATTERN ...ð¡
ug --save-config ...options-you-want-to-save...saves a .ugrep config file in the working directory so that the next time you runugthere it uses these options. Do this in your home directory to save a .ugrep config file with options you generally want to use. -
Interactive query TUI, press F1 or CTRL-Z for help and TAB/SHIFT-TAB to navigate to dirs and files
ug -Q ug -Q -e PATTERNð¡
-QreplacesPATTERNon the command line to let you enter patterns interactively in the TUI. In the TUI use ALT+letter keys to toggle short "letter options" on/off, for example ALT-n (option-n) to show/hide line numbers. -
Search the contents of archives (zip, tar, pax, jar, cpio, 7z) and compressed files (gz, Z, bz, bz2, lzma, xz, lz4, zstd, brotli)
ug -z PATTERN ... ug -z --zmax=2 PATTERN ...ð¡ specify
-z --zmax=2to search compressed files and archives nested within archives. The--zmaxargument may range from 1 (default) to 99 for up to 99 decompression and de-archiving steps to search nested archives -
Search with Google-like Boolean query patterns using
-%patterns withAND(or just space),OR(or a bar|),NOT(or a dash-), using quotes to match exactly, and grouping with( )(shown on the left side below); or with options-e(as an "or"),--and,--andnot, and--notregex patterns (shown on the right side below):ug -% 'A B C' ... ug -e 'A' --and 'B' --and 'C' ... ug -% 'A|B C' ... ug -e 'A' -e 'B' --and 'C' ... ug -% 'A -B -C' ... ug -e 'A' --andnot 'B' --andnot 'C' ... ug -% 'A -(B|C)'... ug -e 'A' --andnot 'B' --andnot 'C' ... ug -% '"abc" "def"' ... ug -e '\Qabc\E' --and '\Qdef\E' ...where
A,BandCare arbitrary regex patterns (use option-Fto search strings)ð¡ specify option
-%%(--bool --files) to apply the Boolean query to files as a whole: a file matches if all Boolean conditions are satisfied by matching patterns file-wide. Otherwise, Boolean conditions apply to single lines by default, since grep utilities are generally line-based pattern matchers. Option--statsdisplays the query in human-readable form after the search completes. -
Search pdf, doc, docx, e-book, and more with
ug+using filters associated with filename extensions:ug+ PATTERN ...or specify
--filterwith a file type to use a filter utility:ug --filter='pdf:pdftotext % -' PATTERN ... ug --filter='doc:antiword %' PATTERN ... ug --filter='odt,docx,epub,rtf:pandoc --wrap=preserve -t plain % -o -' PATTERN ... ug --filter='odt,doc,docx,rtf,xls,xlsx,ppt,pptx:soffice --headless --cat %' PATTERN ... ug --filter='pem:openssl x509 -text,cer,crt,der:openssl x509 -text -inform der' PATTERN ... ug --filter='latin1:iconv -f LATIN1 -t UTF-8' PATTERN ...ð¡ the
ug+command is the same as theugcommand, but also uses filters to search PDFs, documents, and image metadata -
Display horizontal context with option
-o(--only-matching) and context options-ABC, e.g. to find matches in very long lines, such as Javascript and JSON sources:ug -o -C20 -nk PATTERN longlines.jsð¡
-o -C20fits all matches with context in 20 characters before and 20 charactess after a match (i.e. 40 Unicode characters total),-nkoutputs line and column numbers. -
Find approximate pattern matches with fuzzy search, within the specified Levenshtein distance
ug -Z PATTERN ... ug -Z3 PATTTERN ...ð¡
-Znmatches up tonextra, missing or replaced characters,-Z+nmatches up tonextra characters,-Z-nmatches with up tonmissing characters and-Z~nmatches up tonreplaced characters.-Zdefaults to-Z1. -
Fzf-like search with regex (or fixed strings with
-F), fuzzy matching with up to 4 extra characters with-Z+4and words only with-w, using-%%for file-wide Boolean searchesug -Q -%% -l -w -Z+4 --sort=bestð¡
-llists the matching files in the TUI, pressTABthenALT-yto view a file,SHIFT-TABandAlt-lto go back to view the list of matching files ordered by best match -
Search binary files and display hexdumps with binary pattern matches (Unicode text or
-Ufor byte patterns)ug --hexdump -U BYTEPATTERN ... ug --hexdump TEXTPATTERN ... ug -X -U BYTEPATTERN ... ug -X TEXTPATTERN ... ug -W -U BYTEPATTERN ... ug -W TEXTPATTERN ...ð¡
--hexdump=4chC1displays4columns of hex without a character columnc, no hex spacingh, and with one extra hex lineC1before and after a match. -
Include files to search by file types or file "magic bytes" or exclude them with
^ug -t TYPE PATTERN ... ug -t ^TYPE PATTERN ... ug -M 'MAGIC' PATTERN ... ug -M '^MAGIC' PATTERN ... -
Include files and directories to search that match gitignore-style globs or exclude them with
^ug -g 'FILEGLOB' PATTERN ... ug -g '^FILEGLOB' PATTERN ... ug -g 'DIRGLOB/' PATTERN ... ug -g '^DIRGLOB/' PATTERN ... ug -g 'PATH/FILEGLOB' PATTERN ... ug -g '^PATH/FILEGLOB' PATTERN ... ug -g 'PATH/DIRGLOB/' PATTERN ... ug -g '^PATH/DIRGLOB/' PATTERN ... -
Include files to search by filename extensions (suffix) or exclude them with
^, a shorthand for-g"*.EXT"ug -O EXT PATTERN ... ug -O ^EXT PATTERN ... -
Include hidden files (dotfiles) and directories to search (omitted by default)
ug -. PATTERN ... ug -g'.*,.*/' PATTERN ...ð¡ specify
hiddenin your .ugrep to always search hidden files withug. -
Exclude files specified by .gitignore etc.
ug --ignore-files PATTERN ... ug --ignore-files=.ignore PATTERN ...ð¡ specify
ignore-filesin your .ugrep to always ignore them withug. Add additionalignore-files=...as desired. -
Search patterns excluding negative patterns ("match this but not that")
ug -e PATTERN -N NOTPATTERN ... ug -e '[0-9]+' -N 123 ... -
Use predefined regex patterns to search source code, javascript, XML, JSON, HTML, PHP, markdown, etc.
ug PATTERN -f c++/zap_comments -f c++/zap_strings ... ug PATTERN -f php/zap_html ... ug -f js/functions ... | ug PATTERN ... -
Sort matching files by name, best match, size, and time
ug --sort PATTERN ... ug --sort=size PATTERN ... ug --sort=changed PATTERN ... ug --sort=created PATTERN ... ug -Z --sort=best PATTERN ... ug --no-sort PATTERN ... -
Output results in CSV, JSON, XML, and user-specified formats
ug --csv PATTERN ... ug --json PATTERN ... ug --xml PATTERN ... ug --format='file=%f line=%n match=%O%~' PATTERN ...ð¡
ug --help formatdisplays help on format%fields for customized output. -
Search with PCRE's Perl-compatible regex patterns and display or replace subpattern matches
ug -P PATTERN ... ug -P --format='%1 and %2%~' 'PATTERN(SUB1)(SUB2)' ... -
Replace patterns in the output with -P and --replace replacement text, optionally containing
%formatting fields, using-yto pass the rest of the file through:ug --replace='TEXT' PATTERN ... ug -y --replace='TEXT' PATTERN ... ug --replace='(%m:%o)' PATTERN ... ug -y --replace='(%m:%o)' PATTERN ... ug -P --replace='%1' PATTERN ... ug -y -P --replace='%1' PATTERN ...ð¡
ug --help formatdisplays help on format%fields to optionally use with--replace. -
Search files with a specific encoding format such as ISO-8859-1 thru 16, CP 437, CP 850, MACROMAN, KOI8, etc.
ug --encoding=LATIN1 PATTERN ...
Table of contents
- How to install
- Performance comparisons
- Using ugrep within Vim
- Using ugrep within Emacs
- Using ugrep to replace GNU/BSD grep
- Tutorial
- Examples
- Advanced examples
- Displaying helpful info
- Configuration files
- Interactive search with -Q
- Recursively list matching files with -l, -R, -r, --depth, -g, -O, and -t
- Boolean query patterns with -%, -%%, --and, --not
- Search this but not that with -v, -e, -N, -f, -L, -w, -x
- Search non-Unicode files with --encoding
- Matching multiple lines of text
- Displaying match context with -A, -B, -C, and -y
- Searching source code using -f, -O, and -t
- Searching compressed files and archives with -z
- Find files by file signature and shebang "magic bytes" with -M, -O and -t
- Fuzzy search with -Z
- Search hidden files with -.
- Using filter utilities to search documents with --filter
- Searching and displaying binary files with -U, -W, and -X
- Ignore binary files with -I
- Ignoring .gitignore-specified files with --ignore-files
- Using gitignore-style globs to select directories and files to search
- Including or excluding mounted file systems from searches
- Counting the number of matches with -c and -co
- Displaying file, line, column, and byte offset info with -H, -n, -k, -b, and -T
- Displaying colors with --color and paging the output with --pager
- Output matches in JSON, XML, CSV, C++
- Customize output with --format
- Replacing matches with -P --replace and --format using backreferences
- Limiting the number of matches with -1,-2...-9, -K, -m, and --max-files
- Matching empty patterns with -Y
- Case-insensitive matching with -i and -j
- Sort files by name, best match, size, and time
- Tips for advanced users
- More examples
- Man page
- Regex patterns
- Troubleshooting
How to install
MacOS
Install the latest ugrep with Homebrew:
$ brew install ugrep
or install with MacPorts:
$ sudo port install ugrep
This installs the ugrep and ug commands, where ug is the same as ugrep
but also loads the configuration file .ugrep when present in the working
directory or home directory.
Windows
Install with Winget
winget install Genivia.ugrep
Or install with Chocolatey
choco install ugrep
Or install with Scoop scoop install ugrep
Or download the full-featured ugrep.exe executable as release artifact from
https://github.com/Genivia/ugrep/releases. The zipped release contains the
main ugrep.exe binary as well as ug.exe. The ug command, intended for
interactive use, loads and reads in settings from the .ugrep configuration
file (when present in the working directory or home directory).
Add ugrep.exe and ug.exe to your execution path: go to Settings and
search for "Path" in Find a Setting. Select environment variables ->
Path -> New and add the directory where you placed the ugrep.exe and
ug.exe executables.
[!TIP] Practical hints on using
ugrep.exeandug.exeon the Windows command line:
- when quoting patterns and arguments on the command line, do not use single
'quotes but use"instead; most Windows command utilities consider the single'quotes part of the command-line argument!- file and directory globs are best specified with option
-g/GLOBinstead of the usualGLOBcommand line arguments to select files and directories to search, especially for recursive searches;- when specifying an empty pattern
""to match all input, this may be ignored by some Windows command interpreters such as Powershell, in that case you must specify option--matchinstead;- to match newlines in patterns, you may want to use
\Rinstead of\nto match any Unicode newlines, such as\r\npairs and single\rand\n.
Alpine Linux
$ apk add ugrep ugrep-doc
Check https://pkgs.alpinelinux.org/packages?name=ugrep for version info.
Arch Linux
$ pacman -S ugrep
Check https://archlinux.org/packages/extra/x86_64/ugrep for version info.
CentOS
First enable the EPEL repository, then you can install ugrep.
$ dnf install ugrep
Check https://packages.fedoraproject.org/pkgs/ugrep/ugrep/ for version info.
Debian
$ apt-get install ugrep
Check https://packages.debian.org/ugrep for version info. To build and try
ugrep locally, see "All platforms" build steps further below.
Fedora
$ dnf install ugrep
Check https://packages.fedoraproject.org/pkgs/ugrep/ugrep/ for version info.
FreeBSD
$ pkg install ugrep
Check https://www.freshports.org/textproc/ugrep for version info.
Haiku
$ pkgman install cmd:ugrep
Check https://github.com/haikuports/haikuports/tree/master/app-text/ugrep for
version info. To build and try ugrep locally, see "All platforms" build
steps further below.
NetBSD
You can use the standard NetBSD package installer (pkgsrc): http://cdn.netbsd.org/pub/pkgsrc/current/pkgsrc/textproc/ugrep/README.html
OpenBSD
$ pkg_add ugrep
Check https://openports.pl/path/sysutils/ugrep for version info.
OpenSUSE
$ zypper install ugrep
Check https://build.opensuse.org/package/show/utilities/ugrep for version info.
RHEL
First enable the EPEL repository, then you can install ugrep.
$ dnf install ugrep
Check https://packages.fedoraproject.org/pkgs/ugrep/ugrep/ for version info.
Other platforms: step 1 download
Clone ugrep with
$ git clone https://github.com/Genivia/ugrep
Or visit https://github.com/Genivia/ugrep/releases to download a specific release.
Other platforms: step 2 consider optional dependencies
You can always add these later, when you need these features:
-
Option
-P(Perl regular expressions) requires either the PCRE2 library (recommended) or the Boost.Regex library (optional fallback). If PCRE2 is not installed, install PCRE2 with e.g.sudo apt-get install -y libpcre2-devor download PCRE2 and follow the installation instructions. Alternatively, download Boost.Regex and run./bootstrap.shandsudo ./b2 --with-regex install. See Boost: getting started. -
Option
-z(compressed files and archives search) requires the zlib library installed. It is installed on most systems. If not, install it, e.g. withsudo apt-get install -y libz-dev. To search.bzand.bz2files, install the bzip2 library (recommended), e.g. withsudo apt-get install -y libbz2-dev. To search.lzmaand.xzfiles, install the lzma library (recommended), e.g. withsudo apt-get install -y liblzma-dev. To search.lz4files, install the lz4 library (optional, not required), e.g. withsudo apt-get install -y liblz4-dev. To search.zstfiles, install the zstd library (optional, not required), e.g. withsudo apt-get install -y libzstd-dev. To search.brfiles, install the brotli library (optional, not required), e.g. withsudo apt-get install -y libbrotli-dev. To search.bz3files, install the bzip3 library (optional, not required), e.g. withsudo apt-get install -y bzip3.
[!TIP] Even if your system has command line utilities, such as
bzip2, that does not necessarily mean that the development libraries such aslibbz2are installed. The development libraries should be installed.Some Linux systems may not be configured to load dynamic libraries from
/usr/local/lib, causing a library load error when runningugrep. To correct this, addexport LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/lib"to your~/.bashrcfile. Or runsudo ldconfig /usr/local/lib.
Other platforms: step 3 build
Execute the ./build.sh script to build ugrep:
$ cd ugrep
$ ./build.sh
This builds the ugrep executable in the ugrep/src directory with
./configure and make -j, verified with make test. When all tests pass,
the ugrep executable is copied to ugrep/bin/ugrep and the symlink
ugrep/bin/ug -> ugrep/bin/ugrep is added for the ug command.
Note that ug is the same as ugrep but also loads the configuration file
.ugrep when present in the working directory or home directory. This means
that you can define your default options for ug in .ugrep.
Alternative paths to installed or local libraries may be specified with
./build.sh. To get help on the available build options:
$ ./build.sh --help
You can build static executables by specifying:
$ ./build.sh --enable-static
This may fail if libraries don't link statically, such as brotli. In that case
try ./build.sh --enable-static --without-brotli.
You can build ugrep with customized defaults enabled, such as a pager:
$ ./build.sh --enable-pager
Options to select defaults for builds include:
--helpdisplay build options--enable-staticbuild static executables, if possible--enable-hiddenalways search hidden files and directories--enable-pageralways use a pager to display output on terminals--enable-prettycolorize output to terminals and add filename headings--disable-auto-colordisable automatic colors, requires ugrep option--color=autoto show colors--disable-mmapdisable memory mapped files--disable-sse2disable SSE2 and AVX optimizations--disable-avx2disable AVX2 and AVX512BW optimizations, but compile with SSE2 when supported--disable-neondisable ARM NEON/AArch64 optimizations--with-grep-paththe default-fpath ifGREP_PATHis not defined--with-grep-colorsthe default colors ifGREP_COLORSis not defined
After the build completes, copy ugrep/bin/ugrep and ugrep/bin/ug to a
convenient location, for example in your ~/bin directory. Or, if you may want
to install the ugrep and ug commands and man pages:
$ sudo make install
This also installs the pattern files with predefined patterns for option -f
at /usr/local/share/ugrep/patterns/. Option -f first checks the working
directory for the presence of pattern files, if not found checks environment
variable GREP_PATH to load the pattern files, and if not found reads the
installed predefined pattern files.
Troubleshooting
Git and timestamps
Unfortunately, git clones do not preserve timestamps which means that you may
run into "WARNING: 'aclocal-1.15' is missing on your system." or that
autoheader was not found when running make.
To work around this problem, run:
$ autoreconf -fi
$ ./build.sh
Compiler warnings
GCC 8 and greater may produce warnings of the sort "note: parameter passing for argument ... changed in GCC 7.1". These warnings should be ignored.
Dockerfile for developers
A Dockerfile is included to build ugrep in a Ubuntu container.
Developers may want to use sanitizers to verify the ugrep code when making significant changes, for example to detect data races with the ThreadSanitizer:
$ ./build.sh CXXFLAGS='-fsanitize=thread -O1 -g'
We checked ugrep with the clang AddressSanitizer, MemorySanitizer,
ThreadSanitizer, and UndefinedBehaviorSanitizer. These options incur
significant runtime overhead and should not be used for the final build.
ð Back to table of contents
Performance comparisons
Please note that the ugrep and ug commands search binary files by
default and do not ignore .gitignore specified files, which will not make
recursive search performance comparisons meaningful unless options -I and
--ignore-files are used. To make these options the default for ug,
simply add ignore-binary and ignore-files to your .ugrep configuration
file.
For an up-to-date performance comparison of the latest ugrep, please see the ugrep performance benchmarks. Ugrep is faster than GNU grep, Silver Searcher, ack, sift. Ugrep's speed beats ripgrep in most benchmarks.
Using ugrep within Vim
First, let's define the :grep command in Vim to search files recursively. To
do so, add the following lines to your .vimrc located in the root directory:
if executable('ugrep')
set grepprg=ugrep\ -RInk\ -j\ -u\ --tabs=1\ --ignore-files
set grepformat=%f:%l:%c:%m,%f+%l+%c+%m,%-G%f\\\|%l\\\|%c\\\|%m
endif
This specifies -j case insensitive searches with the Vim :grep
command. For case sensitive searches, remove \ -j from grepprg. Multiple
matches on the same line are listed in the quickfix window separately. If this
is not desired, remove \ -u from grepprg. With this change, only the first
match on a line is shown. Option --ignore-files skips files specified in
.gitignore files, when present. To limit the depth of recursive searches to
the current directory only, append \ -1 to grepprg.
You can now invoke the Vim :grep command in Vim to search files on a
specified PATH for PATTERN matches:
:grep PATTERN [PATH]
If you omit PATH, then the working directory is searched. Use % as PATH
to search only the currently opened file in Vim:
:grep PATTERN %
The :grep command shows the results in a
quickfix window
that allows you to quickly jump to the matches found.
To open a quickfix window with the latest list of matches:
:copen
Double-click on a line in this window (or select a line and press ENTER) to
jump to the file and location in the file of the match. Enter commands :cn
and :cp to jump to the next or previous match, respectively. To update the
search results in the quickfix window, just grep them. For example, to
recursively search C++ source code marked FIXME in the working directory:
:grep -tc++ FIXME
To close the quickfix window:
:cclose
You can use ugrep options with the :grep command, for example to
select single- and multi-line comments in the current file:
:grep -f c++/comments %
Only the first line of a multi-line comment is shown in quickfix, to save
space. To show all lines of a multi-line match, remove %-G from
grepformat.
A popular Vim tool is ctrlp.vim, which is installed with:
$ cd ~/.vim
$ git clone https://github.com/kien/ctrlp.vim.git bundle/ctrlp.vim
CtrlP uses ugrep by adding the following lines to your .vimrc:
if executable('ugrep')
set runtimepath^=~/.vim/bundle/ctrlp.vim
let g:ctrlp_match_window='bottom,order:ttb'
let g:ctrlp_user_command='ugrep "" %s -Rl -I --ignore-files -3'
endif
where -I skips binary files, option --ignore-files skips files specified in
.gitignore files, when present, and option -3 restricts searching
directories to three levels (the working directory and up to two levels below).
Start Vim then enter the command:
:helptags ~/.vim/bundle/ctrlp.vim/doc
To view the CtrlP documentation in Vim, enter the command:
:help ctrlp.txt
ð Back to table of contents
Using ugrep within Emacs
Thanks to Manuel Uberti,
you can now use ugrep in Emacs. To use ugrep instead of GNU grep
within Emacs, add the following line to your .emacs.d/init.el file:
(setq-default xref-search-program âugrep)
This means that Emacs commands such as project-find-regexp that rely on
Xref can
now leverage the power of ugrep.
Furthermore, it is possible to use grep in the Emacs grep
commands.
For instance, you can run lgrep with ugrep by customizing grep-template
to something like the following:
(setq-default grep-template "ugrep --color=always -0Iinr -e <R>")
If you do not have Emacs version 29 (or greater) you can download and build Emacs from the Emacs master branch, or enable Xref integration with ugrep manually:
(with-eval-after-load 'xref
(push '(ugrep . "xargs -0 ugrep <C> --null -ns -e <R>")
xref-search-program-alist)
(setq-default xref-search-program 'ugrep))
ð Back to table of contents
Using ugrep to replace GNU/BSD grep
ugrep supports all standard GNU/BSD grep command-line options and improves many of them too. See notable improvements over grep.
In fact, executing ugrep with options -U, -Y, -. and --sort makes it
behave like egrep, permitting empty patterns to match and search hidden files
instead of ignoring them. See grep equivalence.
-
You can create convenient grep aliases with or without options
-Y,-.and--sortor include other options as desired. If you really must stick exactly to GNU/BSD grep ASCII/LATIN1 patterns, use options-Uand--grepto disable Unicode pattern matching and to reassign options-zand-Zto--null-dataand--null, respectively. -
You can also create
grep,egrepandfgrepexecutables by symlinking or copyingugrepto those names. When theugrep(orugrep.exe) executable is copied asgrep(grep.exe),egrep(egrep.exe),fgrep(fgrep.exe), then options-Yand-.are automatically enabled together with either-Gforgrep,-Eforegrepand-Fforfgrep. In addition, when copied aszgrep,zegrepandzfgrep, option--decompressis enabled. For example, whenugrepis copied aszegrep, options--decompress,-E,-Y,-.and--sortare enabled. -
Likewise, symlinks and hard links can be used to create
grep,egrepandfgrepreplacements in the usual installation directories. For example:sudo ln -s `which ugrep` /opt/local/bin/grep sudo ln -s `which ugrep` /opt/local/bin/egrep sudo ln -s `which ugrep` /opt/local/bin/fgrep sudo ln -s `which ugrep` /opt/local/bin/zgrep sudo ln -s `which ugrep` /opt/local/bin/zegrep sudo ln -s `which ugrep` /opt/local/bin/zfgrepThe
/opt/local/binhere is an example and may or may not be in your$pathand may or may not be found, so please adjust as necessary. Caution: bash does not obey the linked name when executing the program, reverting to the nameugrepinstead, which negates all internal compatibility settings. To avoid this, copy the executables instead of linking!
When linking or copying ugrep to grep, egrep, fgrep, zgrep, zegrep,
zfgrep, options -z and -Z are reassigned for compatibility to GNU/BSD
grep options --null-data and --null, respectively.
Equivalence to GNU/BSD grep
When the ugrep executable file is symlinked or copied to grep, egrep,
fgrep, zgrep, zegrep and zfgrep executables, then those executables
will behave as GNU grep equivalents. This behavior is implicit and automatic,
essentially using the following translations:
grep = ugrep -G -Y -. --sort
egrep = ugrep -E -Y -. --sort
fgrep = ugrep -F -Y -. --sort
zgrep = ugrep -z -G -Y -. --sort
zegrep = ugrep -z -E -Y -. --sort
zfgrep = ugrep -z -F -Y -. --sort
please note that:
-Yenables empty matches, so for example the patterna*matches every line instead of a sequence ofa's. By default in ugrep, the patterna*matches a sequence ofa's. Moreover, in ugrep the patterna*b*c*matches what it is supposed to match by default. See improvements.-.searches hidden files (dotfiles). By default, hidden files are ignored, like most Unix utilities.--sortspecifies output sorted by pathname, showing sorted matching files first followed by sorted recursive matches in subdirectories. Otherwise, matching files are reported in no particular order to improve performance;- options
-zand-Zare reassigned to--null-dataand--nulland no longer enable--decompressand--fuzzysearching modes.
There is one minor difference with GNU/BSD grep:
- GNU/BSD grep defaults to
-Dreadand-dreadwhich are not recommended, see improvements for an explanation.
ð Back to table of contents
Short and quick command aliases
Commonly-used aliases to add to .bashrc to increase productivity:
alias uq = 'ug -Q' # interactive TUI search (uses .ugrep config)
alias uz = 'ug -z' # compressed files and archives search (uses .ugrep config)
alias ux = 'ug -U --hexdump' # binary pattern search (uses .ugrep config)
alias ugit = 'ug -R --ignore-files' # works like git-grep & define your preferences in .ugrep config
alias grep = 'ug -G' # search with basic regular expressions (BRE) like grep
alias egrep = 'ug -E' # search with extended regular expressions (ERE) like egrep
alias fgrep = 'ug -F' # find string(s) like fgrep
alias zgrep = 'ug -zG' # search compressed files and archives with BRE
alias zegrep = 'ug -zE' # search compressed files and archives with ERE
alias zfgrep = 'ug -zF' # find string(s) in compressed files and/or archives
alias xdump = 'ugrep -X ""' # hexdump files without searching (don't use .ugrep config)
alias zmore = 'ugrep+ -z -I -+ --pager ""' # view compressed, archived and regular files (don't use .ugrep config)
ð Back to table of contents
Notable improvements over grep
- ugrep starts an interactive query TUI with option
-Q. - ugrep matches patterns across multiple lines when patterns match
\n. - ugrep matches full Unicode by default (disabled with option
-U). - ugrep supports Boolean patterns with AND, OR and NOT (option
--bool). - ugrep supports gitignore with option
--ignore-files. - ugrep supports fuzzy (approximate) matching with option
-Z. - ugrep supports user-defined global and local configuration files.
- ugrep searches compressed files and archives with option
-z. - ugrep searches cpio, jar, pax, tar, zip and 7z archives with option
-z. - ugrep searches cpio, jar, pax, tar, zip and 7z archives recursively
stored within archives with
-zand--zmax=NUMfor up toNUMlevels deep. - ugrep searches pdf, doc, docx, xls, xlsx, epub, and more with
--filterusing third-party format conversion utilities as plugins. - ugrep searches a directory when the FILE argument is a directory, like
most Unix/Linux utilities; use option
-rto search directories recursively. - ugrep does not match hidden files by default like most Unix/Linux
utilities (hidden dotfile file matching is enabled with
-.). - ugrep regular expression patterns are more expressive than GNU grep and
BSD grep POSIX ERE and support Unicode pattern matching. Extended regular
expression (ERE) syntax is the default (i.e. option
-Eas egrep, whereas-Genables BRE). - ugrep spawns threads to search files concurrently to improve search
speed (disabled with option
-J1). - ugrep produces hexdumps with
-W(output binary matches in hex with text matches output as usual) and-X(output all matches in hex). - ugrep can output matches in JSON, XML, CSV and user-defined formats (with
option
--format). - ugrep option
-fusesGREP_PATHenvironment variable or the predefined patterns installed in/usr/local/share/ugrep/patterns. If-fis specified and also one or more-epatterns are specified, then options-F,-x, and-wdo not apply to-fpatterns. This is to avoid confusion when-fis used with predefined patterns that may no longer work properly with these options. - ugrep options
-O,-M, and-tspecify file extensions, file signature magic byte patterns, and predefined file types, respectively. This allows searching for certain types of files in directory trees, for example with recursive search options-Rand-r. Options-O,-M, and-talso applies to archived files in cpio, jar, pax, tar, zip and 7z files. - ugrep option
-k,--column-numberto display the column number, taking tab spacing into account by expanding tabs, as specified by option--tabs. - ugrep option
-P(Perl regular expressions) supports backreferences (with--format) and lookbehinds, which uses the PCRE2 or Boost.Regex library for fast Perl regex matching with a PCRE-like syntax. - ugrep option
-bwith option-oor with option-u, ugrep displays the exact byte offset of the pattern match instead of the byte offset of the start of the matched line reported by GNU/BSD grep. - ugrep option
-u,--ungroupto not group multiple matches per line. This option displays a matched input line again for each additional pattern match on the line. This option is particularly useful with option-cto report the total number of pattern matches per file instead of the number of lines matched per file. - ugrep option
-Yenables matching empty patterns. Grepping with empty-matching patterns is weird and gives different results with GNU grep versus BSD grep. Empty matches are not output by ugrep by default, which avoids making mistakes that may produce "random" results. For example, with GNU/BSD grep, patterna*matches every line in the input, and actually matchesxyzthree times (the empty transitions before and between thex,y, andz). Allowing empty matches requires ugrep option-Y. Patterns that start with^or end with$, such as^\h*$, match empty. These patterns automatically enable option-Y. - ugrep option
-D, --devices=ACTIONisskipby default, instead ofread. This prevents unexpectedly hanging on named pipes in directories that are recursively searched, as may happen with GNU/BSD grep thatreaddevices by default. - ugrep option
-d, --directories=ACTIONisskipby default, instead ofread. By default, directories specified on the command line are searched, but not recursively deeper into subdirectories. - ugrep offers negative patterns
-N PATTERN, which are patterns of the form(?^X)that skip allXinput, thus removingXfrom the search. For example, negative patterns can be used to skip strings and comments when searching for identifiers in source code and find matches that aren't in strings and comments. Predefinedzappatterns use negative patterns, for example, use-f cpp/zap_commentsto ignore pattern matches in C++ comments. - ugrep ignores the
GREP_OPTIONSenvironment variable, because the behavior of ugrep must be portable and predictable on every system. Also GNU grep abandonedGREP_OPTIONSfor this reason. Please use theugcommand that loads the .ugrep configuration file located in the working directory or in the home directory when present, or use shell aliases to create new commands with specific search options.
ð Back to table of contents
Tutorial
Examples
To perform a search using a configuration file .ugrep placed in the working
directory or home directory (note that ug is the same as ugrep --config):
ug PATTERN FILE...
To save a .ugrep configuration file to the working directory, then edit this
file in your home directory to customize your preferences for ug defaults:
ug --save-config
To search the working directory and recursively deeper for main (note that
-r recurse symlinks is enabled by default if no file arguments are
specified):
ug main
Same, but only search C++ source code files recursively, ignoring all other files:
ug -tc++ main
Same, using the interactive query TUI, starting with the initial search pattern
main (note that -Q with an initial pattern requires option -e because
patterns are normally specified interactively and all command line arguments
are considered files/directories):
ug -Q -tc++ -e main
To search for #define (and # define etc) using a regex pattern in C++ files
(note that patterns should be quoted to prevent shell globbing of * and ?):
ug -tc++ '#[\t ]*define'
To search for main as a word (-w) recursively without following symlinks
(-r) in directory myproject, showing the matching line (-n) and column
(-k) numbers next to the lines matched:
ug -r -nkw main myproject
Same, but only search myproject without recursing deeper (note that directory
arguments are searched at one level by default):
ug -nkw main myproject
Same, but search myproject and one subdirectory level deeper (two levels)
with -2:
ug -2 -nkw main myproject
Same, but only search C++ files in myproject and its subdirectories with
-tc++:
ug -tc++ -2 -nkw main myproject
Same, but also search inside archives (e.g. zip and tar files) and compressed
files with -z:
ug -z -tc++ -2 -nkw main myproject
Search recursively the working directory for main while ignoring gitignored
files (e.g. assuming .gitignore is in the working directory or below):
ug --ignore-files -tc++ -nkw main
To list all files in the working directory and deeper that are not ignored by
.gitignore file(s):
ug --ignore-files -l ''
To display the list of file name extensions and "magic bytes" (shebangs)
that are searched corresponding to -t arguments:
ug -tlist
To list all shell files recursively, based on extensions and shebangs with -l
(note that '' matches any non-empty file):
ug -l -tShell ''
ð Back to table of contents
Advanced examples
To search for main in source code while ignoring strings and comment blocks
you can use negative patterns with option -N to skip unwanted matches in
C/C++ quoted strings and comment blocks:
ug -r -nkw -e 'main' -N '"(\\.|\\\r?\n|[^\\\n"])*"|//.*|/\*(.*\n)*?.*\*+\/' myproject
This is a lot of work to type in correctly! If you are like me, I don't want
to spend time fiddling with regex patterns when I am working on something more
important. There is an easier way by using ugrep's predefined patterns
(-f) that are installed with the ugrep tool:
ug -r -nkw 'main' -f c/zap_strings -f c/zap_comments myproject
This query also searches through other files than C/C++ source code, like
READMEs, Makefiles, and so on. We're also skipping symlinks with -r. So
let's refine this query by selecting C/C++ files only using option -tc,c++
and include symlinks to files and directories with -R:
ug -R -tc,c++ -nkw 'main' -f c/zap_strings -f c/zap_comments myproject
What if you only want to look for the identifier main but not as a function
main(? In this case, use a negative pattern for this to skip unwanted
main\h*( pattern matches:
ug -R -tc,c++ -nkw -e 'main' -N 'main\h*\(' -f c/zap_strings -f c/zap_comments myproject
This uses the -e and -N options to explicitly specify a pattern and a
negative pattern, respectively, which is essentially forming the pattern
main|(?^main\h*\(), where \h matches space and tab. In general, negative
patterns are useful to filter out pattern matches that we are not interested
in.
As another example, let's say we may want to search for the word FIXME in
C/C++ comment blocks. To do so we can first select the comment blocks with
ugrep's predefined c/comments pattern AND THEN select lines with FIXME
using a pipe:
ug -R -tc,c++ -nk -f c/comments myproject | ug -w 'FIXME'
Filtering results with pipes is generally easier than using AND-OR logic that some search tools use. This approach follows the Unix spirit to keep utilities simple and use them in combination for more complex tasks.
Let's produce a sorted list of all identifiers found in Java source code while skipping strings and comments:
ug -R -tjava -f java/names myproject | sort -u
This matches Java Unicode identifiers using the regex
\p{JavaIdentifierStart}\p{JavaIdentifierPart}* defined in
patterns/java/names.
With traditional grep and grep-like tools it takes great effort to recursively
search for the C/C++ source file that defines function qsort, requiring
something like this:
ug -R --include='*.c' --include='*.cpp' '^([ \t]*[[:word:]:*&]+)+[ \t]+qsort[ \t]*\([^;\n]+$' myproject
Fortunately, with ugrep we can simply select all function definitions in
files with extension .c or .cpp by using option -Oc,cpp and by using a
predefined pattern functions that is installed with the tool to produce
all function definitions. Then we select the one we want:
ug -R -Oc,cpp -nk -f c/functions | ug 'qsort'
Note that we could have used -tc,c++ to select C/C++ files, but this also
includes header files when we want to only search .c and .cpp files.
We can also skip files and directories from being searched that are defined in
.gitignore. To do so we use --ignore-files to exclude any files and
directories from recursive searches that match the globs in .gitignore, when
one or more .gitignore files are found:
ug -R -tc++ --ignore-files -f c++/defines
This searches C++ files (-tc++) in the working directory for #define
lines (-f c++/defines), while skipping files and directories declared in
.gitignore. If you find this too long to type then define an alias to search
GitHub directories:
alias ugit='ugrep -R --ignore-files'
ugit -tc++ -f c++/defines
To highlight matches when pushed through a chain of pipes we should use
--color=always:
ugit --color=always -tc++ -f c++/defines | ugrep -w 'FOO.*'
This returns a color-highlighted list of all #define FOO... macros in C/C++
source code files, skipping files defined in .gitignore.
Note that the complement of --exclude is not --include, because exclusions
always take precedence over inclusions, so we cannot reliably list the files
that are ignored with --include-from='.gitignore'. Only files explicitly
specified with --include and directories explicitly specified with
--include-dir are visited. The --include-from from lists globs that are
considered both files and directories to add to --include and
--include-dir, respectively. This means that when directory names and
directory paths are not explicitly listed in this file then it will not be
visited using --include-from.
Because ugrep checks if the input is valid UTF-encoded Unicode (unless -U is
used), it is possible to use it as a filter to ignore non-UTF output produced
by a program:
program | ugrep -I ''
If the program produces valid output then the output is passed through,
otherwise the output is filtered out option -I. If the output is initially
valid for a very large portion but is followed by invalid output, then ugrep
may initially show the output up to but excluding the invalid output after
which further output is blocked.
To filter lines that are valid ASCII or UTF-encoded, while removing lines that are not:
program | ugrep '[\p{Unicode}--[\n]]+'
Note that \p{Unicode} matches \n but we don't want to matche the whole
file! Just lines with [\p{Unicode}--[\n]]+.
ð Back to table of contents
Displaying helpful info
The ugrep man page:
man ugrep
To show a help page:
ug --help
To show options that mention WHAT:
ug --help WHAT
To show a list of -t TYPES option values:
ug -tlist
In the interactive query TUI, press F1 or CTRL-Z for help and options:
ug -Q
ð Back to table of contents
Configuration files
--config[=FILE], ---[FILE]
Use configuration FILE. The default FILE is `.ugrep'. The working
directory is checked first for FILE, then the home directory. The
options specified in the configuration FILE are parsed first,
followed by the remaining options specified on the command line.
The ug command automatically loads a `.ugrep' configuration file,
unless --config=FILE or --no-config is specified.
--no-config
Do not load the default .ugrep configuration file.
--save-config[=FILE] [OPTIONS]
Save configuration FILE to include OPTIONS. Update FILE when
first loaded with --config=FILE. The default FILE is `.ugrep',
which is automatically loaded by the ug command. When FILE is a
`-', writes the configuration to standard output. Only part of the
OPTIONS are saved that do not cause searches to fail when combined
with other options. Additional options may be specified by editing
the saved configuration file. A configuration file may be modified
manually to specify one or more config[=FILE] to indirectly load
the specified FILEs, but recursive config loading is not allowed.
The ug command versus the ugrep command
The ug command is intended for context-dependent interactive searching and is
equivalent to the ugrep --config command to load the configuration file
.ugrep when present in the working directory or, when not found, in the home
directory:
ug PATTERN ...
ugrep --config PATTERN ...
The ug command also sorts files by name per directory searched. A
configuration file contains NAME=VALUE pairs per line, where NAME is the
name of a long option (without --) and =VALUE is an argument, which is
optional and may be omitted depending on the option. Empty lines and lines
starting with a # are ignored:
# Color scheme
colors=cx=hb:ms=hiy:mc=hic:fn=hi+y+K:ln=hg:cn=hg:bn=hg:se=
# Disable searching hidden files and directories
no-hidden
# ignore files specified in .ignore and .gitignore in recursive searches
ignore-files=.ignore
ignore-files=.gitignore
Command line options are parsed in the following order: first the (default or named) configuration file is loaded, then the remaining options and arguments on the command line are parsed.
Option --stats displays the configuration file used after searching.
Named configuration files
Named configuration files are intended to streamline custom search tasks, by
reducing the number of command line options to just one ---FILE to use the
collection of options specified in FILE. The --config=FILE option and its
abbreviated form ---FILE load the specified configuration file located in the
working directory or, when not found, located in the home directory:
ug ---FILE PATTERN ...
ugrep ---FILE PATTERN ...
An error is produced when FILE is not found or cannot be read.
Named configuration files can be used to define a collection of options that
are specific to the requirements of a task in the development workflow of a
project. For example to report unresolved issues by checking the source code
and documentation for comments with FIXME and TODO items. Such named
configuration file can be localized to a project by placing it in the project
directory, or it can be made global by placing it in the home directory. For
visual feedback, a color scheme specific to this task can be specified with
option colors in the configuration FILE to help identify the output
produced by a named configuration as opposed to the default configuration.
Saving a configuration file
The --save-config option saves a .ugrep configuration file to the working
directory using the current configuration loaded with --config. This saves
the current configuration combined with additional options when specified also.
Only those options that cannot conflict with other options and options that
cannot negatively impact search results will be saved.
The --save-config=FILE option saves the configuration to the specified FILE.
The configuration is written to standard output when FILE is a -.
Alternatively, a configuration file may be manually created or modified. A
configuration file may include one or more config[=FILE] to indirectly load
the specfified FILE, but recursive config loading is prohibited. The
simplest way to manuall create a configuration file is to specify config at
the top of the file, followed by the long options to override the defaults.
ð Back to table of contents
Interactive search with -Q
-Q[=DELAY], --query[=DELAY]
Query mode: start a TUI to perform interactive searches. This mode
requires an ANSI capable terminal. An optional DELAY argument may
be specified to reduce or increase the response time to execute
searches after the last key press, in increments of 100ms, where
the default is 3 (300ms delay). No whitespace may be given between
-Q and its argument DELAY. Initial patterns may be specified with
-e PATTERN, i.e. a PATTERN argument requires option -e. Press F1
or CTRL-Z to view the help screen. Press F2 or CTRL-Y to invoke a
command to view or edit the file shown at the top of the screen.
The command can be specified with option --view, or defaults to
environment variable PAGER when defined, or EDITOR. Press Tab and
Shift-Tab to navigate directories and to select a file to search.
Press Enter to select lines to output. Press ALT-l for option -l
to list files, ALT-n for -n, etc. Non-option commands include
ALT-] to increase context. See also options --no-confirm, --delay,
--split and --view.
--no-confirm
Do not confirm actions in -Q query TUI. The default is confirm.
--delay=DELAY
Set the default -Q key response delay. Default is 3 for 300ms.
--split
Split the -Q query TUI screen on startup.
--view[=COMMAND]
Use COMMAND to view/edit a file in -Q query TUI by pressing CTRL-Y.
This option starts a user interface to enter search patterns interactively:
- Press F1 or CTRL-Z to view a help screen and to enable or disable options.
- Press Alt with a key corresponding to a ugrep option letter or digit to
enable or disable the ugrep option. For example, pressing Alt-c enables
option
-cto count matches. Pressing Alt-c again disables-c. Options can be toggled with the Alt key while searching or when viewing the help screen. If Alt/Meta keys are not working (e.g. X11 xterm), then press CTRL-O followed by the key corresponding to the option. Alt keys may work in xterm by addingxterm*metaSendsEscape: trueto ~/.Xdefaults`. - Press Alt-g to enter or edit option
-gfile and directory matching globs, a comma-separated list of gitignore-style glob patterns. Presssing ESC returns control to the query pattern prompt (the globs are saved). When a glob is preceded by a!or a^, skips files whose name matches the glob When a glob contains a/, full pathnames are matched. Otherwise basenames are matched. When a glob ends with a/, directories are matched. - The query TUI prompt switches between
Q>(normal),F>(fixed strings),G>(basic regex),P>(Perl matching), andZ>(fuzzy matching). When the--glob=prompt is shown, a comma-separated list of gitignore-style glob patterns may be entered. Presssing ESC returns control to the pattern prompt. - Press CTRL-T to split the TUI screen to preview a file in the bottom pane.
- Press CTRL-Y to view a file with a pager specified with
--view. - Press Enter to switch to selection mode to select lines to output when ugrep exits. Normally, ugrep in query mode does not output any results unless results are selected. While in selection mode, select or deselect lines with Enter or Del, or press A to select all results.
- The file listed or shown at the top of the screen, or beneath the cursor in
selection mode, is edited by pressing F2 or CTRL-Y. A file viewer or editor
may be specified with
--view=COMMAND. Otherwise, thePAGERorEDITORenvironment variables are used to invoke the command with CTRL-Y. Filenames must be enabled and visible in the output to use this feature. - Press TAB to chdir one level down into the directory of the file listed or viewed at the top of the screen. If no directory exists, the file itself is selected to search. Press Shift-TAB to go back up one level.
- Press CTRL-] to toggle colors on and off. Normally ugrep in query mode uses
colors and other markup to highlight results. When colors are turned off,
selected results are also not colored in the output produced by ugrep when
ugrep exits. When colors are turned on (the default), selected results are
colored depending on the
--coloroption. - The query engine is optimized to limit system load by performing on-demand searches to produce results only for the visible parts shown in the interface. That is, results are shown on demand, when scrolling down and when exiting when all results are selected. When the search pattern is modified, the previous search query is cancelled when incomplete. This effectively limits the load on the system to maintain a high degree of responsiveness of the query engine to user input. Because the search results are produced on demand, occasionally you may notice a flashing "Searching..." message when searching files.
- To display results faster, specify a low
DELAYvalue such as 1. However, lower values may increase system load as a result of repeatedly initiating and cancelling searches by each key pressed. - To avoid long pathnames to obscure the view,
--headingis enabled by default. Press Alt-+ to switch headings off.
Query TUI key mapping:
| key(s) | function |
|---|---|
Alt-key | toggle ugrep command-line option corresponding to key |
Alt-/xxxx/ | insert Unicode hex code point U+xxxx |
Esc Ctrl-C | go back or exit |
Ctrl-Q | quick exit and output the results selected in selection mode |
Tab | chdir to the directory of the file shown at the top of the screen or select file |
Shift-Tab | chdir one level up or deselect file |
Enter | enter selection mode and toggle selected lines to output on exit |
Up Ctrl-P | move up |
Down Ctrl-N | move down |
Left Ctrl-B | move left |
Right Ctrl-F | move right |
PgUp Ctrl-G | move display up by a page |
PgDn Ctrl-D | move display down by a page |
Alt-Up | move display up by 1/2 page (MacOS Shift-Up) |
Alt-Down | move display down by 1/2 page (MacOS Shift-Down) |
Alt-Left | move display left by 1/2 page (MacOS Shift-Left) |
Alt-Right | move display right by 1/2 page (MacOS Shift-Right) |
Home Ctrl-A | move cursor to the beginning of the line |
End Ctrl-E | move cursor to the end of the line |
Ctrl-K | delete after cursor |
Ctrl-L | refresh screen |
Ctrl-O+key | toggle ugrep command-line option corresponding to key, same as Alt-key |
Ctrl-R F4 | jump to bookmark |
Ctrl-S | jump to the next dir/file/context |
Ctrl-T F5 | toggle split screen (--split starts a split-screen TUI) |
Ctrl-U | delete before cursor |
Ctrl-V | verbatim character |
Ctrl-W | jump back one dir/file/context |
Ctrl-X F3 | set bookmark |
Ctrl-Y F2 | view or edit the file shown at the top of the screen |
Ctrl-Z F1 | view help and options |
Ctrl-^ | chdir back to the starting working directory |
Ctrl-] | toggle color/mono |
Ctrl-\ | terminate process |
To interactively search the files in the working directory and below:
ug -Q
Same, but restricted to C++ files only and ignoring .gitignore files:
ug -Q -tc++ --ignore-files
To interactively search all makefiles in the working directory and below:
ug -Q -g 'Makefile*' -g 'makefile*'
Same, but for up to 2 directory levels (working and one subdirectory level):
ug -Q -2 -g 'Makefile*' -g 'makefile*'
To interactively view the contents of main.cpp and search it, where -y
shows any nonmatching lines as context:
ug -Q -y main.cpp
To interactively search main.cpp, starting with the search pattern TODO and
a match context of 5 lines (context can be interactively enabled and disabled,
this also overrides the default context size of 2 lines):
ug -Q -C5 -e TODO main.cpp
To view and search the contents of an archive (e.g. zip, tarball):
ug -Q -z archive.tar.gz
To interactively select files from project.zip to decompress with unzip,
using ugrep query selection mode (press Enter to select lines):
unzip project.zip `zipinfo -1 project.zip | ugrep -Q`
ð Back to table of contents
Recursively list matching files with -l, -R, -r, -S, --depth, -g, -O, and -t
-L, --files-without-match
Only the names of files not containing selected lines are written
to standard output. Pathnames are listed once per file searched.
If the standard input is searched, the string ``(standard input)''
is written.
-l, --files-with-matches
Only the names of files containing selected lines are written to
standard output. ugrep will only search a file until a match has
been found, making searches potentially less expensive. Pathnames
are listed once per file searched. If the standard input is
searched, the string ``(standard input)'' is written.
-R, --dereference-recursive
Recursively read all files under each directory. Follow all
symbolic links to files and directories, unlike -r.
-r, --recursive
Recursively read all files under each directory, following symbolic
links only if they are on the command line. Note that when no FILE
arguments are specified and input is read from a terminal,
recursive searches are performed as if -r is specified.
-S, --dereference-files
When -r is specified, symbolic links to files are followed, but not
to directories. The default is not to follow symbolic links.
--depth=[MIN,][MAX], -1, -2, -3, ... -9, -10, -11, -12, ...
Restrict recursive searches from MIN to MAX directory levels deep,
where -1 (--depth=1) searches the specified path without recursing
into subdirectories. Note that -3 -5, -3-5, and -35 search 3 to 5
levels deep. Enables -r if -R or -r is not specified.
-g GLOBS, --glob=GLOBS
Search only files whose name matches the specified comma-separated
list of GLOBS, same as --include='glob' for each `glob' in GLOBS.
When a `glob' is preceded by a `!' or a `^', skip files whose name
matches `glob', same as --exclude='glob'. When `glob' contains a
`/', full pathnames are matched. Otherwise basenames are matched.
When `glob' ends with a `/', directories are matched, same as
--include-dir='glob' and --exclude-dir='glob'. A leading `/'
matches the working directory. This option may be repeated and may
be combined with options -M, -O and -t to expand searches. See
`ugrep --help globs' and `man ugrep' section GLOBBING for details.
-O EXTENSIONS, --file-extension=EXTENSIONS
Search only files whose filename extensions match the specified
comma-separated list of EXTENSIONS, same as --include='*.ext' for
each `ext' in EXTENSIONS. When `ext' is preceded by a `!' or a
`^', skip files whose filename extensions matches `ext', same as
--exclude='*.ext'. This option may be repeated and may be combined
with options -g, -M and -t to expand the recursive search.
-t TYPES, --file-type=TYPES
Search only files associated with TYPES, a comma-separated list of
file types. Each file type corresponds to a set of filename
extensions passed to option -O and filenames passed to option -g.
For capitalized file types, the search is expanded to include files
with matching file signature magic bytes, as if passed to option
-M. When a type is preceded by a `!' or a `^', excludes files of
the specified type. This option may be repeated.
--stats
Output statistics on the number of files and directories searched,
and the inclusion and exclusion constraints applied.
If no FILE arguments are specified and input is read from a terminal, recursive
searches are performed as if -r is specified. To force reading from standard
input, specify - as the FILE argument.
To recursively list all non-empty files in the working directory:
ug -r -l ''
To list all non-empty files in the working directory but not deeper (since a
FILE argument is given, in this case . for the working directory):
ug -l '' .
To list all non-empty files in directory mydir but not deeper (since a FILE
argument is given):
ug -l '' mydir
To list all non-empty files in directory mydir and deeper while following
symlinks:
ug -R -l '' mydir
To recursively list all non-empty files on the path specified, while visiting
subdirectories only, i.e. directories mydir/ and subdirectories at one
level deeper mydir/*/ are visited (note that -2 -l can be abbreviated to
-l2):
ug -2 -l '' mydir
To recursively list all non-empty files in directory mydir, not following any
symbolic links (except when on the command line such as mydir):
ug -rl '' mydir
To recursively list all Makefiles matching the text CPP:
ug -l -tmake 'CPP'
To recursively list all Makefile.* matching bin_PROGRAMS:
ug -l -g'Makefile.*' 'bin_PROGRAMS'
To recursively list all non-empty files with extension .sh, with -Osh:
ug -l -Osh ''
To recursively list all shell scripts based on extensions and shebangs with
-tShell:
ug -l -tShell ''
To recursively list all shell scripts based on extensions only with -tshell:
ug -l -tshell ''
ð Back to table of contents
Boolean query patterns with -%, -%%, --and, --not
--bool, -%, -%%
Specifies Boolean query patterns. A Boolean query pattern is
composed of `AND', `OR', `NOT' operators and grouping with `(' `)'.
Spacing between subpatterns is the same as `AND', `|' is the same
as `OR' and a `-' is the same as `NOT'. The `OR' operator binds
more tightly than `AND'. For example, --bool 'A|B C|D' matches
lines with (`A' or `B') and (`C' or `D'), --bool 'A -B' matches
lines with `A' and not `B'. Operators `AND', `OR', `NOT' require
proper spacing. For example, --bool 'A OR B AND C OR D' matches
lines with (`A' or `B') and (`C' or `D'), --bool 'A AND NOT B'
matches lines with `A' without `B'. Quoted subpatterns are matched
literally as strings. For example, --bool 'A "AND"|"OR"' matches
lines with `A' and also either `AND' or `OR'. Parentheses are used
for grouping. For example, --bool '(A B)|C' matches lines with `A'
and `B', or lines with `C'. Note that all subpatterns in a Boolean
query pattern are regular expressions, unless -F is specified.
Options -E, -F, -G, -P and -Z can be combined with --bool to match
subpatterns as strings or regular expressions (-E is the default.)
This option does not apply to -f FILE patterns. The double short
option -%% enables options --bool --files. Option --stats displays
the Boolean search patterns applied. See also options --and,
--andnot, --not, --files and --lines.
--files
Boolean file matching mode, the opposite of --lines. When combined
with option --bool, matches a file if all Boolean conditions are
satisfied. For example, --bool --files 'A B|C -D' matches a file
if some lines match `A', and some lines match either `B' or `C',
and no line matches `D'. See also options --and, --andnot, --not,
--bool and --lines. The double short option -%% enables options
--bool --files.
--lines
Boolean line matching mode for option --bool, the default mode.
--and [[-e] PATTERN] ... -e PATTERN
Specify additional patterns to match. Patterns must be specified
with -e. Each -e PATTERN following this option is considered an
alternative pattern to match, i.e. each -e is interpreted as an OR
pattern. For example, -e A -e B --and -e C -e D matches lines with
(`A' or `B') and (`C' or `D'). Note that multiple -e PATTERN are
alternations that bind more tightly together than --and. Option
--stats displays the search patterns applied. See also options
--not, --andnot, and --bool.
--andnot [[-e] PATTERN] ...
Combines --and --not. See also options --and, --not, and --bool.
--not [-e] PATTERN
Specifies that PATTERN should not match. Note that -e A --not -e B
matches lines with `A' or lines without a `B'. To match lines with
`A' that have no `B', specify -e A --andnot -e B. Option --stats
displays the search patterns applied. See also options --and,
--andnot, and --bool.
--stats
Output statistics on the number of files and directories searched,
and the inclusion and exclusion constraints applied.
Note that the --and, --not, and --andnot options require -e PATTERN.
The -% option makes all patterns Boolean-based, supporting the following
logical operations listed from the highest level of precedence to the lowest:
| operator | alternative | result |
|---|---|---|
"x" | match x literally and exactly as specified (using the standard regex escapes \Q and \E) | |
( ) | Boolean expression grouping | |
-x | NOT x | inverted match, i.e. matches if x does not match |
x|y | x OR y | matches lines with x or y |
x y | x AND y | matches lines with both x and y |
-
xandyare subpatterns that do not start with the special symbols|,-, and((use quotes or a\escape to match these); -
-andNOTare the same and take precedence overOR, which means that-x|y==(-x)|yfor example. -
|andORare the same and take precedence overAND, which means thatx y|z==x (y|z)for example;
The --stats option displays the Boolean queries in human-readable form
converted to CNF (Conjunctive Normal Form), after the search is completed.
To show the CNF without a search, read from standard input terminated by an
EOF, like echo | ugrep -% '...' --stats.
Subpatterns are color-highlighted in the output, except those negated with
NOT (a NOT subpattern may still show up in a matching line when using an
OR-NOT pattern like x|-y). Note that subpatterns may overlap. In that
case only the first matching subpattern is color-highlighted.
Multiple lines may be matched when subpatterns match newlines. There is one
exception however: subpatterns ending with (?=X) lookaheads may not match
when X spans multiple lines.
Empty patterns match any line (grep standard). Therefore, -% 'x|""|y'
matches everything and x and y are not color-highlighted. Option -y
should be used to show every line as context, for example -y 'x|y'.
Fzf-like interactive querying (Boolean search with fixed strings with fuzzy
matching to allow e.g. up to 4 extra characters matched with -Z+4 in words
with -w), press TAB and ALT-y to view a file with matches. Press SHIFT-TAB
and ALT-l to go back to the list of matching files:
ug -Q -%% -l -w -F -Z+4 --sort=best
To recursively find all files containing both hot and dog anywhere in the
file with option --files:
ug -%% 'hot dog'
ug --files -e hot --and dog
To find lines containing both hot and dog in myfile.txt:
ug -% 'hot dog' myfile.txt
ug -e hot --and dog myfile.txt
To find lines containing place and then also hotdog or taco (or both) in
myfile.txt:
ug -% 'hotdog|taco place' myfile.txt
ug -e hotdog -e taco --and place myfile.txt
Same, but exclude lines matching diner:
ug -% 'hotdog|taco place -diner' myfile.txt
ug -e hotdog -e taco --and place --andnot diner myfile.txt
To find lines with diner or lines that match both fast and food but not bad in myfile.txt:
ug -% 'diner|(fast food -bad)' myfile.txt
To find lines with fast food (exactly) or lines with diner but not bad or old in myfile.txt:
ug -% '"fast food"|diner -bad -old' myfile.txt
Same, but using a different Boolean expression that has the same meaning:
ug -% '"fast food"|diner -(bad|old)' myfile.txt
To find lines with diner implying good in myfile.txt (that is, show lines
with good without diner and show lines with diner but only those with
good, which is logically implied!):
ug -% 'good|-diner' myfile.txt
ug -e good --not diner myfile.txt
To find lines with foo and -bar and "baz" in myfile.txt (not that -
and " should be matched using \ escapes and with --and -e -bar):
ug -% 'foo \-bar \"baz\"' myfile.txt
ug -e foo --and -e -bar --and '"baz"' myfile.txt
To search myfile.cpp for lines with TODO or FIXME but not both on the
same line, like XOR:
ug -% 'TODO|FIXME -(TODO FIXME)' myfile.cpp
ug -e TODO -e FIXME --and --not TODO --not FIXME myfile.cpp
ð Back to table of contents
Search this but not that with -v, -e, -N, -f, -L, -w, -x
-e PATTERN, --regexp=PATTERN
Specify a PATTERN to search the input. An input line is selected
if it matches any of the specified patterns. This option is useful
when multiple -e options are used to specify multiple patterns, or
when a pattern begins with a dash (`-'), or to specify a pattern
after option -f or after the FILE arguments.
-f FILE, --file=FILE
Read newline-separated patterns from FILE. White space in patterns
is significant. Empty lines in FILE are ignored. If FILE does not
exist, the GREP_PATH environment variable is used as path to FILE.
If that fails, looks for FILE in /usr/local/share/ugrep/pattern.
When FILE is a `-', standard input is read. This option may be
repeated.
-L, --files-without-match
Only the names of files not containing selected lines are written
to standard output. Pathnames are listed once per file searched.
If the standard input is searched, the string ``(standard input)''
is written.
-N PATTERN, --neg-regexp=PATTERN
Specify a negative PATTERN to reject specific -e PATTERN matches
with a counter pattern. Note that longer patterns take precedence
over shorter patterns, i.e. a negative pattern must be of the same
length or longer to reject matching patterns. Option -N cannot be
specified with -P. This option may be repeated.
-v, --invert-match
Selected lines are those not matching any of the specified
patterns.
-w, --word-regexp
The PATTERN is searched for as a word, such that the matching text
is preceded by a non-word character and is followed by a non-word
character. Word-like characters are Unicode letters, digits and
connector punctuations such as underscore.
-x, --line-regexp
Select only those matches that exactly match the whole line, as if
the patterns are surrounded by ^ and $.
See also Boolean query patterns with -%, -%%, --and, --not for more powerful Boolean query options than the traditional GNU/BSD grep options.
To display lines in file myfile.sh but not lines matching ^[ \t]*#:
ug -v '^[ \t]*#' myfile.sh
To search myfile.cpp for lines with FIXME and urgent, but not Scotty:
ugrep FIXME myfile.cpp | ugrep urgent | ugrep -v Scotty
Same, but using -% for Boolean queries:
ug -% 'FIXME urgent -Scotty' myfile.cpp
To search for decimals using pattern \d+ that do not start with 0 using
negative pattern 0\d+ and excluding 555:
ug -e '\d+' -N '0\d+' -N 555 myfile.cpp
To search for words starting with disp without matching display in file
myfile.py by using a "negative pattern" -N '/<display\>' where -N
specifies an additional negative pattern to skip matches:
ug -e '\<disp' -N '\<display\>' myfile.py
To search for lines with the word display in file myfile.py skipping this
word in strings and comments, where -f specifies patterns in files which are
predefined patterns in this case:
ug -n -w 'display' -f python/zap_strings -f python/zap_comments myfile.py
To display lines that are not blank lines:
ug -x -e '.*' -N '\h*' myfile.py
Same, but using -v and -x with \h*, i.e. pattern ^\h*$:
ug -v -x '\h*' myfile.py
To recursively list all Python files that do not contain the word display,
allowing the word to occur in strings and comments:
ug -RL -tPython -w 'display' -f python/zap_strings -f python/zap_comments
ð Back to table of contents
Search non-Unicode files with --encoding
--encoding=ENCODING
The encoding format of the input. The default ENCODING is binary
and UTF-8 which are the same. Note that option -U specifies binary
PATTERN matching (text matching is the default.)
Binary, ASCII and UTF-8 files do not require this option to search them. Also
UTF-16 and UTF-32 files do not require this option to search them, assuming
that UTF-16 and UTF-32 files start with a UTF BOM
(byte order mark) as usual.
Other file encodings require option --encoding=ENCODING:
| encoding | parameter |
|---|---|
| ASCII | n/a |
| UTF-8 | n/a |
| UTF-16 with BOM | n/a |
| UTF-32 with BOM | n/a |
| UTF-16 BE w/o BOM | UTF-16 or UTF-16BE |
| UTF-16 LE w/o BOM | UTF-16LE |
| UTF-32 w/o BOM | UTF-32 or UTF-32BE |
| UTF-32 w/o BOM | UTF-32LE |
| Latin-1 | LATIN1 or ISO-8859-1 |
| ISO-8859-1 | ISO-8859-1 |
| ISO-8859-2 | ISO-8859-2 |
| ISO-8859-3 | ISO-8859-3 |
| ISO-8859-4 | ISO-8859-4 |
| ISO-8859-5 | ISO-8859-5 |
| ISO-8859-6 | ISO-8859-6 |
| ISO-8859-7 | ISO-8859-7 |
| ISO-8859-8 | ISO-8859-8 |
| ISO-8859-9 | ISO-8859-9 |
| ISO-8859-10 | ISO-8859-10 |
| ISO-8859-11 | ISO-8859-11 |
| ISO-8859-13 | ISO-8859-13 |
| ISO-8859-14 | ISO-8859-14 |
| ISO-8859-15 | ISO-8859-15 |
| ISO-8859-16 | ISO-8859-16 |
| MAC (CR=newline) | MAC |
| MacRoman (CR=newline) | MACROMAN |
| EBCDIC | EBCDIC |
| DOS code page 437 | CP437 |
| DOS code page 850 | CP850 |
| DOS code page 858 | CP858 |
| Windows code page 1250 | CP1250 |
| Windows code page 1251 | CP1251 |
| Windows code page 1252 | CP1252 |
| Windows code page 1253 | CP1253 |
| Windows code page 1254 | CP1254 |
| Windows code page 1255 | CP1255 |
| Windows code page 1256 | CP1256 |
| Windows code page 1257 | CP1257 |
| Windows code page 1258 | CP1258 |
| KOI8-R | KOI8-R |
| KOI8-U | KOI8-U |
| KOI8-RU | KOI8-RU |
Note that regex patterns are always specified in UTF-8 (includes ASCII). To search binary files with binary patterns, see searching and displaying binary files with -U, -W, and -X.
To recursively list all files that are ASCII (i.e. 7-bit):
ug -L '[^[:ascii:]]'
To recursively list all files that are non-ASCII, i.e. UTF-8, UTF-16, and UTF-32 files with non-ASCII Unicode characters (U+0080 and up):
ug -l '[^[:ascii:]]'
To check if a file contains non-ASCII Unicode (U+0080 and up):
ug -q '[^[:ascii:]]' myfile && echo "contains Unicode"
To remove invalid Unicode characters from a file (note that -o may not work
because binary data is detected and rejected and newlines are added, but
--format="%o% does not check for binary and copies the match "as is"):
ug "[\p{Unicode}\n]" --format="%o" badfile.txt
To recursively list files with invalid UTF content (i.e. invalid UTF-8 byte
sequences or files that contain any UTF-8/16/32 code points that are outside
the valid Unicode range) by matching any code point with . and by using a
negative pattern -N '\p{Unicode}' to ignore each valid Unicode character:
ug -l -e '.' -N '\p{Unicode}'
To display lines containing laughing face emojis:
ug '[ð-ð]' emojis.txt
The same results are obtained using \x{hhhh} to select a Unicode character
range:
ug '[\x{1F600}-\x{1F60F}]' emojis.txt
To display lines containing the names Gödel (or Goedel), Escher, or Bach:
ug 'G(ö|oe)del|Escher|Bach' GEB.txt wiki.txt
To search for lorem in lower or upper case in a UTF-16 file that is marked
with a UTF-16 BOM:
ug -iw 'lorem' utf16lorem.txt
To search utf16lorem.txt when this file has no UTF-16 BOM, using --encoding:
ug --encoding=UTF-16 -iw 'lorem' utf16lorem.txt
To search file spanish-iso.txt encoded in ISO-8859-1:
ug --encoding=ISO-8859-1 -w 'año' spanish-iso.txt
ð Back to table of contents
Matching multiple lines of text
-o, --only-matching
Output only the matching part of lines. If -A, -B or -C is
specified, fits the match and its context on a line within the
specified number of columns.
Multiple lines may be matched by patterns that match newline characters. Use
option -o to output the match only, not the full lines(s) that match.
To match a \n line break, include \n in the pattern to match the LF
character. If you want to match \r\n and \n line breaks, use \r?\n or
simply use \R to match any Unicode line break \r\n, \r, \v, \f, \n,
U+0085, U+2028 and U+2029.
To match C/C++ /*...*/ multi-line comments:
ug '/\*(.*\n)*?.*\*+\/' myfile.cpp
To match C/C++ comments using the predefined c/comments patterns with
-f c/comments, restricted to the matching part only with option -o:
ug -of c/comments myfile.cpp
Same as sed -n '/begin/,/end/p': to match all lines between a line containing
begin and the first line after that containing end, using lazy repetition:
ug -o '.*begin(.|\n)*?end.*' myfile.txt
ð Back to table of contents
Displaying match context with -A, -B, -C, -y, and --width
-A NUM, --after-context=NUM
Output NUM lines of trailing context after matching lines. Places
a --group-separator between contiguous groups of matches. If -o is
specified, output the match with context to fit NUM columns after
the match or shortens the match. See also options -B, -C and -y.
-B NUM, --before-context=NUM
Output NUM lines of leading context before matching lines. Places
a --group-separator between contiguous groups of matches. If -o is
specified, output the match with context to fit NUM columns before
the match or shortens the match. See also options -A, -C and -y.
-C NUM, --context=NUM
Output NUM lines of leading and trailing context surrounding each
matching line. Places a --group-separator between contiguous
groups of matches. If -o is specified, output the match with
context to fit NUM columns before and after the match or shortens
the match. See also options -A, -B and -y.
-y, --any-line
Any line is output (passthru). Non-matching lines are output as
context with a `-' separator. See also options -A, -B, and -C.
--width[=NUM]
Truncate the output to NUM visible characters per line. The width
of the terminal window is used if NUM is not specified. Note that
double wide characters in the output may result in wider lines.
-o, --only-matching
Output only the matching part of lines. If -A, -B or -C is
specified, fits the match and its context on a line within the
specified number of columns.
To display two lines of context before and after a matching line:
ug -C2 'FIXME' myfile.cpp
To show three lines of context after a matched line:
ug -A3 'FIXME.*' myfile.cpp:
To display one line of context before each matching line with a C function definition (C names are non-Unicode):
ug -B1 -f c/functions myfile.c
To display one line of context before each matching line with a C++ function definition (C++ names may be Unicode):
ug -B1 -f c++/functions myfile.cpp
To display any non-matching lines as context for matching lines with -y:
ug -y -f c++/functions myfile.cpp
To display a hexdump of a matching line with one line of hexdump context:
ug -C1 -UX '\xaa\xbb\xcc' a.out
Context within a line is displayed with option -o with a context option:
ug -o -C20 'pattern' myfile.cpp
Same, but with pretty output with headings, line numbers and column numbers
(-k) and showing context:
ug --pretty -oC20 'pattern' myfile.cpp
ð Back to table of contents
Searching source code using -f, -g, -O, and -t
-f FILE, --file=FILE
Read newline-separated patterns from FILE. White space in patterns
is significant. Empty lines in FILE are ignored. If FILE does not
exist, the GREP_PATH environment variable is used as path to FILE.
If that fails, looks for FILE in /usr/local/share/ugrep/pattern.
When FILE is a `-', standard input is read. This option may be
repeated.
--ignore-files[=FILE]
Ignore files and directories matching the globs in each FILE that
is encountered in recursive searches. The default FILE is
`.gitignore'. Matching files and directories located in the
directory of the FILE and in subdirectories below are ignored.
Globbing syntax is the same as the --exclude-from=FILE gitignore
syntax, but files and directories are excluded instead of only
files. Directories are specifically excluded when the glob ends in
a `/'. Files and directories explicitly specified as command line
arguments are never ignored. This option may be repeated to
specify additional files.
-g GLOBS, --glob=GLOBS
Search only files whose name matches the specified comma-separated
list of GLOBS, same as --include='glob' for each `glob' in GLOBS.
When a `glob' is preceded by a `!' or a `^', skip files whose name
matches `glob', same as --exclude='glob'. When `glob' contains a
`/', full pathnames are matched. Otherwise basenames are matched.
When `glob' ends with a `/', directories are matched, same as
--include-dir='glob' and --exclude-dir='glob'. A leading `/'
matches the working directory. This option may be repeated and may
be combined with options -M, -O and -t to expand searches. See
`ugrep --help globs' and `man ugrep' section GLOBBING for details.
-O EXTENSIONS, --file-extension=EXTENSIONS
Search only files whose filename extensions match the specified
comma-separated list of EXTENSIONS, same as --include='*.ext' for
each `ext' in EXTENSIONS. When `ext' is preceded by a `!' or a
`^', skip files whose filename extensions matches `ext', same as
--exclude='*.ext'. This option may be repeated and may be combined
with options -g, -M and -t to expand the recursive search.
-t TYPES, --file-type=TYPES
Search only files associated with TYPES, a comma-separated list of
file types. Each file type corresponds to a set of filename
extensions passed to option -O and filenames passed to option -g.
For capitalized file types, the search is expanded to include files
with matching file signature magic bytes, as if passed to option
-M. When a type is preceded by a `!' or a `^', excludes files of
the specified type. This option may be repeated.
--stats
Output statistics on the number of files and directories searched,
and the inclusion and exclusion constraints applied.
The file types are listed with ugrep -tlist. The list is based on
established filename extensions and "magic bytes". If you have a file type
that is not listed, use options -O and/or -M. You may want to define an
alias, e.g. alias ugft='ugrep -Oft' as a shorthand to search files with
filename suffix .ft.
To recursively display function definitions in C/C++ files (.h, .hpp, .c,
.cpp etc.) with line numbers with -tc++, -o, -n, and -f c++/functions:
ug -on -tc++ -f c++/functions
To recursively display function definitions in .c and .cpp files with line
numbers with -Oc,cpp, -o, -n, and -f c++/functions:
ug -on -Oc,cpp -f c++/functions
To recursively list all shell files with -tShell to match filename extensions
and files with shell shebangs, except files with suffix .sh:
ug -l -tShell -O^sh ''
To recursively list all non-shell files with -t^Shell:
ug -l -t^Shell ''
To recursively list all shell files with shell shebangs that have no shell filename extensions:
ug -l -tShell -t^shell ''
To search for lines with FIXME in C/C++ comments, excluding FIXME in
multi-line strings:
ug -n 'FIXME' -f c++/zap_strings myfile.cpp
To read patterns TODO and FIXME from standard input to match lines in the
input, while excluding matches in C++ strings:
ug -on -f - -f c++/zap_strings myfile.cpp <<END
TODO
FIXME
END
To display XML element and attribute tags in an XML file, restricted to the
matching part with -o, excluding tags that are placed in (multi-line)
comments:
ug -o -f xml/tags -f xml/zap_comments myfile.xml
ð Back to table of contents
Searching compressed files and archives with -z
-z, --decompress
Search compressed files and archives. Archives (.cpio, .pax, .tar)
and compressed archives (e.g. .zip, .7z, .taz, .tgz, .tpz, .tbz,
.tbz2, .tb2, .tz2, .tlz, .txz, .tzst) are searched and matching
pathnames of files in archives are output in braces. When used
with option --zmax=NUM, searches the contents of compressed files
and archives stored within archives up to NUM levels. When -g, -O,
-M, or -t is specified, searches archives for files that match the
specified globs, filename extensions, file signature magic bytes,
or file types, respectively; a side-effect of these options is that
the compressed files and archives searched are only those with
filename extensions that match known compression and archive types.
Supported compression formats: gzip (.gz), compress (.Z), zip, 7z,
bzip2 (.bz, .bz2, .bzip2, .tbz, .tbz2, .tb2, .tz2),
xz (.xz, .txz) and lzma (requires suffix .lzma, .tlz),
zstd (.zst, .zstd, .tzst),
lz4 (requires suffix .lz4),
brotli (requires suffix .br).
--zmax=NUM
When used with option -z (--decompress), searches the contents of
compressed files and archives stored within archives by up to NUM
expansion stages. The default --zmax=1 only permits searching
uncompressed files stored in cpio, pax, tar, zip and 7z archives;
compressed files and archives are detected as binary files and are
effectively ignored. Specify --zmax=2 to search compressed files
and archives stored in cpio, pax, tar, zip and 7z archives. NUM
may range from 1 to 99 for up to 99 decompression and de-archiving
steps. Increasing NUM values gradually degrades performance.
Files compressed with gzip (.gz), compress (.Z), bzip2 (.bz, .bz2,
.bzip2), lzma (.lzma), xz (.xz), lz4 (.lz4), zstd (.zst, .zstd),
brotli (.br) and bzip3 (.bz3) are searched with option -z when the
corresponding libraries are installed and compiled with ugrep. This option
does not require files to be compressed. Uncompressed files are searched also,
although slower.
Other compression formats can be searched with ugrep filters.
Archives (cpio, jar, pax, tar, zip and 7z) are searched with option -z.
Regular files in an archive that match are output with the archive pathnames
enclosed in { and } braces. Supported tar formats are v7, ustar, gnu,
oldgnu, and pax. Supported cpio formats are odc, newc, and crc. Not supported
is the obsolete non-portable old binary cpio format. Archive formats cpio,
tar, and pax are automatically recognized with option -z based on their
content, independent of their filename suffix.
By default, uncompressed archives stored within zip archives are also searched: all cpio, pax, and tar files stored in zip and 7z archives are automatically recognized and searched. However, by default, compressed files stored within archives are not recognized, e.g. zip files stored within tar files are not searched but rather all compressed files and archives are searched as if they are binary files without decompressing them.
Specify --zmax=NUM to search archives that contain compressed files and
archives for up to NUM levels deep. The value of NUM may range from 1 to
99 for up to 99 decompression and de-archiving steps to expand up to 99 nested
archives. Larger --zmax=NUM values degrade performance. It is unlikely you
will ever need 99 as --zmax=2 suffices for most practical use cases, such as
searching zip files stored in tar files.
When option -z is used with options -g, -O, -M, or -t, archives and
compressed and uncompressed files that match the filename selection criteria
(glob, extension, magic bytes, or file type) are searched only. For example,
ugrep -r -z -tc++ searches C++ files such as main.cpp and zip and tar
archives that contain C++ files such as main.cpp. Also included in the
search are compressed C++ files such as main.cpp.gz and main.cpp.xz when
present. Also any cpio, pax, tar, zip and 7z archives when present are
searched for C++ files that they contain, such as main.cpp. Use option
--stats to see a list of the glob patterns applied to filter file pathnames
in the recursive search and when searching archive contents.
When option -z is used with options -g, -O, -M, or -t to search cpio,
jar, pax, tar, zip and 7z archives, archived files that match the filename
selection criteria are searched only.
The gzip, compress, zip, bzip2, xz, and zstd formats are automatically
detected, which is useful when reading compressed data from standard input,
e.g. input redirected from a pipe. Other compression formats require a
filename suffix: .lzma for lzma, .lz4 for lz4, .br for brotli and .bz3
for bzip3. Also the compressed tar archive shorthands .taz, .tgz and
.tpz for gzip, .tbz, .tbz2, .tb2, and .tz2 for bzip2, .tlz for
lzma, .txz for xz, and .tzst for zstd are recognized. To search these
formats with ugrep from standard input, use option --label='stdin.bz2' for
bzip2, --label='stdin.lzma' for lzma, --label='stdin.lz4 for lz4 and so on.
The name stdin is arbitrary and may be omitted:
| format | filename suffix | tar/pax archive short suffix | suffix required? | detect on stdin | library |
|---|---|---|---|---|---|
| gzip | .gz | .taz, .tgz, .tpz | no | automatic | libz |
| compress | .Z | .taZ, .tZ | no | automatic | built-in |
| zip | .zip, .zipx, .ZIP | no | automatic | libz | |
| bzip2 | .bz, .bz2, .bzip2 | .tb2, .tbz, .tbz2, .tz2 | no | automatic | libbz2 |
| xz | .xz | .txz | no | automatic | liblzma |
| zstd | .zst, .zstd | .tzst | no | automatic | libzstd |
| 7zip | .7z | yes | --label=.7z | built-in | |
| brotli | .br | yes | --label=.br | libbrotlidec | |
| bzip3 | .bz3 | yes | --label=.bz3 | libbzip3 | |
| lzma | .lzma | .tlz | yes | --label=.lzma | liblzma |
| lz4 | .lz4 | yes | --label=.lz4 | liblz4 |
The gzip, bzip2, xz, lz4 and zstd formats support concatenated compressed files. Concatenated compressed files are searched as one single file.
Supported zip compression methods are stored (0), deflate (8), bzip2 (12), lzma (14), xz (95) and zstd (93). The bzip2, lzma, xz and zstd methods require ugrep to be compiled with the corresponding compression libraries.
Searching encrypted zip archives is not supported (perhaps in future releases, depending on requests for enhancements).
Searching 7zip archives takes a lot more RAM and more time compared to other
methods. The 7zip LZMA SDK implementation does not support streaming,
requiring a physical seekable 7z file. This means that 7z files cannot be
searched when nested within archives. Best is to avoid 7zip. Support for 7zip
can be disabled with ./build.sh --disable-7zip to build ugrep.
Option -z uses threads for task parallelism to speed up searching larger
files by running the decompressor concurrently with a search of the
decompressed stream.
To list all non-empty files stored in a package.zip archive, including the
contents of all cpio, pax, tar, zip and 7z files that are stored in it:
ug --zmax=2 -z -l '' package.zip
Same, but only list the Python source code files, including scripts that invoke
Python, with option -tPython (ugrep -tlist for details):
ug --zmax=2 -z -l -tPython '' package.zip
To search Python applications distributed as a tar file with their dependencies
includes as wheels (zip files with Python code), searching for the word
my_class in app.tgz:
ug --zmax=2 -z -tPython -w my_class app.tgz
To recursively search C++ files including compressed files for the word
my_function, while skipping C and C++ comments:
ug -z -r -tc++ -Fw my_function -f cpp/zap_comments
To search lzma, lz4, brotli, and bzip3 compressed data on standard input,
option --label may be used to specify the extension corresponding to the
compression format to force decompression when the bzip2 extension is not
available to ugrep, for example:
cat myfile.lz4 | ugrep -z --label='stdin.lz4' 'xyz'
To search file main.cpp in project.zip for TODO and FIXME lines:
ug -z -g main.cpp -w -e 'TODO' -e 'FIXME' project.zip
To search tarball project.tar.gz for C++ files with TODO and FIXME lines:
ug -z -tc++ -w -e 'TODO' -e 'FIXME' project.tar.gz
To search files matching the glob *.txt in project.zip for the word
license in any case (note that the -g glob argument must be quoted):
ug -z -g '*.txt' -w -i 'license' project.zip
To display and page through all C++ files in tarball project.tgz:
ug --pager -z -tc++ '' project.tgz
To list the files matching the gitignore-style glob /**/projects/project1.*
in projects.tgz, by selecting files containing in the archive the text
December 12:
ug -z -l -g '/**/projects/project1.*' -F 'December 12' projects.tgz
To view the META-INF/MANIFEST.MF data in a jar file with -Ojar and -OMF to
select the jar file and the MF file therein (-Ojar is required, otherwise the
jar file will be skipped though we could read it from standard input instead):
ug -z -h -OMF,jar '' my.jar
To extract C++ files that contain FIXME from project.tgz, we use -m1
with --format="'%z '" to generate a space-separated list of pathnames of file
located in the archive that match the word FIXME:
tar xzf project.tgz `ugrep -z -l -tc++ --format='%z ' -w FIXME project.tgz`
To perform a depth-first search with find, then use cpio and ugrep to
search the files:
find . -depth -print | cpio -o | ugrep -z 'xyz'
ð Back to table of contents
Find files by file signature and shebang "magic bytes" with -M, -O and -t
--ignore-files[=FILE]
Ignore files and directories matching the globs in each FILE that
is encountered in recursive searches. The default FILE is
`.gitignore'. Matching files and directories located in the
directory of the FILE and in subdirectories below are ignored.
Globbing syntax is the same as the --exclude-from=FILE gitignore
syntax, but files and directories are excluded instead of only
files. Directories are specifically excluded when the glob ends in
a `/'. Files and directories explicitly specified as command line
arguments are never ignored. This option may be repeated to
specify additional files.
-M MAGIC, --file-magic=MAGIC
Only files matching the signature pattern MAGIC are searched. The
signature \"magic bytes\" at the start of a file are compared to
the MAGIC regex pattern. When matching, the file will be searched.
When MAGIC is preceded by a `!' or a `^', skip files with matching
MAGIC signatures. This option may be repeated and may be combined
with options -O and -t to expand the search. Every file on the
search path is read, making searches potentially more expensive.
-O EXTENSIONS, --file-extension=EXTENSIONS
Search only files whose filename extensions match the specified
comma-separated list of EXTENSIONS, same as --include='*.ext' for
each `ext' in EXTENSIONS. When `ext' is preceded by a `!' or a
`^', skip files whose filename extensions matches `ext', same as
--exclude='*.ext'. This option may be repeated and may be combined
with options -g, -M and -t to expand the recursive search.
-t TYPES, --file-type=TYPES
Search only files associated with TYPES, a comma-separated list of
file types. Each file type corresponds to a set of filename
extensions passed to option -O and filenames passed to option -g.
For capitalized file types, the search is expanded to include files
with matching file signature magic bytes, as if passed to option
-M. When a type is preceded by a `!' or a `^', excludes files of
the specified type. This option may be repeated.
-g GLOBS, --glob=GLOBS
Search only files whose name matches the specified comma-separated
list of GLOBS, same as --include='glob' for each `glob' in GLOBS.
When a `glob' is preceded by a `!' or a `^', skip files whose name
matches `glob', same as --exclude='glob'. When `glob' contains a
`/', full pathnames are matched. Otherwise basenames are matched.
When `glob' ends with a `/', directories are matched, same as
--include-dir='glob' and --exclude-dir='glob'. A leading `/'
matches the working directory. This option may be repeated and may
be combined with options -M, -O and -t to expand searches. See
`ugrep --help globs' and `man ugrep' section GLOBBING for details.
--stats
Output statistics on the number of files and directories searched,
and the inclusion and exclusion constraints applied.
To recursively list all files that start with #! shebangs:
ug -l -M'#!' ''
To recursively list all files that start with # but not with #! shebangs:
ug -l -M'#' -M'^#!' ''
To recursively list all Python files (extension .py or a shebang) with
-tPython:
ug -l -tPython ''
To recursively list all non-shell files with -t^Shell:
ug -l -t^Shell ''
To recursively list Python files (extension .py or a shebang) that have
import statements, including hidden files with -.:
ug -l. -tPython -f python/imports
ð Back to table of contents
Fuzzy search with -Z
-Z[best][+-~][MAX], --fuzzy=[best][+-~][MAX]
Fuzzy mode: report approximate pattern matches within MAX errors.
The default is -Z1: one deletion, insertion or substitution is
allowed. If `+`, `-' and/or `~' is specified, then `+' allows
insertions, `-' allows deletions and `~' allows substitutions. For
example, -Z+~3 allows up to three insertions or substitutions, but
no deletions. If `best' is specified, then only the best matching
lines are output with the lowest cost per file. Option -Zbest
requires two passes over a file and cannot be used with standard
input or Boolean queries. Option --sort=best orders matching files
by best match. The first character of an approximate match always
matches a character at the beginning of the pattern. To fuzzy
match the first character, replace it with a `.' or `.?'. Option
-U applies fuzzy matching to ASCII and bytes instead of Unicode
text. No whitespace may be given between -Z and its argument.
The beginning of a pattern always matches the first character of an approximate
match as a practical strategy to prevent many false "randomized" matches for
short patterns. This also greatly improves search speed. Make the first
character optional to optionally match it, e.g. p?attern or use a dot as
the start of the pattern to match any wide character (but this is slow).
Line feed (\n) and NUL (\0) characters are never deleted or substituted to
ensure that fuzzy matches do not extend the pattern match beyond the number of
lines specified by the regex pattern.
Option -U (--ascii or --binary) restricts fuzzy matches to ASCII and
binary only with edit distances measured in bytes. Otherwise, fuzzy pattern
matching is performed with Unicode patterns and edit distances are measured in
Unicode characters.
Option --sort=best orders files by best match. Files with at least one exact
match anywhere in the file are shown first, followed by files with approximate
matches in increasing minimal edit distance order. That is, ordered by the
minimum error (edit distance) found among all approximate matches per file.
To recursively search for approximate matches of the word foobar with -Z,
i.e. approximate matching with one error, e.g. Foobar, foo_bar, foo bar,
fobar and other forms with one missing, one extra or one deleted character:
ug -Z 'foobar'
Same, but matching words only with -w and ignoring case with -i:
ug -Z -wi 'foobar'
Same, but permit up to 2 insertions with -Z+2, no deletions/substitutions
(matches up to 2 extra characters, such as foos bar), insertions-only offers
the fastest fuzzy matching method:
ug -Z+3 -wi 'foobar'
Same, but sort matches from best (at least one exact match or fewest fuzzy match errors) to worst:
ug -Z+3 -wi --sort=best 'foobar'
Note: because sorting by best match requires two passes over the input files, the efficiency of concurrent searching is significantly reduced.
Same, but with customized formatting to show the edit distance "cost" of the
approximate matches with format field %Z and %F to show the pathname:
ug -Z+3 -wi --format='%F%Z:%O%~' --sort=best 'foobar'
Same, but this time count the matches with option -c and display them with a
custom format using %m, where %Z is the average cost per match:
ug -c -Z+3 -wi --format='%F%Z:%m%~' --sort=best 'foobar'
Note: options -c and -l do not report a meaningful %Z value in the
--format output, because %Z is the edit distance cost of a single match.
ð Back to table of contents
Search hidden files with -.
--hidden, -.
Search hidden files and directories.
To recursively search the working directory, including hidden files and
directories, for the word login in shell scripts:
ug -. -tShell 'login'
ð Back to table of contents
Using filter utilities to search documents with --filter
--filter=COMMANDS
Filter files through the specified COMMANDS first before searching.
COMMANDS is a comma-separated list of `exts:command [option ...]',
where `exts' is a comma-separated list of filename extensions and
`command' is a filter utility. Files matching one of `exts' are
filtered. When `exts' is a `*', all files are filtered. One or
more `option' separated by spacing may be specified, which are
passed verbatim to the command. A `%' as `option' expands into the
pathname to search. For example, --filter='pdf:pdftotext % -'
searches PDF files. The `%' expands into a `-' when searching
standard input. When a `%' is not specified, a filter utility
should read from standard input and write to standard output.
Option --label=.ext may be used to specify extension `ext' when
searching standard input. This option may be repeated.
--filter-magic-label=LABEL:MAGIC
Associate LABEL with files whose signature "magic bytes" match the
MAGIC regex pattern. Only files that have no filename extension
are labeled, unless +LABEL is specified. When LABEL matches an
extension specified in --filter=COMMANDS, the corresponding command
is invoked. This option may be repeated.
The --filter option associates one or more filter utilities with specific
filename extensions. A filter utility is selected based on the filename
extension and executed by forking a process: the utility's standard input
reads the open input file and the utility's standard output is searched. When
a % is specified as an option to the utility, the % is expanded to the
pathname of the file to open and read by the utility.
When a specified utility is not found on the system, an error message is displayed. When a utility fails to produce output, e.g. when the specified options for the utility are invalid, the search is silently skipped.
Filtering does not apply to files stored in archives and compressed files. A filter is usually applied to a file that is physically stored in the file system. Archived files are not physically stored.
Common filter utilities are cat (concat, pass through), head (select first
lines or bytes) tr (translate), iconv and uconv (convert), and more
advanced utilities, such as:
pdftotextto convert pdf to textantiwordto convert doc to textpandocto convert .docx, .epub, and other document formatsexiftoolto read meta information embedded in image and video media formats.sofficeto convert office documentscsvkitto convert spreadsheetsopensslto convert certificates and key files to text and other formats
The ugrep+ and ug+ commands use the pdftotext, antiword, pandoc and
exiftool filters, when installed, to search pdfs, documents, e-books, and
image metadata.
Also decompressors may be used as filter utilities, such as unzip, gunzip,
bunzip2, unlzma, unxz, lzop and 7z that decompress files to standard
output when option --stdout is specified. For example:
ug --filter='lzo:lzop -d --stdout -' ...
ug --filter='gz:gunzip -d --stdout -' ...
ug --filter='7z:7z x -so %' ...
The --filter='lzo:lzop -d --stdout -' option decompresses files with
extension lzo to standard output with --stdout with the compressed stream
being read from standard input with -. The --filter='7z:7z x -so -si
option decompresses files with extension 7z to standard output -so while
reading standard input -si with the compressed file contents.
Note that ugrep option -z is typically faster to search compressed files
compared to --filter.
The --filter option may also be used to run a user-defined shell script to
filter files. For example, to invoke an action depending on the filename
extension of the % argument. Another use case is to pass a file to more than
one filter, which can be accomplished with a shell script containing the line
tool1 $1; tool2 $1. This filters the file argument $1 with tool1
followed by tool2 to produce combined output to search for pattern matches.
Likewise, we can use a script with the line tool1 $1 | tool2 to stack two
filters tool1 and tool2.
The --filter option may also be used as a predicate to skip certain files
from the search. As the most basic example, consider the false utility that
exits with a nonzero exit code without reading input or producing output.
Therefore, --filter='swp: false' skips all .swp files from recursive
searches. The same can be done more efficiently with -O^swp. However,
the --filter option could invoke a script that determines if the filename
passed as a % argument meets certain constraints. If the constraint is met
the script copies standard input to standard output with cat. If not, the
script exits.
Warning: option --filter should not be used with utilities that modify
files. Otherwise searches may be unpredicatable. In the worst case files may
be lost, for example when the specified utility replaces or deletes the file
passed to the command with --filter option %.
To recursively search files including PDF files in the working directory
without recursing into subdirectories (with -1), for matches of drink me
using the pdftotext filter to convert PDF to text without preserving page
breaks:
ug -r -1 --filter='pdf:pdftotext -nopgbrk % -' 'drink me'
To recursively search text files for eat me while converting non-printable
characters in .txt and .md files using the cat -v filter:
ug -r -ttext --filter='txt,md:cat -v' 'eat me'
The same, but specifying the .txt and .md filters separately:
ug -r -ttext --filter='txt:cat -v, md:cat -v' 'eat me'
To search the first 8K of a text file:
ug --filter='txt:head -c 8192' 'eat me' wonderland.txt
To recursively search and list the files that contain the word Alice,
including .docx and .epub documents using the pandoc filter:
ug -rl -w --filter='docx,epub:pandoc --wrap=preserve -t plain % -o -' 'Alice'
Important: the pandoc utility requires an input file and will not read
standard input. Option % expands into the full pathname of the file to
search. The output format specified is markdown, which is close enough to
text to be searched.
To recursively search and list the files that contain the word Alice,
including .odt, .doc, .docx, .rtf, .xls, .xlsx, .ppt, .pptx documents using the
soffice filter:
ug -rl -w --filter='odt,doc,docx,rtf,xls,xlsx,ppt,pptx:soffice --headless --cat %' 'Alice'
Important: the soffice utility will not output any text when one or more
LibreOffice GUIs are open. Make sure to quit all LibreOffice apps first. This
looks like a bug, but the LibreOffice developers do not appear to fix this
any time soon (unless perhaps more people complain?). You can work around this
problem by specifying a specific user profile for soffice with the following
semi-documented argument passed to soffice:
-env:UserInstallation=file:///home/user/.libreoffice-alt.
To recursively search and display rows of .csv, .xls, and .xlsx spreadsheets
that contain 10/6 using the in2csv filter of csvkit:
ug -r -Ocsv,xls,xlsx --filter='xls,xlsx:in2csv %' '10/6'
To search .docx, .xlsx, and .pptx files converted to XML for a match with
10/6 using unzip as a filter:
ug -lr -Odocx,xlsx,pptx --filter='docx,xlsx,pptx:unzip -p %' '10/6'
Important: unzipping docx, xlxs, pptx files produces extensive XML output
containing meta information and binary data such as images. By contrast,
ugrep option -z with -Oxml selects the XML components only:
ug -z -lr -Odocx,xlsx,pptx,xml '10/6'
Note: docx, xlsx, and pptx are zip files containing multiple components.
When selecting the XML components with option -Oxml in docx, xlsx, and pptx
documents, we should also specify -Odocx,xlsx,pptx to search these type of
files, otherwise these files will be ignored.
To recurssively search X509 certificate files for lines with Not After (e.g.
to find expired certificates), using openssl as a filter:
ug -r 'Not After' -Ocer,der,pem --filter='pem:openssl x509 -text,cer,crt,der:openssl x509 -text -inform der'
Note that openssl warning messages are displayed on standard error. If
a file cannot be converted it is probably in a different format. This can
be resolved by writing a shell script that executes openssl with options
based on the file content. Then write a script with ugrep --filter.
To search PNG files by filename extension with -tpng using exiftool:
ug -r -i 'copyright' -tpng --filter='*:exiftool %'
Same, but also include files matching PNG "magic bytes" with -tPng and
--filter-magic-label='+png:\x89png\x0d\x0a\x1a\x0a' to select the png
filter:
ug -r -i 'copyright' -tPng --filter='png:exiftool %' --filter-magic-label='+png:\x89png\x0d\x0a\x1a\x0a'
Note that +png overrides any filename extension match for --filter.
Otherwise, without a +, the filename extension, when present, takes priority
over labelled magic patterns to invoke the corresponding filter command.
The LABEL used with --filter-magic-label and --filter has no specific
meaning; any name or string that does not contain a : or , may be used.
ð Back to table of contents
Searching and displaying binary files with -U, -W, and -X
--hexdump[=[1-8][a][bch][A[NUM]][B[NUM]][C[NUM]]]
Output matches in 1 to 8 columns of 8 hexadecimal octets. The
default is 2 columns or 16 octets per line. Argument `a' outputs a
`*' for all hex lines that are identical to the previous hex line,
`b' removes all space breaks, `c' removes the character column, `h'
removes hex spacing, `A' includes up to NUM hex lines after a
match, `B' includes up to NUM hex lines before a match and `C'
includes up to NUM hex lines before and after a match. Arguments
`A', `B' and `C' are the same as options -A, -B and -C when used
with --hexdump. See also options -U, -W and -X.
-U, --ascii, --binary
Disables Unicode matching for binary file matching, forcing PATTERN
to match bytes, not Unicode characters. For example, -U '\xa3'
matches byte A3 (hex) instead of the Unicode code point U+00A3
represented by the UTF-8 sequence C2 A3. See also --dotall.
-W, --with-hex
Output binary matches in hexadecimal, leaving text matches alone.
This option is equivalent to the --binary-files=with-hex option.
To omit the matching line from the hex output, use both options -W
and --hexdump. See also options -U.
-X, --hex
Output matches and matching lines in hexadecimal. This option is
equivalent to the --binary-files=hex option. To omit the matching
line from the hex output use option --hexdump. See also option -U.
--dotall
Dot `.' in regular expressions matches anything, including newline.
Note that `.*' matches all input and should not be used.
Note that --hexdump differs from -X by omitting the matching line from the
hex output, showing only the matching pattern using a minimal number of hex
lines. Additional match context hex lines are output with the -ABC context
options or with --hexdump=C3 to output 3 hex lines as context, for example.
To search a file for ASCII words, displaying text lines as usual while binary
content is shown in hex with -U and -W:
ug -UW '\w+' myfile
To hexdump an entire file as a match with -X:
ug -X '' myfile
To hexdump an entire file with -X, displaying line numbers and byte offsets
with -nb (here with -y to display all line numbers):
ug -Xynb '' myfile
To hexdump lines containing one or more \0 in a (binary) file using a
non-Unicode pattern with -U and -X:
ug -UX '\x00+' myfile
Same, but hexdump the entire file as context with -y (note that this
line-based option does not permit matching patterns with newlines):
ug -UX -y '\x00+' myfile
Same, compacted to 32 bytes per line without the character column:
ug -UX -y '\x00+' myfile
To match the binary pattern A3..A3. (hex) in a binary file without
Unicode pattern matching (which would otherwise match \xaf as a Unicode
character U+00A3 with UTF-8 byte sequence C2 A3) and display the results
in compact hex with --hexdump with pager:
ug --pager --hexdump -U '\xa3[\x00-\xff]{2}\xa3[\x00-\xff]' a.out
Same, but using option --dotall to let . match any byte, including
newline that is not matched by dot (the default as required by grep):
ug --dotall --pager --hexdump -U '\xa3.{2}\xa3.' a.out
To list all files containing a RPM signature, located in the rpm directory and
recursively below (see for example
list of file signatures):
ug -RlU '\A\xed\xab\xee\xdb' rpm
ð Back to table of contents
Ignore binary files with -I
-I Ignore matches in binary files. This option is equivalent to the
--binary-files=without-match option.
To recursively search without following symlinks and ignoring binary files:
ug -rl -I 'xyz'
To ignore specific binary files with extensions such as .exe, .bin, .out, .a,
use --exclude or --exclude-from:
ug -rl --exclude-from=ignore_binaries 'xyz'
where ignore_binaries is a file containing a glob on each line to ignore
matching files, e.g. *.exe, *.bin, *.out, *.a. Because the command is
quite long to type, an alias for this is recommended, for example ugs (ugrep
source):
alias ugs="ugrep --exclude-from=~/ignore_binaries"
ugs -rl 'xyz'
ð Back to table of contents
Ignoring .gitignore-specified files with --ignore-files
--ignore-files[=FILE]
Ignore files and directories matching the globs in each FILE that
is encountered in recursive searches. The default FILE is
`.gitignore'. Matching files and directories located in the
directory of the FILE and in subdirectories below are ignored.
Globbing syntax is the same as the --exclude-from=FILE gitignore
syntax, but files and directories are excluded instead of only
files. Directories are specifically excluded when the glob ends in
a `/'. Files and directories explicitly specified as command line
arguments are never ignored. This option may be repeated to
specify additional files.
Option --ignore-files looks for .gitignore, or the specified FILE, in
recursive searches. When .gitignore, or the specified FILE, is found while
traversing directory tree branches down, the .gitignore file is used to
temporarily extend the previous exclusions with the additional globs in
.gitignore to apply the combined exclusions to the directory tree rooted at
the .gitignore location. Use --stats to show the selection criteria
applied to the search results and the locations of each FILE found. To avoid
confusion, files and directories specified as command-line arguments to
ugrep are never ignored.
Note that exclude glob patterns take priority over include glob patterns when
specified with command line options. By contrast, negated glob patterns
specified with ! in --ignore-files files take priority. This effectively
overrides the exclusions and resolves conflicts in favor of listing matching
files that are explicitly specified as exceptions and should be included in the
search.
See also Using gitignore-style globs to select directories and files to search.
To recursively search without following symlinks, while ignoring files and
directories ignored by .gitignore (when present), use option --ignore-files.
Note that -r is the default when no FILE arguments are specified, we use it
here to make the examples easier to follow.
ug -rl --ignore-files 'xyz'
Same, but includes hidden files with -. rather than ignoring them:
ug -rl. --ignore-files 'xyz'
To recursively list all files that are not ignored by .gitignore (when present)
with --ignore-files:
ug -rl --ignore-files ''
Same, but list shell scripts that are not ignored by .gitignore, when present:
ug -rl -tShell '' --ignore-files
To recursively list all files that are not ignored by .gitignore and are also
not excluded by .git/info/exclude:
ug -rl '' --ignore-files --exclude-from=.git/info/exclude
Same, but by creating a symlink to .git/info/exclude to make the exclusions
implicit:
ln -s .git/info/exclude .ignore
ug -rl '' --ignore-files --ignore-files=.ignore
ð Back to table of contents
Using gitignore-style globs to select directories and files to search
-g GLOBS, --glob=GLOBS
Search only files whose name matches the specified comma-separated
list of GLOBS, same as --include='glob' for each `glob' in GLOBS.
When a `glob' is preceded by a `!' or a `^', skip files whose name
matches `glob', same as --exclude='glob'. When `glob' contains a
`/', full pathnames are matched. Otherwise basenames are matched.
When `glob' ends with a `/', directories are matched, same as
--include-dir='glob' and --exclude-dir='glob'. A leading `/'
matches the working directory. This option may be repeated and may
be combined with options -M, -O and -t to expand searches. See
`ugrep --help globs' and `man ugrep' section GLOBBING for details.
--exclude=GLOB
Skip files whose name matches GLOB using wildcard matching, same as
-g ^GLOB. GLOB can use **, *, ?, and [...] as wildcards, and \\ to
quote a wildcard or backslash character literally. When GLOB
contains a `/', full pathnames are matched. Otherwise basenames
are matched. When GLOB ends with a `/', directories are excluded
as if --exclude-dir is specified. Otherwise files are excluded.
Note that --exclude patterns take priority over --include patterns.
GLOB should be quoted to prevent shell globbing. This option may
be repeated.
--exclude-dir=GLOB
Exclude directories whose name matches GLOB from recursive
searches, same as -g ^GLOB/. GLOB can use **, *, ?, and [...] as
wildcards, and \\ to quote a wildcard or backslash character
literally. When GLOB contains a `/', full pathnames are matched.
Otherwise basenames are matched. Note that --exclude-dir patterns
take priority over --include-dir patterns. GLOB should be quoted
to prevent shell globbing. This option may be repeated.
--exclude-from=FILE
Read the globs from FILE and skip files and directories whose name
matches one or more globs. A glob can use **, *, ?, and [...] as
wildcards, and \ to quote a wildcard or backslash character
literally. When a glob contains a `/', full pathnames are matched.
Otherwise basenames are matched. When a glob ends with a `/',
directories are excluded as if --exclude-dir is specified.
Otherwise files are excluded. A glob starting with a `!' overrides
previously-specified exclusions by including matching files. Lines
starting with a `#' and empty lines in FILE are ignored. When FILE
is a `-', standard input is read. This option may be repeated.
--from=FILE
Read additional pathnames of files to search from FILE. When FILE
is a `-', standard input is read. This option is useful with `find
... -print | ugrep --from=- ...' to search specific files.
--ignore-files[=FILE]
Ignore files and directories matching the globs in each FILE that
is encountered in recursive searches. The default FILE is
`.gitignore'. Matching files and directories located in the
directory of the FILE and in subdirectories below are ignored.
Globbing syntax is the same as the --exclude-from=FILE gitignore
syntax, but files and directories are excluded instead of only
files. Directories are specifically excluded when the glob ends in
a `/'. Files and directories explicitly specified as command line
arguments are never ignored. This option may be repeated to
specify additional files.
--include=GLOB
Search only files whose name matches GLOB using wildcard matching,
same as -g GLOB. GLOB can use **, *, ?, and [...] as wildcards,
and \\ to quote a wildcard or backslash character literally. When
GLOB contains a `/', full pathnames are matched. Otherwise
basenames are matched. When GLOB ends with a `/', directories are
included as if --include-dir is specified. Otherwise files are
included. Note that --exclude patterns take priority over
--include patterns. GLOB should be quoted to prevent shell
globbing. This option may be repeated.
--include-dir=GLOB
Only directories whose name matches GLOB are included in recursive
searches, same as -g GLOB/. GLOB can use **, *, ?, and [...] as
wildcards, and \\ to quote a wildcard or backslash character
literally. When GLOB contains a `/', full pathnames are matched.
Otherwise basenames are matched. Note that --exclude-dir patterns
take priority over --include-dir patterns. GLOB should be quoted
to prevent shell globbing. This option may be repeated.
--include-from=FILE
Read the globs from FILE and search only files and directories
whose name matches one or more globs. A glob can use **, *, ?, and
[...] as wildcards, and \ to quote a wildcard or backslash
character literally. When a glob contains a `/', full pathnames
are matched. Otherwise basenames are matched. When a glob ends
with a `/', directories are included as if --include-dir is
specified. Otherwise files are included. A glob starting with a
`!' overrides previously-specified inclusions by excluding matching
files. Lines starting with a `#' and empty lines in FILE are
ignored. When FILE is a `-', standard input is read. This option
may be repeated.
-O EXTENSIONS, --file-extension=EXTENSIONS
Search only files whose filename extensions match the specified
comma-separated list of EXTENSIONS, same as --include='*.ext' for
each `ext' in EXTENSIONS. When `ext' is preceded by a `!' or a
`^', skip files whose filename extensions matches `ext', same as
--exclude='*.ext'. This option may be repeated and may be combined
with options -g, -M and -t to expand the recursive search.
--stats
Output statistics on the number of files and directories searched,
and the inclusion and exclusion constraints applied.
See also Including or excluding mounted file systems from searches.
Gitignore-style glob syntax and conventions:
| pattern | matches |
|---|---|
* | anything except / |
? | any one character except / |
[abc-e] | one character a,b,c,d,e |
[^abc-e] | one character not a,b,c,d,e,/ |
[!abc-e] | one character not a,b,c,d,e,/ |
/ | when used at the start of a glob, matches working directory |
**/ | zero or more directories |
/** | when at the end of a glob, matches everything after the / |
\? | a ? or any other character specified after the backslash |
When a glob pattern contains a path separator /, the full pathname is
matched. Otherwise the basename of a file or directory is matched in recursive
searches. For example, *.h matches foo.h and bar/foo.h. bar/*.h
matches bar/foo.h but not foo.h and not bar/bar/foo.h.
When a glob pattern begins with a /, files and directories are matched at the
working directory, not recursively. For example, use a leading / to force
/*.h to match foo.h but not bar/foo.h.
When a glob pattern ends with a /, directories are matched instead of files,
same as --include-dir.
When a glob starts with a ! as specified with -g!GLOB, or specified in a
FILE with --include-from=FILE or --exclude-from=FILE, it is negated.
To view a list of inclusions and exclusions that were applied to a search, use
option --stats.
To list only readable files with names starting with foo in the working
directory, that contain xyz, without producing warning messages with -s and
-l:
ug -sl 'xyz' foo*
The same, but using deep recursion with inclusion constraints (note that
-g'/foo* is the same as --include='/foo*' and -g'/foo*/' is the same as
--include-dir='/foo*', i.e. immediate subdirectories matching /foo* only):
ug -rl 'xyz' -g'/foo*' -g'/foo*/'
Note that -r is the default, we use it here to make the examples easier to
follow.
To exclude directory bak located in the working directory:
ug -rl 'xyz' -g'^/bak/'
To exclude all directoies bak at any directory level deep:
ug -rl 'xyz' -g'^bak/'
To only list files in the working directory and its subdirectory doc,
that contain xyz (note that -g'/doc/' is the same as
--include-dir='/doc', i.e. immediate subdirectory doc only):
ug -rl 'xyz' -g'/doc/'
To only list files that are on a subdirectory path doc that includes
subdirectory html anywhere, that contain xyz:
ug -rl 'xyz' -g'doc/**/html/'
To only list files in the working directory and in the subdirectories doc
and doc/latest but not below, that contain xyz:
ug -rl 'xyz' -g'/doc/' -g'/doc/latest/'
To recursively list .cpp files in the working directory and any subdirectory
at any depth, that contain xyz:
ug -rl 'xyz' -g'*.cpp'
The same, but using a .gitignore-style glob that matches pathnames (globs with
/) instead of matching basenames (globs without /) in the recursive search:
ug -rl 'xyz' -g'**/*.cpp'
Same, but using option -Ocpp to match file name extensions:
ug -rl -Ocpp 'xyz'
To recursively list all files in the working directory and below that are not ignored by a specific .gitignore file:
ug -rl '' --exclude-from=.gitignore
To recursively list all files in the working directory and below that are not ignored by one or more .gitignore files, when any are present:
ug -rl '' --ignore-files
ð Back to table of contents
Including or excluding mounted file systems from searches
--exclude-fs=MOUNTS
Exclude file systems specified by MOUNTS from recursive searches.
MOUNTS is a comma-separated list of mount points or pathnames to
directories. When MOUNTS is not specified, only descends into the
file systems associated with the specified file and directory
search targets, i.e. excludes all other file systems. Note that
--exclude-fs=MOUNTS take priority over --include-fs=MOUNTS. This
option may be repeated.
--include-fs=MOUNTS
Only file systems specified by MOUNTS are included in recursive
searches. MOUNTS is a comma-separated list of mount points or
pathnames to directories. When MOUNTS is not specified, restricts
recursive searches to the file system of the working directory,
same as --include-fs=. (dot). Note that --exclude-fs=MOUNTS take
priority over --include-fs=MOUNTS. This option may be repeated.
These options control recursive searches across file systems by comparing device numbers. Mounted devices and symbolic links to files and directories located on mounted file systems may be included or excluded from recursive searches by specifying a mount point or a pathname of any directory on the file system to specify the applicable file system.
Note that a list of mounted file systems is typically stored in /etc/mtab.
To restrict recursive searches to the file system(s) of the search targets
only, without crossing into other file systems (similar to find option -x):
ug -rl --exclude-fs 'xyz' /sys /var
To restrict recursive searches to the file system of the working directory only, without crossing into other file systems:
ug -l --include-fs 'xyz'
In fact, for this case we can use --exclude-fs because we search the working
directory as the target and we want to exclude all other file systems:
ug -l --exclude-fs 'xyz'
To exclude the file systems mounted at /dev and /proc from recursive
searches:
ug -l --exclude-fs=/dev,/proc 'xyz'
To only include the file system associated with drive d: in recursive
searches:
ug -l --include-fs=d:/ 'xyz'
To exclude fuse and tmpfs type file systems from recursive searches:
exfs=`ugrep -w -e fuse -e tmpfs /etc/mtab | ugrep -P '^\S+ (\S+)' --format='%,%1'`
ug -l --exclude-fs="$exfs" 'xyz'
ð Back to table of contents
Counting the number of matches with -c and -co
-c, --count
Only a count of selected lines is written to standard output.
If -o or -u is specified, counts the number of patterns matched.
If -v is specified, counts the number of non-matching lines. If
-m1, (with a comma or --min-count=1) is specified, counts only
matching files without outputting zero matches.
To count the number of lines in a file:
ug -c '' myfile.txt
To count the number of lines with TODO:
ug -c -w 'TODO' myfile.cpp
To count the total number of TODO in a file, use -c and -o:
ug -co -w 'TODO' myfile.cpp
To count the number of ASCII words in a file:
ug -co '[[:word:]]+' myfile.txt
To count the number of ASCII and Unicode words in a file:
ug -co '\w+' myfile.txt
To count the number of Unicode characters in a file:
ug -co '\p{Unicode}' myfile.txt
To count the number of zero bytes in a file:
ug -UX -co '\x00' image.jpg
ð Back to table of contents
Displaying file, line, column, and byte offset info with -H, -n, -k, -b, and -T
-b, --byte-offset
The offset in bytes of a matched line is displayed in front of the
respective matched line. When used with option -u, displays the
offset in bytes of each pattern matched. Byte offsets are exact
for ASCII, UTF-8, and raw binary input. Otherwise, the byte offset
in the UTF-8 converted input is displayed.
-H, --with-filename
Always print the filename with output lines. This is the default
when there is more than one file to search.
-k, --column-number
The column number of a matched pattern is displayed in front of the
respective matched line, starting at column 1. Tabs are expanded
when columns are counted, see option --tabs.
-n, --line-number
Each output line is preceded by its relative line number in the
file, starting at line 1. The line number counter is reset for
each file processed.
-T, --initial-tab
Add a tab space to separate the file name, line number, column
number, and byte offset with the matched line.
To display the file name -H, line -n, and column -k numbers of matches in
myfile.cpp, with spaces and tabs to space the columns apart with -T:
ug -THnk 'main' myfile.cpp
To display the line with -n of word main in myfile.cpp:
ug -nw 'main' myfile.cpp
To display the entire file myfile.cpp with line -n numbers:
ug -n '' myfile.cpp
To recursively search for C++ files with main, showing the line and column
numbers of matches with -n and -k:
ug -r -nk -tc++ 'main'
To display the byte offset of matches with -b:
ug -r -b -tc++ 'main'
To display the line and column numbers of matches in XML with --xml:
ug -r -nk --xml -tc++ 'main'
ð Back to table of contents
Displaying colors with --color and paging the output with --pager
--color[=WHEN], --colour[=WHEN]
Mark up the matching text with the expression stored in the
GREP_COLOR or GREP_COLORS environment variable. The possible
values of WHEN can be `never', `always', or `auto', where `auto'
marks up matches only when output on a terminal. The default is
`auto'.
--colors=COLORS, --colours=COLORS
Use COLORS to mark up text. COLORS is a colon-separated list of
one or more parameters `sl=' (selected line), `cx=' (context line),
`mt=' (matched text), `ms=' (match selected), `mc=' (match
context), `fn=' (file name), `ln=' (line number), `cn=' (column
number), `bn=' (byte offset), `se=' (separator), `qp=' (TUI
prompt), `qe=' (TUI errors), `qr=' (TUI regex), `qm=' (TUI regex
meta characters), `ql=' (TUI regex lists and literals), `qb=' (TUI
regex braces). Parameter values are ANSI SGR color codes or `k'
(black), `r' (red), `g' (green), `y' (yellow), `b' (blue), `m'
(magenta), `c' (cyan), `w' (white), or leave empty for no color.
Upper case specifies background colors. A `+' qualifies a color as
bright. A foreground and a background color may be combined with
font properties `n' (normal), `f' (faint), `h' (highlight), `i'
(invert), `u' (underline). Parameter `hl' enables file name
hyperlinks. Parameter `rv' reverses the `sl=' and `cx=' parameters
when option -v is specified. Selectively overrides GREP_COLORS.
Legacy grep single parameter codes may be specified, for example
--colors='7;32' or --colors=ig to set ms (match selected).
--tag[=TAG[,END]]
Disables colors to mark up matches with TAG. END marks the end of
a match if specified, otherwise TAG. The default is `___'.
--pager[=COMMAND]
When output is sent to the terminal, uses COMMAND to page through
the output. COMMAND defaults to environment variable PAGER when
defined or `less'. Enables --heading and --line-buffered.
--pretty[=WHEN]
When output is sent to a terminal, enables --color, --heading, -n,
--sort, --tree and -T when not explicitly disabled. WHEN can be
`never', `always', or `auto'. The default is `auto'.
--tree, -^
Output directories with matching files in a tree-like format for
option -c or --count, -l or --files-with-matches, -L or
--files-without-match. This option is enabled by --pretty when the
output is sent to a terminal.
To change the color palette, set the GREP_COLORS environment variable or use
--colors=COLORS. The value is a colon-separated list of ANSI SGR parameters
that defaults to cx=33:mt=1;31:fn=1;35:ln=1;32:cn=1;32:bn=1;32:se=36:
| param | result |
|---|---|
sl= | selected lines |
cx= | context lines |
rv | Swaps the sl= and cx= capabilities when -v is specified |
mt= | matching text in any matching line |
ms= | matching text in a selected line. The substring mt= by default |
mc= | matching text in a context line. The substring mt= by default |
fn= | file names |
ln= | line numbers |
cn= | column numbers |
bn= | byte offsets |
se= | separators |
hl | hyperlink file names, same as --hyperlink |
qp= | TUI prompt |
qe= | TUI errors |
qr= | TUI regex |
qm= | TUI regex meta characters |
ql= | TUI regex lists and literals |
qb= | TUI regex braces |
Multiple SGR codes may be specified for a single parameter when separated by a
semicolon, e.g. mt=1;31 specifies bright red. The following SGR codes are
available on most color terminals:
| code | c | effect | code | c | effect |
|---|---|---|---|---|---|
| 0 | n | normal font and color | 2 | f | faint (not widely supported) |
| 1 | h | highlighted bold font | 21 | H | highlighted bold off |
| 4 | u | underline | 24 | U | underline off |
| 7 | i | invert video | 27 | I | invert off |
| 30 | k | black text | 90 | +k | bright gray text |
| 31 | r | red text | 91 | +r | bright red text |
| 32 | g | green text | 92 | +g | bright green text |
| 33 | y | yellow text | 93 | +y | bright yellow text |
| 34 | b | blue text | 94 | +b | bright blue text |
| 35 | m | magenta text | 95 | +m | bright magenta text |
| 36 | c | cyan text | 96 | +c | bright cyan text |
| 37 | w | white text | 97 | +w | bright white text |
| 40 | K | black background | 100 | +K | bright gray background |
| 41 | R | dark red background | 101 | +R | bright red background |
| 42 | G | dark green background | 102 | +G | bright green background |
| 43 | Y | dark yellow backgrounda | 103 | +Y | bright yellow background |
| 44 | B | dark blue background | 104 | +B | bright blue background |
| 45 | M | dark magenta background | 105 | +M | bright magenta background |
| 46 | C | dark cyan background | 106 | +C | bright cyan background |
| 47 | W | dark white background | 107 | +W | bright white background |
See Wikipedia ANSI escape code - SGR parameters
For quick and easy color specification, the corresponding single-letter color names may be used in place of numeric SGR codes and semicolons are not required to separate color names. Color names and numeric codes may be mixed.
For example, to display matches in underlined bright green on bright selected lines, aiding in visualizing white space in matches and file names:
export GREP_COLORS='sl=1:cx=33:ms=1;4;32;100:mc=1;4;32:fn=1;32;100:ln=1;32:cn=1;32:bn=1;32:se=36'
The same, but with single-letter color names:
export GREP_COLORS='sl=h:cx=y:ms=hug+K:mc=hug:fn=hg+K:ln=hg:cn=hg:bn=hg:se=c'
Another color scheme that works well:
export GREP_COLORS='cx=hb:ms=hiy:mc=hic:fn=hi+y+K:ln=hg:cn=hg:bn=hg:se='
Modern Windows command interpreters support ANSI escape codes. Named or
numeric colors can be set with SET GREP_COLORS, for example:
SET GREP_COLORS=sl=1;37:cx=33:mt=1;31:fn=1;35:ln=1;32:cn=1;32:bn=1;32:se=36
To disable colors on Windows:
SET GREP_COLORS=""
Color intensities may differ per platform and per terminal program used, which affects readability.
Option -y outputs every line of input, including non-matching lines as
context. The use of color helps distinguish matches from non-matching context.
To copy silver searcher's color palette:
export GREP_COLORS='mt=30;43:fn=1;32:ln=1;33:cn=1;33:bn=1;33'
To produce color-highlighted results (--color is redundance since it is the
default):
ug --color -r -n -k -tc++ 'FIXME.*'
To page through the results with pager (less -R by default):
ug --pager -r -n -k -tc++ 'FIXME'
To display a hexdump of a zip file itself (i.e. without decompressing), with
color-highlighted matches of the zip magic bytes PK\x03\x04 (--color is
redundant since it is the default):
ug --color -y -UX 'PK\x03\x04' some.zip
To use predefined patterns to list all #include and #define in C++ files:
ug --pretty -r -n -tc++ -f c++/includes -f c++/defines
Same, but overriding the color of matches as inverted yellow (reverse video)
and headings with yellow on blue using --pretty:
ug --pretty --colors="ms=yi:fn=hyB" -r -n -tc++ -f c++/includes -f c++/defines
To list all #define FOO... macros in C++ files, color-highlighted:
ug --color=always -r -n -tc++ -f c++/defines | ug 'FOO.*'
Same, but restricted to .cpp files only:
ug --color=always -r -n -Ocpp -f c++/defines | ug 'FOO.*'
To search tarballs for matching names of PDF files (assuming bash is our shell):
for tb in *.tar *.tar.gz *.tgz; do echo "$tb"; tar tfz "$tb" | ugrep '.*\.pdf$'; done
ð Back to table of contents
Output matches in JSON, XML, CSV, C++
--cpp Output file matches in C++. See also options --format and -u.
--csv Output file matches in CSV. If -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
--json Output file matches in JSON. If -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
--xml Output file matches in XML. If -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
To recursively search for lines with TODO and display C++ file matches in
JSON with line number properties:
ug -tc++ -n --json 'TODO'
To recursively search for lines with TODO and display C++ file matches in
XML with line and column number attributes:
ug -tc++ -nk --xml 'TODO'
To recursively search for lines with TODO and display C++ file matches in CSV
format with file pathname, line number, and column number fields:
ug -tc++ --csv -Hnk 'TODO'
To extract a table from an HTML file and put it in C/C++ source code using
-o:
ug -o --cpp '<tr>.*</tr>' index.html > table.cpp
ð Back to table of contents
Customized output with --format
--format=FORMAT
Output FORMAT-formatted matches. For example --format='%f:%n:%O%~'
outputs matching lines `%O' with filename `%f` and line number `%n'
followed by a newline `%~'. If -P is specified, FORMAT may include
`%1' to `%9', `%[NUM]#' and `%[NAME]#' to output group captures. A
`%%' outputs `%'. See `ugrep --help format' and `man ugrep'
section FORMAT for details. When option -o is specified, option -u
is also enabled. Context options -A, -B, -C and -y are ignored.
-P, --perl-regexp
Interpret PATTERN as a Perl regular expression.
Use option -P to use group captures and backreferences. Capturing groups in
regex patterns are parenthesized expressions (pattern). The first group is
referenced in FORMAT by %1, the second by %2 and so on. Named captures
are of the form (?<NAME>pattern) and are referenced in FORMAT by
%[NAME]#.
The following output formatting options may be used. The FORMAT string
%-fields are listed in a table further below:
| option | result |
|---|---|
--format-begin=FORMAT | FORMAT beginning the search |
--format-open=FORMAT | FORMAT opening a file and a match was found |
--format=FORMAT | FORMAT for each match in a file |
--format-close=FORMAT | FORMAT closing a file and a match was found |
--format-end=FORMAT | FORMAT ending the search |
The following tables show the formatting options corresponding to --csv,
--json, and --xml.
--csv
| option | format string (within quotes) |
|---|---|
--format-open | '%+' |
--format | '%[,]$%H%N%K%B%V%~%u' |
--json
| option | format string (within quotes) |
|---|---|
--format-begin | '[' |
--format-open | '%,%~ {%~ %[,%~ ]$%["file": ]H"matches": [' |
--format | '%,%~ { %[, ]$%["line": ]N%["column": ]K%["offset": ]B"match": %J }%u' |
--format-close | '%~ ]%~ }' |
--format-end | '%~]%~' |
--xml
| option | format string (within quotes) |
|---|---|
--format-begin | '<grep>%~' |
--format-open | ' <file%["]$%[ name="]I>%~' |
--format | ' <match%["]$%[ line="]N%[ column="]K%[ offset="]B>%X</match>%~%u' |
--format-close | ' </file>%~' |
--format-end | '</grep>%~' |
--only-line-number
| option | format string (within quotes) |
|---|---|
--format-open | '%+' |
--format | '%F%n%s%K%B%~%u' |
The following fields may be used in the FORMAT string:
| field | output |
|---|---|
%% | the percentage sign |
%~ | a newline (LF or CRLF in Windows) |
%F | if option -H is used: the file pathname and separator |
%[TEXT]F | if option -H is used: TEXT, the file pathname and separator |
%f | the file pathname |
%a | the file basename without directory path |
%p | the directory path to the file |
%z | the pathname in a (compressed) archive, without { and } |
%H | if option -H is used: the quoted pathname and separator, \" and \\ replace " and \ |
%+ | if option -+ or --heading is used: %F and a newline character, suppress all %F and %H afterward |
%[TEXT]H | if option -H is used: TEXT, the quoted pathname and separator, \" and \\ replace " and \ |
%h | the quoted file pathname, \" and \\ replace " and \ |
%I | if option -H is used: the pathname in XML and separator |
%[TEXT]I | if option -H is used: TEXT, the pathname as XML and separator |
%i | the file pathnames as XML |
%N | if option -n is used: the line number and separator |
%[TEXT]N | if option -n is used: TEXT, the line number and separator |
%n | the line number of the match |
%l | the last line number of the match (multi-line matching) |
%L | the number of lines matched (multi-line matching) |
%K | if option -k is used: the column number and separator |
%[TEXT]K | if option -k is used: TEXT, the column number and separator |
%k | the column number of the match |
%A | byte range (offset and end) of a match in hex |
%B | if option -b is used: the byte offset and separator |
%[TEXT]B | if option -b is used: TEXT, the byte offset and separator |
%b | the byte offset of the match |
%T | if option -T is used: TEXT and a tab character |
%[TEXT]T | if option -T is used: TEXT and a tab character |
%t | a tab character |
%[SEP]$ | set field separator to SEP for the rest of the format fields |
%[TEXT]< | if the first match: TEXT |
%[TEXT]> | if not the first match: TEXT |
%, | if not the first match: a comma, same as %[,]> |
%: | if not the first match: a colon, same as %[:]> |
%; | if not the first match: a semicolon, same as %[;]> |
%â | if not the first match: a vertical bar, same as %[â]> |
%S | if not the first match: separator, see also %[SEP]$ |
%[TEXT]S | if not the first match: TEXT and separator, see also %[SEP]$ |
%s | the separator, see also %[TEXT]S and %[SEP]$ |
%R | if option --break or --heading is used: a newline |
%m | the number of matches, sequential (or number of matching files with --format-end) |
%M | the number of matching lines (or number of matching files with --format-end) |
%O | the matching line is output as is (a raw string of bytes) |
%o | the match is output as is (a raw string of bytes) |
%Q | the matching line as a quoted string, \" and \\ replace " and \ |
%q | the match as a quoted string, \" and \\ replace " and \ |
%C | the matching line formatted as a quoted C/C++ string |
%c | the match formatted as a quoted C/C++ string |
%J | the matching line formatted as a quoted JSON string |
%j | the match formatted as a quoted JSON string |
%V | the matching line formatted as a quoted CSV string |
%v | the match formatted as a quoted CSV string |
%X | the matching line formatted as XML character data |
%x | the match formatted as XML character data |
%Y | the matching line formatted in hex |
%y | the match formatted in hex |
%A | byte range of the match in hex |
%w | the width of the match, counting (wide) characters |
%d | the size of the match, counting bytes |
%e | the ending byte offset of the match |
%Z | the edit distance cost of an approximate match with option -Z |
%u | select unique lines only unless option -u is used |
%[hhhh]U | U+hhhh Unicode code point |
%[CODE]= | a color CODE, such as ms, see colors |
%= | turn color off |
%1 %2 ... %9 | the first regex group capture of the match, and so on up to group %9, requires option -P |
%[NUM]# | the group capture NUM; requires option -P |
%[NUM]b | the byte offset of the group capture NUM; requires option -P |
%[NUM]e | the ending byte offset of the group capture NUM; requires option -P |
%[NUM]d | the byte length of the group capture NUM; requires option -P |
%[NUM]j | the group capture NUM as JSON; requires option -P |
%[NUM]q | the group capture NUM quoted; requires option -P |
%[NUM]x | the group capture NUM as XML; requires option -P |
%[NUM]y | the group capture NUM as hex; requires option -P |
%[NUM]v | the group capture NUM as CSV; requires option -P |
%[NUM1|NUM2|...]# | the first group capture NUM that matched; requires option -P |
%[NUM1|NUM2|...]b | the byte offset of the first group capture NUM that matched; requires option -P. |
%[NUM1|NUM2|...]e | the ending byte offset of the first group capture NUM that matched; requires option -P. |
%[NUM1|NUM2|...]d | the byte length of the first group capture NUM that matched; requires option -P. |
%[NUM1|NUM2|...]j | the first group capture NUM that matched, as JSON; requires option -P |
%[NUM1|NUM2|...]q | the first group capture NUM that matched, quoted; requires option -P |
%[NUM1|NUM2|...]x | the first group capture NUM that matched, as XML; requires option -P |
%[NUM1|NUM2|...]y | the first group capture NUM that matched, as hex; requires option -P |
%[NUM1|NUM2|...]v | the first group capture NUM that matched, as CSV; requires option -P |
%[NAME]# | the NAMEd group capture; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME]b | the byte offset of the NAMEd group capture; requires option -P and capturing pattern (?<NAME>PATTERN). |
%[NAME]e | the ending byte offset of the NAMEd group capture; requires option -P and capturing pattern (?<NAME>PATTERN). |
%[NAME]d | the byte length of the NAMEd group capture; requires option -P and capturing pattern (?<NAME>PATTERN). |
%[NAME]j | the NAMEd group capture as JSON; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME]q | the NAMEd group capture quoted; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME]x | the NAMEd group capture as XML; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME]y | the NAMEd group capture as hex; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME]v | the NAMEd group capture as CSV; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]# | the first NAMEd group capture that matched; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]b | the byte offset of the first NAMEd group capture that matched; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]e | the ending byte offset of the first NAMEd group capture that matched; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]d | the byte length of the first NAMEd group capture that matched; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]j | the first NAMEd group capture that matched, as JSON; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]q | the first NAMEd group capture that matched, quoted; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]x | the first NAMEd group capture that matched, as XML; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]y | the first NAMEd group capture that matched, as hex; requires option -P and capturing pattern (?<NAME>PATTERN) |
%[NAME1|NAME2|...]v | the first NAMEd group capture that matched, as CSV; requires option -P and capturing pattern (?<NAME>PATTERN) |
%G | list of group capture indices/names of the match (see note) |
%[TEXT1|TEXT2|...]G | list of TEXT indexed by group capture indices that matched; requires option -P |
%g | the group capture index of the match or 1 (see note) |
%[TEXT1|TEXT2|...]g | the first TEXT indexed by the first group capture index that matched; requires option -P |
Note:
- Formatted output is written without a terminating newline, unless
%~is explicitly specified in the format string. - Option
-ochanges the output of the%Oand%Qfields to output the match only. - Options
-c,-land-ochange the output of%C,%J,%Xand%Yaccordingly - The
[TEXT]part of a field is optional and may be omitted. When present, the argument must be placed in[]brackets, for example%[,]Fto output a comma, the pathname, and a separator, when option-His used. - Numeric fields such as
%nare padded with spaces when%{width}nis specified. - Matching line fields such as
%Oare cut to width when%{width}Ois specified or when%{-width}Ois specified to cut from the end of the line. - Character context on a matching line before or after a match is output when
%{-width}oor%{+width}ois specified for match fields such as%o, where%{width}owithout a +/- sign cuts the match to the specified width. - Fields
%[SEP]$and%uare switches and do not write anything to the output. - The separator used by
%F,%H,%N,%K,%B,%S, and%Gmay be changed by preceding the field with a%[SEP]$. When[SEP]is not provided, reverts the separator to the default separator or the separator specified by--separator. - Formatted output is written for each matching pattern, which means that a
line may be output multiple times when patterns match more than once on the
same line. When field
%uis found anywhere in the specified format string, matching lines are output only once unless option-u,--ungroupis used or when a newline is matched. - The group capture index value output by
%gcorresponds to the index of the sub-pattern matched among the alternations in the pattern when option-Pis not used. For examplefoo|barmatchesfoowith index 1 andbarwith index 2. With option-P, the index corresponds to the number of the first group captured in the specified pattern. - The strings specified in the list
%[TEXT1|TEXT2|...]Gand%[TEXT1|TEXT2|...]gshould correspond to the group capture index (see the note above), i.e.TEXT1is output for index 1,TEXT2is output for index 2, and so on. If the list is too short, the index value is output or the name of a named group capture is output. - Option
-Tand--prettyadd right-justifying spacing to fields%Nand%Kif no leading[TEXT]part is specified. - Field
%+may be used in--format-opento output the pathname heading and a newline break, respectively. Field%+suppresses%a,%F,%f,%H,%hand%poutput.
To output matching lines faster by omitting the header output and binary match
checks, using --format with field %O (output matching line as is) and field
%~ (output newline):
ug --format='%O%~' 'href=' index.html
Same, but also displaying the line and column numbers:
ug --format='%n%k: %O%~' 'href=' index.html
Same, but display a line at most once when matching multiple patterns, unless
option -u is used:
ug --format='%u%n%k: %O%~' 'href=' index.html
To string together a list of unique line numbers of matches, separated by
commas with field %,:
ug --format='%u%,%n' 'href=' index.html
To output the matching part of a line only with field %o (or option -o with
field %O):
ug --format='%o%~' "href=[\"'][^\"'][\"']" index.html
To string together the pattern matches as CSV-formatted strings with field %v
separated by commas with field %,:
ug --format='%,%v' "href=[\"'][^\"'][\"']" index.html
To output matches in CSV (comma-separated values), the same as option --csv
(works with options -H, -n, -k, -b to add CSV values):
ug --format='"%[,]$%H%N%K%B%V%~%u"' 'href=' index.html
To output matches in AckMate format:
ug --format=":%f%~%n;%k %w:%O%~" 'href=' index.html
To output the sub-pattern indices 1, 2, and 3 on the left to the match for the
three patterns foo, bar, and baz in file foobar.txt:
ug --format='%g: %o%~' 'foo|bar|baz' foobar.txt
Same, but using a file foos containing three lines with foo, bar, and
baz, where option -F is used to match strings instead of regex:
ug -F -f foos --format='%g: %o%~' foobar.txt
To output one, two, and a word for the sub-patterns [fF]oo, [bB]ar,
and any other word \w+, respectively, using argument [one|two|a word] with
field %g indexed by sub-pattern (or group captures with option -P):
ug --format='%[one|two|a word]g%~' '([fF]oo)|([bB]ar)|(\w+)' foobar.txt
To output a list of group capture indices with %G separated by the word and
instead of the default colons with %[ and ]$, followed by the matching line:
ug -P --format='%[ and ]$%G%$%s%O%~' '(foo)|(ba((r)|(z)))' foobar.txt
Same, but showing names instead of numbers:
ug -P --format='%[ and ]$%[foo|ba|r|z]G%$%s%O%~' '(foo)|(ba(?:(r)|(z)))' foobar.txt
Note that option -P is required for general use of group captures for
sub-patterns. Named sub-pattern matches may be used with PCRE2 and shown in
the output:
ug -P --format='%[ and ]$%G%$%s%O%~' '(?P<foo>foo)|(?P<ba>ba(?:(?P<r>r)|(?P<z>z)))' foobar.txt
ð Back to table of contents
Replacing matches with -P --replace and --format using backreferences
--replace=FORMAT
Replace matching patterns in the output by the specified FORMAT
with `%' fields. If -P is specified, FORMAT may include `%1' to
`%9', `%[NUM]#' and `%[NAME]#' to output group captures. A `%%'
outputs `%' and `%~' outputs a newline. See option --format,
`ugrep --help format' and `man ugrep' section FORMAT for details.
-y, --any-line
Any line is output (passthru). Non-matching lines are output as
context with a `-' separator. See also options -A, -B, and -C.
-P, --perl-regexp
Interpret PATTERN as a Perl regular expression.
--format=FORMAT
Output FORMAT-formatted matches. For example --format='%f:%n:%O%~'
outputs matching lines `%O' with filename `%f` and line number `%n'
followed by a newline `%~'. If -P is specified, FORMAT may include
`%1' to `%9', `%[NUM]#' and `%[NAME]#' to output group captures. A
`%%' outputs `%'. See `ugrep --help format' and `man ugrep'
section FORMAT for details. When option -o is specified, option -u
is also enabled. Context options -A, -B, -C and -y are ignored.
See customized output with --format for details on the FORMAT
fields.
For option -o, the replacement is not automatically followed by a newline to
allow for more flexibility in replacements. To output a newline, use %~ in
the FORMAT string.
Use option -P to use group captures and backreferences. Capturing groups in
regex patterns are parenthesized expressions (pattern) and the first is
referenced in FORMAT by %1, the second by %2 and so on. Named captures
are of the form (?<NAME>pattern) and are referenced in FORMAT by
%[NAME]#.
To display pattern matches with their sequential match number using
--replace='%m:%o' where %m is the sequential match number and %o is the
pattern matched:
ug --replace='%m:%o' pattern myfile.txt
Same, but passing the file through with option -y, while applying the
replacements to the output:
ug -y --replace='%m:%o' pattern myfile.txt
To extract table cells from an HTML file using Perl matching (-P) to support
group captures with lazy quantifier (.*?), and translate the matches to a
comma-separated list with format %,%1 (conditional comma and group capture):
ug -P -o '<td>(.*?)</td>' --replace='%,%1' index.html
Same, but using --format='%,%1' instead and we do not need -o (note that
--replace color-highlights matches shown on a terminal but --format does
not):
ug -P '<td>(.*?)</td>' --format='%,%1' index.html
Same, but displaying the formatted matches line-by-line, with --replace or
with --format:
ug -P -o '<td>(.*?)</td>' --replace='%,%1' index.html
ug -P '<td>(.*?)</td>' --format='%1%~' index.html
To collect all href URLs from all HTML and PHP files down the working
directory, then sort them:
ug -r -thtml,php -P '<[^<>]+href\h*=\h*.([^\x27"]+).' --format='%1%~' | sort -u
Same, but much easier by using the predefined html/href pattern:
ug -r -thtml,php -P -f html/href --format='%1%~' | sort -u
Same, but in this case select <script> src URLs when referencing http and
https sites:
ug -r -thtml,php -P '<script.*src\h*=\h*.(https?:[^\x27"]+).' --format='%1%~' | sort -u
ð Back to table of contents
Limiting the number of matches with -1,-2...-9, -K, -m, and --max-files
--depth=[MIN,][MAX], -1, -2, -3, ... -9, -10, -11, -12, ...
Restrict recursive searches from MIN to MAX directory levels deep,
where -1 (--depth=1) searches the specified path without recursing
into subdirectories. Note that -3 -5, -3-5, and -35 search 3 to 5
levels deep. Enables -r if -R or -r is not specified.
-K [MIN,][MAX], --range=[MIN,][MAX], --min-line=MIN, --max-line=MAX
Start searching at line MIN, stop at line MAX when specified.
-m [MIN,][MAX], --min-count=MIN, --max-count=MAX
Require MIN matches, stop after MAX matches when specified. Output
MIN to MAX matches. For example, -m1 outputs the first match and
-cm1, (with a comma) counts nonzero matches. If -u is specified,
each individual match counts. See also option -K.
--max-files=NUM
Restrict the number of files matched to NUM. Note that --sort or
-J1 may be specified to produce replicable results. If --sort is
specified, the number of threads spawned is limited to NUM.
--sort[=KEY]
Displays matching files in the order specified by KEY in recursive
searches. Normally the ug command sorts by name whereas the ugrep
batch command displays matches in no particular order to improve
performance. The sort KEY can be `name' to sort by pathname
(default), `best' to sort by best match with option -Z (sort by
best match requires two passes over files, which is expensive),
`size' to sort by file size, `used' to sort by last access time,
`changed' to sort by last modification time and `created' to sort
by creation time. Sorting is reversed with `rname', `rbest',
`rsize', `rused', `rchanged', or `rcreated'. Archive contents are
not sorted. Subdirectories are sorted and displayed after matching
files. FILE arguments are searched in the same order as specified.
To show only up to the first 10 matching lines with FIXME in C++ files in the
working directory and all subdirectories below:
ug -r -m10 -tc++ FIXME
Same, but recursively search up to two directory levels, meaning that ./ and
./sub/ are visited but not deeper:
ug -2 -m10 -tc++ FIXME
To show only the first two files that have one or more matches of FIXME in
the list of files sorted by pathname, using --max-files=2:
ug --sort -r --max-files=2 -tc++ FIXME
To search file install.sh for the occurrences of the word make after the
first line, we use -K with line number 2 to start searching, where -n shows
the line numbers in the output:
ug -n -K2 -w make install.sh
Same, but restricting the search to lines 2 to 40 (inclusive):
ug -n -K2,40 -w make install.sh
Same, but showing all lines 2 to 40 with -y:
ug -y -n -K2,40 -w make install.sh
Same, but showing only the first four matching lines after line 2, with one line of context:
ug -n -C1 -K2 -m4 -w make install.sh
ð Back to table of contents
Matching empty patterns with -Y
-Y, --empty
Permits empty matches. By default, empty matches are disabled,
unless a pattern begins with `^' or ends with `$'. Note that -Y
when specified with an empty-matching pattern, such as x? and x*,
match all input, not only lines containing the character `x'.
Option -Y permits empty pattern matches, like GNU/BSD grep. This option is
introduced by ugrep to prevent accidental matching with empty patterns:
empty-matching patterns such as x? and x* match all input, not only lines
with x. By default, without -Y, patterns match lines with at least one x
as intended.
This option is automatically enabled when a pattern starts with ^ or ends
with $ is specified. For example, ^\h*$ matches blank lines, including
empty lines.
To recursively list files in the working directory with blank lines, i.e. lines
with white space only, including empty lines (note that option -Y is
implicitly enabled since the pattern starts with ^ and ends with $):
ug -l '^\h*$'
ð Back to table of contents
Case-insentitive matching with -i and -j
-i, --ignore-case
Perform case insensitive matching. By default, ugrep is case
sensitive. By default, this option applies to ASCII letters only.
Use options -P and -i for Unicode case insensitive matching.
-j, --smart-case
Perform case insensitive matching like option -i, unless a pattern
is specified with a literal ASCII upper case letter.
To match todo in myfile.cpp regardless of case:
ug -i 'todo' myfile.txt
To match todo XXX with todo in any case but XXX as given, with pattern
(?i:todo) to match todo ignoring case:
ug '(?i:todo) XXX' myfile.cpp
ð Back to table of contents
Sort files by name, best match, size, and time
--sort[=KEY]
Displays matching files in the order specified by KEY in recursive
searches. Normally the ug command sorts by name whereas the ugrep
batch command displays matches in no particular order to improve
performance. The sort KEY can be `name' to sort by pathname
(default), `best' to sort by best match with option -Z (sort by
best match requires two passes over files, which is expensive),
`size' to sort by file size, `used' to sort by last access time,
`changed' to sort by last modification time and `created' to sort
by creation time. Sorting is reversed with `rname', `rbest',
`rsize', `rused', `rchanged', or `rcreated'. Archive contents are
not sorted. Subdirectories are sorted and displayed after matching
files. FILE arguments are searched in the same order as specified.
Matching files are displayed in the order specified by --sort per directory
searched. By default, the ug command sorts by name whereas the output of the
ugrep command is not sorted to improve performance, unless option -Q is
used which sorts files by name. An optimized sorting method and strategy are
implemented in the asynchronous output class to keep the overhead of sorting
very low. Directories are displayed after files are displayed first, when
recursing, which visually aids the user in finding the "closest" matching files
first at the top of the displayed results.
To recursively search for C++ files that match main and sort them by date
created:
ug --sort=created -tc++ 'main'
Same, but sorted by time changed from most recent to oldest:
ug --sort=rchanged -tc++ 'main'
ð Back to table of contents
Tips for advanced users
When searching non-binary files only, the binary content check is disabled with
option -a (--text) to speed up searching and displaying pattern matches.
For example, searching for lines with int in C++ source code:
ug -r -a -Ocpp -w 'int'
If a file has potentially many pattern matches, but each match is only one a
single line, then option -u (--ungroup) can speed this up:
ug -r -a -u -Opython -w 'def'
Even greater speeds can be achieved with --format when searching files with
many matches. For example, --format='%O%~' displays matching lines for each
match on that line, while --format='%o%~' displays the matching part only.
Note that the --format option does not check for binary matches, so the
output is always "as is". To match text and binary, you can use
--format='%C%~' to display matches formatted as quoted C++ strings with
escapes. To display a line at most once (unless option -u is used), add the
%u (unique) field to the format string, e.g. --format='%u%O%~'.
For example, to match all words recursively in the working directory with line
and column numbers, where %n is the line number, %k is the column number,
%o is the match (only matching), and %~ is a newline:
ug -r --format='%n,%k:%o%~' '\w+'
ð Back to table of contents
More examples
To search for pattern -o in script.sh using -e to explicitly specify a
pattern to prevent pattern -o from being interpreted as an option:
ug -n -e '-o' script.sh
Alternatively, using -- to end the list of command arguments:
ug -n -- '-o' script.sh
To recursively list all text files (.txt and .md) that do not properly end with
a \n (-o is required to match \n or \z):
ug -L -o -Otext '\n\z'
To list all markdown sections in text files (.text, .txt, .TXT, and .md):
ug -o -ttext -e '^.*(?=\r?\n(===|---))' -e '^#{1,6}\h+.*'
To display multi-line backtick and indented code blocks in markdown files with
their line numbers, using a lazy quantifier *? to make the pattern compact:
ug -n -ttext -e '^```(.|\n)*?\n```' -e '^(\t|[ ]{4}).*'
To find mismatched code (a backtick without matching backtick on the same line) in markdown:
ug -n -ttext -e '`[^`]+' -N '`[^`]*`'
ð Back to table of contents
Man page
UGREP(1) User Commands UGREP(1)
NAME
ugrep, ug -- file pattern searcher
SYNOPSIS
ugrep [OPTIONS] [-i|-j] [-Q|PATTERN] [-e PATTERN] [-N PATTERN] [-f FILE]
[-E|-F|-G|-P|-Z] [-U] [-m [MIN,][MAX]] [--bool [--files|--lines]]
[-r|-R|-1|...|-9|-10|-11|...] [-t TYPES] [-g GLOBS] [--sort[=KEY]]
[-q|-l|-c|-o] [-v] [-n] [-k] [-b] [-A NUM] [-B NUM] [-C NUM] [-y]
[--color[=WHEN]|--colour[=WHEN]] [--pretty] [--pager[=COMMAND]]
[--hexdump|--csv|--json|--xml] [-I] [-z] [--zmax=NUM] [FILE ...]
DESCRIPTION
The ugrep utility searches any given input files, selecting files and
lines that match one or more patterns specified as regular expressions or
as fixed strings. A pattern matches multiple input lines when the
pattern's regular expression matches one or more newlines. An empty
pattern matches every line. Each input line that matches at least one of
the patterns is written to the standard output.
The ug command is intended for interactive searching, using a `.ugrep'
configuration file located in the working directory or, if not found, in
the home directory, see CONFIGURATION. ug is equivalent to ugrep
--config --pretty --sort to load a configuration file, enhance the
terminal output, and to sort files by name.
The ugrep+ and ug+ commands are the same as the ugrep and ug commands,
but also use filters to search pdfs, documents, e-books, and image
metadata, when the corresponding filter tools are installed.
A list of matching files is produced with option -l (--files-with-
matches). Option -c (--count) counts the number of matching lines. When
combined with option -o, counts the total number of matches. When
combined with option -m1, (--min-count=1), skips files with zero matches.
The default pattern syntax is an extended form of the POSIX ERE syntax,
same as option -E (--extended-regexp). Try ug --help regex for help with
pattern syntax and how to use logical connectives to specify Boolean
search queries with option -% (--bool) to match lines and -%% (--bool
--files) to match files. Options -F (--fixed-strings), -G (--basic-
regexp) and -P (--perl-regexp) specify other pattern syntaxes.
Option -i (--ignore-case) ignores letter case in patterns. Option -j
(--smart-case) enables -i only if the search patterns are specified in
lower case.
Fuzzy (approximate) search is specified with option -Z (--fuzzy) with an
optional argument to control character insertions, deletions, and/or
substitutions. Try ug --help fuzzy for help with fuzzy search.
Note that pattern `.' matches any non-newline character. Pattern `\n'
matches a newline character. Multiple lines may be matched with patterns
that match one or more newline characters.
The empty pattern "" matches all lines. Other empty-matching patterns do
not. For example, the pattern `a*' will match one or more a's. Option
-Y forces empty matches for compatibility with other grep tools.
Option -f FILE matches patterns specified in FILE.
By default Unicode patterns are matched. Option -U (--ascii or --binary)
disables Unicode matching for ASCII and binary pattern matching. Non-
Unicode matching is more efficient.
ugrep accepts input of various encoding formats and normalizes the output
to UTF-8. When a UTF byte order mark is present in the input, the input
is automatically normalized. An input encoding format may be specified
with option --encoding.
If no FILE arguments are specified and standard input is read from a
terminal, recursive searches are performed as if -r is specified. To
force reading from standard input, specify `-' as a FILE argument.
Directories specified as FILE arguments are searched without recursing
deeper into subdirectories, unless -R, -r, or -2...-9 is specified to
search subdirectories recursively (up to the specified depth.)
Option -I (--ignore-binary) ignores binary files. A binary file is a
file with non-text content. A file with zero bytes or invalid UTF
formatting is considered binary.
Hidden files and directories are ignored in recursive searches. Option
-. (--hidden) includes hidden files and directories in recursive
searches.
To match the names of files to search and the names of directories to
recurse, one or more of the following options may be specified. Option
-O specifies one or more filename extensions to match. Option -t
specifies one or more file types to search (-t list outputs a list of
types.) Option -g specifies a gitignore-style glob pattern to match
filenames. Option --ignore-files specifies a file with gitignore-style
globs to ignore directories and files. Try ug --help globs for help with
filename and directory name matching. See also section GLOBBING.
Compressed files and archives are searched with option -z (--decompress).
When used with option --zmax=NUM, searches the contents of compressed
files and archives stored within archives up to NUM levels.
Output to a terminal for viewing is enhanced with --pretty, which is
enabled by default with the ug command.
A query terminal user interface (TUI) is opened with -Q (--query) to
interactively specify search patterns and view search results. A PATTERN
argument requires -e PATTERN to start the query TUI with the specified
pattern.
A terminal output pager is enabled with --pager that accepts an optional
COMMAND to view the output.
Customized output is produced with option --format or --replace. Try ug
--help format for help with custom formatting of the output. See also
section FORMAT. Predefined formats include CSV with option --csv, JSON
with option --json, and XML with option --xml. Hexdumps are output with
option -X (--hex) or with option --hexdump to customize hexdumps.
A `--' signals the end of options; the rest of the parameters are FILE
arguments, allowing filenames to begin with a `-' character.
Long options may start with `--no-' to disable, when applicable.
ug --help WHAT displays help on options related to WHAT.
The following options are available:
-A NUM, --after-context=NUM
Output NUM lines of trailing context after matching lines. Places
a --group-separator between contiguous groups of matches. If -o
is specified, output the match with context to fit NUM columns
after the match or shortens the match. See also options -B, -C
and -y.
-a, --text
Process a binary file as if it were text. This is equivalent to
the --binary-files=text option. This option might output binary
garbage to the terminal, which can have problematic consequences
if the terminal driver interprets some of it as terminal commands.
--all, -@
Search all files except hidden: cancel previous file and directory
search restrictions and cancel --ignore-binary and --ignore-files
when specified. Restrictions specified after this option, i.e. to
the right, are still applied. For example, -@I searches all
non-binary files and -@. searches all files including hidden
files. Note that hidden files and directories are never searched,
unless option -. or --hidden is specified.
--and [-e] PATTERN
Specify additional PATTERN that must match. Additional -e PATTERN
following this option is considered an alternative pattern to
match, i.e. each -e is interpreted as an OR pattern enclosed
within the AND. For example, -e A -e B --and -e C -e D matches
lines with (`A' or `B') and (`C' or `D'). Note that multiple -e
PATTERN are alternations that bind more tightly together than
--and. Option --stats displays the search patterns applied. See
also options --not, --andnot, --bool, --files and --lines.
--andnot [-e] PATTERN
Combines --and --not. See also options --and, --not and --bool.
-B NUM, --before-context=NUM
Output NUM lines of leading context before matching lines. Places
a --group-separator between contiguous groups of matches. If -o
is specified, output the match with context to fit NUM columns
before the match or shortens the match. See also options -A, -C
and -y.
-b, --byte-offset
The offset in bytes of a pattern match is displayed in front of
the respective matched line. When -u or --ungroup is specified,
displays the offset for each pattern matched on the same line.
Byte offsets are exact for ASCII, UTF-8 and raw binary input.
Otherwise, the offset in the UTF-8-normalized input is displayed.
--binary-files=TYPE
Controls searching and reporting pattern matches in binary files.
TYPE can be `binary', `without-match`, `text`, `hex` and
`with-hex'. The default is `binary' to search binary files and to
report a match without displaying the match. `without-match'
ignores binary matches. `text' treats all binary files as text,
which might output binary garbage to the terminal, which can have
problematic consequences if the terminal driver interprets some of
it as commands. `hex' reports all matches in hexadecimal.
`with-hex' only reports binary matches in hexadecimal, leaving
text matches alone. Files having NUL (zero) bytes are binary and
files with invalid UTF encoding are binary unless option -U or
--ascii or --binary is specified. Short options are -a, -I, -W,
-X.
--bool, -%, -%%
Specifies Boolean query patterns. A Boolean query pattern is
composed of `AND', `OR', `NOT' operators and grouping with `('
`)'. Spacing between subpatterns is the same as `AND', `|' is the
same as `OR' and a `-' is the same as `NOT'. The `OR' operator
binds more tightly than `AND'. For example, --bool 'A|B C|D'
matches lines with (`A' or `B') and (`C' or `D'), --bool 'A -B'
matches lines with `A' and not `B'. Operators `AND', `OR', `NOT'
require proper spacing. For example, --bool 'A OR B AND C OR D'
matches lines with (`A' or `B') and (`C' or `D'), --bool 'A AND
NOT B' matches lines with `A' without `B'. Quoted subpatterns are
matched literally as strings. For example, --bool 'A "AND"|"OR"'
matches lines with `A' and also either `AND' or `OR'. Parentheses
are used for grouping. For example, --bool '(A B)|C' matches
lines with `A' and `B', or lines with `C'. Note that all
subpatterns in a Boolean query pattern are regular expressions,
unless -F is specified. Options -E, -F, -G, -P and -Z can be
combined with --bool to match subpatterns as strings or regular
expressions (-E is the default.) This option does not apply to -f
FILE patterns. The double short option -%% enables options --bool
--files. Option --stats displays the Boolean search patterns
applied. See also options --and, --andnot, --not, --files and
--lines.
--break
Adds a line break between results from different files. This
option is enabled by --heading.
-C NUM, --context=NUM
Output NUM lines of leading and trailing context surrounding each
matching line. Places a --group-separator between contiguous
groups of matches. If -o is specified, output the match with
context to fit NUM columns before and after the match or shortens
the match. See also options -A, -B and -y.
-c, --count
Only a count of selected lines is written to standard output.
When -o or -u is specified, counts the number of patterns matched.
When -v is specified, counts the number of non-matching lines.
When -m1, (with a comma or --min-count=1) is specified, counts
only matching files without outputting zero matches.
--color[=WHEN], --colour[=WHEN]
Mark up the matching text with the colors specified with option
--colors or the GREP_COLOR or GREP_COLORS environment variable.
WHEN can be `never', `always', or `auto', where `auto' marks up
matches only when output on a terminal. The default is `auto'.
--colors=COLORS, --colours=COLORS
Use COLORS to mark up text. COLORS is a colon-separated list of
one or more parameters `sl=' (selected line), `cx=' (context
line), `mt=' (matched text), `ms=' (match selected), `mc=' (match
context), `fn=' (file name), `ln=' (line number), `cn=' (column
number), `bn=' (byte offset), `se=' (separator), `qp=' (TUI
prompt), `qe=' (TUI errors), `qr=' (TUI regex), `qm=' (TUI regex
meta characters), `ql=' (TUI regex lists and literals), `qb=' (TUI
regex braces). Parameter values are ANSI SGR color codes or `k'
(black), `r' (red), `g' (green), `y' (yellow), `b' (blue), `m'
(magenta), `c' (cyan), `w' (white), or leave empty for no color.
Upper case specifies background colors. A `+' qualifies a color
as bright. A foreground and a background color may be combined
with font properties `n' (normal), `f' (faint), `h' (highlight),
`i' (invert), `u' (underline). Parameter `hl' enables file name
hyperlinks. Parameter `rv' reverses the `sl=' and `cx='
parameters when option -v is specified. Selectively overrides
GREP_COLORS. Legacy grep single parameter codes may be specified,
for example --colors='7;32' or --colors=ig to set ms (match
selected).
--config[=FILE], ---[FILE]
Use configuration FILE. The default FILE is `.ugrep'. The
working directory is checked first for FILE, then the home
directory. The options specified in the configuration FILE are
parsed first, followed by the remaining options specified on the
command line. The ug command automatically loads a `.ugrep'
configuration file when present, unless --config=FILE or
--no-config is specified.
--no-config
Do not automatically load the default .ugrep configuration file.
--no-confirm
Do not confirm actions in -Q query TUI. The default is confirm.
--cpp Output file matches in C++. See also options --format and -u.
--csv Output file matches in CSV. When -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
-D ACTION, --devices=ACTION
If an input file is a device, FIFO or socket, use ACTION to
process it. By default, ACTION is `skip', which means that
devices are silently skipped. When ACTION is `read', devices read
just as if they were ordinary files.
-d ACTION, --directories=ACTION
If an input file is a directory, use ACTION to process it. By
default, ACTION is `skip', i.e., silently skip directories unless
specified on the command line. When ACTION is `read', warn when
directories are read as input. When ACTION is `recurse', read all
files under each directory, recursively, following symbolic links
only if they are on the command line. This is equivalent to the
-r option. When ACTION is `dereference-recurse', read all files
under each directory, recursively, following symbolic links. This
is equivalent to the -R option.
--delay=DELAY
Set the default -Q key response delay. Default is 3 for 300ms.
--depth=[MIN,][MAX], -1, -2, -3, ... -9, -10, -11, ...
Restrict recursive searches from MIN to MAX directory levels deep,
where -1 (--depth=1) searches the specified path without recursing
into subdirectories. The short forms -3 -5, -3-5 and -3,5 search
3 to 5 levels deep. Enables -r if -R or -r is not specified.
--dotall
Dot `.' in regular expressions matches anything, including
newline. Note that `.*' matches all input and should not be used.
-E, --extended-regexp
Interpret patterns as extended regular expressions (EREs). This is
the default.
-e PATTERN, --regexp=PATTERN
Specify a PATTERN to search the input. An input line is selected
if it matches any of the specified patterns. This option is
useful when multiple -e options are used to specify multiple
patterns, or when a pattern starts with a dash (`-'), or to
specify a pattern after option -f or after the FILE arguments.
--encoding=ENCODING
The encoding format of the input. The default ENCODING is binary
or UTF-8 which are treated the same. Therefore, --encoding=binary
has no effect. Contrast this with option -U or --ascii or
--binary that specifies raw binary PATTERN matching. ENCODING can
be: `binary', `ASCII', `UTF-8', `UTF-16', `UTF-16BE', `UTF-16LE',
`UTF-32', `UTF-32BE', `UTF-32LE', `LATIN1', `ISO-8859-1',
`ISO-8859-2', `ISO-8859-3', `ISO-8859-4', `ISO-8859-5',
`ISO-8859-6', `ISO-8859-7', `ISO-8859-8', `ISO-8859-9',
`ISO-8859-10', `ISO-8859-11', `ISO-8859-13', `ISO-8859-14',
`ISO-8859-15', `ISO-8859-16', `MAC', `MACROMAN', `EBCDIC',
`CP437', `CP850', `CP858', `CP1250', `CP1251', `CP1252', `CP1253',
`CP1254', `CP1255', `CP1256', `CP1257', `CP1258', `KOI8-R',
`KOI8-U', `KOI8-RU', `null-data'.
--exclude=GLOB
Exclude files whose name matches GLOB, same as -g ^GLOB. GLOB can
use **, *, ?, and [...] as wildcards and \ to quote a wildcard or
backslash character literally. When GLOB contains a `/', full
pathnames are matched. Otherwise basenames are matched. When
GLOB ends with a `/', directories are excluded as if --exclude-dir
is specified. Otherwise files are excluded. Note that --exclude
patterns take priority over --include patterns. GLOB should be
quoted to prevent shell globbing. This option may be repeated.
--exclude-dir=GLOB
Exclude directories whose name matches GLOB from recursive
searches, same as -g ^GLOB/. GLOB may use **, *, ?, and [...] as
wildcards and \ to quote a wildcard or backslash character
literally. When GLOB contains a `/', full pathnames are matched.
Otherwise basenames are matched. Note that --exclude-dir patterns
take priority over --include-dir patterns. GLOB should be quoted
to prevent shell globbing. This option may be repeated.
--exclude-from=FILE
Read the globs from FILE and skip files and directories whose name
matches one or more globs. A glob may use **, *, ?, and [...] as
wildcards and \ to quote a wildcard or backslash character
literally. When a glob contains a `/', full pathnames are
matched. Otherwise basenames are matched. When a glob ends with
a `/', directories are excluded as if --exclude-dir is specified.
Otherwise files are excluded. A glob starting with a `!'
overrides previously-specified exclusions by including matching
files. Lines starting with a `#' and empty lines in FILE are
ignored. When FILE is a `-', standard input is read. This option
may be repeated.
--exclude-fs=MOUNTS
Exclude file systems specified by MOUNTS from recursive searches.
MOUNTS is a comma-separated list of mount points or pathnames to
directories. When MOUNTS is not specified, only descends into the
file systems associated with the specified file and directory
search targets, i.e. excludes all other file systems. Note that
--exclude-fs=MOUNTS take priority over --include-fs=MOUNTS. This
option may be repeated.
-F, --fixed-strings
Interpret pattern as a set of fixed strings, separated by
newlines, any of which is to be matched. This makes ugrep behave
as fgrep. If a PATTERN is specified, or -e PATTERN or -N PATTERN,
then this option has no effect on -f FILE patterns to allow -f
FILE patterns to narrow or widen the scope of the PATTERN search.
-f FILE, --file=FILE
Read newline-separated patterns from FILE. White space in
patterns is significant. Empty lines in FILE are ignored. If
FILE does not exist, the GREP_PATH environment variable is used as
path to FILE. If that fails, looks for FILE in
/usr/local/share/ugrep/patterns. When FILE is a `-', standard
input is read. Empty files contain no patterns; thus nothing is
matched. This option may be repeated.
--filter=COMMANDS
Filter files through the specified COMMANDS first before
searching. COMMANDS is a comma-separated list of `exts:command
arguments', where `exts' is a comma-separated list of filename
extensions and `command' is a filter utility. Files matching one
of `exts' are filtered. A `*' matches any file. The specified
`command' may include arguments separated by spaces. An argument
may be quoted to include spacing, commas or a `%'. A `%' argument
expands into the pathname to search. For example,
--filter='pdf:pdftotext % -' searches PDF files. The `%' expands
into a `-' when searching standard input. When a `%' is not
specified, the filter command should read from standard input and
write to standard output. Option --label=.ext may be used to
specify extension `ext' when searching standard input. This
option may be repeated.
--filter-magic-label=[+]LABEL:MAGIC
Associate LABEL with files whose signature "magic bytes" match the
MAGIC regex pattern. Only files that have no filename extension
are labeled, unless +LABEL is specified. When LABEL matches an
extension specified in --filter=COMMANDS, the corresponding
command is invoked. This option may be repeated.
--format=FORMAT
Output FORMAT-formatted matches. For example
--format='%f:%n:%O%~' outputs matching lines `%O' with filename
`%f` and line number `%n' followed by a newline `%~'. If -P is
specified, FORMAT may include `%1' to `%9', `%[NUM]#' and
`%[NAME]#' to output group captures. A `%%' outputs `%'. See
`ugrep --help format' and `man ugrep' section FORMAT for details.
When option -o is specified, option -u is also enabled. Context
options -A, -B, -C and -y are ignored.
--free-space
Spacing (blanks and tabs) in regular expressions are ignored.
--from=FILE
Read additional pathnames of files to search from FILE. When FILE
is a `-', standard input is read. This option is useful with
`find
-G, --basic-regexp
Interpret patterns as basic regular expressions (BREs).
-g GLOBS, --glob=GLOBS, --iglob=GLOBS
Only search files whose name matches the specified comma-separated
list of GLOBS, same as --include='glob' for each `glob' in GLOBS.
When a `glob' is preceded by a `!' or a `^', skip files whose name
matches `glob', same as --exclude='glob'. When `glob' contains a
`/', full pathnames are matched and option -r is enabled to
recurse into directories if -d, -r or -R is not already specified.
Otherwise basenames are matched. When `glob' ends with a `/',
directories are matched, same as --include-dir='glob' and
--exclude-dir='glob'. A leading `./' or just `/' matches the
working directory. Option --iglob=GLOBS performs case-insensitive
name matching. This option may be repeated and may be combined
with options -M, -O and -t. For more details, see `ugrep --help
globs' and `man ugrep' section GLOBBING for details.
--glob-ignore-case
Perform case-insensitive glob matching in general.
--group-separator[=SEP]
Use SEP as a group separator for context options -A, -B and -C.
The default is a double hyphen (`--').
--no-group-separator
Removes the group separator line from the output for context
options -A, -B and -C.
-H, --with-filename
Always print the filename with output lines. This is the default
when there is more than one file to search.
-h, --no-filename
Never print filenames with output lines. This is the default when
there is only one file (or only standard input) to search.
--heading, -+
Group matches per file. Adds a heading and a line break between
results from different files. This option is enabled by --pretty
when the output is sent to a terminal.
--help [WHAT], -? [WHAT]
Display a help message on options related to WHAT when specified.
In addition, `--help regex' displays an overview of regular
expressions, `--help globs' displays an overview of glob syntax
and conventions, `--help fuzzy' displays details of fuzzy search,
and `--help format' displays a list of option --format=FORMAT
fields.
--hexdump[=[1-8][a][bch][A[NUM]][B[NUM]][C[NUM]]]
Output matches in 1 to 8 columns of 8 hexadecimal octets. The
default is 2 columns or 16 octets per line. Argument `a' outputs
a `*' for all hex lines that are identical to the previous hex
line, `b' removes all space breaks, `c' removes the character
column, `h' removes hex spacing, `A' includes up to NUM hex lines
after a match, `B' includes up to NUM hex lines before a match and
`C' includes up to NUM hex lines before and after a match.
Arguments `A', `B' and `C' are the same as options -A, -B and -C
when used with --hexdump. See also options -U, -W and -X.
--hidden, -.
Search hidden files and directories (enabled by default in grep
compatibility mode).
--hyperlink[=[PREFIX][+]]
Hyperlinks are enabled for file names when colors are enabled.
Same as --colors=hl. When PREFIX is specified, replaces file://
with PREFIX:// in the hyperlink. A `+' includes the line number
in the hyperlink and when option -k is specified, the column
number.
-I, --ignore-binary
Ignore matches in binary files. This option is equivalent to the
--binary-files=without-match option. Files having NUL (zero)
bytes are binary. Also files with invalid UTF encoding are binary
unless option -U or --ascii or --binary is specified.
-i, --ignore-case
Perform case insensitive matching. By default, ugrep is case
sensitive.
--ignore-files[=FILE]
Ignore files and directories matching the globs in each FILE that
is encountered in recursive searches. The default FILE is
`.gitignore'. Matching files and directories located in the
directory of the FILE and in subdirectories below are ignored.
Globbing syntax is the same as the --exclude-from=FILE gitignore
syntax, but files and directories are excluded instead of only
files. Directories are specifically excluded when the glob ends
in a `/'. Files and directories explicitly specified as command
line arguments are never ignored. This option may be repeated to
specify additional files.
--no-ignore-files
Do not ignore files, i.e. cancel --ignore-files when specified.
--include=GLOB
Only search files whose name matches GLOB, same as -g GLOB. GLOB
may use **, *, ?, and [...] as wildcards and \ to quote a wildcard
or backslash character literally. When GLOB contains a `/', full
pathnames are matched and option -r is enabled to recurse into
directories if -d, -r or -R is not already specified. Otherwise
basenames are matched. When GLOB ends with a `/', directories are
included as if --include-dir is specified. Otherwise files are
included. Note that --exclude patterns take priority over
--include patterns. GLOB should be quoted to prevent shell
globbing. This option may be repeated.
--include-dir=GLOB
Only directories whose name matches GLOB are included in recursive
searches, same as -g GLOB/. GLOB may use **, *, ?, and [...] as
wildcards and \ to quote a wildcard or backslash character
literally. When GLOB contains a `/', full pathnames are matched
and option -r is enabled to recurse into directories if -d, -r or
-R is not already specified. Otherwise basenames are matched.
Note that --exclude-dir patterns take priority over --include-dir
patterns. GLOB should be quoted to prevent shell globbing. This
option may be repeated.
--include-from=FILE
Read the globs from FILE and search only files and directories
whose name matches one or more globs. A glob may use **, *, ?,
and [...] as wildcards and \ to quote a wildcard or backslash
character literally. When a glob contains a `/', full pathnames
are matched. Otherwise basenames are matched. When a glob ends
with a `/', directories are included as if --include-dir is
specified. Otherwise files are included. A glob starting with a
`!' overrides previously-specified inclusions by excluding
matching files. Lines starting with a `#' and empty lines in FILE
are ignored. When FILE is a `-', standard input is read. This
option may be repeated.
--include-fs=MOUNTS
Only file systems specified by MOUNTS are included in recursive
searches. MOUNTS is a comma-separated list of mount points or
pathnames to directories. When MOUNTS is not specified, restricts
recursive searches to the file system of the working directory,
same as --include-fs=. (dot). Note that --exclude-fs=MOUNTS take
priority over --include-fs=MOUNTS. This option may be repeated.
--index
Perform fast index-based recursive search. This option assumes,
but does not require, that files are indexed with ugrep-indexer.
This option also enables option -r or --recursive. Skips indexed
non-matching files, archives and compressed files. Significant
acceleration may be achieved on cold (not file-cached) and large
file systems, or any file system that is slow to search. Note
that the start-up time to search may be increased when complex
search patterns are specified that contain large Unicode character
classes combined with `*' or `+' repeats, which should be avoided.
Option -U or --ascii or --binary improves performance. Option
--stats displays an index search report.
-J NUM, --jobs=NUM
Specifies the number of threads spawned to search files. By
default an optimum number of threads is spawned to search files
simultaneously. -J1 disables threading: files are searched in the
same order as specified.
-j, --smart-case
Perform case insensitive matching, unless a pattern is specified
with a literal upper case letter.
--json Output file matches in JSON. When -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
-K [MIN,][MAX], --range=[MIN,][MAX], --min-line=MIN, --max-line=MAX
Start searching at line MIN, stop at line MAX when specified.
-k, --column-number
The column number of a pattern match is displayed in front of the
respective matched line, starting at column 1. Tabs are expanded
in counting columns, see also option --tabs.
-L, --files-without-match
Only the names of files not containing selected lines are written
to standard output. Pathnames are listed once per file searched.
If the standard input is searched, the string ``(standard input)''
is written.
-l, --files-with-matches
Only the names of files containing selected lines are written to
standard output. ugrep will only search a file until a match has
been found, making searches potentially less expensive. Pathnames
are listed once per file searched. If the standard input is
searched, the string ``(standard input)'' is written.
--label=LABEL
Displays the LABEL value when input is read from standard input
where a file name would normally be printed in the output.
Associates a filename extension with standard input when LABEL has
a suffix. The default value is `(standard input)'.
--line-buffered
Force output to be line buffered instead of block buffered.
--lines
Boolean line matching mode for option --bool, the default mode.
-M MAGIC, --file-magic=MAGIC
Only search files matching the magic signature pattern MAGIC. The
signature "magic bytes" at the start of a file are compared to the
MAGIC regex pattern. When matching, the file will be searched.
When MAGIC is preceded by a `!' or a `^', skip files with matching
MAGIC signatures. This option may be repeated and may be combined
with options -O and -t. Every file on the search path is read,
making recursive searches potentially more expensive.
-m [MIN,][MAX], --min-count=MIN, --max-count=MAX
Require MIN matches, stop after MAX matches when specified.
Output MIN to MAX matches. For example, -m1 outputs the first
match and -cm1, (with a comma) counts nonzero matches. When -u or
--ungroup is specified, each individual match counts. See also
option -K.
--match
Match all input. Same as specifying an empty pattern to search.
--max-files=NUM
Restrict the number of files matched to NUM. Note that --sort or
-J1 may be specified to produce replicable results. If --sort is
specified, then the number of threads spawned is limited to NUM.
--mmap[=MAX]
Use memory maps to search files. By default, memory maps are used
under certain conditions to improve performance. When MAX is
specified, use up to MAX mmap memory per thread.
-N PATTERN, --neg-regexp=PATTERN
Specify a negative PATTERN to reject specific -e PATTERN matches
with a counter pattern. Note that longer patterns take precedence
over shorter patterns, i.e. a negative pattern must be of the same
length or longer to reject matching patterns. Option -N cannot be
specified with -P. This option may be repeated.
-n, --line-number
Each output line is preceded by its relative line number in the
file, starting at line 1. The line number counter is reset for
each file processed.
--not [-e] PATTERN
Specifies that PATTERN should not match. Note that -e A --not -e
B matches lines with `A' or lines without a `B'. To match lines
with `A' that have no `B', specify -e A --andnot -e B. Option
--stats displays the search patterns applied. See also options
--and, --andnot, --bool, --files and --lines.
--null, -0
Output a zero byte after the file name. This option can be used
with commands such as `find -print0' and `xargs -0' to process
arbitrary file names, even those that contain newlines. See also
options -H or --with-filename and --null-data.
--null-data, -00
Input and output are treated as sequences of lines with each line
terminated by a zero byte instead of a newline; effectively swaps
NUL with LF in the input and the output. When combined with
option --encoding=ENCODING, output each line terminated by a zero
byte without affecting the input specified as per ENCODING.
Instead of option --null-data, option --encoding=null-data treats
the input as a sequence of lines terminated by a zero byte without
affecting the output. Option --null-data is not compatible with
UTF-16/32 input. See also options --encoding and --null.
-O EXTENSIONS, --file-extension=EXTENSIONS
Only search files whose filename extensions match the specified
comma-separated list of EXTENSIONS, same as -g '*.ext' for each
`ext' in EXTENSIONS. When an `ext' is preceded by a `!' or a `^',
skip files whose filename extensions matches `ext', same as -g
'^*.ext'. This option may be repeated and may be combined with
options -g, -M and -t.
-o, --only-matching
Only the matching part of a pattern match is output. When -A, -B
or -C is specified, fits the match and its context on a line
within the specified number of columns.
--only-line-number
Only the line number of a matching line is output. The line
number counter is reset for each file processed.
--files, -%%
Boolean file matching mode, the opposite of --lines. When
combined with option --bool, matches a file if all Boolean
conditions are satisfied. For example, --bool --files 'A B|C -D'
matches a file if some lines match `A', and some lines match
either `B' or `C', and no line matches `D'. See also options
--and, --andnot, --not, --bool and --lines. The double short
option -%% enables options --bool --files.
-P, --perl-regexp
Interpret PATTERN as a Perl regular expression using PCRE2. Note
that Perl pattern matching differs from the default grep POSIX
pattern matching.
-p, --no-dereference
If -R or -r is specified, do not follow symbolic links, even when
symbolic links are specified on the command line.
--pager[=COMMAND]
When output is sent to the terminal, uses COMMAND to page through
the output. COMMAND defaults to environment variable PAGER when
defined or `less'. Enables --heading and --line-buffered.
--pretty[=WHEN]
When output is sent to a terminal, enables --color, --heading, -n,
--sort, --tree and -T when not explicitly disabled. WHEN can be
`never', `always', or `auto'. The default is `auto'.
-Q[=DELAY], --query[=DELAY]
Query mode: start a TUI to perform interactive searches. This
mode requires an ANSI capable terminal. An optional DELAY
argument may be specified to reduce or increase the response time
to execute searches after the last key press, in increments of
100ms, where the default is 3 (300ms delay). No whitespace may be
given between -Q and its argument DELAY. Initial patterns may be
specified with -e PATTERN, i.e. a PATTERN argument requires option
-e. Press F1 or CTRL-Z to view the help screen. Press F2 or
CTRL-Y to invoke a command to view or edit the file shown at the
top of the screen. This command can be specified with option
--view and defaults to environment variable PAGER when defined, or
VISUAL or EDITOR. Press TAB or SHIFT-TAB to navigate directories
and to select a file to search. Press ENTER to select lines to
output. Press ALT-l for option -l to list files, ALT-n for -n,
etc. Non-option commands include ALT-] to increase context and
ALT-} to increase fuzzyness. If ALT or OPTION keys are not
available, then press CTRL-O + KEY to switch option `KEY', or
press F1 or CTRL-Z for help and press KEY. See also options
--no-confirm, --delay, --split and --view.
-q, --quiet, --silent
Quiet mode: suppress all output. Only search a file until a match
has been found.
-R, --dereference-recursive
Recursively read all files under each directory, following
symbolic links to files and directories, unlike -r.
-r, --recursive
Recursively read all files under each directory, following
symbolic links only if they are on the command line. Note that
when no FILE arguments are specified and input is read from a
terminal, recursive searches are performed as if -r is specified.
--replace=FORMAT
Replace matching patterns in the output by FORMAT with `%' fields.
If -P is specified, FORMAT may include `%1' to `%9', `%[NUM]#' and
`%[NAME]#' to output group captures. A `%%' outputs `%' and `%~'
outputs a newline. See also option --format, `ugrep --help
format' and `man ugrep' section FORMAT for details.
-S, --dereference-files
When -r is specified, follow symbolic links to files, but not to
directories. The default is not to follow symbolic links.
-s, --no-messages
Silent mode: nonexistent and unreadable files are ignored and
their error messages and warnings are suppressed.
--save-config[=FILE] [OPTIONS]
Save configuration FILE to include OPTIONS. Update FILE when
first loaded with --config=FILE. The default FILE is `.ugrep',
which is automatically loaded by the ug command. When FILE is a
`-', writes the configuration to standard output. Only part of
the OPTIONS are saved that do not cause searches to fail when
combined with other options. Additional options may be specified
by editing the saved configuration file. A configuration file may
be modified by adding one or more config=FILE to include
configuration files, but recursive configuration file inclusion is
not permitted.
--separator[=SEP], --context-separator=SEP
Use SEP as field separator between file name, line number, column
number, byte offset and the matched line. The default separator
is a colon (`:') and a bar (`|') for multi-line pattern matches,
and a dash (`-') for context lines. See also option
--group-separator.
--split
Split the -Q query TUI screen on startup.
--sort[=KEY]
Displays matching files in the order specified by KEY in recursive
searches. Normally the ug command sorts by name whereas the ugrep
batch command displays matches in no particular order to improve
performance. The sort KEY can be `name' to sort by pathname
(default), `best' to sort by best match with option -Z (sort by
best match requires two passes over files, which is expensive),
`size' to sort by file size, `used' to sort by last access time,
`changed' to sort by last modification time and `created' to sort
by creation time. Sorting is reversed with `rname', `rbest',
`rsize', `rused', `rchanged', or `rcreated'. Archive contents are
not sorted. Subdirectories are sorted and displayed after
matching files. FILE arguments are searched in the same order as
specified.
--stats
Output statistics on the number of files and directories searched
and the inclusion and exclusion constraints applied.
-T, --initial-tab
Add a tab space to separate the file name, line number, column
number and byte offset with the matched line.
-t TYPES, --file-type=TYPES
Search only files associated with TYPES, a comma-separated list of
file types. Each file type corresponds to a set of filename
extensions passed to option -O and filenames passed to option -g.
For capitalized file types, the search is expanded to include
files with matching file signature magic bytes, as if passed to
option -M. When a type is preceded by a `!' or a `^', excludes
files of the specified type. Specifying the initial part of a
type name suffices when the choice is unambiguous. This option
may be repeated. The possible file types can be (-tlist displays
a list): `actionscript', `ada', `adoc', `asm', `asp', `aspx',
`autoconf', `automake', `awk', `Awk', `basic', `batch', `bison',
`c', `c++', `clojure', `cpp', `csharp', `css', `csv', `dart',
`Dart', `delphi', `elisp', `elixir', `erlang', `fortran', `gif',
`Gif', `go', `groovy', `gsp', `haskell', `html', `jade', `java',
`jpeg', `Jpeg', `js', `json', `jsp', `julia', `kotlin', `less',
`lex', `lisp', `lua', `m4', `make', `markdown', `matlab', `node',
`Node', `objc', `objc++', `ocaml', `parrot', `pascal', `pdf',
`Pdf', `perl', `Perl', `php', `Php', `png', `Png', `prolog',
`python', `Python', `r', `rpm', `Rpm', `rst', `rtf', `Rtf',
`ruby', `Ruby', `rust', `scala', `scheme', `seed7', `shell',
`Shell', `smalltalk', `sql', `svg', `swift', `tcl', `tex', `text',
`tiff', `Tiff', `tt', `typescript', `verilog', `vhdl', `vim',
`xml', `Xml', `yacc', `yaml', `zig'.
--tabs[=NUM]
Set the tab size to NUM to expand tabs for option -k. The value
of NUM may be 1 (no expansion), 2, 4, or 8. The default size is
8.
--tag[=TAG[,END]]
Disables colors to mark up matches with TAG. END marks the end of
a match if specified, otherwise TAG. The default is `___'.
--tree, -^
Output directories with matching files in a tree-like format for
option -c or --count, -l or --files-with-matches, -L or
--files-without-match. This option is enabled by --pretty when
the output is sent to a terminal.
-U, --ascii, --binary
Disables Unicode matching for ASCII and binary matching. PATTERN
matches bytes. For example, -U '\xa3' matches byte A3 (hex)
instead of the Unicode code point U+00A3 represented by the UTF-8
sequence C2 A3. Input is not flagged as "binary" for having
invalid UTF, only for having NUL (zero) bytes.
-u, --ungroup
Do not group multiple pattern matches on the same matched line.
Output the matched line again for each additional pattern match.
-V, --version
Display version with linked libraries and exit.
-v, --invert-match
Selected lines are those not matching any of the specified
patterns.
--view[=COMMAND]
Use COMMAND to view/edit a file in -Q query TUI by pressing
CTRL-Y.
-W, --with-hex
Output binary matches in hexadecimal, leaving text matches alone.
This option is equivalent to the --binary-files=with-hex option.
To omit the matching line from the hex output, use both options -W
and --hexdump. See also options -U.
-w, --word-regexp
The PATTERN is searched for as a word, such that the matching text
is preceded by a non-word character and is followed by a non-word
character. Word-like characters are Unicode letters, digits and
connector punctuations such as underscore.
--width[=NUM]
Truncate the output to NUM visible characters per line. The width
of the terminal window is used if NUM is not specified. Note that
double-width characters in the output may result in wider lines.
-X, --hex
Output matches and matching lines in hexadecimal. This option is
equivalent to the --binary-files=hex option. To omit the matching
line from the hex output use option --hexdump. See also option
-U.
-x, --line-regexp
Select only those matches that exactly match the whole line, as if
the patterns are surrounded by ^ and $.
--xml Output file matches in XML. When -H, -n, -k, or -b is specified,
additional values are output. See also options --format and -u.
-Y, --empty
Empty-matching patterns match all lines. Normally, empty matches
are not output, unless a pattern starts with `^' or ends with `$'.
With this option, empty-matching patterns, such as x*y?, x*y*z*,
and x*(y?|z) match all lines, not only the expected pattern. This
option is enabled by default in grep compatibility mode; specify
option --no-empty to prevent matching all lines.
-y, --any-line, --passthru
Any line is output (passthru). Non-matching lines are output as
context with a `-' separator. See also options -A, -B and -C.
-Z[best][+-~][MAX], --fuzzy[=[best][+-~][MAX]]
Fuzzy mode: report approximate pattern matches within MAX errors.
The default is -Z1: one deletion, insertion or substitution is
allowed. If `+`, `-' and/or `~' is specified, then `+' allows
insertions, `-' allows deletions and `~' allows substitutions.
For example, -Z+~3 allows up to three insertions or substitutions,
but no deletions. If `best' is specified, then only the best
matching lines are output with the lowest cost per file. Option
-Zbest requires two passes over a file and cannot be used with
standard input or Boolean queries. Option --sort=best orders
matching files by best match. The first character of an
approximate match always matches a character at the beginning of
the pattern. To fuzzy match the first character, replace it with
a `.' or `.?'. Option -U applies fuzzy matching to ASCII and
bytes instead of Unicode text. No whitespace may be given between
-Z and its argument.
-z, --decompress
Search compressed files and archives. Archives (.cpio, .pax,
.tar) and compressed archives (e.g. .zip, .7z, .taz, .tgz, .tpz,
.tbz, .tbz2, .tb2, .tz2, .tlz, .txz, .tzst) are searched and
matching pathnames of files in archives are output in braces.
When used with option --zmax=NUM, searches the contents of
compressed files and archives stored within archives up to NUM
levels. When -g, -O, -M, or -t is specified, searches archives
for files that match the specified globs, filename extensions,
file signature magic bytes, or file types, respectively; a
side-effect of these options is that the compressed files and
archives searched are only those with filename extensions that
match known compression and archive types. Supported compression
formats: gzip (.gz), compress (.Z), zip, 7z, bzip2 (.bz, .bz2,
.bzip2, .tbz, .tbz2, .tb2, .tz2), xz (.xz, .txz) and lzma
(requires suffix .lzma, .tlz), zstd (.zst, .zstd, .tzst), lz4
(requires suffix .lz4), brotli (requires suffix .br).
--zmax=NUM
When used with option -z or --decompress, searches the contents of
compressed files and archives stored within archives by up to NUM
expansion stages. The default --zmax=1 only permits searching
uncompressed files stored in cpio, pax, tar, zip and 7z archives;
compressed files and archives are detected as binary files and are
effectively ignored. Specify --zmax=2 to search compressed files
and archives stored in cpio, pax, tar, zip and 7z archives. NUM
may range from 1 to 99 for up to 99 decompression and de-archiving
steps. Increasing NUM values gradually degrades performance.
EXIT STATUS
The ugrep utility exits with one of the following values:
0 One or more lines were selected.
1 No lines were selected.
>1 An error occurred.
If -q or --quiet or --silent is used and a line is selected, the exit
status is 0 even if an error occurred.
CONFIGURATION
The ug command is intended for interactive searching and is equivalent to
the ugrep --config --pretty --sort command to load the `.ugrep`
configuration file located in the working directory or, when not found,
in the home directory.
A configuration file contains `NAME=VALUE' pairs per line, where `NAME`
is the name of a long option (without `--') and `=VALUE' is an argument,
which is optional and may be omitted depending on the option. Empty
lines and lines starting with a `#' are ignored.
The --config=FILE option and its abbreviated form ---FILE load the
specified configuration file located in the working directory or, when
not found, in the home directory. An error is produced when FILE is not
found or cannot be read.
Command line options are parsed in the following order: the configuration
file is loaded first, followed by the remaining options and arguments on
the command line.
The --save-config option saves a `.ugrep' configuration file to the
working directory with a subset of the options specified on the command
line. Only part of the specified options are saved that do not cause
searches to fail when combined with other options. The --save-
config=FILE option saves the configuration to FILE. The configuration is
written to standard output when FILE is a `-'.
GLOBBING
Globbing is used by options -g (--glob and --iglob), --include,
--include-dir, --include-from, --exclude, --exclude-dir, --exclude-from
and --ignore-files to match pathnames or basenames in recursive searches.
Glob arguments for these options should be quoted to prevent shell
globbing.
Globbing supports gitignore syntax and the corresponding matching rules,
except that a glob normally matches files but not directories. If a glob
ends in a path separator `/', then it matches directories but not files,
as if --include-dir or --exclude-dir is specified. When a glob contains
a path separator `/', the full pathname is matched. Otherwise the
basename of a file or directory is matched. For example, *.h matches
foo.h and bar/foo.h. bar/*.h matches bar/foo.h but not foo.h and not
bar/bar/foo.h. Use a leading `./' or just `/' to force /*.h to match
foo.h in the working directory but not bar/foo.h.
When a glob starts with a `^' or a `!' as in -g^GLOB, the match is
negated. Likewise, a `!' (but not a `^') may be used with globs in the
files specified --include-from, --exclude-from, and --ignore-files to
negate the glob match. Empty lines or lines starting with a `#' are
ignored.
Glob Syntax and Conventions
* Matches anything except /.
? Matches any one character except /.
[abc-e]
Matches one character a,b,c,d,e.
[^abc-e]
Matches one character not a,b,c,d,e,/.
[!abc-e]
Matches one character not a,b,c,d,e,/.
/ When used at the start of a glob, matches the working directory.
When used at the end of a glob, matches directories only.
**/ Matches zero or more directories.
/** When used at the end of a glob, matches everything after the /.
\? Matches a ? or any other character specified after the backslash.
Glob Matching Examples
* Matches a, b, x/a, x/y/b
a Matches a, x/a, x/y/a, but not b, x/b, a/a/b
/* Matches a, b, but not x/a, x/b, x/y/a
/a Matches a, but not x/a, x/y/a
a?b Matches axb, ayb, but not a, b, ab, a/b
a[xy]b Matches axb, ayb but not a, b, azb
a[a-z]b
Matches aab, abb, acb, azb, but not a, b, a3b, aAb, aZb
a[^xy]b
Matches aab, abb, acb, azb, but not a, b, axb, ayb
a[^a-z]b
Matches a3b, aAb, aZb but not a, b, aab, abb, acb, azb
a/*/b Matches a/x/b, a/y/b, but not a/b, a/x/y/b
**/a Matches a, x/a, x/y/a, but not b, x/b.
a/**/b Matches a/b, a/x/b, a/x/y/b, but not x/a/b, a/b/x
a/** Matches a/x, a/y, a/x/y, but not a, b/x
a\?b Matches a?b, but not a, b, ab, axb, a/b
Note that exclude glob patterns take priority over include glob patterns
when specified with options -g, --exclude, --exclude-dir, --include and
include-dir.
Glob patterns specified with prefix `!' in any of the files associated
with --include-from, --exclude-from and --ignore-files will negate a
previous glob match. That is, any matching file or directory excluded by
a previous glob pattern specified in the files associated with --exclude-
from or --ignore-file will become included again. Likewise, any matching
file or directory included by a previous glob pattern specified in the
files associated with --include-from will become excluded again.
ENVIRONMENT
GREP_PATH
May be used to specify a file path to pattern files. The file
path is used by option -f to open a pattern file, when the pattern
file does not exist. Defaults to /usr/local/share/ugrep/patterns
when GREP_PATH is undefined.
GREP_COLOR
May be used to specify ANSI SGR parameters to highlight matches
when option --color is used, e.g. 1;35;40 shows pattern matches in
bold magenta text on a black background. Deprecated in favor of
GREP_COLORS, but still supported.
GREP_COLORS
May be used to specify ANSI SGR parameters to highlight matches
and other attributes when option --color is used. Its value is a
colon-separated list of ANSI SGR parameters that defaults to
cx=33:mt=1;31:fn=1;35:ln=1;32:cn=1;32:bn=1;32:se=36 with
additional parameters for TUI colors
:qp=1;32:qe=1;37;41:qm=1;32:ql=36:qb=1;35. The mt=, ms=, and mc=
capabilities of GREP_COLORS take priority over GREP_COLOR. Option
--colors takes priority over GREP_COLORS.
GREP_COLORS
Colors are specified as string of colon-separated ANSI SGR parameters of
the form `what=substring', where `substring' is a semicolon-separated
list of ANSI SGR codes or `k' (black), `r' (red), `g' (green), `y'
(yellow), `b' (blue), `m' (magenta), `c' (cyan), `w' (white). Upper case
specifies background colors. A `+' qualifies a color as bright. A
foreground and a background color may be combined with one or more font
properties `n' (normal), `f' (faint), `h' (highlight), `i' (invert), `u'
(underline). Substrings may be specified for:
sl= selected lines.
cx= context lines.
rv swaps the sl= and cx= capabilities when -v is specified.
mt= matching text in any matching line.
ms= matching text in a selected line. The substring mt= by default.
mc= matching text in a context line. The substring mt= by default.
fn= filenames.
ln= line numbers.
cn= column numbers.
bn= byte offsets.
se= separators.
rv a Boolean parameter, switches sl= and cx= with option -v.
hl a Boolean parameter, enables filename hyperlinks (\33]8;;link).
ne a Boolean parameter, disables ``erase in line'' \33[K.
qp= TUI prompt.
qe= TUI errors.
qr= TUI regex.
qm= TUI regex meta characters.
ql= TUI regex lists and literals.
qb= TUI regex braces.
FORMAT
Option --format=FORMAT specifies an output format for matches. Option
--replace=FORMAT only replaces the matching patterns. Fields may be used
in FORMAT, which expand into the following values:
%[TEXT]F
if option -H is used: TEXT, the file pathname and separator.
%f the file pathname.
%a the file basename without directory path.
%p the directory path to the file.
%z the file pathname in a (compressed) archive.
%[TEXT]H
if option -H is used: TEXT, the quoted pathname and separator, \"
and \\ replace " and \.
%h the quoted file pathname, \" and \\ replace " and \.
%[TEXT]I
if option -H is used: TEXT, the pathname as XML character data and
separator.
%i the file pathname as XML character data.
%[TEXT]N
if option -n is used: TEXT, the line number and separator.
%n the line number of the match.
%[TEXT]K
if option -k is used: TEXT, the column number and separator.
%k the column number of the match.
%[TEXT]B
if option -b is used: TEXT, the byte offset and separator.
%b the byte offset of the match.
%[TEXT]T
if option -T is used: TEXT and a tab character.
%t a tab character.
%[SEP]$
set field separator to SEP for the rest of the format fields.
%[TEXT]<
if the first match: TEXT.
%[TEXT]>
if not the first match: TEXT.
%, if not the first match: a comma, same as %[,]>.
%: if not the first match: a colon, same as %[:]>.
%; if not the first match: a semicolon, same as %[;]>.
%| if not the first match: a vertical bar, same as %[|]>.
%[TEXT]S
if not the first match: TEXT and separator, see also %[SEP]$.
%s the separator, see also %[TEXT]S and %[SEP]$.
%~ a newline character.
%M the number of matching lines
%m the number of matches
%O the matching line is output as a raw string of bytes.
%o the match is output as a raw string of bytes.
%Q the matching line as a quoted string, \" and \\ replace " and \.
%q the match as a quoted string, \" and \\ replace " and \.
%C the matching line formatted as a quoted C/C++ string.
%c the match formatted as a quoted C/C++ string.
%J the matching line formatted as a quoted JSON string.
%j the match formatted as a quoted JSON string.
%V the matching line formatted as a quoted CSV string.
%v the match formatted as a quoted CSV string.
%X the matching line formatted as XML character data.
%x the match formatted as XML character data.
%w the width of the match, counting wide characters.
%d the size of the match, counting bytes.
%e the ending byte offset of the match.
%Z the edit distance cost of an approximate match with option -Z
%u select unique lines only, unless option -u is used.
%1 the first regex group capture of the match, and so on up to group
%9, same as %[1]#; requires option -P.
%[NUM]#
the regex group capture NUM; requires option -P.
%[NUM]b
the byte offset of the group capture NUM; requires option -P. Use
e for the ending byte offset and d for the byte length.
%[NUM1|NUM2|...]#
the first group capture NUM that matched; requires option -P.
%[NUM1|NUM2|...]b
the byte offset of the first group capture NUM that matched;
requires option -P. Use e for the ending byte offset and d for
the byte length.
%[NAME]#
the NAMEd group capture; requires option -P and capturing pattern
`(?<NAME>PATTERN)', see also %G.
%[NAME]b
the byte offset of the NAMEd group capture; requires option -P and
capturing pattern `(?<NAME>PATTERN)'. Use e for the ending byte
offset and d for the byte length.
%[NAME1|NAME2|...]#
the first NAMEd group capture that matched; requires option -P and
capturing pattern `(?<NAME>PATTERN)', see also %G.
%[NAME1|NAME2|...]b
the byte offset of the first NAMEd group capture that matched;
requires option -P and capturing pattern `(?<NAME>PATTERN)'. Use
e for the ending byte offset and d for the byte length.
%G list of group capture indices/names that matched; requires option
-P.
%[TEXT1|TEXT2|...]G
list of TEXT indexed by group capture indices that matched;
requires option -P.
%g the group capture index/name matched or 1; requires option -P.
%[TEXT1|TEXT2|...]g
the first TEXT indexed by the first group capture index that
matched; requires option -P.
%% the percentage sign.
Formatted output is written without a terminating newline, unless %~ or
`\n' is explicitly specified in the format string.
The [TEXT] part of a field is optional and may be omitted. When present,
the argument must be placed in [] brackets, for example %[,]F to output a
comma, the pathname, and a separator.
%[SEP]$ and %u are switches and do not send anything to the output.
The separator used by the %F, %H, %I, %N, %K, %B, %S and %G fields may be
changed by preceding the field by %[SEP]$. When [SEP] is not provided,
this reverts the separator to the default separator or the separator
specified with --separator.
Formatted output is written for each matching pattern, which means that a
line may be output multiple times when patterns match more than once on
the same line. If field %u is specified anywhere in a format string,
matching lines are output only once, unless option -u, --ungroup is
specified or when more than one line of input matched the search pattern.
Additional formatting options:
--format-begin=FORMAT
the FORMAT when beginning the search.
--format-open=FORMAT
the FORMAT when opening a file and a match was found.
--format-close=FORMAT
the FORMAT when closing a file and a match was found.
--format-end=FORMAT
the FORMAT when ending the search.
The context options -A, -B, -C, -y, and display options --break,
--heading, --color, -T, and --null have no effect on formatted output.
EXAMPLES
Display lines containing the word `patricia' in `myfile.txt':
$ ugrep -w patricia myfile.txt
Display lines containing the word `patricia', ignoring case:
$ ugrep -wi patricia myfile.txt
Display lines approximately matching the word `patricia', ignoring case
and allowing up to 2 spelling errors using fuzzy search:
$ ugrep -Z2 -wi patricia myfile.txt
Count the number of lines containing `patricia', ignoring case:
$ ugrep -cwi patricia myfile.txt
Count the number of words `patricia', ignoring case:
$ ugrep -cowi patricia myfile.txt
List lines with `amount' and a decimal, ignoring case (space is AND):
$ ugrep -i -% 'amount \d+(\.\d+)?' myfile.txt
The same Boolean search query, but with options -e and --and:
$ ugrep -wi -e amount --and '\d+(\.\d+)?' myfile.txt
List all Unicode words in a file:
$ ugrep -o '\w+' myfile.txt
List the laughing face emojis (Unicode code points U+1F600 to U+1F60F):
$ ugrep -o '[\x{1F600}-\x{1F60F}]' myfile.txt
Check if a file contains any non-ASCII (i.e. Unicode) characters:
$ ugrep -q '[^[:ascii:]]' myfile.txt && echo "contains Unicode"
Display the line and column number of `FIXME' in C++ files using
recursive search, with one line of context before and after a matched
line:
$ ugrep -C1 -R -n -k -tc++ FIXME
Display the line and column number of `FIXME' in long Javascript files
using recursive search, showing only matches with up to 10 characters of
context before and after:
$ ugrep -o -C20 -R -n -k -tjs FIXME
Find blocks of text between lines matching BEGIN and END by using a lazy
quantifier `*?' to match only what is necessary and pattern `\n' to match
newlines:
$ ugrep -n 'BEGIN.*\n(.*\n)*?.*END' myfile.txt
Likewise, list the C/C++ comments in a file and line numbers:
$ ugrep -n -e '//.*' -e '/\*(.*\n)*?.*\*+\/' myfile.cpp
The same, but using predefined pattern c++/comments:
$ ugrep -n -f c++/comments myfile.cpp
List the lines that need fixing in a C/C++ source file by looking for the
word `FIXME' while skipping any `FIXME' in quoted strings:
$ ugrep -e FIXME -N '"(\\.|\\\r?\n|[^\\\n"])*"' myfile.cpp
The same, but using predefined pattern cpp/zap_strings:
$ ugrep -e FIXME -f cpp/zap_strings myfile.cpp
Find lines with `FIXME' or `TODO', showing line numbers:
$ ugrep -n -e FIXME -e TODO myfile.cpp
Find lines with `FIXME' that also contain `urgent':
$ ugrep -n -e FIXME --and urgent myfile.cpp
The same, but with a Boolean query pattern (a space is AND):
$ ugrep -n -% 'FIXME urgent' myfile.cpp
Find lines with `FIXME' that do not also contain `later':
$ ugrep -n -e FIXME --andnot later myfile.cpp
The same, but with a Boolean query pattern (a space is AND, - is NOT):
$ ugrep -n -% 'FIXME -later' myfile.cpp
Output a list of line numbers of lines with `FIXME' but not `later':
$ ugrep -e FIXME --andnot later --format='%,%n' myfile.cpp
Recursively list all files with both `FIXME' and `LICENSE' anywhere in
the file, not necessarily on the same line:
$ ugrep -l -%% 'FIXME LICENSE'
Find lines with `FIXME' in the C/C++ files stored in a tarball:
$ ugrep -z -tc++ -n FIXME project.tgz
Recursively find lines with `FIXME' in C/C++ files, but do not search any
`bak' and `old' directories:
$ ugrep -n FIXME -tc++ -g^bak/,^old/
Recursively search for the word `copyright' in cpio, jar, pax, tar, zip,
7z archives, compressed and regular files, and in PDFs using a PDF
filter:
$ ugrep -z -w --filter='pdf:pdftotext % -' copyright
Match the binary pattern `A3hhhhA3' (hex) in a binary file without
Unicode pattern matching -U (which would otherwise match `\xaf' as a
Unicode character U+00A3 with UTF-8 byte sequence C2 A3) and display the
results in hex with --hexdump with C1 to output one hex line before and
after each match:
$ ugrep -U --hexdump=C1 '\xa3[\x00-\xff]{2}\xa3' a.out
Hexdump an entire file using a pager for viewing:
$ ugrep -X --pager '' a.out
List all files that are not ignored by one or more `.gitignore':
$ ugrep -l '' --ignore-files
List all files containing a RPM signature, located in the `rpm' directory
and recursively below up to two levels deeper (3 levels total):
$ ugrep -3 -l -tRpm '' rpm/
Monitor the system log for bug reports and ungroup multiple matches from
matching lines into separate lines:
$ tail -f /var/log/system.log | ugrep -u -i -w bug
Interactive fuzzy search with Boolean search queries:
$ ugrep -Q -l -% -Z2 --sort=best
Display all words in a MacRoman-encoded file that has CR newlines:
$ ugrep --encoding=MACROMAN '\w+' mac.txt
Display options related to "fuzzy" searching:
$ ugrep --help fuzzy
COPYRIGHT
Copyright (c) 2021-2025 Robert A. van Engelen <engelen@acm.org>
ugrep is released under the BSD-3 license. All parts of the software
have reasonable copyright terms permitting free redistribution. This
includes the ability to reuse all or parts of the ugrep source tree.
SEE ALSO
ugrep-indexer(1), grep(1), zgrep(1).
BUGS
Report bugs at: <https://github.com/Genivia/ugrep/issues>
ugrep 7.5.0 June 18, 2025 UGREP(1)
ð Back to table of contents
Regex patterns
For PCRE regex patterns with option -P, please see the PCRE documentation
https://www.pcre.org/original/doc/html/pcrepattern.html. The pattern syntax
has more features than the pattern syntax described below. For the patterns in
common the syntax and meaning are the same.
Note that [[:space:]] and \s and inverted bracket lists [^...] are
modified in ugrep to prevent matching newlines \n. This modification is
done to replicate the behavior of grep.
POSIX regular expression syntax
An empty pattern is a special case that matches everything except empty files, i.e. does not match zero-length files, as per POSIX.1 grep standard.
A regex pattern is an extended set of regular expressions (ERE), with nested
sub-expression patterns Ï and Ï:
| Pattern | Matches |
|---|---|
x | matches the character x, where x is not a special character |
. | matches any single character except newline (unless in dotall mode) |
\. | matches . (dot), special characters are escaped with a backslash |
\n | matches a newline, others are \a (BEL), \b (BS), \t (HT), \v (VT), \f (FF), and \r (CR) |
\0 | matches the NUL character |
\cX | matches the control character X mod 32 (e.g. \cA is \x01) |
\0141 | matches an 8-bit character with octal value 141, i.e. a |
\x7f | matches an 8-bit character with hexadecimal value 7f |
\x{3B1} | matches Unicode character U+03B1, i.e. α |
\u{3B1} | matches Unicode character U+03B1, i.e. α |
\o{141} | matches Unicode character U+0061, i.e. a, in octal |
\p{C} | matches a character in Unicode category C |
\Q...\E | matches the quoted content between \Q and \E literally |
[abc] | matches one of a, b, or c |
[0-9] | matches a digit 0 to 9 |
[^0-9] | matches any character except a digit and excluding \n |
Ï? | matches Ï zero or one time (optional) |
Ï* | matches Ï zero or more times (repetition) |
Ï+ | matches Ï one or more times (repetition) |
Ï{2,5} | matches Ï two to five times (repetition) |
Ï{2,} | matches Ï at least two times (repetition) |
Ï{2} | matches Ï exactly two times (repetition) |
Ï?? | matches Ï zero or once as needed (lazy optional) |
Ï*? | matches Ï a minimum number of times as needed (lazy repetition) |
Ï+? | matches Ï a minimum number of times at least once as needed (lazy repetition) |
Ï{2,5}? | matches Ï two to five times as needed (lazy repetition) |
Ï{2,}? | matches Ï at least two times or more as needed (lazy repetition) |
ÏÏ | matches Ï then matches Ï (concatenation) |
Ïâ®Ï | matches Ï or matches Ï (alternation) |
(Ï) | matches Ï as a group |
(?:Ï) | matches Ï as a group without capture |
(?=Ï) | matches Ï without consuming it, i.e. lookahead (without option -P: nothing may occur after (?=Ï)) |
(?^Ï) | matches Ï and ignores it, marking everything in the pattern as a non-match |
^Ï | matches Ï at the start of input or start of a line (nothing may occur before ^) |
Ï$ | matches Ï at the end of input or end of a line (nothing may occur after $) |
\AÏ | matches Ï at the start of input (nothing may occur before \A) |
Ï\z | matches Ï at the end of input (nothing may occur after \z) |
\bÏ | matches Ï starting at a word boundary (without option -P: nothing may occur before \b) |
Ï\b | matches Ï ending at a word boundary (without option -P: nothing may occur after \b) |
\BÏ | matches Ï starting at a non-word boundary (without option -P: nothing may occur before \B) |
Ï\B | matches Ï ending at a non-word boundary (without option -P: nothing may occur after \B) |
\<Ï | matches Ï that starts a word (without option -P: nothing may occur before \<) |
\>Ï | matches Ï that starts a non-word (without option -P: nothing may occur before \>) |
Ï\< | matches Ï that ends a non-word (without option -P: nothing may occur after \<) |
Ï\> | matches Ï that ends a word (without option -P: nothing may occur after \>) |
(?i:Ï) | matches Ï ignoring case |
(?s:Ï) | . (dot) in Ï matches newline |
(?x:Ï) | ignore all whitespace and comments in Ï |
(?#:X) | all of X is skipped as a comment |
The order of precedence for composing larger patterns from sub-patterns is as follows, from high to low precedence:
- Characters, character classes (bracket expressions), escapes, quotation
- Grouping
(Ï),(?:Ï),(?=Ï), and inline modifiers(?imsux:Ï) - Quantifiers
?,*,+,{n,m} - Concatenation
ÏÏ - Anchoring
^,$,\<,\>,\b,\B,\A,\z - Alternation
Ï|Ï - Global modifiers
(?imsux)Ï
ð Back to table of contents
POSIX and Unicode character classes
Character classes in bracket lists represent sets of characters. Sets can be
negated (inverted), subtracted, intersected, and merged (not supported by PCRE2
with option -P):
| Pattern | Matches |
|---|---|
[a-zA-Z] | matches a letter |
[^a-zA-Z] | matches a non-letter (character class negation), newlines are not matched |
[a-zââ[aeiou]] | matches a consonant (character class subtraction) |
[a-z&&[^aeiou]] | matches a consonant (character class intersection) |
[a-zâ®â®[A-Z]] | matches a letter (character class union) |
Bracket lists cannot be empty, so [] and [^] are invalid. In fact, the
first character after the bracket is always part of the list. So [][] is a
list that matches a ] and a [, [^][] is a list that matches anything but
] and [, and [-^] is a list that matches a - and a ^.
Negated character classes such as [^a-z] do not match newlines for
compatibility with traditional grep pattern matching.
ð Back to table of contents
POSIX and Unicode character categories
The POSIX form can only be used in bracket lists, for example
[[:lower:][:digit:]] matches an ASCII lower case letter or a digit.
You can also use the \p{C} form for class C and upper case \P{C} form
that has the same meaning as \p{^C}, which matches any character except
characters in the class C. For example, \P{ASCII} is the same as
\p{^ASCII} which is the same as [[:^ascii]].
| POSIX form | Matches |
|---|---|
[:ascii:] | matches an ASCII character U+0000 to U+007F including \n |
[:space:] | matches a white space character [ \t\v\f\r] excluding \n |
[:xdigit:] | matches a hex digit [0-9A-Fa-f] |
[:cntrl:] | matches a control character [\x00-\t\x0b-\x1f\x7f] excluding \n |
[:print:] | matches a printable character [\x20-\x7e] |
[:alnum:] | matches a alphanumeric character [0-9A-Za-z] |
[:alpha:] | matches a letter [A-Za-z] |
[:blank:] | matches a blank character \h same as [ \t] |
[:digit:] | matches a digit [0-9] |
[:graph:] | matches a visible character [\x21-\x7e] |
[:lower:] | matches a lower case letter [a-z] |
[:punct:] | matches a punctuation character [\x21-\x2f\x3a-\x40\x5b-\x60\x7b-\x7e] |
[:upper:] | matches an upper case letter [A-Z] |
[:word:] | matches a word character [0-9A-Za-z_] |
[:^blank:] | matches a non-blank characater \H same as [^ \t] |
[:^digit:] | matches a non-digit [^0-9] |
POSIX character categories only cover ASCII, [[:^ascii]] is empty and
therefore invalid to use. By contrast, [^[:ascii]] is a Unicode character
class that excludes the ASCII character category.
Note that the patterns [[:ascii:]] and negated classes such as [[:^digit:]]
match newlines, which is the official definition of these POSIX categories. By
contrast, GNU/BSD grep never match newlines. As a consequence, more patterns
may match.
Negated character classes of the form [^...] match any Unicode character
except the given characters and does not match newlines either. For example
[^[:digit:]] matches non-digits (including Unicode) and does not match
newlines. By contrast, [[:^digit:]] matches ASCII non-digits, including
newlines.
Option -U disables Unicode wide-character matching, i.e. ASCII matching.
| Unicode category | Matches |
|---|---|
. | matches any single Unicode character except newline \n unless with --dotall |
\a | matches BEL U+0007 |
\d | matches a digit [0-9] or \p{Nd} |
\D | matches a non-digit including \n |
\e | matches ESC U+001b |
\f | matches FF U+000c |
\h | matches a blank [ \t] |
\H | matches a non-blank [^ \t] including \n |
\l | matches a lower case letter \p{Ll} |
\n | matches LF U+000a |
\N | matches a non-LF character |
\r | matches CR U+000d |
\R | matches a Unicode line break (\r\n, \r, \v, \f, \n, U+0085, U+2028 and U+2029) |
\s | matches a white space character [ \t\v\f\r\x85\p{Z}] excluding \n |
\S | matches a non-white space character and excluding \n |
\t | matches TAB U+0009 |
\u | matches an upper case letter \p{Lu} |
\v | matches VT U+000b or vertical space character with option -P |
\w | matches a word character [0-9A-Za-z_] or [\p{L}\p{Nd}\p{Pc}] |
\W | matches a non-Unicode word character including \n |
\X | matches any ISO-8859-1 or Unicode character including \n |
\p{Space} | matches a white space character [ \t\v\f\r\x85\p{Z}] excluding \n |
\p{Unicode} | matches any Unicode character U+0000 to U+10FFFF minus U+D800 to U+DFFF |
\p{ASCII} | matches an ASCII character U+0000 to U+007F including \n |
\p{Non_ASCII_Unicode} | matches a non-ASCII character U+0080 to U+10FFFF minus U+D800 to U+DFFF |
\p{L&} | matches a character with Unicode property L& (i.e. property Ll, Lu, or Lt) |
\p{Letter},\p{L} | matches a character with Unicode property Letter |
\p{Mark},\p{M} | matches a character with Unicode property Mark |
\p{Separator},\p{Z} | matches a character with Unicode property Separator |
\p{Symbol},\p{S} | matches a character with Unicode property Symbol |
\p{Number},\p{N} | matches a character with Unicode property Number |
\p{Punctuation},\p{P} | matches a character with Unicode property Punctuation |
\p{Other},\p{C} | matches a character with Unicode property Other |
\p{Lowercase_Letter}, \p{Ll} | matches a character with Unicode sub-property Ll |
\p{Uppercase_Letter}, \p{Lu} | matches a character with Unicode sub-property Lu |
\p{Titlecase_Letter}, \p{Lt} | matches a character with Unicode sub-property Lt |
\p{Modifier_Letter}, \p{Lm} | matches a character with Unicode sub-property Lm |
\p{Other_Letter}, \p{Lo} | matches a character with Unicode sub-property Lo |
\p{Non_Spacing_Mark}, \p{Mn} | matches a character with Unicode sub-property Mn |
\p{Spacing_Combining_Mark}, \p{Mc} | matches a character with Unicode sub-property Mc |
\p{Enclosing_Mark}, \p{Me} | matches a character with Unicode sub-property Me |
\p{Space_Separator}, \p{Zs} | matches a character with Unicode sub-property Zs |
\p{Line_Separator}, \p{Zl} | matches a character with Unicode sub-property Zl |
\p{Paragraph_Separator}, \p{Zp} | matches a character with Unicode sub-property Zp |
\p{Math_Symbol}, \p{Sm} | matches a character with Unicode sub-property Sm |
\p{Currency_Symbol}, \p{Sc} | matches a character with Unicode sub-property Sc |
\p{Modifier_Symbol}, \p{Sk} | matches a character with Unicode sub-property Sk |
\p{Other_Symbol}, \p{So} | matches a character with Unicode sub-property So |
\p{Decimal_Digit_Number}, \p{Nd} | matches a character with Unicode sub-property Nd |
\p{Letter_Number}, \p{Nl} | matches a character with Unicode sub-property Nl |
\p{Other_Number}, \p{No} | matches a character with Unicode sub-property No |
\p{Dash_Punctuation}, \p{Pd} | matches a character with Unicode sub-property Pd |
\p{Open_Punctuation}, \p{Ps} | matches a character with Unicode sub-property Ps |
\p{Close_Punctuation}, \p{Pe} | matches a character with Unicode sub-property Pe |
\p{Initial_Punctuation}, \p{Pi} | matches a character with Unicode sub-property Pi |
\p{Final_Punctuation}, \p{Pf} | matches a character with Unicode sub-property Pf |
\p{Connector_Punctuation}, \p{Pc} | matches a character with Unicode sub-property Pc |
\p{Other_Punctuation}, \p{Po} | matches a character with Unicode sub-property Po |
\p{Control}, \p{Cc} | matches a character with Unicode sub-property Cc |
\p{Format}, \p{Cf} | matches a character with Unicode sub-property Cf |
\p{UnicodeIdentifierStart} | matches a character in the Unicode IdentifierStart class |
\p{UnicodeIdentifierPart} | matches a character in the Unicode IdentifierPart class |
\p{IdentifierIgnorable} | matches a character in the IdentifierIgnorable class |
\p{JavaIdentifierStart} | matches a character in the Java IdentifierStart class |
\p{JavaIdentifierPart} | matches a character in the Java IdentifierPart class |
\p{CsIdentifierStart} | matches a character in the C# IdentifierStart class |
\p{CsIdentifierPart} | matches a character in the C# IdentifierPart class |
\p{PythonIdentifierStart} | matches a character in the Python IdentifierStart class |
\p{PythonIdentifierPart} | matches a character in the Python IdentifierPart class |
To specify a Unicode block as a category use \p{IsBlockName} with a Unicode
BlockName.
To specify a Unicode language script, use \p{Language} with a Unicode
Language.
Unicode language script character classes differ from the Unicode blocks that
have a similar name. For example, the \p{Greek} class represents Greek and
Coptic letters and differs from the Unicode block \p{IsGreek} that spans a
specific Unicode block of Greek and Coptic characters only, which also includes
unassigned characters.
ð Back to table of contents
Perl regular expression syntax
For the pattern syntax of ugrep option -P (Perl regular expressions), see
for example Perl regular expression syntax.
However, ugrep enhances the Perl regular expression syntax with all of the
features listed in POSIX regular expression syntax.
ð Back to table of contents
Troubleshooting
If something is not working, then please check the tutorial and the man page. If you can't find it there and it looks like a bug, then report an issue on GitHub. Bug reports are quickly addressed.
Copyright (c) Robert van Engelen, 2025
Top Related Projects
ripgrep recursively searches directories for a regex pattern while respecting your gitignore
A simple, fast and user-friendly alternative to 'find'
:cherry_blossom: A command-line fuzzy finder
A code-searching tool similar to ack, but faster.
A code search tool similar to ack and the_silver_searcher(ag). It supports multi platforms and multi encodings.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot