
Top Related Projects

大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
Quick Overview
The InsaneLife/ChineseNLPCorpus repository is a collection of various Chinese natural language processing (NLP) datasets, including news articles, social media posts, and other textual data. This repository aims to provide a comprehensive resource for researchers and developers working on Chinese NLP tasks.
Pros
- Diverse Datasets: The repository contains a wide range of Chinese NLP datasets, covering different domains and genres, which can be useful for various NLP tasks.
- Open-Source: The datasets are freely available and can be used for research and development purposes, promoting collaboration and advancement in the field.
- Regularly Updated: The repository is actively maintained, and new datasets are added periodically, ensuring the availability of the latest resources.
- Detailed Documentation: The repository provides detailed documentation for each dataset, including descriptions, usage instructions, and licensing information.
Cons
- Uneven Quality: The quality and preprocessing of the datasets may vary, as they are contributed by different sources, which can introduce challenges in consistent usage.
- Limited Metadata: Some datasets may lack detailed metadata or annotations, which can limit their usefulness for specific NLP tasks.
- Language Barrier: The documentation and dataset descriptions are primarily in Chinese, which may pose a challenge for non-Chinese-speaking users.
- Potential Licensing Issues: While the datasets are open-source, users should carefully review the licensing terms for each dataset to ensure compliance.
Getting Started
To use the datasets from the InsaneLife/ChineseNLPCorpus repository, follow these steps:
- Clone the repository to your local machine:
git clone https://github.com/InsaneLife/ChineseNLPCorpus.git
- Navigate to the cloned repository:
cd ChineseNLPCorpus
-
Explore the available datasets in the
datadirectory. Each dataset has its own subdirectory with a README file providing detailed information about the dataset, including its description, format, and usage instructions. -
Depending on the dataset you want to use, follow the specific instructions in the corresponding README file to download, preprocess, and utilize the data for your NLP tasks.
-
If you encounter any issues or have questions, refer to the repository's documentation or create a new issue on the GitHub repository.
Competitor Comparisons
大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
Pros of brightmart/nlp_chinese_corpus
- Larger dataset: brightmart/nlp_chinese_corpus contains a more extensive collection of Chinese natural language processing (NLP) datasets, including news articles, social media posts, and other textual data.
- Diverse data sources: The corpus includes data from various sources, such as news websites, social media platforms, and online forums, providing a more comprehensive representation of Chinese language usage.
- Detailed documentation: The repository provides detailed documentation, including descriptions of the datasets, their sources, and instructions for using the data.
Cons of brightmart/nlp_chinese_corpus
- Potential data quality issues: As the corpus is compiled from various online sources, there may be concerns about the accuracy, reliability, and consistency of the data.
- Limited preprocessing: Compared to InsaneLife/ChineseNLPCorpus, brightmart/nlp_chinese_corpus may have less extensive data preprocessing and cleaning, which could impact the usability of the data for certain NLP tasks.
- Licensing and usage restrictions: The licensing and usage terms for the datasets in brightmart/nlp_chinese_corpus may be less permissive than those in InsaneLife/ChineseNLPCorpus, potentially limiting the flexibility of how the data can be used.
Code Comparison
Here's a brief code comparison between the two repositories:
InsaneLife/ChineseNLPCorpus:
import pandas as pd
# Load the dataset
df = pd.read_csv('path/to/dataset.csv')
# Preprocess the data
df['text'] = df['text'].str.replace('\n', ' ')
df['text'] = df['text'].str.lower()
brightmart/nlp_chinese_corpus:
import os
import json
# Load the dataset
with open('path/to/dataset.json', 'r') as f:
data = json.load(f)
The key differences are that InsaneLife/ChineseNLPCorpus uses a CSV file format and includes some basic data preprocessing, while brightmart/nlp_chinese_corpus uses a JSON file format without any apparent preprocessing steps in the provided code snippet.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
[TOC]
ChineseNlpCorpus
ä¸æèªç¶è¯è¨å¤çæ°æ®éï¼å¹³æ¶ååå®éªçææã欢è¿è¡¥å æ交å并ã
é 读ç解
é 读ç解æ°æ®éæç §æ¹æ³ä¸»è¦æï¼æ½åå¼ãåç±»ï¼è§ç¹æåï¼ãæç §ç¯ç« åå为åç¯ç« ãå¤ç¯ç« ï¼æ¯å¦æçé®é¢çæ¡å¯è½éè¦ä»å¤ä¸ªæç« ä¸æåï¼æ¯ä¸ªæç« å¯è½é½åªæ¯ä¸é¨åï¼é£ä¹å¤ç¯ç« æåå°±ä¼é¢ä¸´æä¹å并ï¼å并çæ¶åæä¹å»æéå¤çï¼ä¿çè¡¥å çã
| å称 | è§æ¨¡ | 说æ | åä½ | 论æ | ä¸è½½ | è¯æµ |
|---|---|---|---|---|---|---|
| DuReader | 30ä¸é®é¢ 140ä¸ææ¡£ 66ä¸çæ¡ | é®çé 读ç解æ°æ®é | ç¾åº¦ | é¾æ¥ | é¾æ¥ | 2018 NLP Challenge on MRC 2019 Language and Intelligence Challenge on MRC |
| $DuReader_{robust}$ | 2.2ä¸é®é¢ | åç¯ç« ãæ½åå¼é 读ç解æ°æ®é | ç¾åº¦ | é¾æ¥ | è¯æµ | |
| CMRC 2018 | 2ä¸é®é¢ | ç¯ç« ç段æ½ååé 读ç解 | å工大讯é£èåå®éªå®¤ | é¾æ¥ | é¾æ¥ | 第äºå±â讯é£æ¯âä¸ææºå¨é 读ç解è¯æµ |
| $DuReader_{yesno}$ | 9ä¸ | è§ç¹åé 读ç解æ°æ®é | ç¾åº¦ | é¾æ¥ | è¯æµ | |
| $DuReader_{checklist}$ | 1ä¸ | æ½åå¼æ°æ®é | ç¾åº¦ | é¾æ¥ |
ä»»å¡å对è¯æ°æ®
Medical DS
å¤æ¦å¤§å¦åå¸çåºäºç¾åº¦ææå»çä¸çå®å¯¹è¯æ°æ®çï¼é¢åä»»å¡å对è¯çä¸æå»çè¯ææ°æ®éã
| å称 | è§æ¨¡ | å建æ¥æ | ä½è | åä½ | 论æ | ä¸è½½ |
|---|---|---|---|---|---|---|
| Medical DS | 710ä¸ªå¯¹è¯ 67ç§çç¶ 4ç§ç¾ç | 2018å¹´ | Liu et al. | å¤æ¦å¤§å¦ | é¾æ¥ | é¾æ¥ |
åè¨æ°æ®é
å å«ç¥è¯å¯¹è¯ãæ¨è对è¯ãç»å对è¯ã详ç»è§å®ç½ åè¨éé¢è¿æå¾å¤æ°æ®éï¼è§:https://www.luge.ai/#/
CATSLU
ä¹åçä¸äºå¯¹è¯æ°æ®ééä¸äºè¯ä¹ç解ï¼èå·¥ä¸ççå®æ åµASRä¹ä¼æé误ï¼å¾å¾è¢«å¿½ç¥ãCATSLUèæ¯ä¸ä¸ªä¸æè¯é³+NLUææ¬ç解ç对è¯æ°æ®éï¼å¯ä»¥ä»è¯é³ä¿¡å·å°ç解端å°ç«¯è¿è¡å®éªï¼ä¾å¦ç´æ¥ä»é³ç´ 建模è¯è¨ç解ï¼èéword or tokenï¼ã
æ°æ®ç»è®¡ï¼
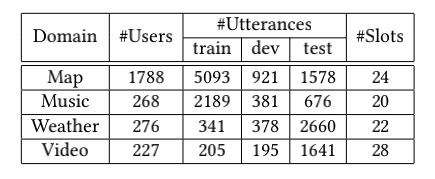
å®æ¹è¯´ææåï¼CATSLU æ°æ®ä¸è½½ï¼https://sites.google.com/view/CATSLU/home
NLPCC2018 Shared Task 4
ä¸æå¢çå®åç¨è½¦è½½è¯é³ä»»å¡å对è¯ç³»ç»ç对è¯æ¥å¿.
| å称 | è§æ¨¡ | å建æ¥æ | ä½è | åä½ | 论æ | ä¸è½½ | è¯æµ |
|---|---|---|---|---|---|---|---|
| NLPCC2018 Shared Task 4 | 5800å¯¹è¯ 2.6ä¸é®é¢ | 2018å¹´ | zhao et al. | è ¾è®¯ | é¾æ¥ | è®ç»å¼åé æµè¯é | NLPCC 2018 Spoken Language Understanding in Task-oriented Dialog Systems |
NLPCCæ¯å¹´é½ä¼ä¸¾åï¼å å«å¤§éä¸ææ°æ®éï¼å¦å¯¹è¯ãqaãnerãæ ææ£æµãæè¦çä»»å¡
SMP
è¿æ¯ä¸ç³»ç±»æ°æ®éï¼æ¯å¹´é½ä¼ææ°çæ°æ®éæ¾åºã
SMP-2020-ECDTå°æ ·æ¬å¯¹è¯è¯è¨ç解æ°æ®é
论æä¸å«FewJoint åºåæ°æ®éï¼æ¥èªäºè®¯é£AIUIå¼æ¾å¹³å°ä¸çå®ç¨æ·è¯æåä¸å®¶æé çè¯æ(æ¯ä¾å¤§æ¦ä¸º3ï¼7)ï¼å å«59个çå®domainï¼ç®ådomainæå¤ç对è¯æ°æ®éä¹ä¸ï¼å¯ä»¥é¿å æé 模ædomainï¼é常éåå°æ ·æ¬åå å¦ä¹ æ¹æ³è¯æµãå ¶ä¸45个è®ç»domainï¼5个å¼ådomainï¼9个æµè¯domainã
æ°æ®éä»ç»ï¼æ°é»é¾æ¥
æ°æ®é论æï¼https://arxiv.org/abs/2009.08138 æ°æ®éä¸è½½å°åï¼https://atmahou.github.io/attachments/FewJoint.zip å°æ ·æ¬å·¥å ·å¹³å°ä¸»é¡µå°åï¼https://github.com/AtmaHou/MetaDialog
SMP-2019-NLU
å å«é¢ååç±»ãæå¾è¯å«åè¯ä¹æ§½å¡«å ä¸é¡¹åä»»å¡çæ°æ®éãè®ç»æ°æ®éä¸è½½ï¼trian.jsonï¼ç®ååªè·åå°è®ç»éï¼å¦ææåå¦ææµè¯éï¼æ¬¢è¿æä¾ã
| Train | |
|---|---|
| Domain | 24 |
| Intent | 29 |
| Slot | 63 |
| Samples | 2579 |
SMP-2017
ä¸æ对è¯æå¾è¯å«æ°æ®éï¼å®æ¹gitåæ°æ®: https://github.com/HITlilingzhi/SMP2017ECDT-DATA
æ°æ®éï¼
| Train | |
|---|---|
| Train samples | 2299 |
| Dev samples | 770 |
| Test samples | 666 |
| Domain | 31 |
论æï¼https://arxiv.org/abs/1709.10217
ææ¬åç±»
æ°é»åç±»
- ä»æ¥å¤´æ¡ä¸ææ°é»ï¼çææ¬ï¼åç±»æ°æ®é ï¼https://github.com/fateleak/toutiao-text-classfication-dataset
- æ°æ®è§æ¨¡ï¼å ±**38ä¸æ¡**ï¼åå¸äº15个åç±»ä¸ã
- ééæ¶é´ï¼2018å¹´05æã
- 以0.7 0.15 0.15ååå² ã
- æ¸
åæ°é»åç±»è¯æï¼
- æ ¹æ®æ°æµªæ°é»RSS订é é¢é2005~2011å¹´é´çåå²æ°æ®çéè¿æ»¤çæã
- æ°æ®éï¼**74ä¸ç¯æ°é»ææ¡£**ï¼2.19 GBï¼
- å°æ°æ®å®éªå¯ä»¥çéç±»å«ï¼ä½è², è´¢ç», æ¿äº§, å®¶å± , æè², ç§æ, æ¶å°, æ¶æ¿, 游æ, 娱ä¹
- http://thuctc.thunlp.org/#%E8%8E%B7%E5%8F%96%E9%93%BE%E6%8E%A5
- rnnåcnnå®éªï¼https://github.com/gaussic/text-classification-cnn-rnn
- ä¸ç§å¤§æ°é»åç±»è¯æåºï¼http://www.nlpir.org/?action-viewnews-itemid-145
æ æ/è§ç¹/è¯è®º å¾åæ§åæ
| æ°æ®é | æ°æ®æ¦è§ | ä¸è½½ |
|---|---|---|
| ChnSentiCorp_htl_all | 7000 å¤æ¡é åºè¯è®ºæ°æ®ï¼5000 å¤æ¡æ£åè¯è®ºï¼2000 å¤æ¡è´åè¯è®º | å°å |
| waimai_10k | æå¤åå¹³å°æ¶éçç¨æ·è¯ä»·ï¼æ£å 4000 æ¡ï¼è´å 约 8000 æ¡ | å°å |
| online_shopping_10_cats | 10 个类å«ï¼å ± 6 ä¸å¤æ¡è¯è®ºæ°æ®ï¼æ£ãè´åè¯è®ºå约 3 ä¸æ¡ï¼ å æ¬ä¹¦ç±ãå¹³æ¿ãææºãæ°´æãæ´åæ°´ãçæ°´å¨ãèçãè¡£æã计ç®æºãé åº | å°å |
| weibo_senti_100k | 10 ä¸å¤æ¡ï¼å¸¦æ ææ 注 æ°æµªå¾®åï¼æ£è´åè¯è®ºçº¦å 5 ä¸æ¡ | å°å |
| simplifyweibo_4_moods | 36 ä¸å¤æ¡ï¼å¸¦æ ææ 注 æ°æµªå¾®åï¼å å« 4 ç§æ æï¼ å ¶ä¸åæ¦çº¦ 20 ä¸æ¡ï¼æ¤æãåæ¶ãä½è½å约 5 ä¸æ¡ | å°å |
| dmsc_v2 | 28 é¨çµå½±ï¼è¶ 70 ä¸ ç¨æ·ï¼è¶ 200 ä¸æ¡ è¯å/è¯è®º æ°æ® | å°å |
| yf_dianping | 24 ä¸å®¶é¤é¦ï¼54 ä¸ç¨æ·ï¼440 ä¸æ¡è¯è®º/è¯åæ°æ® | å°å |
| yf_amazon | 52 ä¸ä»¶ååï¼1100 å¤ä¸ªç±»ç®ï¼142 ä¸ç¨æ·ï¼720 ä¸æ¡è¯è®º/è¯åæ°æ® | å°å |
| ç¾åº¦åè¨æ æåææ°æ®é | å æ¬å¥å级æ æåç±»ï¼Sentence-level Sentiment Classificationï¼ãè¯ä»·å¯¹è±¡çº§æ æåç±»ï¼Aspect-level Sentiment Classificationï¼ãè§ç¹æ½åï¼Opinion Target Extractionï¼ | å°å |
å®ä½è¯å«&è¯æ§æ 注&åè¯
-
å¾®åå®ä½è¯å«.
-
bosonæ°æ®ã
- å å«6ç§å®ä½ç±»åã
- https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/boson
-
人æ°æ¥æ¥æ°æ®éã
- 人åãå°åãç»ç»åä¸ç§å®ä½ç±»å
- 1998ï¼https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/renMinRiBao
- 2004ï¼https://pan.baidu.com/s/1LDwQjoj7qc-HT9qwhJ3rcA password: 1fa3
-
MSRA微软äºæ´²ç 究é¢æ°æ®éã
- 5 ä¸å¤æ¡ä¸æå½åå®ä½è¯å«æ 注æ°æ®ï¼å æ¬å°ç¹ãæºæã人ç©ï¼
- https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/MSRA
-
SIGHAN Bakeoff 2005ï¼ä¸å ±æå个æ°æ®éï¼å å«ç¹ä½ä¸æåç®ä½ä¸æï¼ä¸é¢æ¯ç®ä½ä¸æåè¯æ°æ®ã
å¦å¤è¿ä¸ä¸ªé¾æ¥éé¢æ°æ®éä¹æºå ¨çï¼é¾æ¥ï¼
å¥æ³&è¯ä¹è§£æ
ä¾åå¥æ³
è¯ä¹è§£æ
- çæ¹æ³ä¸»è¦è¿æ¯è½¬å为åç±»ånerä»»å¡ãä¸è½½å°åï¼https://aistudio.baidu.com/aistudio/competition/detail/47/?isFromLUGE=TRUE
| æ°æ®é | å/å¤è¡¨ | è¯è¨ | å¤æ度 | æ°æ®åº/è¡¨æ ¼ | è®ç»é | éªè¯é | æµè¯é | ææ¡£ |
|---|---|---|---|---|---|---|---|---|
| NL2SQL | å | ä¸æ | ç®å | 5,291/5,291 | 41,522 | 4,396 | 8,141 | NL2SQL |
| CSpider | å¤ | ä¸è± | å¤æ | 166/876 | 6,831 | 954 | 1,906 | CSpider |
| DuSQL | å¤ | ä¸æ | å¤æ | 200/813 | 22,521 | 2,482 | 3,759 | DuSQL |
ä¿¡æ¯æ½å
æç´¢å¹é
åè¨ææ¬ç¸ä¼¼åº¦
ç¾åº¦åè¨ææ¬ç¸ä¼¼åº¦ï¼ä¸»è¦å å«LCQMC/BQ Corpus/PAWS-Xï¼è§å®ç½ï¼ä¸°å¯ææ¬å¹é çæ°æ®ï¼å¯ä»¥ä½ä¸ºç®æ å¹é æ°æ®éçæºåæ°æ®ï¼è¿è¡å¤ä»»å¡å¦ä¹ /è¿ç§»å¦ä¹ ã
OPPOææºæç´¢æåº
OPPOææºæç´¢æåºquery-titleè¯ä¹å¹é æ°æ®éã
é¾æ¥: https://pan.baidu.com/s/1KzLK_4Iv0CHOkkut7TJBkA?pwd=ju52 æåç : ju52
ç½é¡µæç´¢ç»æè¯ä»·(SogouE)
-
ç¨æ·æ¥è¯¢åç¸å ³URLå表
æ¨èç³»ç»
| æ°æ®é | æ°æ®æ¦è§ | ä¸è½½å°å |
|---|---|---|
| ez_douban | 5 ä¸å¤é¨çµå½±ï¼3 ä¸å¤æçµå½±å称ï¼2 ä¸å¤æ²¡æçµå½±å称ï¼ï¼2.8 ä¸ ç¨æ·ï¼280 ä¸æ¡è¯åæ°æ® | ç¹å»æ¥ç |
| dmsc_v2 | 28 é¨çµå½±ï¼è¶ 70 ä¸ ç¨æ·ï¼è¶ 200 ä¸æ¡ è¯å/è¯è®º æ°æ® | ç¹å»æ¥ç |
| yf_dianping | 24 ä¸å®¶é¤é¦ï¼54 ä¸ç¨æ·ï¼440 ä¸æ¡è¯è®º/è¯åæ°æ® | ç¹å»æ¥ç |
| yf_amazon | 52 ä¸ä»¶ååï¼1100 å¤ä¸ªç±»ç®ï¼142 ä¸ç¨æ·ï¼720 ä¸æ¡è¯è®º/è¯åæ°æ® | ç¹å»æ¥ç |
ç¾ç§æ°æ®
ç»´åºç¾ç§
ç»´åºç¾ç§ä¼å®æ¶å°è¯æåºæå åå¸ï¼
ç¾åº¦ç¾ç§
åªè½èªå·±ç¬ï¼ç¬åå¾é¾æ¥ï¼https://pan.baidu.com/share/init?surl=i3wvfilæåç neqs ã
æ代æ¶æ§
CoNLL 2012 ï¼http://conll.cemantix.org/2012/data.html
é¢è®ç»ï¼ï¼è¯åéor模åï¼
BERT
- å¼æºä»£ç ï¼https://github.com/google-research/bert
- 模åä¸è½½ï¼BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
BERTåç§æ¨¡åï¼
| 模å | åæ° | git |
|---|---|---|
| Chinese-BERT-base | 108M | BERT |
| Chinese-BERT-wwm-ext | 108M | Chinese-BERT-wwm |
| RBT3 | 38M | Chinese-BERT-wwm |
| ERNIE 1.0 Base ä¸æ | 108M | ERNIEãernie模å转ætensorflow模å:tensorflow_ernie |
| RoBERTa-large | 334M | RoBERT |
| XLNet-mid | 209M | XLNet-mid |
| ALBERT-large | 59M | Chinese-ALBERT |
| ALBERT-xlarge | Chinese-ALBERT | |
| ALBERT-tiny | 4M | Chinese-ALBERT |
| chinese-roberta-wwm-ext | 108M | Chinese-BERT-wwm |
| chinese-roberta-wwm-ext-large | 330M | Chinese-BERT-wwm |
ELMO
- å¼æºä»£ç ï¼https://github.com/allenai/bilm-tf
- é¢è®ç»ç模åï¼https://allennlp.org/elmo
è ¾è®¯è¯åé
è ¾è®¯AIå®éªå®¤å ¬å¼çä¸æè¯åéæ°æ®éå å«800å¤ä¸ä¸æè¯æ±ï¼å ¶ä¸æ¯ä¸ªè¯å¯¹åºä¸ä¸ª200ç»´çåéã
- ä¸è½½å°åï¼~~https://ai.tencent.com/ailab/nlp/embedding.html~~ï¼ç½é¡µå·²ç»å¤±æï¼æç½çé¾æ¥åå¦å¸æå享ä¸
ä¸è½½å°åï¼https://ai.tencent.com/ailab/nlp/en/download.html
ä¸ç¾ç§é¢è®ç»ä¸æè¯åé
https://github.com/Embedding/Chinese-Word-Vectors
ä¸æå®å½¢å¡«ç©ºæ°æ®é
https://github.com/ymcui/Chinese-RC-Dataset
ä¸åå¤è¯è¯æ°æ®åº
æå ¨ä¸åå¤è¯è¯æ°æ®éï¼åå®ä¸¤æè¿ä¸ä¸ååå¤è¯äºº, æ¥è¿5.5ä¸é¦åè¯å 26ä¸å®è¯. 两å®æ¶æ1564ä½è¯äººï¼21050é¦è¯ã
https://github.com/chinese-poetry/chinese-poetry
ä¿é©è¡ä¸è¯æåº
https://github.com/Samurais/insuranceqa-corpus-zh
æ±è¯æååå ¸
è±æå¯ä»¥åchar embeddingï¼ä¸æä¸å¦¨å¯ä»¥è¯è¯æå
https://github.com/kfcd/chaizi
ä¸ææ°æ®éå¹³å°
-
æçå®éªå®¤
æçå®éªå®¤æä¾äºä¸äºé«è´¨éçä¸æææ¬æ°æ®éï¼æ¶é´æ¯è¾æ©ï¼å¤ä¸º2012年以åçæ°æ®ã
-
ä¸ç§å¤§èªç¶è¯è¨å¤çä¸ä¿¡æ¯æ£ç´¢å ±äº«å¹³å°
-
ä¸æè¯æå°æ°æ®
- å å«äºä¸æå½åå®ä½è¯å«ãä¸æå ³ç³»è¯å«ãä¸æé 读ç解çä¸äºå°éæ°æ®ã
- https://github.com/crownpku/Small-Chinese-Corpus
-
ç»´åºç¾ç§æ°æ®é
- https://dumps.wikimedia.org/
- ä¸æç»´åºç¾ç§23ä¸æ¡é«è´¨éè¯æ¡æ°æ®éï¼æ´æ°è³2307ï¼ï¼https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered
NLPå·¥å ·
THULACï¼ https://github.com/thunlp/THULAC ï¼å æ¬ä¸æåè¯ãè¯æ§æ 注åè½ã
HanLPï¼https://github.com/hankcs/HanLP
å工大LTP https://github.com/HIT-SCIR/ltp
NLPIRÂ https://github.com/NLPIR-team/NLPIR
jieba https://github.com/yanyiwu/cppjieba
ç¾åº¦åè¨æ°æ®éï¼https://github.com/luge-ai/luge-ai
Top Related Projects
大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot