 VILA
VILA
VILA is a family of state-of-the-art vision language models (VLMs) for diverse multimodal AI tasks across the edge, data center, and cloud.
Top Related Projects

ImageBind One Embedding Space to Bind Them All

CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation



🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Quick Overview
VILA (Visual Language) is a research project by NVIDIA Labs that focuses on developing advanced visual language models. It aims to improve the understanding and generation of visual content in conjunction with natural language, potentially enhancing various applications in computer vision and natural language processing.
Pros
- Cutting-edge research in visual language models
- Potential for significant improvements in image-text understanding
- Backed by NVIDIA, a leader in GPU technology and AI research
- Could lead to advancements in various fields like image captioning, visual question answering, and multimodal AI
Cons
- Limited public information available about the project
- May require significant computational resources for implementation
- Potential ethical concerns regarding advanced AI models and their applications
- Possible steep learning curve for developers and researchers new to visual language models
Code Examples
As this is a research project without a publicly available code library, there are no specific code examples to provide.
Getting Started
Since VILA is a research project without a public code release, there are no specific getting started instructions available. Interested researchers and developers should monitor the official NVIDIA Labs GitHub repository and research publications for updates on the project and potential future releases.
Competitor Comparisons
ImageBind One Embedding Space to Bind Them All
Pros of ImageBind
- Supports a wider range of modalities (6 in total) including audio, text, and depth
- Provides pre-trained models and extensive documentation for easy use
- Offers a more flexible architecture for cross-modal learning
Cons of ImageBind
- Requires more computational resources due to its larger scale
- May have a steeper learning curve for beginners due to its complexity
- Less focused on specific visual-language tasks compared to VILA
Code Comparison
VILA example:
from vila import VILAModel
model = VILAModel.from_pretrained("vila-base")
outputs = model(images=images, text=text)
ImageBind example:
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
inputs = {
ModalityType.VISION: vision_x,
ModalityType.TEXT: text_x,
ModalityType.AUDIO: audio_x,
}
model = imagebind_model.imagebind_huge(pretrained=True)
embeddings = model(inputs)
Both repositories focus on multimodal learning, but ImageBind offers a broader range of modalities and a more flexible architecture. VILA is more specialized for visual-language tasks, potentially making it easier to use for specific applications. The code examples demonstrate that ImageBind requires more setup but provides greater flexibility in input types.
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
Pros of CLIP
- Broader applicability across various vision-language tasks
- Larger pre-trained model with more extensive dataset
- More extensive documentation and community support
Cons of CLIP
- Higher computational requirements for training and inference
- Less focus on specific video-language tasks
- May require fine-tuning for optimal performance on certain tasks
Code Comparison
CLIP example:
import torch
from PIL import Image
from clip import clip
model, preprocess = clip.load("ViT-B/32", device="cuda")
image = preprocess(Image.open("image.jpg")).unsqueeze(0).to("cuda")
text = clip.tokenize(["a dog", "a cat"]).to("cuda")
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
VILA example:
import torch
from vila import VILA
model = VILA.from_pretrained("vila-base")
video = torch.randn(1, 3, 8, 224, 224) # Example video tensor
text = ["a person dancing", "a car driving"]
with torch.no_grad():
video_features = model.encode_video(video)
text_features = model.encode_text(text)
PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Pros of BLIP
- More versatile, supporting a wider range of vision-language tasks
- Better performance on image-text retrieval and visual question answering
- More active development and community support
Cons of BLIP
- Higher computational requirements for training and inference
- More complex architecture, potentially harder to understand and modify
Code Comparison
BLIP example:
from models.blip import blip_decoder
model = blip_decoder(pretrained='model_base', image_size=384, vit='base')
model.eval()
model.generate(image, sample=False, num_beams=3, max_length=20, min_length=5)
VILA example:
from vila import VILA
model = VILA.from_pretrained("vila-base")
model.eval()
output = model.generate(image, max_length=20)
Both repositories focus on vision-language tasks, but BLIP offers a more comprehensive solution with superior performance across multiple benchmarks. VILA, while simpler, may be easier to integrate into existing projects due to its straightforward architecture. BLIP's code example demonstrates its flexibility in generation parameters, while VILA's example showcases its simplicity of use.
Pros of BioGPT
- Specialized for biomedical text processing and generation
- Larger model with more extensive training on domain-specific data
- Supports a wider range of biomedical NLP tasks
Cons of BioGPT
- More resource-intensive, requiring higher computational power
- Less focus on visual-language tasks compared to VILA
- May have limited performance on general-domain tasks
Code Comparison
VILA example:
from vila import VILAModel
model = VILAModel.from_pretrained("nvlabs/vila-base")
output = model.generate(image, text_prompt)
BioGPT example:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("microsoft/biogpt")
model = AutoModelForCausalLM.from_pretrained("microsoft/biogpt")
output = model.generate(tokenizer.encode(input_text, return_tensors="pt"))
Key Differences
- VILA focuses on visual-language tasks, while BioGPT specializes in biomedical text processing
- VILA integrates image and text inputs, whereas BioGPT primarily works with text
- BioGPT offers more extensive language modeling capabilities for biomedical applications
- VILA provides a more compact model suitable for multimodal tasks with lower computational requirements
Pros of vision_transformer
- More established and widely adopted in the research community
- Extensive documentation and examples for various vision tasks
- Supports a broader range of vision transformer architectures
Cons of vision_transformer
- Less focus on video-language tasks compared to VILA
- May require more computational resources for training and inference
- Limited support for multi-modal learning beyond vision
Code Comparison
VILA example (video-text retrieval):
from vila import VILAModel
model = VILAModel.from_pretrained("vila-base")
video_features = model.encode_video(video_frames)
text_features = model.encode_text(text_input)
similarity = model.compute_similarity(video_features, text_features)
vision_transformer example (image classification):
import tensorflow as tf
from vit_keras import vit
model = vit.vit_b16(
image_size=224,
activation='softmax',
pretrained=True,
include_top=True,
pretrained_top=True
)
predictions = model.predict(images)
VILA focuses on video-language tasks and provides a more streamlined API for multi-modal learning, while vision_transformer offers a broader range of vision transformer implementations for various computer vision tasks. The choice between the two depends on the specific requirements of your project and the type of data you're working with.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of transformers
- Extensive library with support for numerous pre-trained models and architectures
- Large community and frequent updates, ensuring compatibility with latest research
- Comprehensive documentation and examples for various NLP tasks
Cons of transformers
- Can be overwhelming for beginners due to its vast scope and complexity
- May have higher computational requirements for some models
- Less focused on vision-language tasks compared to VILA
Code comparison
VILA example:
from vila import VILAModel
model = VILAModel.from_pretrained("vila-base")
outputs = model(image, text)
transformers example:
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
Summary
transformers is a comprehensive library for various NLP tasks with extensive community support, while VILA focuses specifically on vision-language tasks. transformers offers a wider range of models and applications but may be more complex for beginners. VILA provides a more streamlined approach for vision-language tasks but has a narrower scope. The choice between the two depends on the specific requirements of the project and the user's familiarity with the libraries.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
VILA: Optimized Vision Language Models
![]()
![]()
![]()
arXiv / Demo / Models / Subscribe
ð¡ Introduction
VILA is a family of open VLMs designed to optimize both efficiency and accuracy for efficient video understanding and multi-image understanding.
ð¡ News
- [2025/6] We release PS3 and VILA-HD. PS3 is a vision encoder that scales up vision pre-training to 4K resolution. VILA-HD is VILA with PS3 as the vision encoder and shows superior performance and efficiency in understanding high-resolution detail-rich images.
- [2025/1] As of January 6, 2025 VILA is now part of the new Cosmos Nemotron vision language models.
- [2024/12] We release NVILA (a.k.a VILA2.0) that explores the full stack efficiency of multi-modal design, achieving cheaper training, faster deployment and better performance.
- [2024/12] We release LongVILA that supports long video understanding, with long-context VLM with more than 1M context length and multi-modal sequence parallel system.
- [2024/10] VILA-M3, a SOTA medical VLM finetuned on VILA1.5 is released! VILA-M3 significantly outperforms Llava-Med and on par w/ Med-Gemini and is fully opensourced! code model
- [2024/10] We release VILA-U: a Unified foundation model that integrates Video, Image, Language understanding and generation.
- [2024/07] VILA1.5 also ranks 1st place (OSS model) on MLVU test leaderboard.
- [2024/06] VILA1.5 is now the best open sourced VLM on MMMU leaderboard and Video-MME leaderboard!
- [2024/05] We release VILA-1.5, which offers video understanding capability. VILA-1.5 comes with four model sizes: 3B/8B/13B/40B.
Click to show more news
- [2024/05] We release AWQ-quantized 4bit VILA-1.5 models. VILA-1.5 is efficiently deployable on diverse NVIDIA GPUs (A100, 4090, 4070 Laptop, Orin, Orin Nano) by TinyChat and TensorRT-LLM backends.
- [2024/03] VILA has been accepted by CVPR 2024!
- [2024/02] We release AWQ-quantized 4bit VILA models, deployable on Jetson Orin and laptops through TinyChat and TinyChatEngine.
- [2024/02] VILA is released. We propose interleaved image-text pretraining that enables multi-image VLM. VILA comes with impressive in-context learning capabilities. We open source everything: including training code, evaluation code, datasets, model ckpts.
- [2023/12] Paper is on Arxiv!
Performance
Image Benchmarks
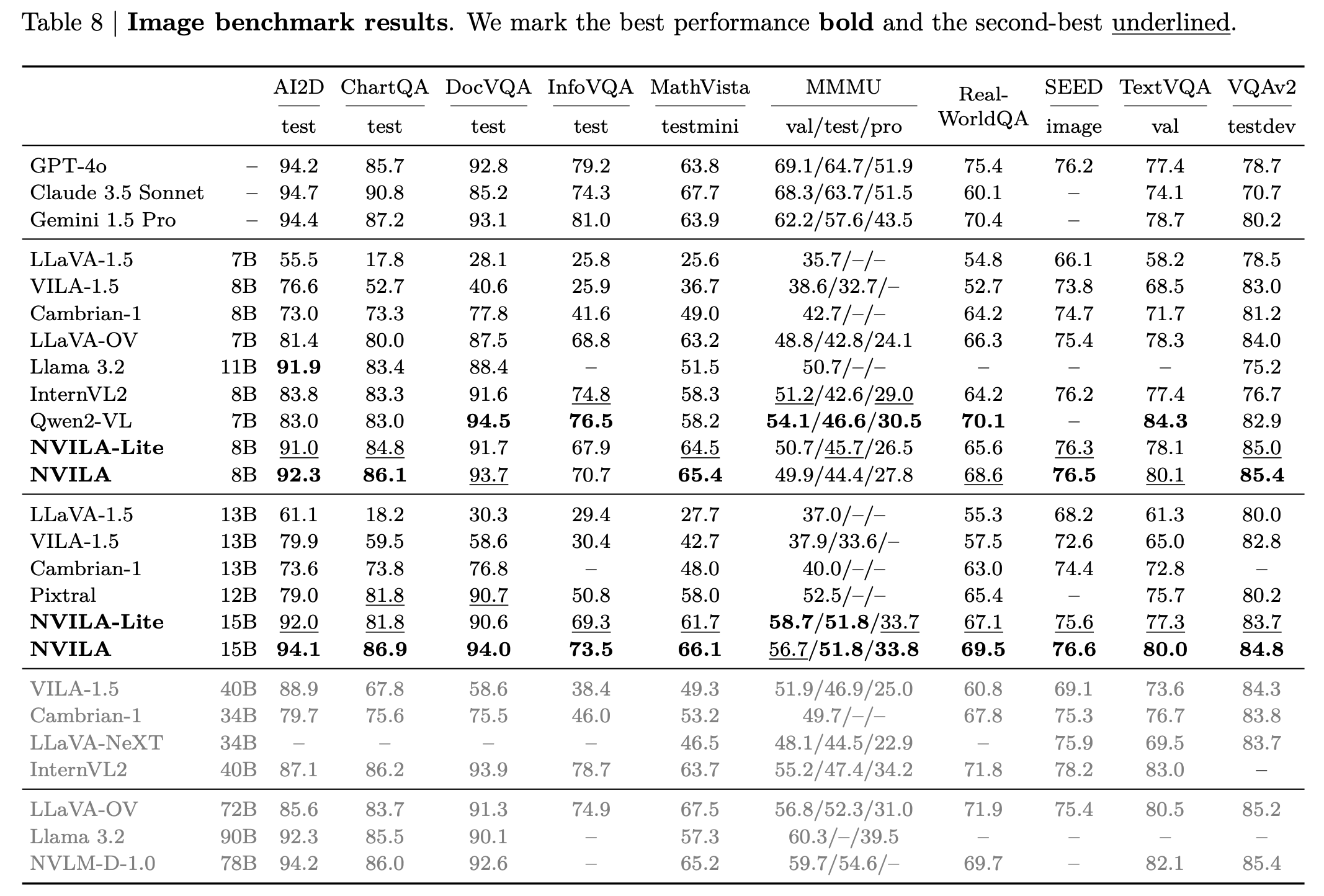
Video Benchmarks
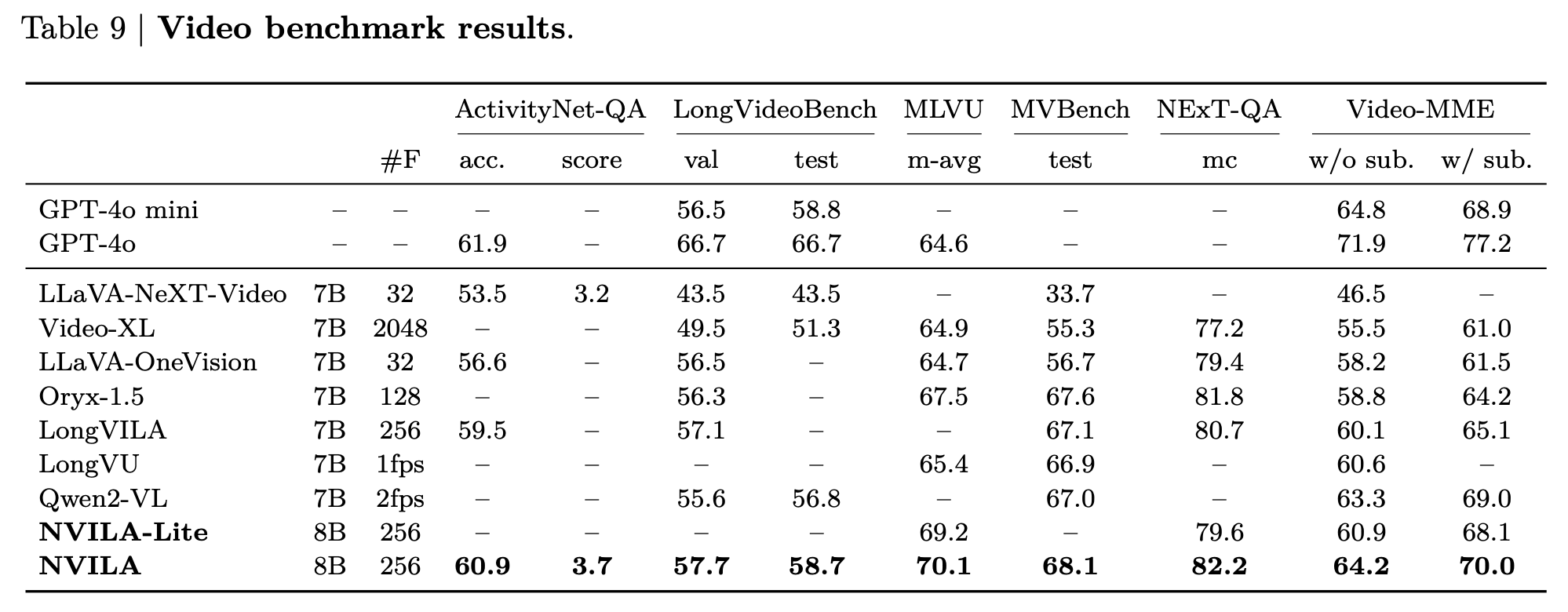
Efficient Deployments
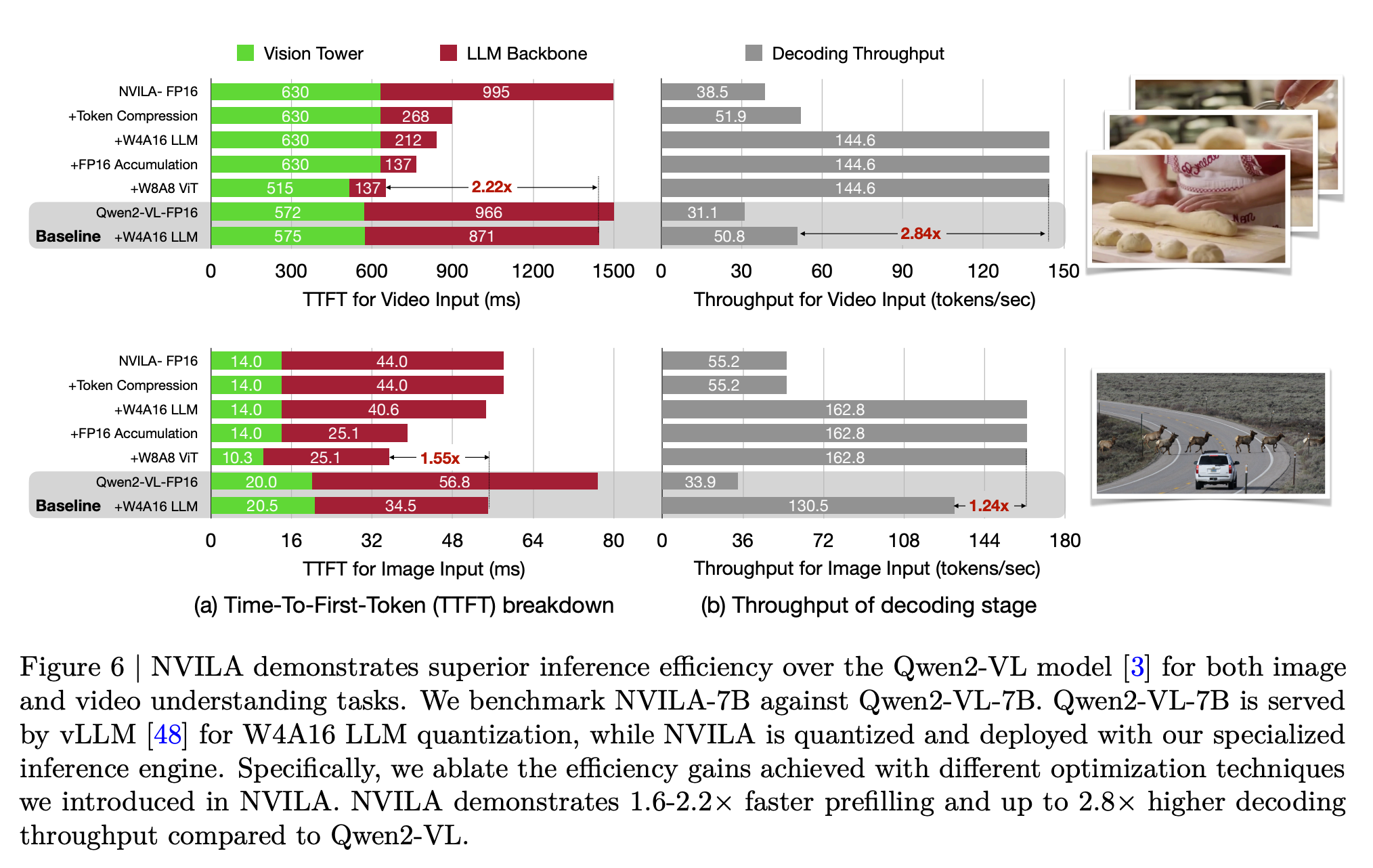
NOTE: Measured using the TinyChat backend at batch size = 1.
Inference Performance
Decoding Throughput ( Token/sec )
| $~~~~~~$ | A100 | 4090 | Orin |
|---|---|---|---|
| NVILA-3B-Baseline | 140.6 | 190.5 | 42.7 |
| NVILA-3B-TinyChat | 184.3 | 230.5 | 45.0 |
| NVILA-Lite-3B-Baseline | 142.3 | 190.0 | 41.3 |
| NVILA-Lite-3B-TinyChat | 186.0 | 233.9 | 44.9 |
| NVILA-8B-Baseline | 82.1 | 61.9 | 11.6 |
| NVILA-8B-TinyChat | 186.8 | 162.7 | 28.1 |
| NVILA-Lite-8B-Baseline | 84.0 | 62.0 | 11.6 |
| NVILA-Lite-8B-TinyChat | 181.8 | 167.5 | 32.8 |
| NVILA-Video-8B-Baseline * | 73.2 | 58.4 | 10.9 |
| NVILA-Video-8B-TinyChat * | 151.8 | 145.0 | 32.3 |
TTFT (Time-To-First-Token) ( Sec )
| $~~~~~~$ | A100 | 4090 | Orin |
|---|---|---|---|
| NVILA-3B-Baseline | 0.0329 | 0.0269 | 0.1173 |
| NVILA-3B-TinyChat | 0.0260 | 0.0188 | 0.1359 |
| NVILA-Lite-3B-Baseline | 0.0318 | 0.0274 | 0.1195 |
| NVILA-Lite-3B-TinyChat | 0.0314 | 0.0191 | 0.1241 |
| NVILA-8B-Baseline | 0.0434 | 0.0573 | 0.4222 |
| NVILA-8B-TinyChat | 0.0452 | 0.0356 | 0.2748 |
| NVILA-Lite-8B-Baseline | 0.0446 | 0.0458 | 0.2507 |
| NVILA-Lite-8B-TinyChat | 0.0391 | 0.0297 | 0.2097 |
| NVILA-Video-8B-Baseline * | 0.7190 | 0.8840 | 5.8236 |
| NVILA-Video-8B-TinyChat * | 0.6692 | 0.6815 | 5.8425 |
NOTE: Measured using the TinyChat backend at batch size = 1, dynamic_s2 disabled, and num_video_frames = 64. We use W4A16 LLM and W8A8 Vision Tower for Tinychat and the baseline precision is FP16. *: Measured with video captioning task. Otherwise, measured with image captioning task.
VILA Examples
Video captioning
https://github.com/Efficient-Large-Model/VILA/assets/156256291/c9520943-2478-4f97-bc95-121d625018a6
Prompt: Elaborate on the visual and narrative elements of the video in detail.
Caption: The video shows a person's hands working on a white surface. They are folding a piece of fabric with a checkered pattern in shades of blue and white. The fabric is being folded into a smaller, more compact shape. The person's fingernails are painted red, and they are wearing a black and red garment. There are also a ruler and a pencil on the surface, suggesting that measurements and precision are involved in the process.
In context learning


Multi-image reasoning

VILA on Jetson Orin
https://github.com/Efficient-Large-Model/VILA/assets/7783214/6079374c-0787-4bc4-b9c6-e1524b4c9dc4
VILA on RTX 4090
https://github.com/Efficient-Large-Model/VILA/assets/7783214/80c47742-e873-4080-ad7d-d17c4700539f
Installation
-
Install Anaconda Distribution.
-
Install the necessary Python packages in the environment.
./environment_setup.sh vila -
(Optional) If you are an NVIDIA employee with a wandb account, install onelogger and enable it by setting
training_args.use_one_loggertoTrueinllava/train/args.py.pip install --index-url=https://sc-hw-artf.nvidia.com/artifactory/api/pypi/hwinf-mlwfo-pypi/simple --upgrade one-logger-utils -
Activate a conda environment.
conda activate vila
Training
VILA training contains three steps, for specific hyperparameters, please check out the scripts/NVILA-Lite folder:
Step-1: Alignment
We utilize LLaVA-CC3M-Pretrain-595K dataset to align the textual and visual modalities.
The stage 1 script takes in two parameters and it can run on a single 8xA100 node.
bash scripts/NVILA-Lite/align.sh Efficient-Large-Model/Qwen2-VL-7B-Instruct <alias to data>
and the trained models will be saved to runs/train/nvila-8b-align.
Step-1.5:
bash scripts/NVILA-Lite/stage15.sh runs/train/nvila-8b-align/model <alias to data>
and the trained models will be saved to runs/train/nvila-8b-align-1.5.
Step-2: Pretraining
We use MMC4 and Coyo dataset to train VLM with interleaved image-text pairs.
bash scripts/NVILA-Lite/pretrain.sh runs/train/nvila-8b-align-1.5 <alias to data>
and the trained models will be saved to runs/train/nvila-8b-pretraining.
Step-3: Supervised fine-tuning
This is the last stage of VILA training, in which we tune the model to follow multimodal instructions on a subset of M3IT, FLAN and ShareGPT4V. This stage runs on a 8xA100 node.
bash scripts/NVILA-Lite/sft.sh runs/train/nvila-8b-pretraining <alias to data>
and the trained models will be saved to runs/train/nvila-8b-SFT.
Evaluations
We have introduce vila-eval command to simplify the evaluation. Once the data is prepared, the evaluation can be launched via
MODEL_NAME=NVILA-15B
MODEL_ID=Efficient-Large-Model/$MODEL_NAME
huggingface-cli download $MODEL_ID
vila-eval \
--model-name $MODEL_NAME \
--model-path $MODEL_ID \
--conv-mode auto \
--tags-include local
it will launch all evaluations and return a summarized result.
Inference
We provide vila-infer for quick inference with user prompts and images.
# image description
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the image" \
--media demo_images/demo_img.png
# video description
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4
vila-infer is also compatible with VILA-1.5 models. For example:
vila-infer \
--model-path Efficient-Large-Model/VILA1.5-3b \
--conv-mode vicuna_v1 \
--text "Please describe the image" \
--media demo_images/demo_img.png
vila-infer \
--model-path Efficient-Large-Model/VILA1.5-3b \
--conv-mode vicuna_v1 \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4
Quantization and Deployment
Our VILA models are quantized by AWQ into 4 bits for efficient inference on the edge. We provide a push-the-button script to quantize VILA with AWQ, along with pre-quantized weights so you can try them out directly.
Running VILA on desktop GPUs and edge GPUs
We support AWQ-quantized 4bit VILA on GPU platforms via TinyChat. We provide a tutorial to run the model with TinyChat after quantization. We also provide an instruction to launch a Gradio server (powered by TinyChat and AWQ) to serve 4-bit quantized VILA models.
Running VILA on laptops
We further support our AWQ-quantized 4bit VILA models on various CPU platforms with both x86 and ARM architectures with our TinyChatEngine. We also provide a detailed tutorial to help the users deploy VILA on different CPUs.
Running VILA API server
A simple API server has been provided to serve VILA models. The server is built on top of FastAPI and Huggingface Transformers. The server can be run with the following command:
With CLI
python -W ignore server.py \
--port 8000 \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto
With Docker
docker build -t vila-server:latest .
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v ./hub:/root/.cache/huggingface/hub \
-it --rm -p 8000:8000 \
-e VILA_MODEL_PATH=Efficient-Large-Model/NVILA-15B \
-e VILA_CONV_MODE=auto \
vila-server:latest
Then you can call the endpoint with the OpenAI SDK as follows:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000",
api_key="fake-key",
)
response = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Whatâs in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://blog.logomyway.com/wp-content/uploads/2022/01/NVIDIA-logo.jpg",
# Or you can pass in a base64 encoded image
# "url": "data:image/png;base64,<base64_encoded_image>",
},
},
],
}
],
model="NVILA-15B",
)
print(response.choices[0].message.content)
NOTE: This API server is intended for evaluation purposes only and has not been optimized for production use. SGLang support is coming on the way.
Checkpoints
We release the following models:
- NVILA-8B / NVILA-8B-Lite
- NVILA-15B / NVILA-15B-Lite
VILA-HD
Please refer to vila_hd/
ð License
- The code is released under the Apache 2.0 license as found in the LICENSE file.
- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.
- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:
- Model License of LLaMA. For LLAMA3-VILA checkpoints terms of use, please refer to the LLAMA3 License for additional details.
- Terms of Use of the data generated by OpenAI
- Dataset Licenses for each one used during training.
Team
NVILA Core contributors: Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, Yao Lu
LongVILA contributors: Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, Song Han
VILA-HD contributors: Baifeng Shi, Boyi Li, Han Cai, Yao Lu, Sifei Liu, Marco Pavone, Jan Kautz, Song Han, Trevor Darrell, Pavlo Molchanov, Hongxu Yin
VILA-1.5 contributors
*Yao Lu: Nvidia, *Hongxu Yin: Nvidia, *Ji Lin: OpenAI (work done at Nvidia and MIT), Wei Ping: Nvidia, Pavlo Molchanov: Nvidia, Andrew Tao: Nvidia, Haotian Tang: MIT, Shang Yang: MIT, Ligeng Zhu: Nvidia, MIT, Wei-Chen Wang: MIT, Fuzhao Xue: Nvidia, NUS, Yunhao Fang: Nvidia, UCSD, Yukang Chen: Nvidia, Zhuoyang Zhang: Nvidia, Yue Shen: Nvidia, Wei-Ming Chen: Nvidia, Huizi Mao: Nvidia, Baifeng Shi: Nvidia, UC Berkeley, Jan Kautz: Nvidia, Mohammad Shoeybi: Nvidia, Song Han: Nvidia, MIT
Citations
@misc{liu2024nvila,
title={NVILA: Efficient Frontier Visual Language Models},
author={Zhijian Liu and Ligeng Zhu and Baifeng Shi and Zhuoyang Zhang and Yuming Lou and Shang Yang and Haocheng Xi and Shiyi Cao and Yuxian Gu and Dacheng Li and Xiuyu Li and Yunhao Fang and Yukang Chen and Cheng-Yu Hsieh and De-An Huang and An-Chieh Cheng and Vishwesh Nath and Jinyi Hu and Sifei Liu and Ranjay Krishna and Daguang Xu and Xiaolong Wang and Pavlo Molchanov and Jan Kautz and Hongxu Yin and Song Han and Yao Lu},
year={2024},
eprint={2412.04468},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.04468},
}
@misc{chen2024longvila,
title={LongVILA: Scaling Long-Context Visual Language Models for Long Videos},
author={Yukang Chen and Fuzhao Xue and Dacheng Li and Qinghao Hu and Ligeng Zhu and Xiuyu Li and Yunhao Fang and Haotian Tang and Shang Yang and Zhijian Liu and Ethan He and Hongxu Yin and Pavlo Molchanov and Jan Kautz and Linxi Fan and Yuke Zhu and Yao Lu and Song Han},
year={2024},
eprint={2408.10188},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{shi2025scaling,
title={Scaling Vision Pre-Training to 4K Resolution},
author={Baifeng Shi and Boyi Li and Han Cai and Yao Lu and Sifei Liu and Marco Pavone and Jan Kautz and Song Han and Trevor Darrell and Pavlo Molchanov and Hongxu Yin},
year={2025},
eprint={2503.19903},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.19903},
}
@misc{lin2023vila,
title={VILA: On Pre-training for Visual Language Models},
author={Ji Lin and Hongxu Yin and Wei Ping and Yao Lu and Pavlo Molchanov and Andrew Tao and Huizi Mao and Jan Kautz and Mohammad Shoeybi and Song Han},
year={2023},
eprint={2312.07533},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Acknowledgement
- LLaVA: the codebase we built upon. Thanks for their wonderful work.
- InternVL: for open-sourcing InternViT (used in VILA1.5-40b) and the InternVL-SFT data blend (inspired by LLaVA-1.6) used in all VILA1.5 models.
- Vicuna: the amazing open-sourced large language model!
- Video-ChatGPT: we borrowed video evaluation script from this repository.
- MMC4, COYO-700M, M3IT, OpenORCA/FLAN, ShareGPT4V, WIT, GSM8K-ScRel, VisualGenome, VCR, ScienceQA, Shot2Story, Youcook2, Vatex, ShareGPT-Video for providing datasets used in this research.
Top Related Projects
ImageBind One Embedding Space to Bind Them All
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot