
Top Related Projects

PyTorch3D is FAIR's library of reusable components for deep learning with 3D data

Image-to-Image Translation in PyTorch
Official PyTorch implementation of StyleGAN3

A latent text-to-image diffusion model

CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Quick Overview
The NVlabs/imaginaire repository is a PyTorch-based framework for training and evaluating generative adversarial networks (GANs) and other generative models. It provides a modular and extensible codebase for developing and experimenting with various GAN architectures and applications.
Pros
- Modular and Extensible: The codebase is designed to be modular, allowing users to easily swap out different components (e.g., generators, discriminators, loss functions) and experiment with new architectures.
- Comprehensive Functionality: The framework supports a wide range of GAN-based tasks, including image-to-image translation, text-to-image synthesis, and video generation.
- Efficient Training: The framework utilizes PyTorch's efficient GPU-accelerated computation, enabling fast and scalable training of generative models.
- Active Development and Community: The project is actively maintained by the NVIDIA research team, and it has a growing community of contributors and users.
Cons
- Steep Learning Curve: The framework's modular design and extensive functionality can make it challenging for new users to get started, especially those unfamiliar with PyTorch and GAN architectures.
- Limited Documentation: While the project has some documentation, it may not be comprehensive enough for users to easily navigate the codebase and understand all the available features and configurations.
- Potential Performance Issues: Depending on the complexity of the GAN architecture and the hardware available, training large-scale generative models with the framework may require significant computational resources.
- Limited Support for Non-PyTorch Environments: The framework is primarily designed for PyTorch-based environments, which may limit its usability for users working in other deep learning frameworks.
Code Examples
Here are a few code examples demonstrating the usage of the NVlabs/imaginaire framework:
- Training a GAN for Image-to-Image Translation:
from imaginaire.trainers.image_to_image_translation import ImageToImageTranslationTrainer
trainer = ImageToImageTranslationTrainer(config)
trainer.train()
This code sets up and trains a GAN for image-to-image translation tasks, such as semantic segmentation or style transfer, using the provided configuration.
- Generating Images from Text:
from imaginaire.trainers.text_to_image import TextToImageTrainer
trainer = TextToImageTrainer(config)
generated_images = trainer.generate_images(text_inputs)
This code demonstrates how to use the framework to generate images from text inputs, such as captions or descriptions.
- Evaluating a Trained GAN:
from imaginaire.evaluators.fid import FIDEvaluator
evaluator = FIDEvaluator(config)
fid_score = evaluator.evaluate(real_images, generated_images)
This code shows how to use the framework's evaluation utilities to compute the Fréchet Inception Distance (FID) between real and generated images, which is a common metric for assessing the quality of GAN-generated outputs.
Getting Started
To get started with the NVlabs/imaginaire framework, follow these steps:
- Install the required dependencies: Ensure that you have PyTorch and the necessary Python packages installed. You can install the required dependencies using the provided
requirements.txtfile:
pip install -r requirements.txt
-
Set up the configuration: The framework uses a YAML-based configuration system to define the model architecture, training hyperparameters, and other settings. You can start by modifying one of the example configuration files provided in the
configs/directory. -
Prepare your data: Depending on the task you're working on, you'll need to prepare your dataset and provide the necessary data loaders. The framework provides utilities for common datasets, but you may need to implement custom data loaders for your specific use case.
-
Train your model: Once you have your configuration and data ready, you can start training your GAN model using the provided trainer classes. For example:
from imaginaire.trainers.image_to_image_translation import ImageToImageTranslationTrainer
trainer = ImageToImageTranslationTrainer(config)
trainer.train()
- Evaluate and Visualize:
Competitor Comparisons
PyTorch3D is FAIR's library of reusable components for deep learning with 3D data
Pros of pytorch3d
- Focused on 3D computer vision tasks, offering specialized tools for 3D rendering and manipulation
- Seamless integration with PyTorch, leveraging its ecosystem and GPU acceleration
- Extensive documentation and tutorials for easier adoption
Cons of pytorch3d
- Limited scope compared to imaginaire, which covers a broader range of image and video synthesis tasks
- May require more domain-specific knowledge in 3D graphics and computer vision
- Less emphasis on generative models and image-to-image translation
Code Comparison
imaginaire (image-to-image translation):
from imaginaire.generators import OCONetGenerator
generator = OCONetGenerator(opts)
output = generator(input_image, mask)
pytorch3d (3D mesh rendering):
from pytorch3d.structures import Meshes
from pytorch3d.renderer import Textures, MeshRenderer
meshes = Meshes(verts=vertices, faces=faces)
renderer = MeshRenderer(rasterizer, shader)
images = renderer(meshes)
Both libraries offer high-level APIs for their respective tasks, but pytorch3d focuses on 3D operations while imaginaire specializes in image synthesis and manipulation. pytorch3d provides more granular control over 3D rendering processes, while imaginaire abstracts complex image generation tasks into simpler interfaces.
Image-to-Image Translation in PyTorch
Pros of pytorch-CycleGAN-and-pix2pix
- Focused implementation of specific image-to-image translation models
- Simpler codebase, easier to understand and modify for beginners
- Well-documented with extensive tutorials and examples
Cons of pytorch-CycleGAN-and-pix2pix
- Limited to CycleGAN and pix2pix models
- Less flexibility for advanced users or complex projects
- Fewer features and optimizations compared to imaginaire
Code Comparison
pytorch-CycleGAN-and-pix2pix:
from models import create_model
model = create_model(opt)
model.setup(opt)
model.train()
imaginaire:
from imaginaire.trainers import BaseTrainer
trainer = BaseTrainer(cfg)
trainer.train()
pytorch-CycleGAN-and-pix2pix provides a more straightforward approach to model creation and training, while imaginaire offers a more modular and configurable framework.
imaginaire supports a wider range of models and techniques, making it more suitable for advanced users and research projects. It also includes optimizations and features that may improve performance and flexibility.
However, pytorch-CycleGAN-and-pix2pix's simplicity and focus on specific models make it an excellent choice for those looking to quickly implement and experiment with CycleGAN or pix2pix architectures.
Official PyTorch implementation of StyleGAN3
Pros of StyleGAN3
- Focuses specifically on high-quality image generation with improved architecture
- Offers better rotation and translation equivariance in generated images
- Provides a more streamlined codebase for easier understanding and modification
Cons of StyleGAN3
- Limited to image generation tasks, lacking versatility for other AI applications
- Requires more computational resources due to its advanced architecture
- Has a steeper learning curve for beginners compared to Imaginaire
Code Comparison
StyleGAN3:
import torch
import dnnlib
import legacy
network_pkl = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl'
device = torch.device('cuda')
with dnnlib.util.open_url(network_pkl) as f:
G = legacy.load_network_pkl(f)['G_ema'].to(device)
Imaginaire:
from imaginaire.trainers import BaseTrainer
from imaginaire.utils.distributed import init_dist
from imaginaire.utils.distributed import master_only_print as print
trainer = BaseTrainer(cfg)
init_dist(cfg.dist)
trainer.train()
Summary
StyleGAN3 excels in high-quality image generation with improved equivariance, while Imaginaire offers a more versatile toolkit for various AI tasks. StyleGAN3 may require more resources and expertise, but provides a focused solution for advanced image synthesis. Imaginaire, on the other hand, offers a broader range of applications with potentially easier implementation for diverse projects.
A latent text-to-image diffusion model
Pros of stable-diffusion
- More focused on text-to-image generation, offering a streamlined experience for this specific task
- Provides a web-based demo, making it accessible to users without local setup
- Has gained significant popularity and community support, leading to numerous extensions and improvements
Cons of stable-diffusion
- Limited to image generation tasks, while imaginaire offers a broader range of image and video manipulation capabilities
- Requires more computational resources for optimal performance, especially for high-resolution outputs
- Less flexibility in terms of customization and fine-tuning compared to imaginaire's modular architecture
Code Comparison
stable-diffusion:
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
imaginaire:
from imaginaire.generators import Generator
from imaginaire.utils.visualization import tensor2im
generator = Generator('pix2pixHD')
output = generator(input_image)
output_image = tensor2im(output)
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
Pros of CLIP
- Versatile multimodal learning, connecting text and images
- Efficient zero-shot classification capabilities
- Widely applicable across various computer vision tasks
Cons of CLIP
- Limited to image-text pairs, not as diverse as Imaginaire's multi-domain capabilities
- Lacks specific image generation or manipulation features
- May require fine-tuning for specialized tasks
Code Comparison
CLIP example:
import torch
from PIL import Image
import clip
model, preprocess = clip.load("ViT-B/32", device="cuda")
image = preprocess(Image.open("image.jpg")).unsqueeze(0).to("cuda")
text = clip.tokenize(["a dog", "a cat"]).to("cuda")
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
Imaginaire example:
from imaginaire.utils.distributed import init_dist
from imaginaire.trainers import find_trainer
from imaginaire.config import Config
cfg = Config('config.yaml')
trainer = find_trainer(cfg)
trainer.train()
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Pros of Detectron2
- Focused on object detection and segmentation tasks
- Extensive documentation and tutorials
- Large community support and frequent updates
Cons of Detectron2
- Limited to computer vision tasks
- Steeper learning curve for beginners
- Less flexibility for custom architectures
Code Comparison
Detectron2:
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
predictor = DefaultPredictor(cfg)
Imaginaire:
from imaginaire.utils.distributed import init_dist
from imaginaire.trainers import BaseTrainer
trainer = BaseTrainer(cfg)
trainer.train()
Key Differences
- Detectron2 focuses on object detection and segmentation, while Imaginaire covers a broader range of image synthesis tasks
- Detectron2 has a more structured API, whereas Imaginaire offers greater flexibility for custom architectures
- Imaginaire includes more advanced image generation techniques, such as GANs and style transfer
Both repositories are valuable tools for computer vision tasks, with Detectron2 excelling in object detection and Imaginaire offering a wider range of image synthesis capabilities.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Imaginaire
Docs | License | Installation | Model Zoo
Imaginaire is a pytorch library that contains optimized implementation of several image and video synthesis methods developed at NVIDIA.
License
Imaginaire is released under NVIDIA Software license. For commercial use, please consult NVIDIA Research Inquiries.
What's inside?
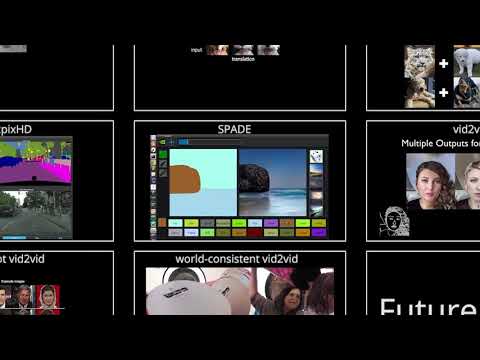
We have a tutorial for each model. Click on the model name, and your browser should take you to the tutorial page for the project.
Supervised Image-to-Image Translation
| Algorithm Name | Feature | Publication |
|---|---|---|
| pix2pixHD | Learn a mapping that converts a semantic image to a high-resolution photorealistic image. | Wang et. al. CVPR 2018 |
| SPADE | Improve pix2pixHD on handling diverse input labels and delivering better output quality. | Park et. al. CVPR 2019 |
Unsupervised Image-to-Image Translation
| Algorithm Name | Feature | Publication |
|---|---|---|
| UNIT | Learn a one-to-one mapping between two visual domains. | Liu et. al. NeurIPS 2017 |
| MUNIT | Learn a many-to-many mapping between two visual domains. | Huang et. al. ECCV 2018 |
| FUNIT | Learn a style-guided image translation model that can generate translations in unseen domains. | Liu et. al. ICCV 2019 |
| COCO-FUNIT | Improve FUNIT with a content-conditioned style encoding scheme for style code computation. | Saito et. al. ECCV 2020 |
Video-to-video Translation
| Algorithm Name | Feature | Publication |
|---|---|---|
| vid2vid | Learn a mapping that converts a semantic video to a photorealistic video. | Wang et. al. NeurIPS 2018 |
| fs-vid2vid | Learn a subject-agnostic mapping that converts a semantic video and an example image to a photoreslitic video. | Wang et. al. NeurIPS 2019 |
World-to-world Translation
| Algorithm Name | Feature | Publication |
|---|---|---|
| wc-vid2vid | Improve vid2vid on view consistency and long-term consistency. | Mallya et. al. ECCV 2020 |
| GANcraft | Convert semantic block worlds to realistic-looking worlds. | Hao et. al. ICCV 2021 |
Top Related Projects
PyTorch3D is FAIR's library of reusable components for deep learning with 3D data
Image-to-Image Translation in PyTorch
Official PyTorch implementation of StyleGAN3
A latent text-to-image diffusion model
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot