
Top Related Projects
Apache Pinot - A realtime distributed OLAP datastore
Apache Druid: a high performance real-time analytics database.
Apache Doris is an easy-to-use, high performance and unified analytics database.

The official home of the Presto distributed SQL query engine for big data
Apache Calcite
Apache Hive
Quick Overview
Apache Kylin is an open-source distributed analytics engine designed to provide SQL interface and multi-dimensional analysis (OLAP) on Hadoop/Spark supporting extremely large datasets. It aims to bridge the gap between Big Data and traditional OLAP tools, enabling interactive analytics on massive datasets.
Pros
- Extreme OLAP Engine: Kylin enables sub-second query latency on datasets with trillions of rows
- SQL Interface: Provides a standard SQL interface for querying data, making it accessible to business users
- Seamless integration: Works well with various Big Data and visualization tools in the ecosystem
- Scalability: Designed to handle petabyte-scale datasets efficiently
Cons
- Complex setup: Initial configuration and cube design can be challenging for beginners
- Resource intensive: Building and maintaining cubes can be computationally expensive
- Limited ad-hoc analysis: Requires pre-built cubes, which can limit flexibility for unexpected queries
- Learning curve: Understanding cube design and optimization requires significant effort
Getting Started
To get started with Apache Kylin:
- Download and install Kylin from the official website
- Set up Hadoop and other dependencies
- Configure Kylin by editing the
conf/kylin.propertiesfile - Start Kylin server:
${KYLIN_HOME}/bin/kylin.sh start
- Access the web interface at
http://localhost:7070/kylin - Create a project, define a data model, and build a cube
- Query your data using SQL through the web interface or JDBC
For detailed instructions, refer to the official Apache Kylin documentation.
Competitor Comparisons
Apache Pinot - A realtime distributed OLAP datastore
Pros of Pinot
- Better real-time analytics capabilities, especially for streaming data
- More flexible schema design and support for nested data structures
- Higher query performance for large-scale datasets
Cons of Pinot
- Steeper learning curve and more complex setup compared to Kylin
- Less mature OLAP cube functionality
- Requires more manual tuning for optimal performance
Code Comparison
Pinot query example:
SELECT COUNT(*) FROM myTable
WHERE timeColumn BETWEEN ? AND ?
GROUP BY dimension1, dimension2
LIMIT 100
Kylin query example:
SELECT dimension1, dimension2, SUM(metric1)
FROM my_cube
WHERE time_column BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY dimension1, dimension2
Key Differences
- Pinot uses a columnar storage format optimized for real-time ingestion and querying
- Kylin pre-builds OLAP cubes for faster query performance on predefined dimensions
- Pinot supports a wider range of data types and more flexible schema evolution
- Kylin integrates more tightly with the Hadoop ecosystem
Both projects are Apache Software Foundation top-level projects and offer robust solutions for big data analytics, but they cater to slightly different use cases and architectural preferences.
Apache Druid: a high performance real-time analytics database.
Pros of Druid
- Designed for real-time analytics and sub-second query performance
- Highly scalable and can handle massive datasets efficiently
- Supports streaming ingestion and real-time data updates
Cons of Druid
- Steeper learning curve and more complex setup compared to Kylin
- Less optimized for OLAP cube-based analytics
- May require more hardware resources for optimal performance
Code Comparison
Druid query example:
SELECT COUNT(*) AS count
FROM my_datasource
WHERE timestamp >= CURRENT_TIMESTAMP - INTERVAL '1' DAY
GROUP BY time_floor(__time, 'PT1H')
Kylin query example:
SELECT COUNT(*) AS count
FROM my_cube
WHERE part_dt >= TRUNC(SYSDATE) - 1
GROUP BY TRUNC(part_dt, 'HH24')
Both systems use SQL-like syntax, but Druid focuses on time-series data and real-time aggregations, while Kylin is optimized for pre-calculated OLAP cubes.
Summary
Druid excels in real-time analytics and scalability, making it suitable for large-scale streaming data scenarios. Kylin, on the other hand, is better suited for traditional OLAP workloads with pre-calculated cubes. The choice between the two depends on specific use cases, data volumes, and query patterns.
Apache Doris is an easy-to-use, high performance and unified analytics database.
Pros of Doris
- Better real-time analytics performance, especially for large-scale datasets
- More flexible and scalable architecture, supporting both MPP and vectorized execution
- Easier to deploy and maintain, with a simpler system architecture
Cons of Doris
- Less mature ecosystem compared to Kylin
- Limited support for complex pre-aggregation scenarios
- Steeper learning curve for users familiar with traditional OLAP systems
Code Comparison
Doris query example:
SELECT user_id, SUM(order_amount)
FROM orders
WHERE order_date >= '2023-01-01'
GROUP BY user_id;
Kylin query example:
SELECT user_id, SUM(order_amount)
FROM orders_cube
WHERE order_date >= '2023-01-01'
GROUP BY user_id;
The main difference is that Kylin typically uses pre-built cubes (e.g., orders_cube) for faster query performance, while Doris can efficiently query the base table directly. Doris's MPP architecture allows for fast ad-hoc queries without the need for extensive pre-aggregation, making it more flexible for real-time analytics scenarios.
The official home of the Presto distributed SQL query engine for big data
Pros of Presto
- Faster query execution for large-scale data processing
- More flexible architecture supporting various data sources
- Wider adoption and larger community support
Cons of Presto
- Higher memory consumption
- Steeper learning curve for configuration and optimization
- Less optimized for OLAP-specific workloads
Code Comparison
Kylin query example:
SELECT SUM(price) AS total_price
FROM sales
WHERE country = 'USA'
GROUP BY product_category
Presto query example:
SELECT product_category, SUM(price) AS total_price
FROM hive.sales
WHERE country = 'USA'
GROUP BY product_category
Both examples show similar SQL syntax, but Presto's query includes the data source (hive) in the table reference. Kylin typically uses pre-built cubes for faster OLAP queries, while Presto can query various data sources directly.
Key Differences
- Kylin focuses on OLAP workloads with pre-built cubes, while Presto is a more general-purpose SQL query engine
- Presto supports a wider range of data sources out-of-the-box
- Kylin offers better performance for specific OLAP scenarios, while Presto provides more flexibility for diverse query types
Apache Calcite
Pros of Calcite
- More versatile and adaptable to various data processing systems
- Stronger focus on SQL optimization and query planning
- Wider adoption and integration with other Apache projects
Cons of Calcite
- Steeper learning curve due to its complexity
- May require more configuration and setup for specific use cases
- Less out-of-the-box functionality for OLAP-specific operations
Code Comparison
Calcite (SQL parsing):
SqlParser.Config parserConfig = SqlParser.config()
.withCaseSensitive(false)
.withQuotedCasing(Casing.UNCHANGED)
.withUnquotedCasing(Casing.TO_UPPER);
SqlParser parser = SqlParser.create(sql, parserConfig);
SqlNode sqlNode = parser.parseQuery();
Kylin (Cube building):
CubeInstance cube = cubeManager.getCube(cubeName);
CubeSegment newSeg = cube.getNextSegment();
CubeBuilder cubeBuilder = new CubeBuilder(cube, newSeg);
cubeBuilder.buildCube(jobId, buildType);
While Calcite focuses on SQL parsing and optimization, Kylin specializes in OLAP cube operations. Calcite provides a more flexible foundation for various data processing tasks, whereas Kylin offers more specific functionality for multidimensional analysis and cube management out of the box.
Apache Hive
Pros of Hive
- Mature and widely adopted data warehousing solution with extensive ecosystem support
- Supports a wide range of data formats and storage systems
- Provides SQL-like query language (HiveQL) for easy data manipulation
Cons of Hive
- Can be slower for real-time queries compared to Kylin's OLAP cube approach
- Requires more manual optimization for complex queries
- Less efficient for high-concurrency scenarios
Code Comparison
Hive query example:
SELECT customer_id, SUM(order_total)
FROM orders
GROUP BY customer_id
HAVING SUM(order_total) > 1000;
Kylin query example:
SELECT customer_id, SUM(order_total)
FROM orders_cube
GROUP BY customer_id
HAVING SUM(order_total) > 1000;
The main difference is that Kylin queries are executed on pre-built OLAP cubes, which can provide faster query performance for complex aggregations and high-concurrency scenarios. Hive queries are executed directly on the raw data, which may require more processing time but offers more flexibility for ad-hoc queries.
Both systems use SQL-like syntax, making it easier for users familiar with traditional databases to work with big data. However, Kylin's approach is more suited for scenarios where query patterns are known in advance and can be optimized through cube design, while Hive is more flexible for exploratory data analysis and ad-hoc querying.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Apache Kylin
![]()


![]()
Apache Kylin is a leading open source OLAP engine for Big Data capable for sub-second query latency on trillions of records. Since being created and open sourced by eBay in 2014, and graduated to Top Level Project of Apache Software Foundation in 2015. Kylin has quickly been adopted by thousands of organizations world widely as their critical analytics application for Big Data.
Kylin has following key strengths:
- High qerformance, high concurrency, sub-second query latency
- Unified big data warehouse architecture
- Seamless integration with BI tools
- Comprehensive and enterprise-ready capabilities

What's New in Kylin 5.0
ð 1. Internal Table
Kylin now support internal table, which is designed for flexible query and lakehouse scenarios.
ð¦ 2. Model & Index Recommendation
With recommendation engine, you don't have to be an expert of modeling. Kylin now can auto modeling and optimizing indexes from you query history. You can also create model by importing sql text.
ð¾ 3. Native Compute Engine
Start from version 5.0, Kylin has integrated Gluten-ClickHouse Backend(incubating in apache software foundation) as native compute engine. And use Gluten mergetree as the default storage format of internal table. Which can bring 2~4x performance improvement compared with vanilla spark. Both model and internal table queries can get benefits from the Gluten integration.
ð§ð»ââï¸ 4. Streaming Data Source
Kylin now support Apache Kafka as streaming data source of model building. Users can create a fusion model to implement streaming-batch hybrid analysis.
Significant Change
ð¤1. Metadata Refactory
In Kylin 5.0, we have refactored the metadata storage structure and the transaction process, removed the project lock and Epoch mechanism. This has significantly improved transaction interface performance and system concurrency capabilities.
To upgrade from 5.0 alpha, beta, follow the Metadata Migration Guide
The metadata migration tool for upgrading from Kylin 4.0 is not tested, please contact kylin user or dev mailing list for help.
Other Optimizations and Improvements
Please refer to Release Notes for more details.
Quick Start
ð³ Play Kylin in Docker
To explore new features in Kylin 5 on a laptop, we recommend pulling the Docker image and checking the Apache Kylin Standalone Image on Docker Hub (For amd64 platform).
docker run -d \
--name Kylin5-Machine \
--hostname localhost \
-e TZ=UTC \
-m 10G \
-p 7070:7070 \
-p 8088:8088 \
-p 9870:9870 \
-p 8032:8032 \
-p 8042:8042 \
-p 2181:2181 \
apachekylin/apache-kylin-standalone:5.0.0-GA
Introduction
Kylin utilizes multidimensional modeling theory to build star or snowflake schemas based on tables, making it a powerful tool for large-scale data analysis. The model is Kylin's core component, consisting of three key aspects: model design, index design, and data loading. By carefully designing the model, optimizing indexes, and pre-computed data, queries executed on Kylin can avoid scanning the entire dataset, potentially reducing response times to mere seconds, even for petabyte-scale data.
-
Model design refers to establishing relationships between data tables to enable fast extraction of key information from multidimensional data. The core elements of model design are computed columns, dimensions, measures, and join relations.
-
Index design refers to creating indexes (CUBEs) within the model to precompute query results, thereby reducing query response time. Well-designed indexes not only improve query performance but also help minimize the storage and data-loading costs associated with precomputation.
-
Data loading refers to the process of importing data into the model, enabling queries to utilize the pre-built indexes rather than scanning the entire dataset. This allows for faster query responses by leveraging the model's optimized structure.
Core Concepts
-
Dimension: A perspective of viewing data, which can be used to describe object attributes or characteristics, for example, product category.
-
Measure: An aggregated sum, which is usually a continuous value, for example, product sales.
-
Pre-computation: The process of aggregating data based on model dimension combinations and of storing the results as indexes to accelerate data query.
-
Index: Also called CUBE, which is used to accelerate data query. Indexes are divided into:
- Aggregate Index: An aggregated combination of multiple dimensions and measures, and can be used to answer aggregate queries such as total sales for a given year.
- Table Index: A multilevel index in a wide table and can be used to answer detailed queries such as the last 100 transactions of a certain user.
Why Use Kylin
-
Low Query Latency vs. Large Volume
When analyzing massive data, there are some techniques to speed up computing and storage, but they cannot change the time complexity of query, that is, query latency and data volume are linearly dependent.
If it takes 1 minute to query 100 million entries of data records, querying 10 billion data entries will take about 1 hour and 40 minutes. When companies want to analyze all business data piled up over the years or to add complexity to query, say, with more dimensions, queries will be running extremely slow or even time out.
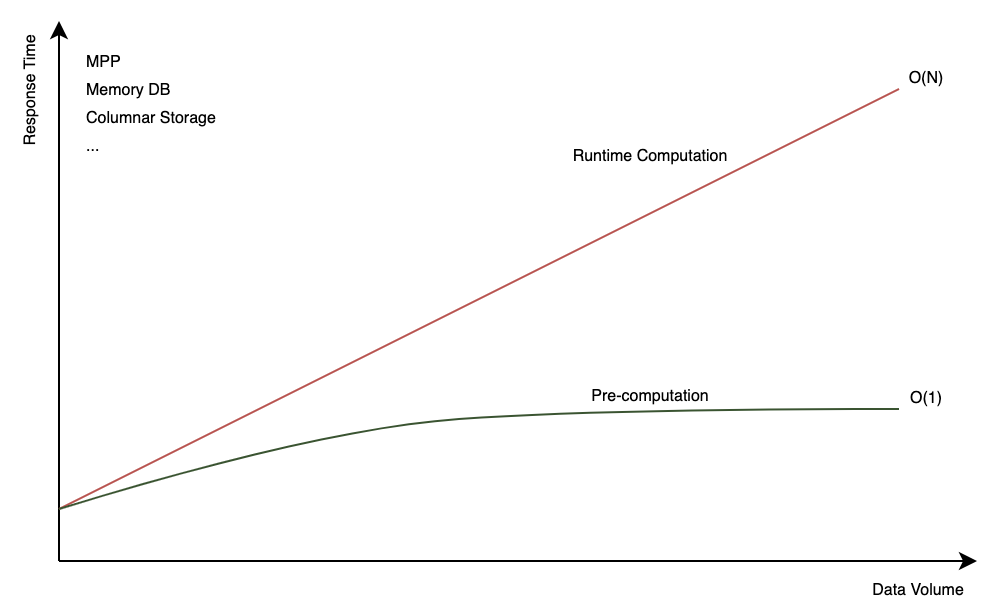
-
Pre-computation vs. Runtime Computation
Pre-computation and runtime computation are two approaches to calculating results in data processing and analytics. Pre-computation involves calculating and storing results in advance, so they can be quickly retrieved when a query is run. In contrast, runtime computation dynamically computes results during query execution, processing raw data and applying aggregations, filters, or transformations as needed for each query.
Kylin primarily focuses on pre-computation to enhance query performance. However, we also offer advanced features that partially support runtime computation. For more details, please refer to Table Snapshot, Runtime Join, and Internal Table.
-
Manual Modeling vs. Recommendation
Before Kylin 5.0, model design had to be done manually, which was a tedious process requiring extensive knowledge of multidimensional modeling. However, this changed with the introduction of Kylin 5.0. We now offer a new approach to model design, called recommendation, which allows models to be created by importing SQL, along with an automatic way to remove unnecessary indexes. Additionally, the system can leverage query history to generate index recommendations, further optimizing query performance. For more details, please refer to Recommendation.
-
Batch Data vs. Streaming Data
In the OLAP field, data has traditionally been processed in batches. However, this is changing as more companies are now required to handle both batch and streaming data to meet their business objectives. The ability to process data in real-time has become increasingly critical for applications such as real-time analytics, monitoring, and event-driven decision-making.
To address these evolving needs, we have introduced support for streaming data in the new version. This allows users to efficiently process and analyze data as it is generated, complementing the traditional batch processing capabilities. For more details, please refer to Streaming.
Top Related Projects
Apache Pinot - A realtime distributed OLAP datastore
Apache Druid: a high performance real-time analytics database.
Apache Doris is an easy-to-use, high performance and unified analytics database.
The official home of the Presto distributed SQL query engine for big data
Apache Calcite
Apache Hive
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot