 dagster
dagster
An orchestration platform for the development, production, and observation of data assets.
Top Related Projects

Prefect is a workflow orchestration framework for building resilient data pipelines in Python.

Apache Airflow - A platform to programmatically author, schedule, and monitor workflows

Always know what to expect from your data.

Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.

Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.

The fastest ⚡️ way to build data pipelines. Develop iteratively, deploy anywhere. ☁️
Quick Overview
Dagster is an open-source data orchestration platform for machine learning, analytics, and ETL. It provides a unified view of data pipelines and assets across the entire organization, allowing data practitioners to design, develop, and manage data workflows with ease.
Pros
- Flexible and extensible architecture that supports various data processing frameworks
- Strong emphasis on testing, observability, and maintainability of data pipelines
- Powerful asset-based paradigm for modeling data dependencies and lineage
- Intuitive UI for monitoring and debugging data workflows
Cons
- Steeper learning curve compared to some simpler workflow management tools
- Limited native integrations with certain cloud services and data platforms
- Resource-intensive for smaller projects or organizations
- Documentation can be overwhelming for beginners due to the platform's extensive features
Code Examples
- Defining a simple asset:
from dagster import asset
@asset
def my_data():
return [1, 2, 3, 4, 5]
- Creating a job with multiple assets:
from dagster import asset, define_asset_job
@asset
def raw_data():
return [1, 2, 3, 4, 5]
@asset
def processed_data(raw_data):
return [x * 2 for x in raw_data]
job = define_asset_job("my_job", selection=[raw_data, processed_data])
- Configuring a schedule for a job:
from dagster import schedule
@schedule(cron_schedule="0 0 * * *", job=job)
def daily_job_schedule(context):
return {}
Getting Started
To get started with Dagster, follow these steps:
- Install Dagster and its dependencies:
pip install dagster dagster-webserver
- Create a new Python file (e.g.,
hello_dagster.py) with a simple asset:
from dagster import asset
@asset
def hello_asset():
return "Hello, Dagster!"
- Run the Dagster UI:
dagster dev -f hello_dagster.py
- Open your browser and navigate to
http://localhost:3000to see the Dagster UI and interact with your asset.
Competitor Comparisons
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
Pros of Prefect
- More flexible and lightweight, allowing for easier integration with existing workflows
- Offers a more intuitive API and user-friendly interface
- Provides better support for dynamic workflows and real-time task execution
Cons of Prefect
- Less robust built-in versioning and lineage tracking compared to Dagster
- Fewer out-of-the-box integrations with data warehouses and analytics tools
- Less emphasis on data quality and testing features
Code Comparison
Prefect example:
from prefect import task, Flow
@task
def say_hello(name):
print(f"Hello, {name}!")
with Flow("My Flow") as flow:
say_hello("World")
Dagster example:
from dagster import job, op
@op
def say_hello(name: str):
print(f"Hello, {name}!")
@job
def my_job():
say_hello("World")
Both Prefect and Dagster offer powerful workflow orchestration capabilities, but they differ in their approach and focus. Prefect emphasizes flexibility and ease of use, while Dagster provides more robust data engineering features and integrations. The choice between the two depends on specific project requirements and team preferences.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Pros of Airflow
- Mature ecosystem with extensive community support and a wide range of integrations
- Rich UI for monitoring and managing workflows
- Flexible scheduling options with cron-like syntax
Cons of Airflow
- Steeper learning curve, especially for complex workflows
- Less emphasis on data-aware pipelines and testing
- Configuration can be verbose and repetitive
Code Comparison
Airflow DAG definition:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def my_task():
print("Hello, Airflow!")
dag = DAG('example_dag', start_date=datetime(2023, 1, 1))
task = PythonOperator(task_id='my_task', python_callable=my_task, dag=dag)
Dagster job definition:
from dagster import job, op
@op
def my_op():
print("Hello, Dagster!")
@job
def example_job():
my_op()
Dagster offers a more concise and type-safe approach to defining workflows, with built-in support for testing and data-aware pipelines. Airflow, on the other hand, provides a more traditional approach to workflow orchestration with a focus on scheduling and monitoring.
Always know what to expect from your data.
Pros of Great Expectations
- Focused specifically on data quality and validation
- Extensive library of built-in expectations for common data quality checks
- Generates detailed data quality reports and documentation
Cons of Great Expectations
- Limited to data validation and quality checks
- Requires integration with other tools for full data pipeline orchestration
- Steeper learning curve for complex data quality scenarios
Code Comparison
Great Expectations:
import great_expectations as ge
df = ge.read_csv("my_data.csv")
df.expect_column_values_to_be_between("age", min_value=0, max_value=120)
df.expect_column_values_to_not_be_null("name")
Dagster:
from dagster import asset
@asset
def process_data(context):
df = pd.read_csv("my_data.csv")
context.log.info(f"Processed {len(df)} rows")
return df
Great Expectations focuses on data validation, while Dagster provides a broader framework for data pipeline orchestration. Great Expectations excels in detailed data quality checks, whereas Dagster offers more flexibility in defining and managing entire data workflows.
Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.
Pros of Meltano
- Simpler setup and configuration, especially for ETL/ELT workflows
- Strong focus on Singer taps and targets, providing a wide range of pre-built connectors
- Built-in CLI for easy management and execution of data pipelines
Cons of Meltano
- Less flexible for complex data orchestration scenarios
- Smaller community and ecosystem compared to Dagster
- Limited support for advanced features like data lineage and observability
Code Comparison
Meltano pipeline configuration:
extractors:
- name: tap-github
pip_url: git+https://github.com/meltano/tap-github.git
loaders:
- name: target-postgres
pip_url: git+https://github.com/meltano/target-postgres.git
Dagster pipeline configuration:
@pipeline
def my_pipeline():
raw_data = extract_github_data()
transformed_data = transform_data(raw_data)
load_to_postgres(transformed_data)
Both Meltano and Dagster offer powerful data pipeline management capabilities, but they cater to different use cases and levels of complexity. Meltano excels in simplicity and quick setup for ETL/ELT workflows, while Dagster provides more flexibility and advanced features for complex data orchestration scenarios.
Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
Pros of Kedro
- Simpler learning curve and easier setup for data science projects
- Strong focus on data engineering best practices and modular code structure
- Built-in support for data catalogs and versioning
Cons of Kedro
- Less robust scheduling and orchestration capabilities
- More limited ecosystem and integrations compared to Dagster
- Fewer advanced features for complex workflows and monitoring
Code Comparison
Kedro pipeline definition:
def create_pipeline(**kwargs):
return Pipeline(
[
node(preprocess, "raw_data", "preprocessed_data"),
node(train_model, "preprocessed_data", "model"),
]
)
Dagster pipeline definition:
@pipeline
def my_pipeline():
preprocessed_data = preprocess(raw_data)
model = train_model(preprocessed_data)
Both Kedro and Dagster are open-source data orchestration frameworks, but they have different strengths. Kedro excels in providing a structured approach to data science projects, while Dagster offers more advanced features for complex data workflows and integrations with other tools. The choice between them depends on the specific needs of your project and team.
The fastest ⚡️ way to build data pipelines. Develop iteratively, deploy anywhere. ☁️
Pros of Ploomber
- Lightweight and easy to set up, with minimal configuration required
- Supports multiple execution environments (local, cloud, Kubernetes) out of the box
- Integrates well with existing Python workflows and Jupyter notebooks
Cons of Ploomber
- Smaller community and ecosystem compared to Dagster
- Less extensive documentation and fewer learning resources available
- Limited built-in integrations with external tools and services
Code Comparison
Ploomber pipeline definition:
from ploomber import DAG
dag = DAG()
dag.add_task('data_extraction', 'python', 'extract.py')
dag.add_task('data_processing', 'python', 'process.py', upstream=['data_extraction'])
dag.add_task('model_training', 'python', 'train.py', upstream=['data_processing'])
Dagster pipeline definition:
from dagster import job, op
@op
def data_extraction():
# Implementation
@op
def data_processing(data):
# Implementation
@op
def model_training(processed_data):
# Implementation
@job
def ml_pipeline():
data = data_extraction()
processed_data = data_processing(data)
model_training(processed_data)
Both frameworks offer declarative pipeline definitions, but Ploomber's approach is more file-centric, while Dagster uses Python functions with decorators.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME




Dagster is a cloud-native data pipeline orchestrator for the whole development lifecycle, with integrated lineage and observability, a declarative programming model, and best-in-class testability.
It is designed for developing and maintaining data assets, such as tables, data sets, machine learning models, and reports.
With Dagster, you declareâas Python functionsâthe data assets that you want to build. Dagster then helps you run your functions at the right time and keep your assets up-to-date.
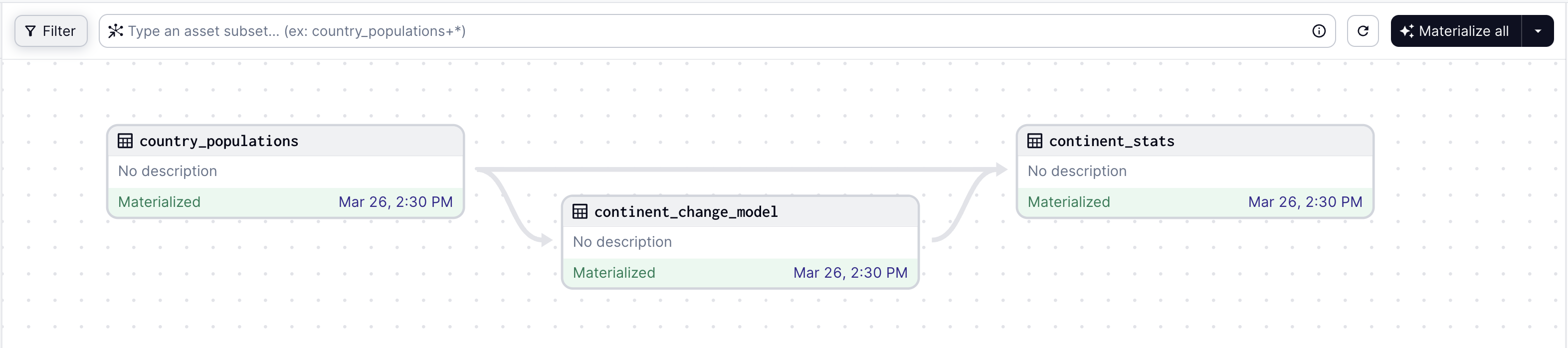
Here is an example of a graph of three assets defined in Python:
from dagster import asset
from pandas import DataFrame, read_html, get_dummies
from sklearn.linear_model import LinearRegression
@asset
def country_populations() -> DataFrame:
df = read_html("https://tinyurl.com/mry64ebh")[0]
df.columns = ["country", "pop2022", "pop2023", "change", "continent", "region"]
df["change"] = df["change"].str.rstrip("%").str.replace("â", "-").astype("float")
return df
@asset
def continent_change_model(country_populations: DataFrame) -> LinearRegression:
data = country_populations.dropna(subset=["change"])
return LinearRegression().fit(get_dummies(data[["continent"]]), data["change"])
@asset
def continent_stats(country_populations: DataFrame, continent_change_model: LinearRegression) -> DataFrame:
result = country_populations.groupby("continent").sum()
result["pop_change_factor"] = continent_change_model.coef_
return result
The graph loaded into Dagster's web UI:
Dagster is built to be used at every stage of the data development lifecycle - local development, unit tests, integration tests, staging environments, all the way up to production.
Quick Start:
If you're new to Dagster, we recommend checking out the docs or following the hands-on tutorial.
Dagster is available on PyPI and officially supports Python 3.9 through Python 3.12.
pip install dagster dagster-webserver
This installs two packages:
dagster: The core programming model.dagster-webserver: The server that hosts Dagster's web UI for developing and operating Dagster jobs and assets.
Documentation
You can find the full Dagster documentation here, including the Quickstart guide.
Key Features:

Dagster as a productivity platform
Identify the key assets you need to create using a declarative approach, or you can focus on running basic tasks. Embrace CI/CD best practices from the get-go: build reusable components, spot data quality issues, and flag bugs early.
Dagster as a robust orchestration engine
Put your pipelines into production with a robust multi-tenant, multi-tool engine that scales technically and organizationally.
Dagster as a unified control plane
Maintain control over your data as the complexity scales. Centralize your metadata in one tool with built-in observability, diagnostics, cataloging, and lineage. Spot any issues and identify performance improvement opportunities.
Master the Modern Data Stack with integrations
Dagster provides a growing library of integrations for todayâs most popular data tools. Integrate with the tools you already use, and deploy to your infrastructure.

Community
Connect with thousands of other data practitioners building with Dagster. Share knowledge, get help, and contribute to the open-source project. To see featured material and upcoming events, check out our Dagster Community page.
Join our community here:
- ð Star us on GitHub
- ð¥ Subscribe to our Newsletter
- ð¦ Follow us on Twitter
- ð´ï¸ Follow us on LinkedIn
- ðº Subscribe to our YouTube channel
- ð Read our blog posts
- ð Join us on Slack
- ð Browse Slack archives
- âï¸ Start a GitHub Discussion
Contributing
For details on contributing or running the project for development, check out our contributing guide.
License
Dagster is Apache 2.0 licensed.
Top Related Projects
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Always know what to expect from your data.
Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.
Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
The fastest ⚡️ way to build data pipelines. Develop iteratively, deploy anywhere. ☁️
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot