
Top Related Projects
The Metadata Platform for your Data and AI Stack

Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.

Apache Atlas - Open Metadata Management and Governance capabilities across the Hadoop platform and beyond

An Open Standard for lineage metadata collection
Quick Overview
DataHub is an open-source metadata platform for the modern data stack. It enables data discovery, data observability, and federated governance to help organizations maximize the value of their data ecosystem. DataHub provides a centralized platform for collecting, organizing, and utilizing metadata from various data sources and tools.
Pros
- Comprehensive metadata management with support for a wide range of data sources and tools
- Powerful search capabilities for easy data discovery
- Extensible architecture allowing for custom integrations and plugins
- Active community and regular updates
Cons
- Steep learning curve for initial setup and configuration
- Resource-intensive for large-scale deployments
- Limited out-of-the-box visualizations compared to some commercial alternatives
- Documentation can be inconsistent or outdated in some areas
Code Examples
# Connecting to DataHub using the Python SDK
from datahub.ingestion.sdk.client import DataHubClient
client = DataHubClient(server="http://localhost:8080")
result = client.get_aspect("urn:li:dataset:(urn:li:dataPlatform:bigquery,my_project.my_dataset.my_table,PROD)", "schemaMetadata")
print(result)
# Ingesting metadata using a recipe file
from datahub.ingestion.run.pipeline import Pipeline
Pipeline.create({
"source": {
"type": "mysql",
"config": {
"username": "user",
"password": "pass",
"host_port": "localhost:3306",
"database": "my_database"
}
},
"sink": {
"type": "datahub-rest",
"config": {
"server": "http://localhost:8080"
}
}
}).run()
# Searching for datasets using the GraphQL API
from gql import gql, Client
from gql.transport.requests import RequestsHTTPTransport
transport = RequestsHTTPTransport(url='http://localhost:8080/api/graphql')
client = Client(transport=transport, fetch_schema_from_transport=True)
query = gql('''
query searchDatasets($input: SearchInput!) {
search(input: $input) {
searchResults {
entity {
urn
type
... on Dataset {
name
platform {
name
}
}
}
}
}
}
''')
variables = {
"input": {
"type": "DATASET",
"query": "sales",
"start": 0,
"count": 10
}
}
result = client.execute(query, variable_values=variables)
print(result)
Getting Started
-
Install DataHub using Docker:
git clone https://github.com/datahub-project/datahub.git cd datahub docker-compose -f docker-compose.yml up -
Access the DataHub web interface at
http://localhost:9002 -
Install the Python SDK:
pip install acryl-datahub -
Ingest metadata using a simple Python script:
from datahub.ingestion.run.pipeline import Pipeline Pipeline.create({ "source": { "type": "file", "config": {"filename": "sample_data.json"} }, "sink": { "type": "datahub-rest", "config": {"server": "http://localhost:8080"} } }).run()
Competitor Comparisons
The Metadata Platform for your Data and AI Stack
Pros of datahub
- More comprehensive metadata management platform
- Broader ecosystem with integrations for various data sources
- Active community and regular updates
Cons of datahub
- Steeper learning curve due to more complex architecture
- Higher resource requirements for deployment and maintenance
- May be overkill for smaller organizations or simpler use cases
Code comparison
datahub:
from datahub.ingestion.run.pipeline import Pipeline
pipeline = Pipeline.create({
"source": {"type": "mysql", "config": {...}},
"sink": {"type": "datahub-rest", "config": {...}}
})
pipeline.run()
datahub>:
# No direct code comparison available
# datahub> appears to be a placeholder or non-existent repository
Summary
DataHub is a robust metadata management platform with a wide range of features and integrations. It offers comprehensive solutions for data discovery, lineage, and governance. However, its complexity may be challenging for smaller teams or projects with simpler requirements. The datahub> repository doesn't seem to exist or contain relevant code for comparison, so it's difficult to provide a meaningful contrast between the two.
Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.
Pros of Amundsen
- Simpler architecture and easier initial setup
- Strong focus on data discovery and search functionality
- Better integration with Apache Atlas for metadata management
Cons of Amundsen
- Less extensive features compared to DataHub
- Smaller community and ecosystem
- Limited support for complex data lineage scenarios
Code Comparison
Amundsen (Python):
from amundsen_common.models.table import Table
from amundsen_databuilder.models.neo4j_csv_serde import Neo4jCsvSerializable
class TableMetadata(Neo4jCsvSerializable):
TABLE_NODE_LABEL = 'Table'
DataHub (Java):
import com.linkedin.metadata.aspect.DatasetAspect;
import com.linkedin.metadata.entity.EntityService;
public class DatasetService {
private final EntityService _entityService;
Both projects use different programming languages and frameworks, reflecting their distinct approaches to metadata management and data cataloging.
Apache Atlas - Open Metadata Management and Governance capabilities across the Hadoop platform and beyond
Pros of Atlas
- More mature project with longer history and established community
- Stronger integration with Hadoop ecosystem and enterprise data governance
- Comprehensive data lineage and impact analysis capabilities
Cons of Atlas
- Steeper learning curve and more complex setup
- Less focus on modern data stack and cloud-native technologies
- UI can be less intuitive and user-friendly compared to DataHub
Code Comparison
Atlas (Java):
AtlasEntity entity = new AtlasEntity("hive_table", "employees");
entity.setAttribute("name", "employees");
entity.setAttribute("owner", "hr_department");
atlasClient.createEntity(entity);
DataHub (Python):
from datahub.emitter.mce_builder import make_dataset_urn
from datahub.emitter.rest_emitter import DatahubRestEmitter
dataset_urn = make_dataset_urn("hive", "employees", "prod")
emitter = DatahubRestEmitter("http://localhost:8080")
emitter.emit_mce(dataset_urn)
Both projects aim to provide metadata management and data governance solutions, but they differ in their approach and target use cases. Atlas is more suited for traditional enterprise environments with a focus on Hadoop ecosystems, while DataHub is designed for modern data stacks and offers a more user-friendly experience. The choice between them depends on specific organizational needs and existing infrastructure.
An Open Standard for lineage metadata collection
Pros of OpenLineage
- Focused specifically on data lineage, providing a more specialized solution
- Lightweight and easier to integrate into existing data pipelines
- Supports a wider range of data processing frameworks out-of-the-box
Cons of OpenLineage
- Less comprehensive metadata management compared to DataHub
- Smaller community and ecosystem of integrations
- Limited features for data discovery and governance
Code Comparison
OpenLineage example (Python):
from openlineage.client import OpenLineageClient
client = OpenLineageClient.from_environment()
client.emit(run_event)
DataHub example (Python):
from datahub.emitter.mce_builder import make_dataset_urn
from datahub.emitter.rest_emitter import DatahubRestEmitter
emitter = DatahubRestEmitter("http://localhost:8080")
dataset_urn = make_dataset_urn("bigquery", "my_dataset.my_table")
emitter.emit_mce(dataset_urn)
Both projects aim to improve data observability and lineage tracking, but they differ in scope and implementation. OpenLineage focuses specifically on lineage tracking across various data processing frameworks, while DataHub offers a more comprehensive metadata management solution. OpenLineage's lightweight nature makes it easier to integrate into existing pipelines, but DataHub provides more extensive features for data discovery and governance. The code examples demonstrate the different approaches: OpenLineage uses a simple client to emit run events, while DataHub requires more setup to emit metadata change events.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()
DataHub: The Data Discovery Platform for the Modern Data Stack
Built with â¤ï¸ by  DataHub and
DataHub and  LinkedIn
LinkedIn



ð Docs: docs.datahub.com
Quickstart | Features | Roadmap | Adoption | Demo | Town Hall
ð£âDataHub Town Hall is the 4th Thursday at 9am US PT of every month - add it to your calendar!
- Town-hall Zoom link: zoom.datahubproject.io
- Meeting details & past recordings
â¨âDataHub Community Highlights:
- Read our Monthly Project Updates here.
- Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At DataHub: Data Engineering Podcast
- Check out our most-read blog post, DataHub: Popular Metadata Architectures Explained @ LinkedIn Engineering Blog.
- Join us on Slack! Ask questions and keep up with the latest announcements.
Introduction
DataHub is an open-source data catalog for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels here. Also read our LinkedIn Engineering blog post, check out our Strata presentation and watch our Crunch Conference Talk. You should also visit DataHub Architecture to get a better understanding of how DataHub is implemented.
Features & Roadmap
Check out DataHub's Features & Roadmap.
Demo and Screenshots
There's a hosted demo environment courtesy of DataHub where you can explore DataHub without installing it locally.
Quickstart
Please follow the DataHub Quickstart Guide to run DataHub locally using Docker.
Development
If you're looking to build & modify datahub please take a look at our Development Guide.
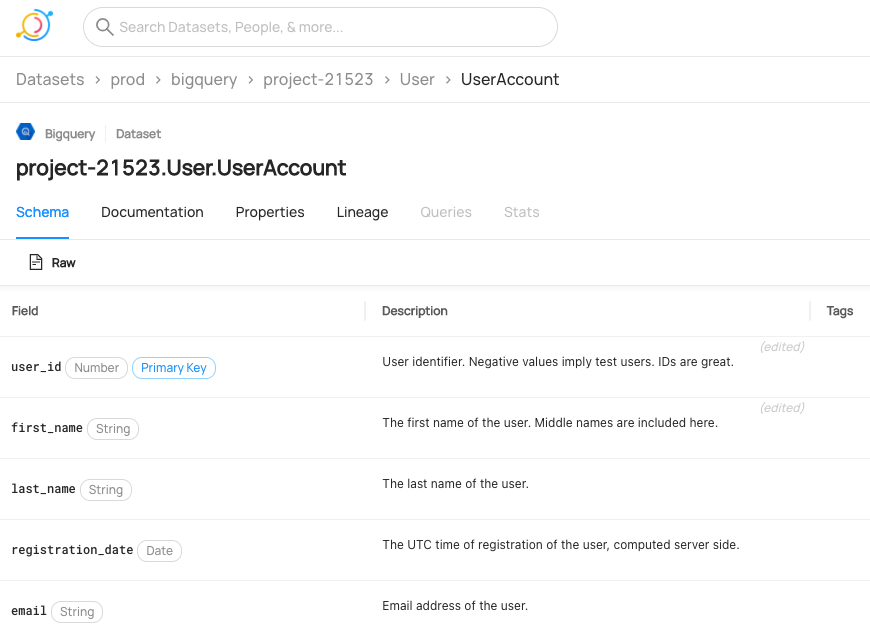
Source Code and Repositories
- datahub-project/datahub: This repository contains the complete source code for DataHub's metadata model, metadata services, integration connectors and the web application.
- acryldata/datahub-actions: DataHub Actions is a framework for responding to changes to your DataHub Metadata Graph in real time.
- acryldata/datahub-helm: Helm charts for deploying DataHub on a Kubernetes cluster
- acryldata/meta-world: A repository to store recipes, custom sources, transformations and other things to make your DataHub experience magical.
- dbt-impact-action: A github action for commenting on your PRs with a summary of the impact of changes within a dbt project.
- datahub-tools: Additional python tools to interact with the DataHub GraphQL endpoints, built by Notion.
- business-glossary-sync-action: A github action that opens PRs to update your business glossary yaml file.
- mcp-server-datahub: A Model Context Protocol server implementation for DataHub.
Releases
See Releases page for more details. We follow the SemVer Specification when versioning the releases and adopt the Keep a Changelog convention for the changelog format.
Contributing
We welcome contributions from the community. Please refer to our Contributing Guidelines for more details. We also have a contrib directory for incubating experimental features.
Community
Join our Slack workspace for discussions and important announcements. You can also find out more about our upcoming town hall meetings and view past recordings.
Security
See Security Stance for information on DataHub's Security.
Adoption
Here are the companies that have officially adopted DataHub. Please feel free to add yours to the list if we missed it.
- ABLY
- Adevinta
- Banksalad
- Cabify
- ClassDojo
- Coursera
- CVS Health
- DefinedCrowd
- DFDS
- Digital Turbine
- Expedia Group
- Experius
- Geotab
- Grofers
- Haibo Technology
- hipages
- inovex
- Inter&Co
- IOMED
- Klarna
- Moloco
- N26
- Optum
- Peloton
- PITS Global Data Recovery Services
- Razer
- Rippling
- Showroomprive
- SpotHero
- Stash
- Shanghai HuaRui Bank
- s7 Airlines
- ThoughtWorks
- TypeForm
- Udemy
- Uphold
- Viasat
- Wealthsimple
- Wikimedia
- Wolt
- Zynga
Select Articles & Talks
- DataHub Blog
- DataHub YouTube Channel
- Optum: Data Mesh via DataHub
- Saxo Bank: Enabling Data Discovery in Data Mesh
- Bringing The Power Of The DataHub Real-Time Metadata Graph To Everyone At DataHub
- DataHub: Popular Metadata Architectures Explained
- Driving DataOps Culture with LinkedIn DataHub @ DataOps Unleashed 2021
- The evolution of metadata: LinkedInâs story @ Strata Data Conference 2019
- Journey of metadata at LinkedIn @ Crunch Data Conference 2019
- DataHub Journey with Expedia Group
- Data Discoverability at SpotHero
- Data Catalogue â Knowing your data
- DataHub: A Generalized Metadata Search & Discovery Tool
- Open sourcing DataHub: LinkedInâs metadata search and discovery platform
- Emerging Architectures for Modern Data Infrastructure
See the full list here.
License
Top Related Projects
The Metadata Platform for your Data and AI Stack
Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.
Apache Atlas - Open Metadata Management and Governance capabilities across the Hadoop platform and beyond
An Open Standard for lineage metadata collection
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot