 deepops
deepops
Observe any stack, any service and any data, using any UI components you prefer, never missing any X factors and resolve them before they become real problems.
Top Related Projects

Tools for building GPU clusters
NVIDIA GPU Operator creates, configures, and manages GPUs in Kubernetes

Machine Learning Toolkit for Kubernetes

The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.

Determined is an open-source machine learning platform that simplifies distributed training, hyperparameter tuning, experiment tracking, and resource management. Works with PyTorch and TensorFlow.
Quick Overview
DeepOps is an open-source project by NVIDIA that provides a set of Ansible playbooks and scripts for deploying and managing GPU-enabled Kubernetes clusters. It aims to simplify the process of setting up and maintaining high-performance computing environments for deep learning and AI workloads.
Pros
- Streamlines the deployment of GPU-enabled Kubernetes clusters
- Supports various infrastructure providers (on-premises, cloud, hybrid)
- Includes tools for monitoring, logging, and cluster management
- Regularly updated and maintained by NVIDIA
Cons
- Steep learning curve for users unfamiliar with Ansible and Kubernetes
- Limited customization options for advanced users
- May require significant hardware resources for optimal performance
- Documentation could be more comprehensive for troubleshooting
Getting Started
To get started with DeepOps, follow these steps:
- Clone the DeepOps repository:
git clone https://github.com/NVIDIA/deepops.git
- Install Ansible and other dependencies:
cd deepops
./scripts/setup.sh
- Configure your inventory file:
cp config/inventory.example config/inventory
-
Edit the
config/inventoryfile to specify your target hosts and their roles. -
Deploy the Kubernetes cluster:
ansible-playbook -l k8s-cluster playbooks/k8s-cluster.yml
For more detailed instructions and advanced configurations, refer to the official DeepOps documentation.
Competitor Comparisons
Tools for building GPU clusters
Pros of DeepOps
- Officially maintained by NVIDIA, ensuring compatibility with their hardware
- More comprehensive documentation and setup guides
- Larger community and more frequent updates
Cons of DeepOps
- More complex setup process due to extensive features
- Heavier resource requirements for full deployment
- Steeper learning curve for beginners
Code Comparison
DeepOps:
# Example from DeepOps Ansible playbook
- name: Install NVIDIA GPU Operator
kubernetes:
definition: "{{ lookup('template', 'gpu-operator.yml.j2') | from_yaml }}"
state: present
deepops:
# Example from deepops Ansible playbook
- name: Install CUDA drivers
apt:
name: nvidia-driver-{{ nvidia_driver_version }}
state: present
Summary
DeepOps, maintained by NVIDIA, offers a more comprehensive solution with better documentation and community support. However, it may be more complex and resource-intensive. The deepops project provides a simpler alternative but with potentially less official support and fewer features. The code examples show different approaches to GPU setup, with DeepOps using Kubernetes operators and deepops focusing on direct driver installation.
NVIDIA GPU Operator creates, configures, and manages GPUs in Kubernetes
Pros of gpu-operator
- Focused specifically on GPU management in Kubernetes
- Officially maintained by NVIDIA, ensuring compatibility and updates
- Simpler setup for GPU-specific tasks in containerized environments
Cons of gpu-operator
- Limited scope compared to DeepOps' broader infrastructure management
- May require additional tools for comprehensive cluster management
- Less flexibility for non-GPU related configurations
Code Comparison
gpu-operator:
apiVersion: "nvidia.com/v1"
kind: "ClusterPolicy"
metadata:
name: "cluster-policy"
spec:
dcgmExporter:
enabled: true
DeepOps:
- hosts: all
become: true
roles:
- nvidia.nvidia_driver
- nvidia.nvidia_docker
Summary
gpu-operator excels in GPU-specific management within Kubernetes, offering a streamlined solution for containerized GPU workloads. It's ideal for organizations focused primarily on GPU utilization in their clusters. DeepOps, on the other hand, provides a more comprehensive approach to infrastructure management, including but not limited to GPU support. It offers greater flexibility for diverse computing environments but may require more setup for GPU-specific tasks compared to gpu-operator's specialized focus.
Machine Learning Toolkit for Kubernetes
Pros of Kubeflow
- More comprehensive ML platform with a wider range of tools and components
- Larger community and ecosystem, leading to better support and resources
- Better integration with cloud-native technologies and Kubernetes
Cons of Kubeflow
- Steeper learning curve and more complex setup process
- Requires more resources and can be overkill for smaller projects
- Less focus on GPU optimization compared to DeepOps
Code Comparison
Kubeflow deployment example:
apiVersion: kfdef.apps.kubeflow.org/v1
kind: KfDef
metadata:
name: kubeflow
spec:
applications:
- name: jupyter
- name: centraldashboard
- name: tf-job-operator
DeepOps deployment example:
- hosts: kube-master
roles:
- { role: kubespray-defaults }
- { role: kubernetes/preinstall }
- { role: kubernetes/master }
- { role: gpu }
DeepOps focuses more on infrastructure setup and GPU optimization, while Kubeflow provides a more comprehensive ML platform with various components. DeepOps may be better suited for GPU-intensive workloads and simpler setups, whereas Kubeflow offers a more extensive ecosystem for complex ML workflows in cloud-native environments.
The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.
Pros of MLflow
- Comprehensive ML lifecycle management with experiment tracking, model versioning, and deployment
- Language-agnostic design supporting multiple programming languages and frameworks
- Large and active community with extensive documentation and integrations
Cons of MLflow
- Steeper learning curve for beginners due to its extensive feature set
- Requires additional setup and infrastructure for full functionality
- May be overkill for smaller projects or teams
Code Comparison
MLflow:
import mlflow
mlflow.start_run()
mlflow.log_param("param1", value1)
mlflow.log_metric("metric1", value2)
mlflow.end_run()
DeepOps:
# No direct code comparison available
# DeepOps focuses on infrastructure deployment rather than ML experiment tracking
Summary
MLflow is a comprehensive platform for managing the machine learning lifecycle, offering experiment tracking, model versioning, and deployment capabilities. It supports multiple languages and has a large community. However, it may have a steeper learning curve and require more setup than simpler alternatives.
DeepOps, on the other hand, is primarily focused on deploying and managing infrastructure for deep learning workloads. It doesn't provide direct ML experiment tracking or model management features like MLflow does.
The choice between these tools depends on your specific needs: MLflow for end-to-end ML lifecycle management, or DeepOps for infrastructure deployment and management for deep learning projects.
Determined is an open-source machine learning platform that simplifies distributed training, hyperparameter tuning, experiment tracking, and resource management. Works with PyTorch and TensorFlow.
Pros of Determined
- More focused on deep learning and distributed training
- Provides a web UI for experiment tracking and visualization
- Offers built-in hyperparameter tuning capabilities
Cons of Determined
- Less comprehensive infrastructure management compared to DeepOps
- May have a steeper learning curve for users new to ML platforms
- Limited support for non-deep learning workloads
Code Comparison
DeepOps example (Kubernetes deployment):
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-operator
spec:
replicas: 1
selector:
matchLabels:
app: gpu-operator
Determined example (experiment configuration):
name: mnist_pytorch
hyperparameters:
learning_rate: 1.0
global_batch_size: 64
n_filters1: 32
n_filters2: 64
resources:
slots_per_trial: 1
DeepOps focuses on infrastructure deployment and management, while Determined emphasizes experiment configuration and management for deep learning workflows. DeepOps provides more flexibility in terms of infrastructure setup, whereas Determined offers a more streamlined experience for ML practitioners with built-in features for experiment tracking and hyperparameter tuning.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Observe everything you want in your business and never miss any X factors .
English | ç®ä½ä¸æ
XO
XO is short for xobserve. It is a programmable observability platform designed specifically for developers. It also serves as an alternative data visualization platform to Grafana.
XO enables users to quickly create online observability scenarios such as monitoring, logging, and tracing. If XO does not meet your specific needs, you can always file an issue, and reasonable requests will be promptly addressed.
Roadmap to V1.0
Up to this point, we have implemented the user interface (UI) part of XO, which can be used as an alternative to Grafana. We are currently working on the observability features, which will be released in V1.0.
Features
XO offers a wide range of features, including:
-
Observability: Encompasses an extensive range of observability scenarios with native support for Opentelemetry.
-
Charts and Datasources: Provides numerous chart components and data sources with rich customization options.
-
Interactivity: Offers deep and customizable interactions between charts and pages.
-
Enterprise features supported: Includes multi-tenancy, permission management, navigation menus, and global state management.
-
User experiences: Offers blazing fast performance and full customizability, ensuring a great user experience.
-
Modern UI design: Supports large data screens and is perfectly compatible with mobile devices.
-
Programmability: Empowers developers with powerful programmability and customization options. For instance, Datav agent supports using WebAssembly to develop your own plugins and data processing pipelines.
-
Community: Comes with extensive documentations, and rapid community support response.
Quick start & Documentation
The documentation is available at xobserve.io/docs.
You can also try online demo at play.xobserve.io.
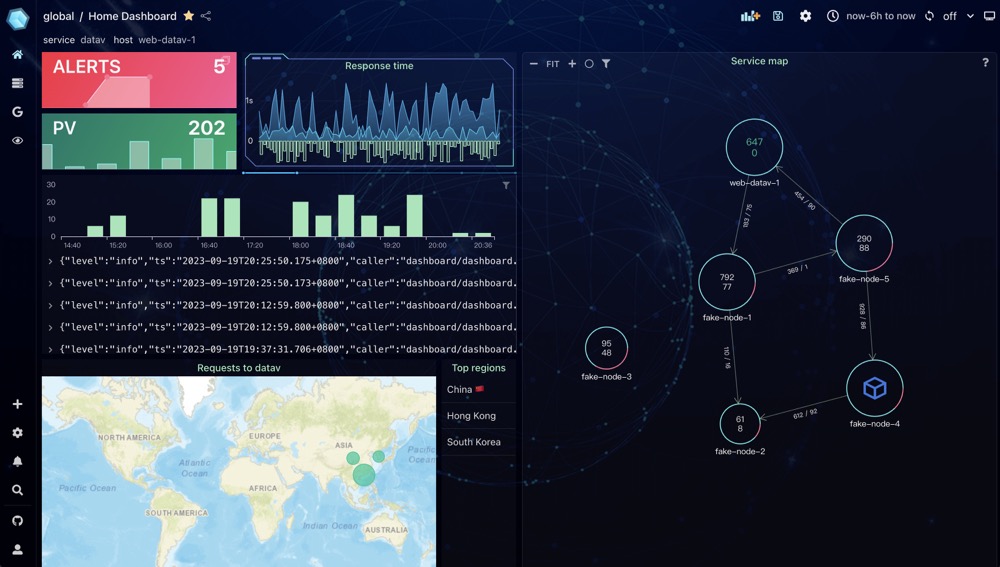
Example images
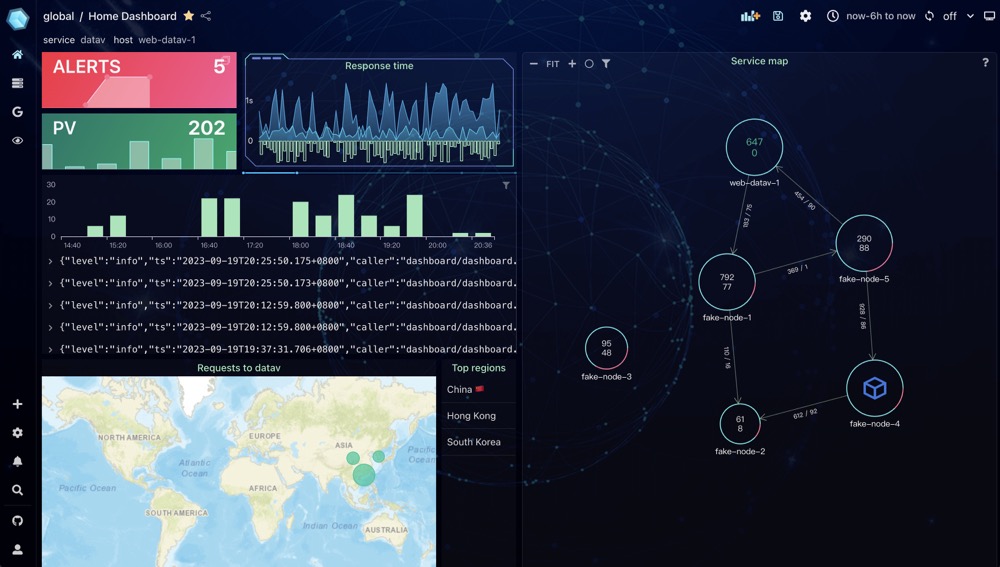
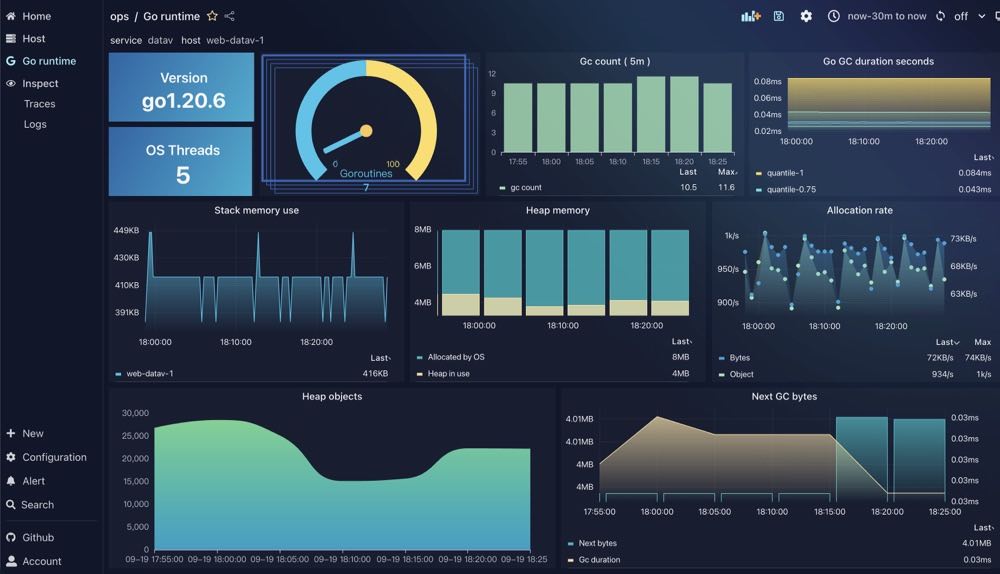
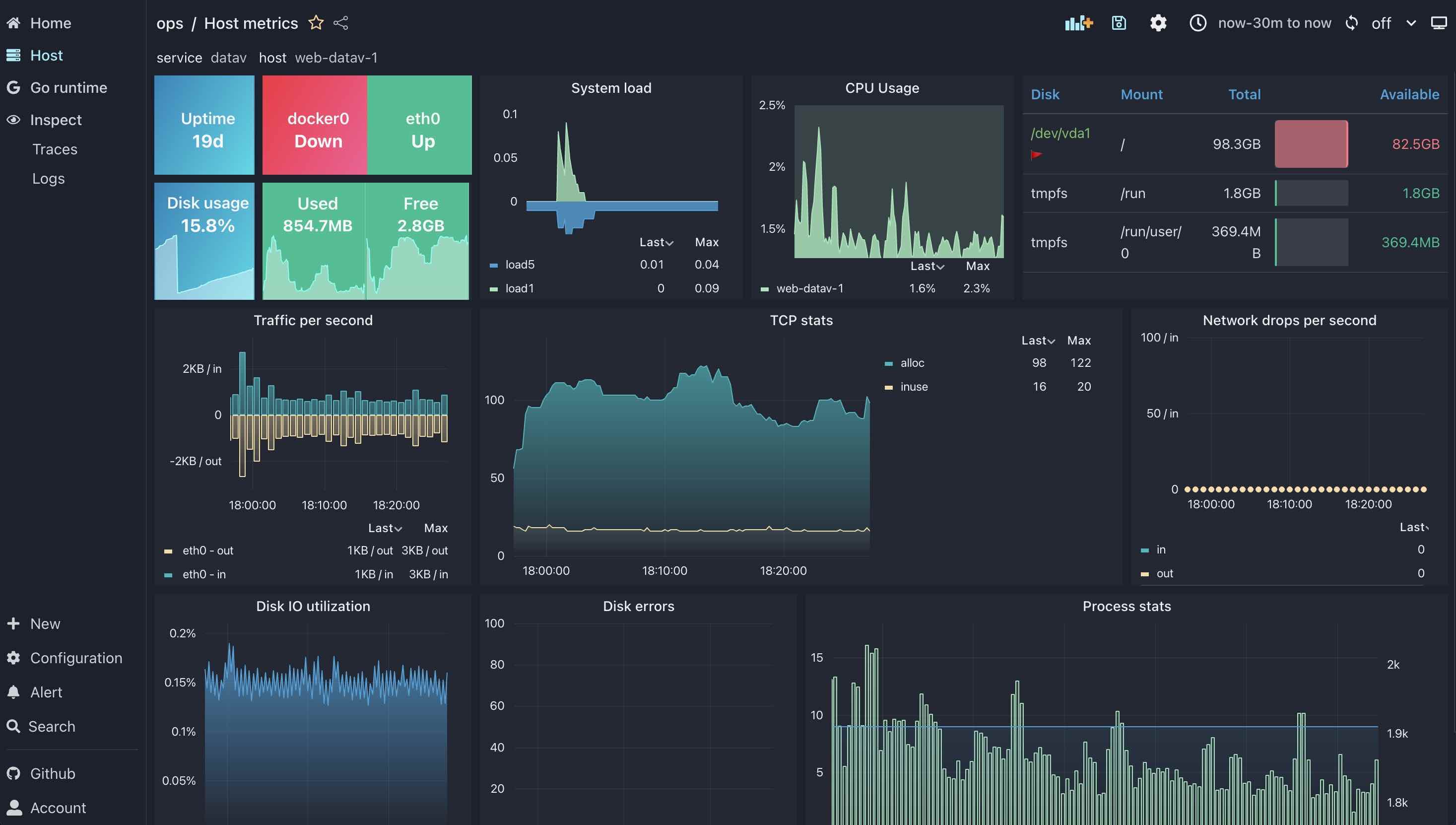

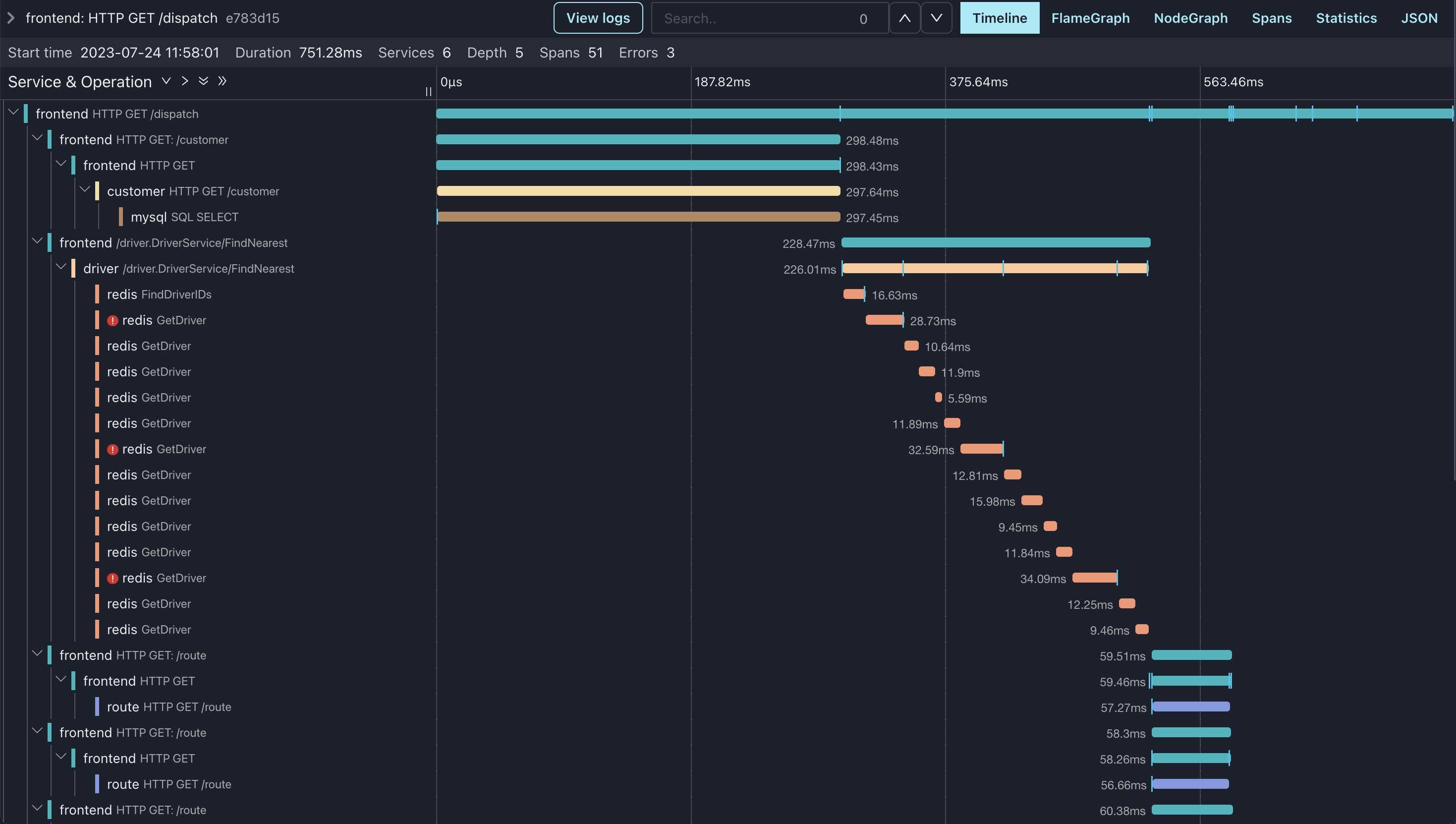


Visitors Count

Top Related Projects
Tools for building GPU clusters
NVIDIA GPU Operator creates, configures, and manages GPUs in Kubernetes
Machine Learning Toolkit for Kubernetes
The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.
Determined is an open-source machine learning platform that simplifies distributed training, hyperparameter tuning, experiment tracking, and resource management. Works with PyTorch and TensorFlow.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot