 Mask2Former
Mask2Former
Code release for "Masked-attention Mask Transformer for Universal Image Segmentation"
Top Related Projects
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.

Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow

OpenMMLab Detection Toolbox and Benchmark
End-to-End Object Detection with Transformers
Per-Pixel Classification is Not All You Need for Semantic Segmentation (NeurIPS 2021, spotlight)

Models and examples built with TensorFlow
Quick Overview
Mask2Former is a state-of-the-art universal image segmentation framework developed by Facebook Research. It unifies instance, semantic, and panoptic segmentation tasks under a single architecture, achieving superior performance across various benchmarks.
Pros
- Versatile: Handles multiple segmentation tasks with a single model
- High performance: Achieves state-of-the-art results on various benchmarks
- Efficient: Uses a unified architecture, reducing the need for task-specific models
- Extensible: Can be easily adapted to new segmentation tasks
Cons
- Complex architecture: May be challenging to understand and implement for beginners
- Resource-intensive: Requires significant computational resources for training and inference
- Limited documentation: Some aspects of the project may lack detailed explanations
- Dependency on specific libraries: Requires particular versions of PyTorch and other dependencies
Code Examples
- Installing Mask2Former:
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
python -m pip install 'git+https://github.com/facebookresearch/Mask2Former.git'
- Importing and using a pre-trained model:
from detectron2.config import get_cfg
from mask2former import add_maskformer2_config
from detectron2.engine import DefaultPredictor
cfg = get_cfg()
add_maskformer2_config(cfg)
cfg.merge_from_file("configs/coco/panoptic-segmentation/swin/maskformer2_swin_large_IN21k_384_bs16_100ep.yaml")
cfg.MODEL.WEIGHTS = "model_final_f07440.pkl"
predictor = DefaultPredictor(cfg)
outputs = predictor(image)
- Visualizing the results:
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog
v = Visualizer(image[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TEST[0]), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imshow("Result", out.get_image()[:, :, ::-1])
cv2.waitKey(0)
Getting Started
-
Install the required dependencies:
pip install torch torchvision pip install 'git+https://github.com/facebookresearch/detectron2.git' pip install 'git+https://github.com/facebookresearch/Mask2Former.git' -
Clone the repository:
git clone https://github.com/facebookresearch/Mask2Former.git cd Mask2Former -
Download a pre-trained model and configuration file from the project's model zoo.
-
Use the provided scripts for inference or training on your own dataset.
Competitor Comparisons
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Pros of Detectron2
- More comprehensive and versatile, supporting a wider range of computer vision tasks
- Longer development history, resulting in a more mature and stable codebase
- Larger community and more extensive documentation
Cons of Detectron2
- Higher complexity and steeper learning curve for beginners
- Potentially slower inference time for specific tasks compared to Mask2Former
Code Comparison
Detectron2:
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
predictor = DefaultPredictor(cfg)
Mask2Former:
from mask2former import add_mask2former_config
from detectron2.config import get_cfg
cfg = get_cfg()
add_mask2former_config(cfg)
cfg.merge_from_file("configs/coco/panoptic-segmentation/swin/maskformer2_swin_large_IN21k_384_bs16_100ep.yaml")
Both repositories build upon the Detectron2 framework, with Mask2Former focusing specifically on advanced instance and panoptic segmentation tasks. Mask2Former offers improved performance for these specific tasks, while Detectron2 provides a more comprehensive toolkit for various computer vision applications. The code comparison shows similarities in configuration setup, with Mask2Former adding its specific configurations to the Detectron2 base.
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
Pros of Mask_RCNN
- Simpler architecture, making it easier to understand and implement
- Well-established and widely used in various applications
- Extensive documentation and community support
Cons of Mask_RCNN
- Lower performance on complex segmentation tasks compared to Mask2Former
- Less flexible in handling different types of segmentation problems
- May require more manual tuning for optimal results
Code Comparison
Mask_RCNN:
from mrcnn import utils
import mrcnn.model as modellib
model = modellib.MaskRCNN(mode="inference", config=config, model_dir=MODEL_DIR)
model.load_weights(WEIGHTS_PATH, by_name=True)
results = model.detect([image], verbose=1)
Mask2Former:
from detectron2.config import get_cfg
from mask2former import add_maskformer2_config
cfg = get_cfg()
add_maskformer2_config(cfg)
cfg.merge_from_file("configs/coco/panoptic-segmentation/swin/maskformer2_swin_large_IN21k_384_bs16_100ep.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(image)
OpenMMLab Detection Toolbox and Benchmark
Pros of mmdetection
- Broader scope: Supports a wide range of object detection, instance segmentation, and panoptic segmentation algorithms
- Extensive documentation and tutorials: Easier for beginners to get started and understand the codebase
- Modular design: Allows for easy customization and extension of components
Cons of mmdetection
- Larger codebase: May be more complex to navigate and understand for specific tasks
- Potentially slower inference: Due to its generalized nature, it might not be as optimized for specific architectures
Code Comparison
mmdetection:
from mmdet.apis import init_detector, inference_detector
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
model = init_detector(config_file, checkpoint_file, device='cuda:0')
result = inference_detector(model, 'test.jpg')
Mask2Former:
from detectron2.config import get_cfg
from mask2former import add_maskformer2_config
from detectron2.engine import DefaultPredictor
cfg = get_cfg()
add_maskformer2_config(cfg)
cfg.merge_from_file("configs/coco/panoptic-segmentation/maskformer2_R50_bs16_50ep.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(image)
End-to-End Object Detection with Transformers
Pros of DETR
- Pioneered end-to-end object detection using transformers
- Simpler architecture with no need for anchor boxes or non-maximum suppression
- Flexible and easily extendable to other tasks like panoptic segmentation
Cons of DETR
- Slower convergence and longer training times compared to Mask2Former
- Lower performance on small objects and dense scenes
- Less efficient in terms of computational resources
Code Comparison
DETR:
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
Mask2Former:
class Mask2Former(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries):
super().__init__()
self.backbone = backbone
self.pixel_decoder = PixelDecoder(feature_channels)
self.transformer_decoder = TransformerDecoder(num_layers, hidden_dim)
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.mask_embed = MLP(hidden_dim, hidden_dim, mask_dim, 3)
Both repositories implement transformer-based architectures for object detection and segmentation tasks. While DETR introduced the concept, Mask2Former builds upon it with improved efficiency and performance, especially for instance and panoptic segmentation.
Per-Pixel Classification is Not All You Need for Semantic Segmentation (NeurIPS 2021, spotlight)
Pros of MaskFormer
- Introduced a unified framework for instance and semantic segmentation
- Simpler architecture compared to Mask2Former
- Established a strong baseline for panoptic segmentation tasks
Cons of MaskFormer
- Lower performance on certain benchmarks compared to Mask2Former
- Less flexible in handling different segmentation tasks
- May require more computational resources for training
Code Comparison
MaskFormer:
class MaskFormer(nn.Module):
def __init__(self, backbone, transformer, num_queries):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.query_embed = nn.Embedding(num_queries, hidden_dim)
Mask2Former:
class Mask2Former(nn.Module):
def __init__(self, backbone, transformer, num_queries, num_feature_levels):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.level_embed = nn.Embedding(num_feature_levels, hidden_dim)
The main difference in the code is that Mask2Former introduces an additional level_embed parameter, allowing it to handle multi-scale feature maps more effectively. This contributes to its improved performance across various segmentation tasks.
Models and examples built with TensorFlow
Pros of models
- Broader scope: Covers a wide range of machine learning tasks and models
- Official TensorFlow implementation: Ensures compatibility and optimized performance
- Extensive documentation and community support
Cons of models
- Larger and more complex repository structure
- May require more setup and configuration for specific tasks
- Less focused on a single task or model architecture
Code comparison
Mask2Former (PyTorch):
from mask2former import Mask2Former
model = Mask2Former(num_classes=80)
outputs = model(images)
models (TensorFlow):
import tensorflow as tf
from official.vision.modeling import maskrcnn_model
model = maskrcnn_model.MaskRCNNModel(num_classes=80)
outputs = model(images, training=False)
Summary
Mask2Former is a specialized repository focused on instance and semantic segmentation using the Mask2Former architecture. It offers a more streamlined experience for this specific task.
models is a comprehensive collection of TensorFlow implementations for various machine learning tasks. It provides a wider range of models and applications but may require more setup for specific use cases.
The choice between the two depends on the specific requirements of your project and your preferred deep learning framework (PyTorch vs. TensorFlow).
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation (CVPR 2022)
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
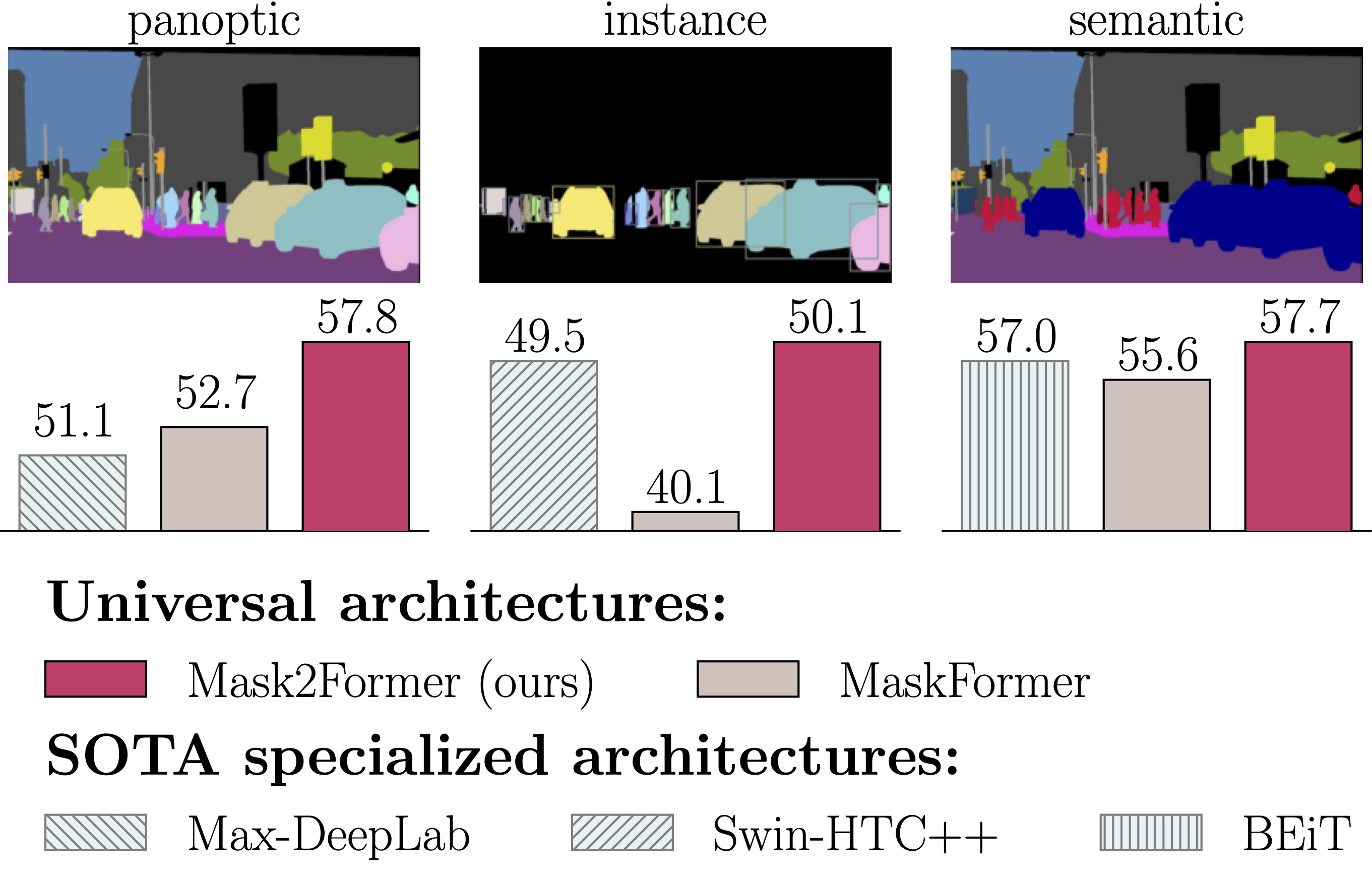
Features
- A single architecture for panoptic, instance and semantic segmentation.
- Support major segmentation datasets: ADE20K, Cityscapes, COCO, Mapillary Vistas.
Updates
- Add Google Colab demo.
- Video instance segmentation is now supported! Please check our tech report for more details.
Installation
See installation instructions.
Getting Started
See Preparing Datasets for Mask2Former.
See Getting Started with Mask2Former.
Run our demo using Colab: ![]()
Integrated into Huggingface Spaces ð¤ using Gradio. Try out the Web Demo:
Replicate web demo and docker image is available here:
Advanced usage
See Advanced Usage of Mask2Former.
Model Zoo and Baselines
We provide a large set of baseline results and trained models available for download in the Mask2Former Model Zoo.
License
Shield: ![]()
The majority of Mask2Former is licensed under a MIT License.
However portions of the project are available under separate license terms: Swin-Transformer-Semantic-Segmentation is licensed under the MIT license, Deformable-DETR is licensed under the Apache-2.0 License.
Citing Mask2Former
If you use Mask2Former in your research or wish to refer to the baseline results published in the Model Zoo, please use the following BibTeX entry.
@inproceedings{cheng2021mask2former,
title={Masked-attention Mask Transformer for Universal Image Segmentation},
author={Bowen Cheng and Ishan Misra and Alexander G. Schwing and Alexander Kirillov and Rohit Girdhar},
journal={CVPR},
year={2022}
}
If you find the code useful, please also consider the following BibTeX entry.
@inproceedings{cheng2021maskformer,
title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
journal={NeurIPS},
year={2021}
}
Acknowledgement
Code is largely based on MaskFormer (https://github.com/facebookresearch/MaskFormer).
Top Related Projects
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
OpenMMLab Detection Toolbox and Benchmark
End-to-End Object Detection with Transformers
Per-Pixel Classification is Not All You Need for Semantic Segmentation (NeurIPS 2021, spotlight)
Models and examples built with TensorFlow
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot