 MaskFormer
MaskFormer
Per-Pixel Classification is Not All You Need for Semantic Segmentation (NeurIPS 2021, spotlight)
Top Related Projects
Code release for "Masked-attention Mask Transformer for Universal Image Segmentation"
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.

Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow

OpenMMLab Detection Toolbox and Benchmark
End-to-End Object Detection with Transformers
FAIR's research platform for object detection research, implementing popular algorithms like Mask R-CNN and RetinaNet.
Quick Overview
MaskFormer is a unified framework for image segmentation tasks developed by Facebook Research. It combines the strengths of mask classification and pixel classification approaches, offering a flexible and efficient solution for various segmentation problems, including panoptic, instance, and semantic segmentation.
Pros
- Versatile: Handles multiple segmentation tasks with a single architecture
- State-of-the-art performance: Achieves competitive results across various benchmarks
- Efficient: Utilizes a transformer-based design for effective feature extraction
- Easy integration: Can be incorporated into existing segmentation pipelines
Cons
- Computational complexity: May require significant computational resources for training and inference
- Learning curve: Understanding and implementing the architecture might be challenging for beginners
- Limited pre-trained models: Fewer pre-trained models available compared to some other segmentation frameworks
- Dependency on specific libraries: Requires specific versions of PyTorch and other dependencies
Code Examples
- Loading a pre-trained MaskFormer model:
from detectron2.config import get_cfg
from mask_former import add_mask_former_config
from mask_former_model import MaskFormerModel
cfg = get_cfg()
add_mask_former_config(cfg)
cfg.merge_from_file("path/to/config.yaml")
model = MaskFormerModel(cfg)
- Performing inference on an image:
import torch
from PIL import Image
image = Image.open("path/to/image.jpg")
inputs = torch.as_tensor(np.asarray(image).transpose(2, 0, 1))
outputs = model([{"image": inputs}])
- Visualizing segmentation results:
from detectron2.utils.visualizer import Visualizer
v = Visualizer(image, metadata=metadata, scale=1.2)
out = v.draw_instance_predictions(outputs[0]["instances"].to("cpu"))
out.save("output.png")
Getting Started
- Install dependencies:
pip install torch torchvision
pip install 'git+https://github.com/facebookresearch/detectron2.git'
pip install 'git+https://github.com/facebookresearch/MaskFormer.git'
- Download a pre-trained model:
wget https://dl.fbaipublicfiles.com/maskformer/mask_former/coco/panoptic/maskformer_panoptic_R50_bs16_50ep/model_final_94dc52.pkl
- Run inference:
from mask_former.config import add_mask_former_config
from detectron2.config import get_cfg
from detectron2.engine import DefaultPredictor
cfg = get_cfg()
add_mask_former_config(cfg)
cfg.merge_from_file("configs/coco/panoptic-segmentation/maskformer_R50_bs16_50ep.yaml")
cfg.MODEL.WEIGHTS = "model_final_94dc52.pkl"
predictor = DefaultPredictor(cfg)
# Use predictor on your images
outputs = predictor(image)
Competitor Comparisons
Code release for "Masked-attention Mask Transformer for Universal Image Segmentation"
Pros of Mask2Former
- Improved performance on various segmentation tasks
- More efficient architecture with reduced computational complexity
- Better handling of multi-scale features and long-range dependencies
Cons of Mask2Former
- Potentially more complex to implement and fine-tune
- May require more training data to achieve optimal results
Code Comparison
MaskFormer:
class MaskFormer(nn.Module):
def __init__(self, backbone, transformer, num_classes):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
Mask2Former:
class Mask2Former(nn.Module):
def __init__(self, backbone, pixel_decoder, transformer_decoder, num_classes):
super().__init__()
self.backbone = backbone
self.pixel_decoder = pixel_decoder
self.transformer_decoder = transformer_decoder
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
The main difference in the code is the introduction of a pixel_decoder and transformer_decoder in Mask2Former, which contributes to its improved performance and efficiency in handling multi-scale features and long-range dependencies.
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Pros of Detectron2
- More comprehensive and versatile, supporting a wider range of computer vision tasks
- Larger community and more extensive documentation
- Modular design allows for easier customization and extension
Cons of Detectron2
- Steeper learning curve due to its complexity and extensive features
- Potentially slower inference time for specific tasks compared to specialized models
Code Comparison
MaskFormer:
from maskformer import MaskFormer
model = MaskFormer(num_classes=150)
outputs = model(images)
Detectron2:
from detectron2.config import get_cfg
from detectron2.engine import DefaultPredictor
cfg = get_cfg()
cfg.merge_from_file("path/to/config.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(image)
Summary
Detectron2 is a more comprehensive computer vision library, offering a wide range of models and tasks. It has a larger community and more extensive documentation, making it suitable for various projects. However, its complexity can lead to a steeper learning curve.
MaskFormer, on the other hand, is more specialized, focusing on instance segmentation tasks. It may offer simpler implementation for specific use cases and potentially faster inference times for certain tasks.
The choice between the two depends on the project requirements, desired flexibility, and the specific computer vision tasks at hand.
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
Pros of Mask_RCNN
- Well-established and widely adopted in the computer vision community
- Extensive documentation and community support
- Suitable for a wide range of instance segmentation tasks
Cons of Mask_RCNN
- Generally slower inference time compared to MaskFormer
- May struggle with complex scenes or overlapping objects
- Limited flexibility in handling different segmentation paradigms
Code Comparison
MaskFormer:
outputs = model(pixel_values=pixel_values)
segmentation = outputs.segmentation
class_queries = outputs.class_queries
Mask_RCNN:
results = model.detect([image], verbose=0)
r = results[0]
masks = r['masks']
class_ids = r['class_ids']
MaskFormer uses a unified approach for various segmentation tasks, while Mask_RCNN is specifically designed for instance segmentation. MaskFormer's code is more concise and flexible, allowing for easier adaptation to different segmentation paradigms. Mask_RCNN's code is more explicit in separating masks and class IDs, which can be beneficial for certain applications but may require more post-processing for others.
OpenMMLab Detection Toolbox and Benchmark
Pros of mmdetection
- Broader scope: Supports a wide range of object detection, instance segmentation, and panoptic segmentation algorithms
- Extensive documentation and tutorials: Offers comprehensive guides for various tasks and model configurations
- Active community: Regular updates, bug fixes, and contributions from a large user base
Cons of mmdetection
- Steeper learning curve: More complex codebase due to its extensive feature set
- Potentially slower inference: May have higher overhead for simple tasks compared to MaskFormer's focused approach
Code Comparison
MaskFormer:
outputs = model(images)
mask_cls_results = outputs["pred_logits"]
mask_pred_results = outputs["pred_masks"]
mmdetection:
results = model(return_loss=False, rescale=True, **data)
bbox_results, mask_results = results[:2]
MaskFormer focuses on a unified approach for segmentation tasks, while mmdetection provides a more comprehensive toolkit for various detection and segmentation algorithms. MaskFormer's code is generally more straightforward for its specific use case, while mmdetection offers more flexibility at the cost of increased complexity.
End-to-End Object Detection with Transformers
Pros of DETR
- Pioneered end-to-end object detection using transformers
- Simpler architecture with no need for anchor boxes or non-maximum suppression
- Versatile framework adaptable to various tasks beyond object detection
Cons of DETR
- Generally slower convergence compared to MaskFormer
- May struggle with small object detection
- Higher computational complexity, especially for large images
Code Comparison
DETR:
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
MaskFormer:
class MaskFormer(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries):
super().__init__()
self.backbone = backbone
self.transformer = transformer
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.mask_embed = MLP(hidden_dim, hidden_dim, hidden_dim, 3)
Both repositories share similar high-level structures, utilizing a backbone and transformer. The main difference lies in their output heads: DETR focuses on bounding box prediction, while MaskFormer emphasizes mask generation for instance segmentation.
FAIR's research platform for object detection research, implementing popular algorithms like Mask R-CNN and RetinaNet.
Pros of Detectron
- More established and mature project with a longer history
- Broader range of object detection and segmentation models
- Extensive documentation and community support
Cons of Detectron
- Less focused on specific tasks like panoptic segmentation
- May have more complexity for users only interested in certain tasks
- Slower development cycle compared to newer projects
Code Comparison
MaskFormer:
from maskformer import MaskFormer
model = MaskFormer(num_classes=150)
outputs = model(images)
Detectron:
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
cfg = model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(image)
MaskFormer offers a simpler API for specific tasks, while Detectron provides a more comprehensive framework with additional configuration options. MaskFormer focuses on unified segmentation tasks, whereas Detectron covers a broader range of computer vision tasks. Both projects are maintained by Facebook Research, but MaskFormer represents a more recent approach to segmentation problems.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation
Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
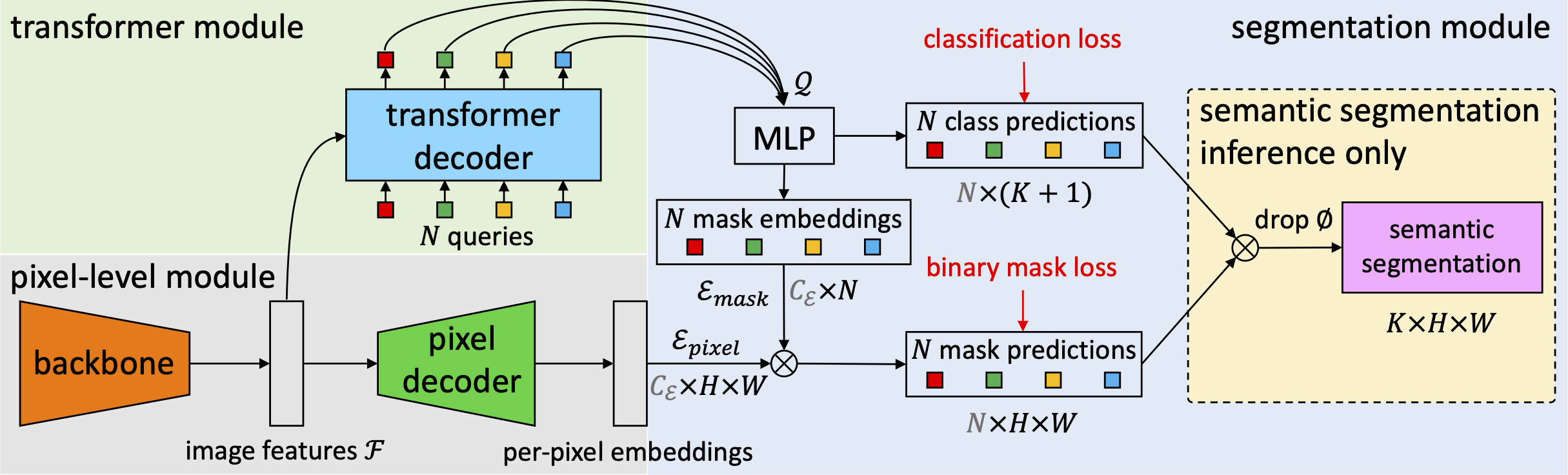
Mask2Former
Checkout Mask2Former, a universal architecture based on MaskFormer meta-architecture that achieves SOTA on panoptic, instance and semantic segmentation across four popular datasets (ADE20K, Cityscapes, COCO, Mapillary Vistas).
Features
- Better results while being more efficient.
- Unified view of semantic- and instance-level segmentation tasks.
- Support major semantic segmentation datasets: ADE20K, Cityscapes, COCO-Stuff, Mapillary Vistas.
- Support ALL Detectron2 models.
Installation
See installation instructions.
Getting Started
See Preparing Datasets for MaskFormer.
See Getting Started with MaskFormer.
Model Zoo and Baselines
We provide a large set of baseline results and trained models available for download in the MaskFormer Model Zoo.
License
Shield: ![]()
The majority of MaskFormer is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.

However portions of the project are available under separate license terms: Swin-Transformer-Semantic-Segmentation is licensed under the MIT license.
Citing MaskFormer
If you use MaskFormer in your research or wish to refer to the baseline results published in the Model Zoo, please use the following BibTeX entry.
@inproceedings{cheng2021maskformer,
title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
journal={NeurIPS},
year={2021}
}
Top Related Projects
Code release for "Masked-attention Mask Transformer for Universal Image Segmentation"
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
OpenMMLab Detection Toolbox and Benchmark
End-to-End Object Detection with Transformers
FAIR's research platform for object detection research, implementing popular algorithms like Mask R-CNN and RetinaNet.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot