
Top Related Projects

Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.

Open Source Neural Machine Translation and (Large) Language Models in PyTorch

Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
A framework for training and evaluating AI models on a variety of openly available dialogue datasets.

🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.

A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)
Quick Overview
Google's seq2seq is a general-purpose encoder-decoder framework for Tensorflow that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more. It provides a modular and extensible framework for defining sequence-to-sequence models and managing the training process.
Pros
- Flexible and extensible architecture for various sequence-to-sequence tasks
- Built on top of TensorFlow, leveraging its powerful features and ecosystem
- Includes pre-built models and examples for common NLP tasks
- Supports distributed training and inference
Cons
- Requires familiarity with TensorFlow and deep learning concepts
- Documentation could be more comprehensive for advanced use cases
- May require significant computational resources for large-scale tasks
- Not actively maintained (last update was in 2017)
Code Examples
- Creating a basic seq2seq model:
import seq2seq
model = seq2seq.models.BasicSeq2SeqWithAttention(
source_vocab_info=source_vocab_info,
target_vocab_info=target_vocab_info,
params=params)
- Training the model:
train_op = seq2seq.training.TrainOp(
model,
optimizer=tf.train.AdamOptimizer(),
learning_rate=0.001)
hooks = [
seq2seq.training.ModelParamsCountHook(),
seq2seq.training.TrainSummaryHook(model, summary_dir),
]
seq2seq.training.train(
train_op,
train_data,
hooks=hooks,
num_epochs=10)
- Performing inference:
predictions = model.predict(features)
translations = predictions["predicted_tokens"]
for translation in translations:
print(" ".join(translation))
Getting Started
- Install seq2seq:
pip install seq2seq
- Prepare your data:
source_vocab_info = seq2seq.data.VocabInfo(...)
target_vocab_info = seq2seq.data.VocabInfo(...)
train_data = seq2seq.data.ParallelTextDataset(...)
- Define and train your model:
model = seq2seq.models.BasicSeq2SeqWithAttention(...)
train_op = seq2seq.training.TrainOp(model, ...)
seq2seq.training.train(train_op, train_data, ...)
- Use the model for inference:
predictions = model.predict(features)
Competitor Comparisons
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Pros of tensor2tensor
- More comprehensive library with a wider range of models and features
- Better documentation and community support
- Actively maintained and updated
Cons of tensor2tensor
- Steeper learning curve due to its complexity
- May be overkill for simpler seq2seq tasks
- Requires more computational resources
Code Comparison
seq2seq:
import seq2seq
model = seq2seq.models.BasicSeq2Seq(source_vocab_size, target_vocab_size, hidden_dim)
model.fit(source_data, target_data)
predictions = model.predict(new_source_data)
tensor2tensor:
import tensor2tensor as t2t
problem = t2t.problems.translate_ende.TranslateEndeWmt32k()
model = t2t.models.transformer.Transformer(hparams)
estimator = t2t.utils.trainer_lib.create_estimator(model, problem, hparams)
estimator.train(input_fn=problem.make_estimator_input_fn(mode=tf.estimator.ModeKeys.TRAIN))
The code comparison shows that tensor2tensor requires more setup and configuration, but offers greater flexibility and power. seq2seq provides a simpler interface for basic sequence-to-sequence tasks, making it easier to get started quickly.
Open Source Neural Machine Translation and (Large) Language Models in PyTorch
Pros of OpenNMT-py
- More actively maintained with frequent updates
- Supports a wider range of model architectures and features
- Better documentation and community support
Cons of OpenNMT-py
- Steeper learning curve for beginners
- May require more computational resources for some models
Code Comparison
OpenNMT-py:
import onmt
# Define model
model = onmt.models.build_model(opt, model_opt, fields, checkpoint)
# Train model
trainer = onmt.Trainer(model, train_loss, valid_loss, optim, trunc_size)
trainer.train(train_iter, valid_iter, train_steps, valid_steps)
seq2seq:
import seq2seq
# Define model
model = seq2seq.models.BasicSeq2Seq(source_vocab_size, target_vocab_size)
# Train model
model.fit(source_sequences, target_sequences, batch_size=32, epochs=10)
Both repositories provide frameworks for sequence-to-sequence learning, but OpenNMT-py offers more flexibility and features at the cost of increased complexity. seq2seq is simpler to use but has limited customization options. OpenNMT-py is better suited for advanced users and research, while seq2seq may be more appropriate for quick prototyping or simpler applications.
Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Pros of fairseq
- More actively maintained with frequent updates
- Supports a wider range of architectures and tasks
- Better documentation and examples
Cons of fairseq
- Steeper learning curve due to more complex codebase
- Requires more computational resources for some models
Code Comparison
seq2seq example:
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=8)
model.compile(loss='mse', optimizer='rmsprop')
fairseq example:
from fairseq.models.transformer import TransformerModel
model = TransformerModel.build_model(args, task)
criterion = task.build_criterion(args)
optimizer = task.build_optimizer(args, model)
Summary
fairseq offers more features and flexibility but may be more challenging for beginners. seq2seq is simpler but less actively maintained. fairseq is better suited for advanced research and production environments, while seq2seq might be preferable for quick prototyping or educational purposes.
A framework for training and evaluating AI models on a variety of openly available dialogue datasets.
Pros of ParlAI
- More comprehensive and versatile, supporting a wider range of dialogue tasks and models
- Active development and regular updates, with a larger community of contributors
- Includes pre-built datasets and evaluation metrics for easier experimentation
Cons of ParlAI
- Steeper learning curve due to its broader scope and more complex architecture
- Potentially higher computational requirements for running some of the more advanced models
Code Comparison
ParlAI example:
from parlai.core.agents import Agent
from parlai.core.worlds import DialogPartnerWorld
class MyAgent(Agent):
def act(self):
observation = self.observation
return {'text': 'Hello, how are you?'}
world = DialogPartnerWorld(opt, [MyAgent(opt), MyAgent(opt)])
world.parley()
seq2seq example:
import tensorflow as tf
from seq2seq import models
from seq2seq.training import utils
model = models.BasicSeq2Seq(source_vocab_info, target_vocab_info, params)
_, losses = model(features, labels)
train_op = utils.create_train_op(losses, optimizer)
The ParlAI example showcases its focus on dialogue-specific interactions, while the seq2seq example demonstrates its lower-level approach to sequence-to-sequence modeling using TensorFlow.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
Pros of transformers
- Broader model support: Includes a wide range of pre-trained models and architectures
- Active development: Regularly updated with new features and improvements
- Extensive documentation: Comprehensive guides and examples for various tasks
Cons of transformers
- Steeper learning curve: More complex API due to its extensive feature set
- Higher resource requirements: Can be more demanding in terms of memory and computation
Code comparison
seq2seq:
import seq2seq
model = seq2seq.models.BasicSeq2Seq(vocab_size, hidden_dim)
output = model(input_sequence)
transformers:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
tokenizer = AutoTokenizer.from_pretrained("t5-small")
output = model.generate(**tokenizer(input_text, return_tensors="pt"))
Summary
transformers offers a more comprehensive and actively maintained library with support for various models and tasks. It provides extensive documentation and regular updates but may have a steeper learning curve and higher resource requirements. seq2seq, while simpler, may be more suitable for basic sequence-to-sequence tasks or when working with limited resources. The code comparison illustrates the difference in complexity and flexibility between the two libraries.
A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)
Pros of NeMo
- More actively maintained with frequent updates
- Supports a wider range of AI tasks beyond sequence-to-sequence models
- Offers pre-trained models and easy fine-tuning capabilities
Cons of NeMo
- Steeper learning curve due to more complex architecture
- Requires more computational resources for training and inference
- Less focused on pure sequence-to-sequence tasks
Code Comparison
NeMo example:
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModel.from_pretrained("QuartzNet15x5Base-En")
transcription = asr_model.transcribe(["audio_file.wav"])
seq2seq example:
import tensorflow as tf
import seq2seq
model = seq2seq.models.BasicSeq2Seq(vocab_size, embedding_dim, hidden_dim)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(x_train, y_train, epochs=10)
NeMo offers a higher-level API with pre-trained models, while seq2seq provides a more basic implementation requiring manual model definition and training. NeMo's approach is more suitable for production environments, while seq2seq is better for educational purposes and custom implementations.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

A general-purpose encoder-decoder framework for Tensorflow that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more.
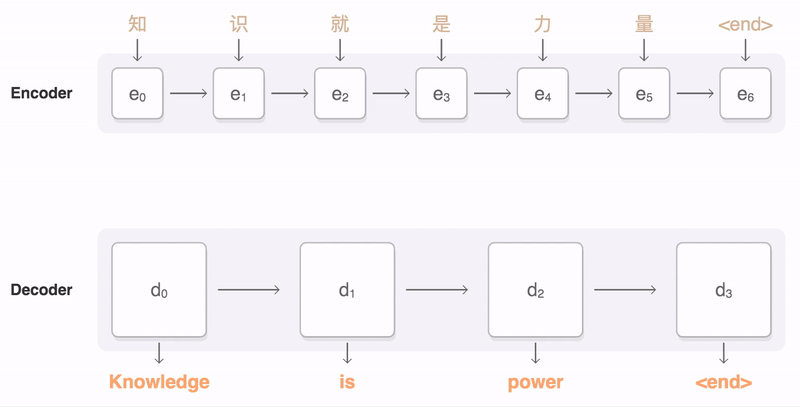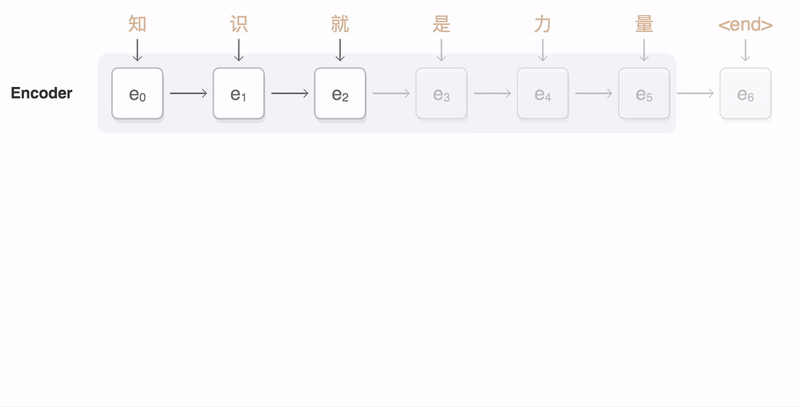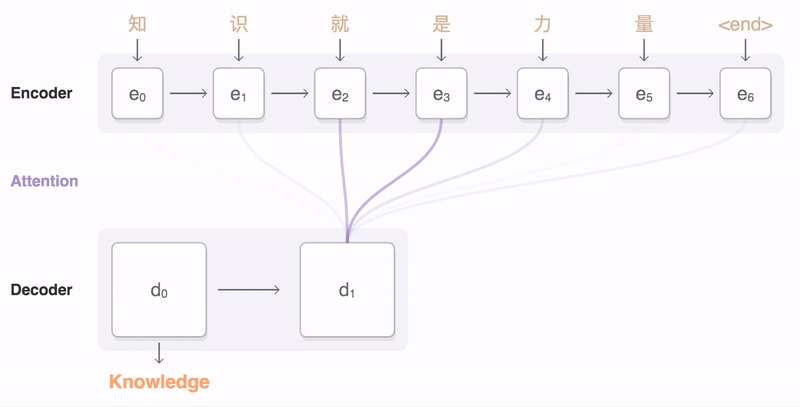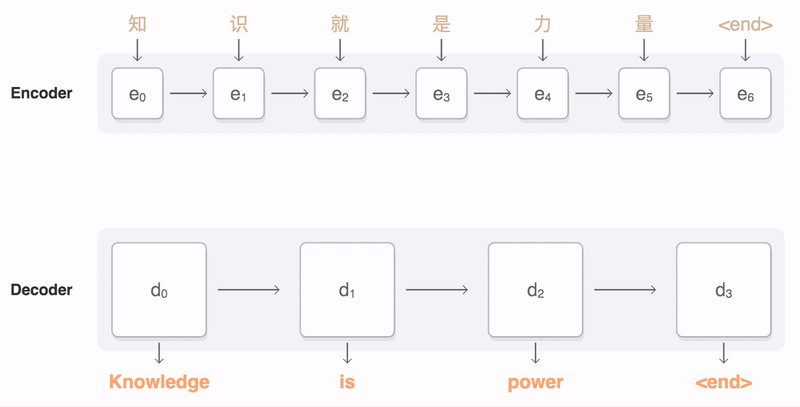
The official code used for the Massive Exploration of Neural Machine Translation Architectures paper.
If you use this code for academic purposes, please cite it as:
@ARTICLE{Britz:2017,
author = {{Britz}, Denny and {Goldie}, Anna and {Luong}, Thang and {Le}, Quoc},
title = "{Massive Exploration of Neural Machine Translation Architectures}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprinttype = {arxiv},
eprint = {1703.03906},
primaryClass = "cs.CL",
keywords = {Computer Science - Computation and Language},
year = 2017,
month = mar,
}
This is not an official Google product.
Top Related Projects
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Open Source Neural Machine Translation and (Large) Language Models in PyTorch
Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
A framework for training and evaluating AI models on a variety of openly available dialogue datasets.
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot