
Top Related Projects
♾️ CML - Continuous Machine Learning | CI/CD for ML

Data-Centric Pipelines and Data Versioning

The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.

The AI developer platform. Use Weights & Biases to train and fine-tune models, and manage models from experimentation to production.

An orchestration platform for the development, production, and observation of data assets.
Quick Overview
DVC (Data Version Control) is an open-source version control system for machine learning projects. It combines the best features of experiment management tools, ML pipelines, and data/model versioning. DVC is designed to handle large files, data sets, machine learning models, and metrics as well as code.
Pros
- Seamless integration with Git for versioning of data, models, and experiments
- Language and framework agnostic, supporting various ML tools and workflows
- Efficient storage and transfer of large files and datasets
- Reproducibility of experiments and ML pipelines
Cons
- Learning curve for users new to version control concepts
- Requires additional setup and configuration compared to traditional version control
- May have performance overhead for very large datasets or complex pipelines
- Limited built-in visualization tools compared to some specialized ML platforms
Code Examples
- Initialize DVC in a Git repository:
$ dvc init
- Add a data file to DVC:
$ dvc add data/dataset.csv
- Define and run a pipeline stage:
# dvc.yaml
stages:
train:
cmd: python train.py
deps:
- data/dataset.csv
- train.py
outs:
- model.pkl
$ dvc repro
- Push data and model to remote storage:
$ dvc push
Getting Started
- Install DVC:
$ pip install dvc
- Initialize DVC in your project:
$ git init
$ dvc init
- Add data to DVC:
$ dvc add data/large_dataset.csv
$ git add data/large_dataset.csv.dvc
$ git commit -m "Add dataset"
- Create a simple pipeline:
# dvc.yaml
stages:
preprocess:
cmd: python preprocess.py
deps:
- data/large_dataset.csv
outs:
- data/processed_data.csv
train:
cmd: python train.py
deps:
- data/processed_data.csv
outs:
- model.pkl
- Run the pipeline:
$ dvc repro
- Version your results:
$ git add .
$ git commit -m "Train model"
Competitor Comparisons
♾️ CML - Continuous Machine Learning | CI/CD for ML
Pros of CML
- Focuses on CI/CD for machine learning, integrating with popular CI platforms
- Provides automated reporting and visualization of ML metrics
- Supports cloud orchestration for running experiments on demand
Cons of CML
- More specialized for ML workflows, less versatile for general data versioning
- Requires integration with CI systems, which may add complexity
- Less mature ecosystem compared to DVC
Code Comparison
CML example:
name: train-and-report
on: [push]
jobs:
run:
runs-on: [ubuntu-latest]
steps:
- uses: actions/checkout@v2
- uses: iterative/setup-cml@v1
- run: |
pip install -r requirements.txt
python train.py
cml-publish accuracy.png --md >> report.md
cml-send-comment report.md
DVC example:
stages:
train:
cmd: python train.py
deps:
- data
- train.py
outs:
- model.pkl
evaluate:
cmd: python evaluate.py
deps:
- model.pkl
- evaluate.py
metrics:
- metrics.json:
cache: false
CML is tailored for ML workflows in CI/CD environments, while DVC offers broader data and model versioning capabilities. CML excels in automated reporting and cloud orchestration, whereas DVC provides more comprehensive version control for data science projects.
Data-Centric Pipelines and Data Versioning
Pros of Pachyderm
- Built-in data lineage and versioning at a container level
- Native support for distributed processing and scalability
- Integrated with Kubernetes for easier deployment and management
Cons of Pachyderm
- Steeper learning curve due to more complex architecture
- Requires more infrastructure setup and maintenance
- Less flexible for smaller projects or individual developers
Code Comparison
DVC example:
import dvc.api
with dvc.api.open('data/features.csv') as f:
# Process the data
pass
Pachyderm example:
import python_pachyderm
client = python_pachyderm.Client()
with client.get_file('data', 'features.csv') as f:
# Process the data
pass
Key Differences
- DVC is more lightweight and easier to integrate into existing workflows
- Pachyderm offers more robust versioning and lineage tracking
- DVC focuses on ML experiments, while Pachyderm targets general data processing
- Pachyderm provides built-in scalability, whereas DVC relies on external tools
- DVC has a larger community and more integrations with popular ML frameworks
Both tools aim to solve data versioning and reproducibility challenges, but they cater to different scales and use cases. DVC is more suitable for individual data scientists and smaller teams, while Pachyderm is better suited for larger organizations with complex data pipelines and infrastructure.
The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.
Pros of MLflow
- More comprehensive end-to-end ML lifecycle management
- Better support for experiment tracking and model registry
- Easier integration with various ML frameworks and cloud platforms
Cons of MLflow
- Steeper learning curve due to more complex features
- Heavier resource usage, especially for smaller projects
- Less focus on data versioning compared to DVC
Code Comparison
MLflow:
import mlflow
mlflow.start_run()
mlflow.log_param("param1", value1)
mlflow.log_metric("metric1", value2)
mlflow.end_run()
DVC:
dvc add data.csv
dvc run -n train -d data.csv -o model.pkl python train.py
dvc push
MLflow provides a more integrated approach for tracking experiments and managing models, while DVC focuses on data and pipeline versioning. MLflow's code is typically used within Python scripts, whereas DVC is often used via command-line interface for data and pipeline management.
Both tools have their strengths, with MLflow excelling in comprehensive ML lifecycle management and DVC specializing in data version control and reproducible pipelines. The choice between them depends on specific project requirements and team preferences.
The AI developer platform. Use Weights & Biases to train and fine-tune models, and manage models from experimentation to production.
Pros of Wandb
- More comprehensive experiment tracking and visualization tools
- Easier integration with cloud services for collaborative projects
- Better support for deep learning frameworks and hyperparameter tuning
Cons of Wandb
- Requires internet connection for full functionality
- Less focus on version control for datasets and models
- Steeper learning curve for beginners
Code Comparison
Wandb:
import wandb
wandb.init(project="my-project")
wandb.config.hyperparameters = {
"learning_rate": 0.01,
"epochs": 100
}
wandb.log({"accuracy": 0.9, "loss": 0.1})
DVC:
import dvc.api
with dvc.api.open('data/features.csv') as f:
# Process data
pass
os.system('dvc add data/features.csv')
os.system('dvc push')
Wandb focuses on experiment tracking and visualization, while DVC emphasizes version control for data and models. Wandb provides more comprehensive tools for monitoring and analyzing machine learning experiments, making it suitable for complex projects and team collaborations. DVC, on the other hand, excels in managing data pipelines and versioning large datasets, which is particularly useful for reproducibility and data-centric workflows.
An orchestration platform for the development, production, and observation of data assets.
Pros of Dagster
- More comprehensive data orchestration platform, offering end-to-end pipeline management
- Better integration with modern data stack tools like dbt, Spark, and Airflow
- Stronger focus on observability and monitoring of data pipelines
Cons of Dagster
- Steeper learning curve due to its more complex architecture
- Potentially overkill for simpler data versioning and tracking needs
- Less focus on experiment tracking and model versioning
Code Comparison
DVC:
import dvc.api
with dvc.api.open('data/features.csv', mode='r') as f:
# Process the data
data = f.read()
Dagster:
from dagster import job, op
@op
def process_data():
# Process the data
pass
@job
def my_data_job():
process_data()
Both DVC and Dagster serve different primary purposes in the data ecosystem. DVC focuses on data and model versioning, while Dagster is a more comprehensive data orchestration platform. The choice between them depends on specific project needs and complexity.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
|Banner|
Website <https://dvc.org>_
⢠Docs <https://dvc.org/doc>_
⢠Blog <http://blog.dataversioncontrol.com>_
⢠Tutorial <https://dvc.org/doc/get-started>_
⢠Related Technologies <https://dvc.org/doc/user-guide/related-technologies>_
⢠How DVC works_
⢠VS Code Extension_
⢠Installation_
⢠Contributing_
⢠Community and Support_
|CI| |Python Version| |Coverage| |VS Code| |DOI|
|PyPI| |PyPI Downloads| |Packages| |Brew| |Conda| |Choco| |Snap|
|
Data Version Control or DVC is a command line tool and VS Code Extension_ to help you develop reproducible machine learning projects:
#. Version your data and models. Store them in your cloud storage but keep their version info in your Git repo.
#. Iterate fast with lightweight pipelines. When you make changes, only run the steps impacted by those changes.
#. Track experiments in your local Git repo (no servers needed).
#. Compare any data, code, parameters, model, or performance plots.
#. Share experiments and automatically reproduce anyone's experiment.
Quick start
Please read our `Command Reference <https://dvc.org/doc/command-reference>`_ for a complete list.
A common CLI workflow includes:
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Task | Terminal |
+===================================+====================================================================================================+
| Track data | | $ git add train.py params.yaml |
| | | $ dvc add images/ |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Connect code and data | | $ dvc stage add -n featurize -d images/ -o features/ python featurize.py |
| | | $ dvc stage add -n train -d features/ -d train.py -o model.p -M metrics.json python train.py |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Make changes and experiment | | $ dvc exp run -n exp-baseline |
| | | $ vi train.py |
| | | $ dvc exp run -n exp-code-change |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Compare and select experiments | | $ dvc exp show |
| | | $ dvc exp apply exp-baseline |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Share code | | $ git add . |
| | | $ git commit -m 'The baseline model' |
| | | $ git push |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
| Share data and ML models | | $ dvc remote add myremote -d s3://mybucket/image_cnn |
| | | $ dvc push |
+-----------------------------------+----------------------------------------------------------------------------------------------------+
How DVC works
We encourage you to read our `Get Started
<https://dvc.org/doc/get-started>`_ docs to better understand what DVC
does and how it can fit your scenarios.
The closest analogies to describe the main DVC features are these:
#. Git for data: Store and share data artifacts (like Git-LFS but without a server) and models, connecting them with a Git repository. Data management meets GitOps! #. Makefiles for ML: Describes how data or model artifacts are built from other data and code in a standard format. Now you can version your data pipelines with Git. #. Local experiment tracking: Turn your machine into an ML experiment management platform, and collaborate with others using existing Git hosting (Github, Gitlab, etc.).
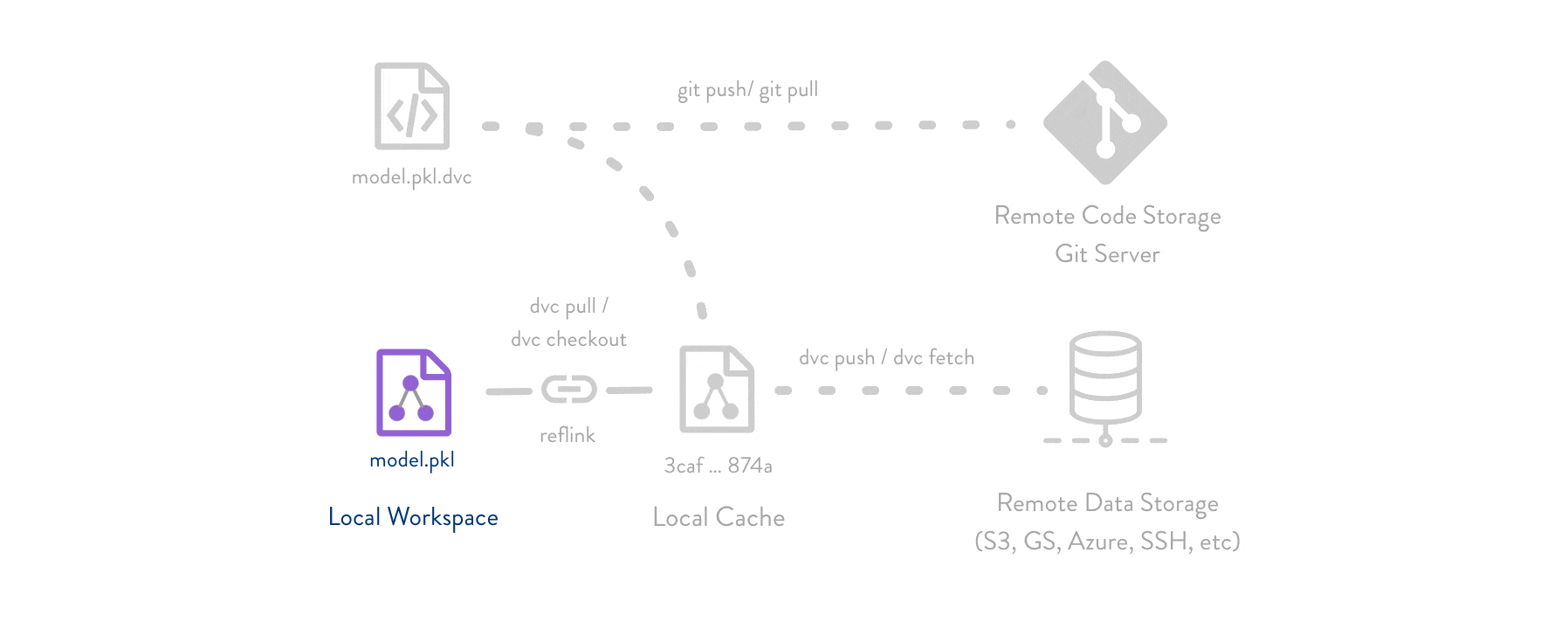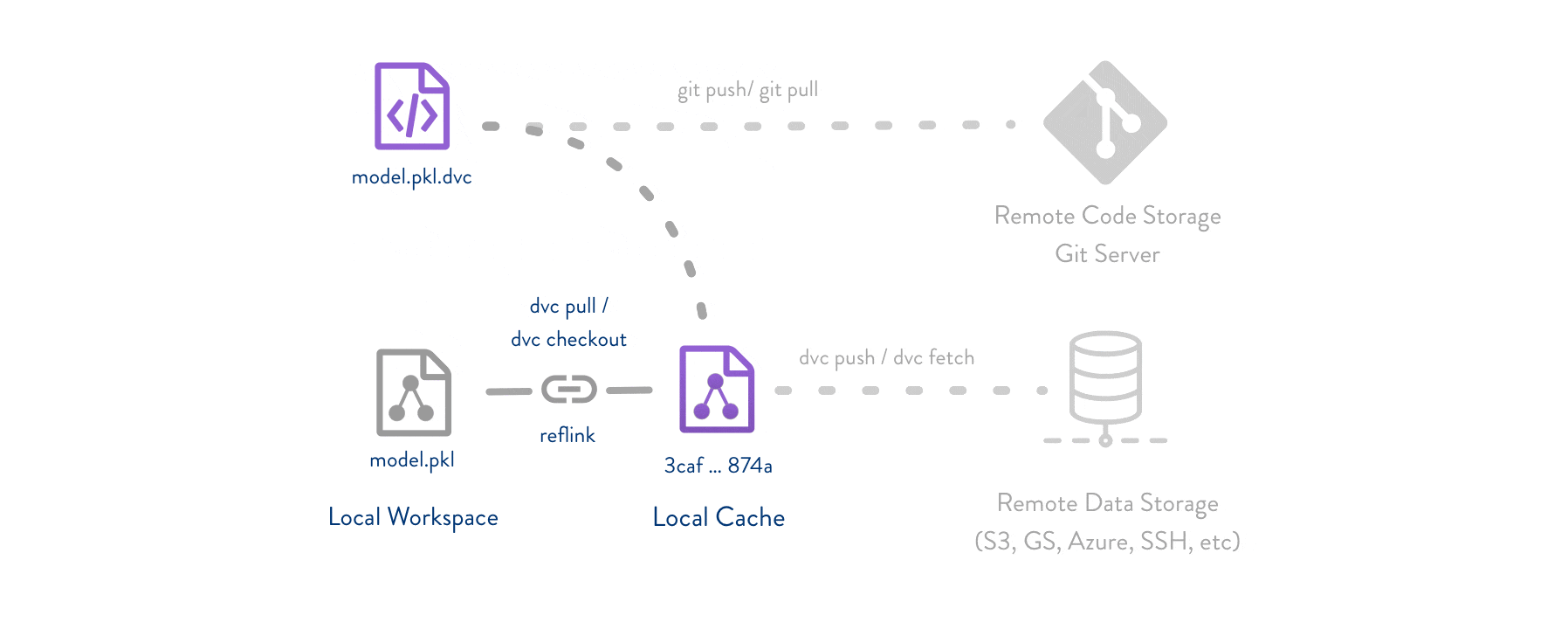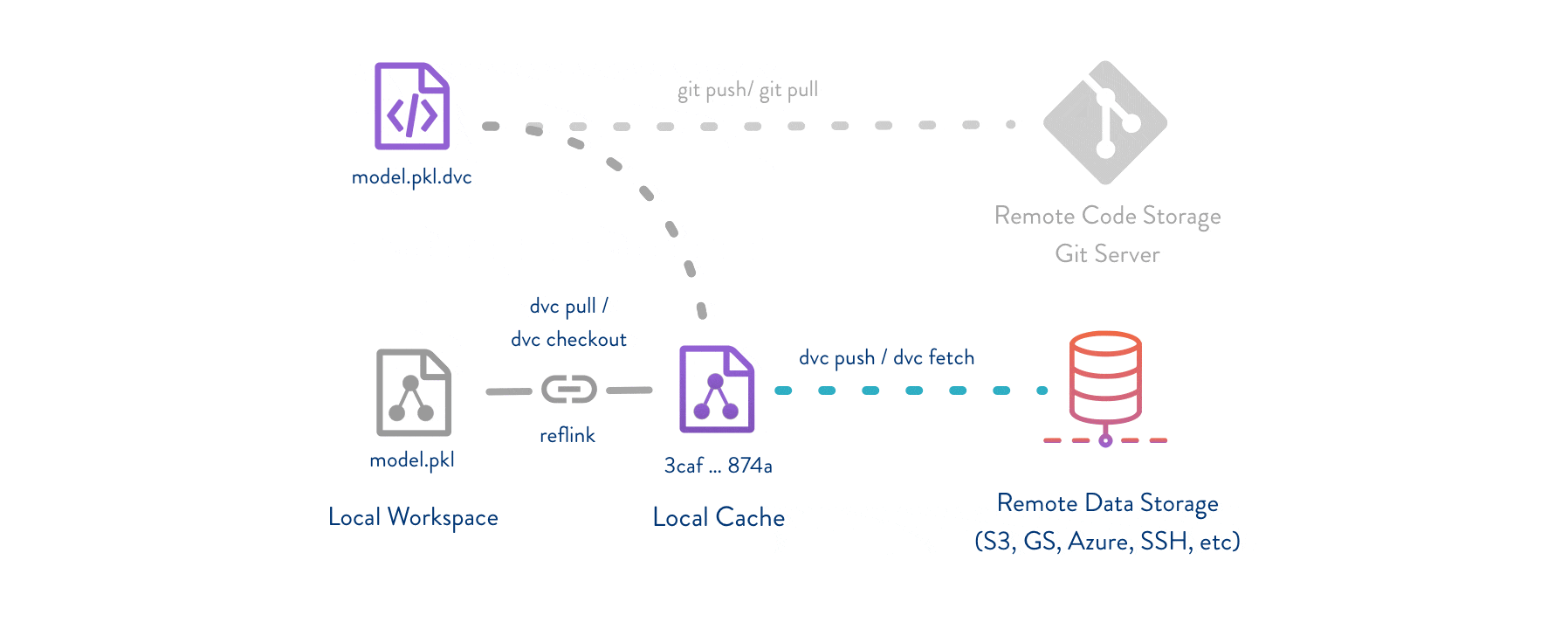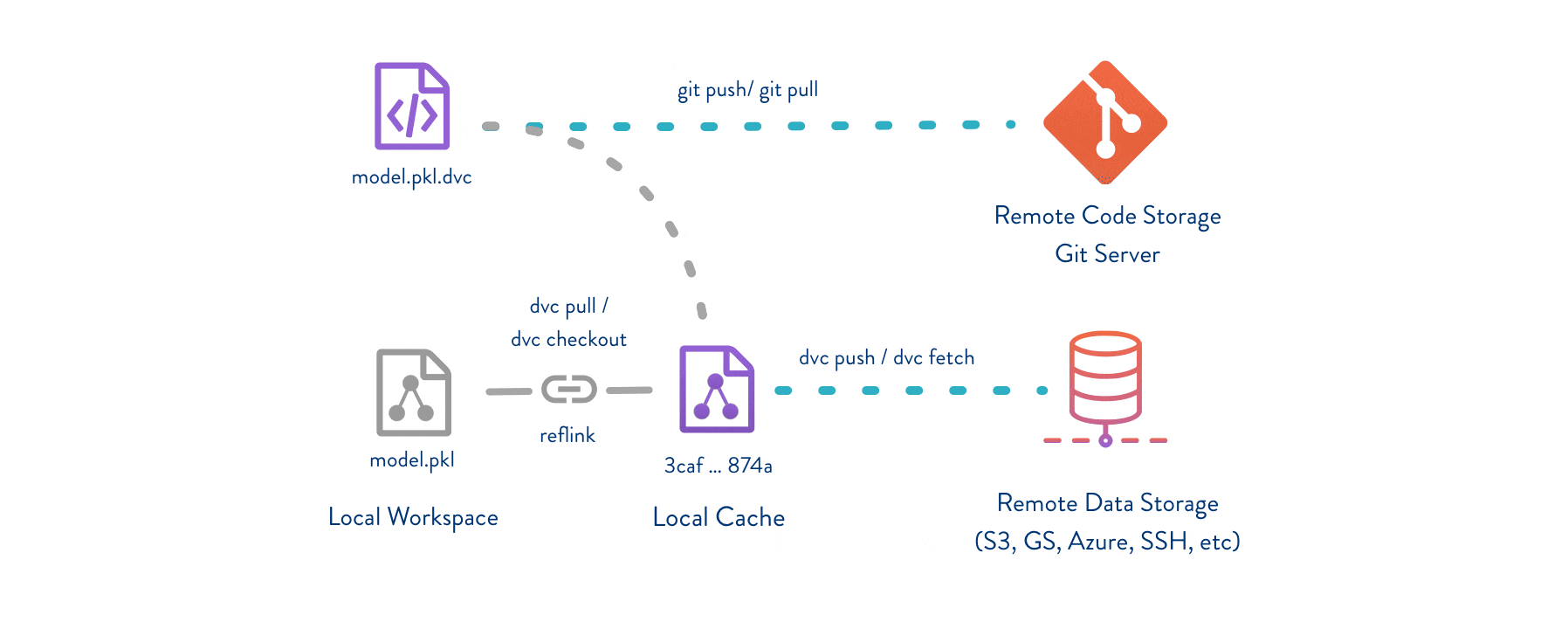
Git is employed as usual to store and version code (including DVC meta-files as placeholders for data).
DVC stores data and model files <https://dvc.org/doc/start/data-management>_ seamlessly in a cache outside of Git, while preserving almost the same user experience as if they were in the repo.
To share and back up the data cache, DVC supports multiple remote storage platforms - any cloud (S3, Azure, Google Cloud, etc.) or on-premise network storage (via SSH, for example).
|Flowchart|
DVC pipelines <https://dvc.org/doc/start/data-management/data-pipelines>_ (computational graphs) connect code and data together.
They specify all steps required to produce a model: input dependencies including code, data, commands to run; and output information to be saved.
Last but not least, DVC Experiment Versioning <https://dvc.org/doc/start/experiments>_ lets you prepare and run a large number of experiments.
Their results can be filtered and compared based on hyperparameters and metrics, and visualized with multiple plots.
.. _VS Code Extension:
VS Code Extension
|VS Code|
To use DVC as a GUI right from your VS Code IDE, install the DVC Extension <https://marketplace.visualstudio.com/items?itemName=Iterative.dvc>_ from the Marketplace.
It currently features experiment tracking and data management, and more features (data pipeline support, etc.) are coming soon!
|VS Code Extension Overview|
Note: You'll have to install core DVC on your system separately (as detailed
below). The Extension will guide you if needed.
Installation
There are several ways to install DVC: in VS Code; using snap, choco, brew, conda, pip; or with an OS-specific package.
Full instructions are available here <https://dvc.org/doc/get-started/install>_.
Snapcraft (Linux)
|Snap|
.. code-block:: bash
snap install dvc --classic
This corresponds to the latest tagged release.
Add --beta for the latest tagged release candidate, or --edge for the latest main version.
Chocolatey (Windows)
|Choco|
.. code-block:: bash
choco install dvc
Brew (mac OS)
|Brew|
.. code-block:: bash
brew install dvc
Anaconda (Any platform)
|Conda|
.. code-block:: bash
conda install -c conda-forge mamba # installs much faster than conda mamba install -c conda-forge dvc
Depending on the remote storage type you plan to use to keep and share your data, you might need to install optional dependencies: dvc-s3, dvc-azure, dvc-gdrive, dvc-gs, dvc-oss, dvc-ssh.
PyPI (Python)
|PyPI|
.. code-block:: bash
pip install dvc
Depending on the remote storage type you plan to use to keep and share your data, you might need to specify one of the optional dependencies: s3, gs, azure, oss, ssh. Or all to include them all.
The command should look like this: pip install 'dvc[s3]' (in this case AWS S3 dependencies such as boto3 will be installed automatically).
To install the development version, run:
.. code-block:: bash
pip install git+git://github.com/iterative/dvc
Package (Platform-specific)
|Packages|
Self-contained packages for Linux, Windows, and Mac are available.
The latest version of the packages can be found on the GitHub releases page <https://github.com/iterative/dvc/releases>_.
Ubuntu / Debian (deb) ^^^^^^^^^^^^^^^^^^^^^ .. code-block:: bash
sudo wget https://dvc.org/deb/dvc.list -O /etc/apt/sources.list.d/dvc.list wget -qO - https://dvc.org/deb/iterative.asc | sudo apt-key add - sudo apt update sudo apt install dvc
Fedora / CentOS (rpm) ^^^^^^^^^^^^^^^^^^^^^ .. code-block:: bash
sudo wget https://dvc.org/rpm/dvc.repo -O /etc/yum.repos.d/dvc.repo sudo rpm --import https://dvc.org/rpm/iterative.asc sudo yum update sudo yum install dvc
Contributing
|Maintainability|
Contributions are welcome!
Please see our Contributing Guide <https://dvc.org/doc/user-guide/contributing/core>_ for more details.
Thanks to all our contributors!
|Contribs|
Community and Support
Twitter <https://twitter.com/DVCorg>_Forum <https://discuss.dvc.org/>_Discord Chat <https://dvc.org/chat>_Email <mailto:support@dvc.org>_Mailing List <https://dvc.org/community#subscribe>_
Copyright
This project is distributed under the Apache license version 2.0 (see the LICENSE file in the project root).
By submitting a pull request to this project, you agree to license your contribution under the Apache license version 2.0 to this project.
Citation
|DOI|
Iterative, DVC: Data Version Control - Git for Data & Models (2020)
DOI:10.5281/zenodo.012345 <https://doi.org/10.5281/zenodo.3677553>_.
Barrak, A., Eghan, E.E. and Adams, B. On the Co-evolution of ML Pipelines and Source Code - Empirical Study of DVC Projects <https://mcis.cs.queensu.ca/publications/2021/saner.pdf>_ , in Proceedings of the 28th IEEE International Conference on Software Analysis, Evolution, and Reengineering, SANER 2021. Hawaii, USA.
.. |Banner| image:: https://dvc.org/img/logo-github-readme.png :target: https://dvc.org :alt: DVC logo
{kind=link}
.. |VS Code Extension Overview| image:: https://raw.githubusercontent.com/iterative/vscode-dvc/main/extension/docs/overview.gif :alt: DVC Extension for VS Code
{kind=link}
.. |CI| image:: https://github.com/iterative/dvc/actions/workflows/tests.yaml/badge.svg :target: https://github.com/iterative/dvc/actions/workflows/tests.yaml :alt: GHA Tests
{kind=link}
.. |Maintainability| image:: https://img.shields.io/codeclimate/maintainability/iterative/dvc :target: https://codeclimate.com/github/iterative/dvc :alt: Code Climate
.. |Python Version| image:: https://img.shields.io/pypi/pyversions/dvc :target: https://pypi.org/project/dvc :alt: Python Version
.. |Coverage| image:: https://codecov.io/gh/iterative/dvc/branch/main/graph/badge.svg :target: https://codecov.io/gh/iterative/dvc :alt: Codecov
{kind=link}
.. |Snap| image:: https://img.shields.io/badge/snap-install-82BEA0.svg?logo=snapcraft :target: https://snapcraft.io/dvc :alt: Snapcraft
{kind=link}
.. |Choco| image:: https://img.shields.io/chocolatey/v/dvc?label=choco :target: https://chocolatey.org/packages/dvc :alt: Chocolatey
.. |Brew| image:: https://img.shields.io/homebrew/v/dvc?label=brew :target: https://formulae.brew.sh/formula/dvc :alt: Homebrew
.. |Conda| image:: https://anaconda.org/conda-forge/dvc/badges/version.svg :target: https://anaconda.org/conda-forge/dvc :alt: Conda-forge
{kind=link}
.. |PyPI| image:: https://img.shields.io/pypi/v/dvc.svg?label=pip&logo=PyPI&logoColor=white :target: https://pypi.org/project/dvc :alt: PyPI
{kind=link}
.. |PyPI Downloads| image:: https://img.shields.io/pypi/dm/dvc.svg?color=blue&label=Downloads&logo=pypi&logoColor=gold :target: https://pypi.org/project/dvc :alt: PyPI Downloads
{kind=link}
.. |Packages| image:: https://img.shields.io/badge/deb|pkg|rpm|exe-blue :target: https://dvc.org/doc/install :alt: deb|pkg|rpm|exe
.. |DOI| image:: https://img.shields.io/badge/DOI-10.5281/zenodo.3677553-blue.svg :target: https://doi.org/10.5281/zenodo.3677553 :alt: DOI
{kind=link}
.. |Flowchart| image:: https://dvc.org/img/flow.gif :target: https://dvc.org/img/flow.gif :alt: how_dvc_works
{kind=link}
.. |Contribs| image:: https://contrib.rocks/image?repo=iterative/dvc :target: https://github.com/iterative/dvc/graphs/contributors :alt: Contributors
.. |VS Code| image:: https://img.shields.io/visual-studio-marketplace/v/Iterative.dvc?color=blue&label=VSCode&logo=visualstudiocode&logoColor=blue :target: https://marketplace.visualstudio.com/items?itemName=Iterative.dvc :alt: VS Code Extension
Top Related Projects
♾️ CML - Continuous Machine Learning | CI/CD for ML
Data-Centric Pipelines and Data Versioning
The open source developer platform to build AI/LLM applications and models with confidence. Enhance your AI applications with end-to-end tracking, observability, and evaluations, all in one integrated platform.
The AI developer platform. Use Weights & Biases to train and fine-tune models, and manage models from experimentation to production.
An orchestration platform for the development, production, and observation of data assets.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot