
Top Related Projects
Magenta: Music and Art Generation with Machine Intelligence

Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable music generation LM with textual and melodic conditioning.

A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)

C++ library for audio and music analysis, description and synthesis, including Python bindings

Python library for audio and music analysis
Quick Overview
DDSP (Differentiable Digital Signal Processing) is an open-source library for audio synthesis and manipulation using machine learning. It provides a set of differentiable DSP functions that can be used to create complex audio effects and synthesizers, which can be trained end-to-end within deep learning models.
Pros
- Enables the creation of interpretable and controllable audio models
- Combines traditional DSP techniques with modern machine learning approaches
- Supports real-time audio generation and manipulation
- Integrates well with TensorFlow and other machine learning frameworks
Cons
- Steep learning curve for those unfamiliar with both DSP and machine learning
- Limited documentation and examples for advanced use cases
- May require significant computational resources for training complex models
- Relatively new project, still evolving and may have breaking changes
Code Examples
- Creating a simple sine oscillator:
import ddsp
# Create a sine oscillator
oscillator = ddsp.synths.Oscillator(
frequencies=440,
amplitudes=0.5,
harmonic_distribution=[1.0, 0.0, 0.0, 0.0]
)
# Generate audio
audio = oscillator(length=16000)
- Applying a filter to an audio signal:
import ddsp
import numpy as np
# Create an input audio signal
audio_input = np.random.uniform(-1, 1, (16000,))
# Apply a lowpass filter
filtered_audio = ddsp.effects.FilteredNoise(
audio=audio_input,
n_samples=16000,
window_size=257,
scale_fn=ddsp.core.exp_sigmoid,
initial_bias=-5.0
)
- Training a simple autoencoder model:
import ddsp
import tensorflow as tf
# Create a simple autoencoder model
encoder = tf.keras.Sequential([
tf.keras.layers.Input(shape=(16000,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu')
])
decoder = ddsp.processors.Reverb(trainable=True)
# Define the model
model = tf.keras.Model(inputs=encoder.input, outputs=decoder(encoder.output))
# Compile and train the model
model.compile(optimizer='adam', loss='mse')
model.fit(x_train, y_train, epochs=10, batch_size=32)
Getting Started
To get started with DDSP, follow these steps:
- Install the library:
pip install ddsp
- Import the necessary modules:
import ddsp
import ddsp.training
- Load a pre-trained model or create your own:
# Load a pre-trained model
model = ddsp.training.models.Autoencoder()
model.restore('path/to/pretrained/model')
# Or create your own model
model = ddsp.training.models.Autoencoder(
preprocessor=ddsp.training.preprocessing.DefaultPreprocessor(),
encoder=ddsp.training.encoders.MfccTimeDistributedRnnEncoder(),
decoder=ddsp.training.decoders.RnnFcDecoder(),
processor_group=ddsp.processors.ProcessorGroup(
[ddsp.synths.Additive(),
ddsp.effects.FilteredNoise(),
ddsp.effects.Reverb()])
)
- Generate audio or process existing audio:
# Generate audio
audio = model.generate(f0_hz, loudness_db, features)
# Process existing audio
processed_audio = model(input_audio)
Competitor Comparisons
Magenta: Music and Art Generation with Machine Intelligence
Pros of Magenta
- Broader scope, covering various music and art generation tasks
- Larger community and more extensive documentation
- Integrates with TensorFlow, offering a wide range of machine learning tools
Cons of Magenta
- Steeper learning curve due to its broader focus
- Potentially heavier resource requirements for some tasks
- May include unnecessary components for users focused solely on audio synthesis
Code Comparison
Magenta (music generation):
melody = music_vae.sample(
n=1,
length=64,
temperature=1.0)
DDSP (audio synthesis):
audio = processor(inputs={
'f0_hz': f0_hz,
'loudness_db': loudness_db
})
Key Differences
- DDSP focuses specifically on differentiable digital signal processing
- Magenta offers a wider range of creative AI tools beyond audio
- DDSP provides more fine-grained control over audio synthesis parameters
- Magenta includes pre-trained models for various music generation tasks
Use Cases
- Choose Magenta for diverse music and art generation projects
- Opt for DDSP when working specifically with audio synthesis and manipulation
- Consider DDSP for more precise control over audio parameters
- Use Magenta if you need integration with other TensorFlow-based tools
Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable music generation LM with textual and melodic conditioning.
Pros of Audiocraft
- More comprehensive audio generation capabilities, including music and sound effects
- Advanced AI models like MusicGen and AudioGen for high-quality audio synthesis
- Active development with recent updates and contributions
Cons of Audiocraft
- Steeper learning curve due to more complex architecture
- Requires more computational resources for training and inference
- Less focus on real-time audio processing compared to DDSP
Code Comparison
DDSP (Differential Digital Signal Processing):
import ddsp
import ddsp.training
# Create a DDSP processor
processor = ddsp.processors.Additive()
# Generate audio
audio = processor(frequencies, amplitudes, harmonic_distribution)
Audiocraft:
from audiocraft.models import MusicGen
# Load a pre-trained MusicGen model
model = MusicGen.get_pretrained('medium')
# Generate music
wav = model.generate(
descriptions=['happy rock'],
duration=10,
)
Both repositories focus on audio synthesis, but Audiocraft offers more advanced AI-driven generation capabilities, while DDSP emphasizes real-time audio processing and manipulation using differentiable DSP techniques. Audiocraft is better suited for complex audio generation tasks, while DDSP excels in low-latency audio processing and synthesis.
A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)
Pros of NeMo
- Broader scope: Covers various AI domains including ASR, NLP, and TTS
- Better scalability: Designed for large-scale model training and deployment
- More extensive documentation and examples
Cons of NeMo
- Steeper learning curve due to its comprehensive nature
- Heavier resource requirements for full utilization
- Less focused on specific audio synthesis tasks compared to DDSP
Code Comparison
DDSP (Audio synthesis):
import ddsp
import ddsp.training
synth = ddsp.synths.Additive()
audio = synth(frequencies, amplitudes, harmonic_distribution)
NeMo (Speech recognition example):
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModel.from_pretrained("QuartzNet15x5Base-En")
transcription = asr_model.transcribe(["audio_file.wav"])
Summary
DDSP focuses specifically on differentiable digital signal processing for audio synthesis, while NeMo is a more comprehensive toolkit for various AI tasks. DDSP may be more suitable for specialized audio projects, whereas NeMo offers a broader range of capabilities for large-scale AI applications across multiple domains.
C++ library for audio and music analysis, description and synthesis, including Python bindings
Pros of Essentia
- Broader scope of audio analysis tools and algorithms
- More mature project with longer development history
- Extensive documentation and examples
Cons of Essentia
- Steeper learning curve due to its comprehensive nature
- Less focus on neural synthesis compared to DDSP
- Requires C++ knowledge for advanced usage
Code Comparison
DDSP (Python):
import ddsp
import ddsp.training
synth = ddsp.synths.Additive()
audio = synth(frequencies, amplitudes, harmonic_distribution)
Essentia (C++):
#include <essentia/algorithmfactory.h>
#include <essentia/essentiamath.h>
Algorithm* spectralPeaks = AlgorithmFactory::create("SpectralPeaks");
vector<Real> frequencies, magnitudes;
spectralPeaks->input("spectrum").set(spectrum);
spectralPeaks->output("frequencies").set(frequencies);
spectralPeaks->output("magnitudes").set(magnitudes);
spectralPeaks->compute();
Summary
Essentia offers a comprehensive suite of audio analysis tools with a long development history, while DDSP focuses more on neural audio synthesis. Essentia provides broader functionality but may require more expertise to use effectively. DDSP offers a more streamlined approach to specific audio tasks using machine learning techniques.
Python library for audio and music analysis
Pros of librosa
- Broader focus on general audio and music processing tasks
- Extensive documentation and tutorials for beginners
- Larger community and more widespread adoption in audio research
Cons of librosa
- Less specialized for neural audio synthesis
- May require additional libraries for advanced machine learning tasks
- Potentially slower performance for certain operations compared to DDSP
Code Comparison
librosa example:
import librosa
y, sr = librosa.load('audio.wav')
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
DDSP example:
import ddsp
audio = ddsp.core.oscillator(frequencies, amplitudes)
filtered_audio = ddsp.processors.FilteredNoise(audio)
reverb_audio = ddsp.effects.Reverb()(filtered_audio)
Both libraries offer powerful audio processing capabilities, but DDSP is more focused on neural audio synthesis and manipulation, while librosa provides a broader set of tools for music and audio analysis. DDSP integrates more seamlessly with machine learning workflows, particularly those involving TensorFlow, while librosa is often favored for its simplicity and extensive documentation in general audio processing tasks.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
DDSP: Differentiable Digital Signal Processing
![]()
Demos | Tutorials | Installation | Overview | Blog Post | Papers
DDSP is a library of differentiable versions of common DSP functions (such as synthesizers, waveshapers, and filters). This allows these interpretable elements to be used as part of an deep learning model, especially as the output layers for audio generation.
Getting Started
First, follow the steps in the Installation section to install the DDSP package and its dependencies. DDSP modules can be used to generate and manipulate audio from neural network outputs as in this simple example:
import ddsp
# Get synthesizer parameters from a neural network.
outputs = network(inputs)
# Initialize signal processors.
harmonic = ddsp.synths.Harmonic()
# Generates audio from harmonic synthesizer.
audio = harmonic(outputs['amplitudes'],
outputs['harmonic_distribution'],
outputs['f0_hz'])
Links
- Check out the blog post ð»
- Read the original paper ð
- Listen to some examples ð
- Try out the timbre transfer demo ð¤->ð»
Demos
Colab notebooks demonstrating some of the neat things you can do with DDSP ddsp/colab/demos
-
Timbre Transfer: Convert audio between sound sources with pretrained models. Try turning your voice into a violin, or scratching your laptop and seeing how it sounds as a flute :). Pick from a selection of pretrained models or upload your own that you can train with the
train_autoencoderdemo. -
Train Autoencoder: Takes you through all the steps to convert audio files into a dataset and train your own DDSP autoencoder model. You can transfer data and models to/from google drive, and download a .zip file of your trained model to be used with the
timbre_transferdemo. -
Pitch Detection: Demonstration of self-supervised pitch detection models from the 2020 ICML Workshop paper.
Tutorials
To introduce the main concepts of the library, we have step-by-step colab tutorials for all the major library components
ddsp/colab/tutorials.
- 0_processor: Introduction to the Processor class.
- 1_synths_and_effects: Example usage of processors.
- 2_processor_group: Stringing processors together in a ProcessorGroup.
- 3_training: Example of training on a single sound.
- 4_core_functions: Extensive examples for most of the core DDSP functions.
Modules
The DDSP library consists of a core library (ddsp/) and a self-contained training library (ddsp/training/). The core library is split up into into several modules:
- Core: All the differentiable DSP functions.
- Processors: Base classes for Processor and ProcessorGroup.
- Synths: Processors that generate audio from network outputs.
- Effects: Processors that transform audio according to network outputs.
- Losses: Loss functions relevant to DDSP applications.
- Spectral Ops: Helper library of Fourier and related transforms.
Besides the tutorials, each module has its own test file that can be helpful for examples of usage.
Installation
Requires tensorflow version >= 2.1.0, but the core library runs in either eager or graph mode.
sudo apt-get install libsndfile-dev
pip install --upgrade pip
pip install --upgrade ddsp
Overview
Processor
The Processor is the main object type and preferred API of the DDSP library. It inherits from tfkl.Layer and can be used like any other differentiable module.
Unlike other layers, Processors (such as Synthesizers and Effects) specifically format their inputs into controls that are physically meaningful.
For instance, a synthesizer might need to remove frequencies above the Nyquist frequency to avoid aliasing or ensure that its amplitudes are strictly positive. To this end, they have the methods:
get_controls(): inputs -> controls.get_signal(): controls -> signal.__call__(): inputs -> signal. (i.e.get_signal(**get_controls()))
Where:
inputsis a variable number of tensor arguments (depending on processor). Often the outputs of a neural network.controlsis a dictionary of tensors scaled and constrained specifically for the processor.signalis an output tensor (usually audio or control signal for another processor).
For example, here are of some inputs to an Harmonic() synthesizer:
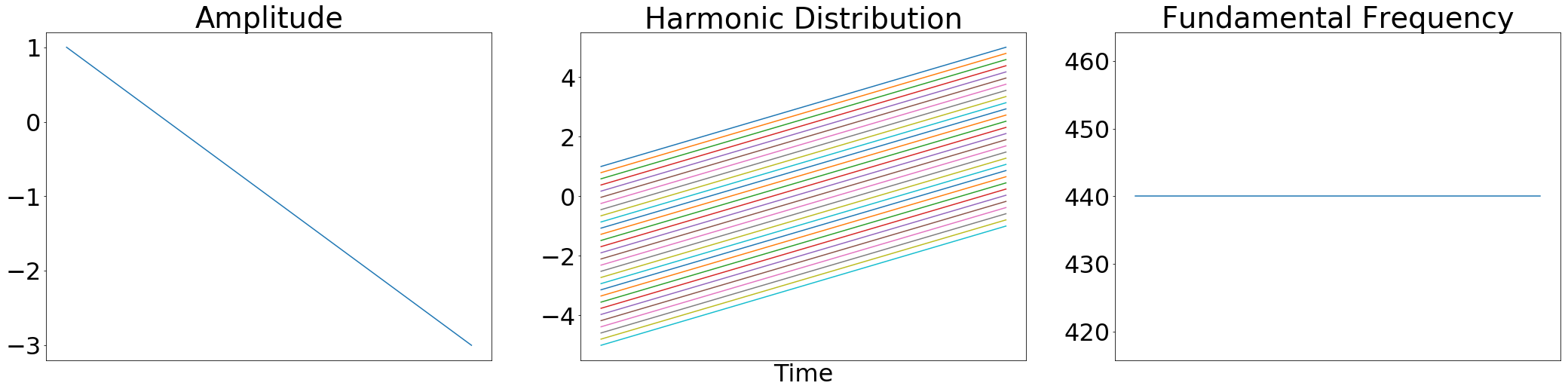
And here are the resulting controls after logarithmically scaling amplitudes, removing harmonics above the Nyquist frequency, and normalizing the remaining harmonic distribution:
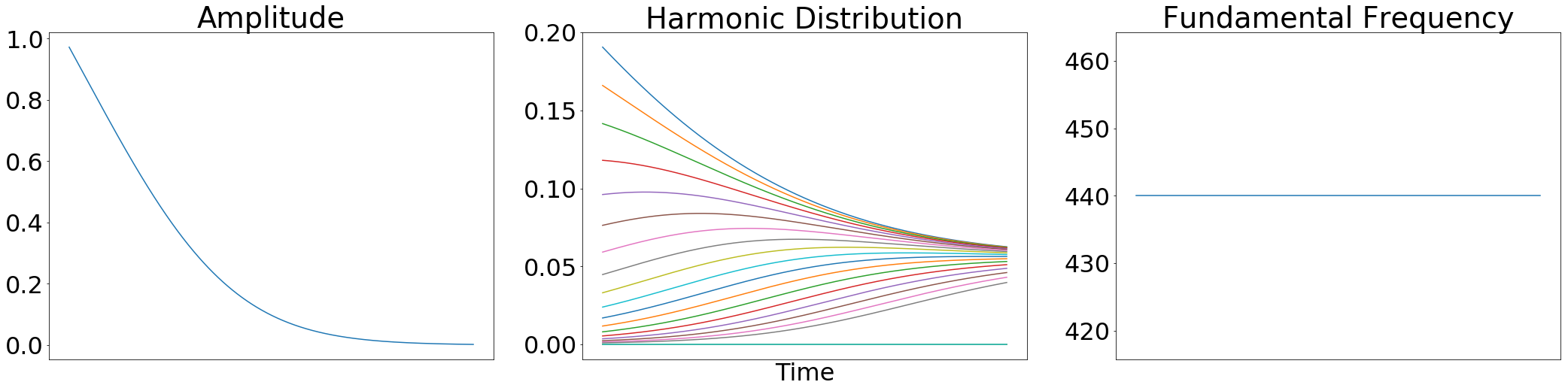
Notice that only 18 harmonics are nonzero (sample rate 16kHz, Nyquist 8kHz, 18*440=7920Hz) and they sum to 1.0 at all times
ProcessorGroup
Consider the situation where you want to string together a group of Processors.
Since Processors are just instances of tfkl.Layer you could use python control flow,
as you would with any other differentiable modules.
In the example below, we have an audio autoencoder that uses a differentiable harmonic+noise synthesizer with reverb to generate audio for a multi-scale spectrogram reconstruction loss.
import ddsp
# Get synthesizer parameters from the input audio.
outputs = network(audio_input)
# Initialize signal processors.
harmonic = ddsp.synths.Harmonic()
filtered_noise = ddsp.synths.FilteredNoise()
reverb = ddsp.effects.TrainableReverb()
spectral_loss = ddsp.losses.SpectralLoss()
# Generate audio.
audio_harmonic = harmonic(outputs['amplitudes'],
outputs['harmonic_distribution'],
outputs['f0_hz'])
audio_noise = filtered_noise(outputs['magnitudes'])
audio = audio_harmonic + audio_noise
audio = reverb(audio)
# Multi-scale spectrogram reconstruction loss.
loss = spectral_loss(audio, audio_input)
ProcessorGroup (with a list)
A ProcessorGroup allows specifies a as a Directed Acyclic Graph (DAG) of processors. The main advantage of using a ProcessorGroup is that the entire signal processing chain can be specified in a .gin file, removing the need to write code in python for every different configuration of processors.
You can specify the DAG as a list of tuples dag = [(processor, ['input1', 'input2', ...]), ...] where processor is an Processor instance, and ['input1', 'input2', ...] is a list of strings specifying input arguments. The output signal of each processor can be referenced as an input by the string 'processor_name/signal' where processor_name is the name of the processor at construction. The ProcessorGroup takes a dictionary of inputs, who keys can be referenced in the DAG.
import ddsp
import gin
# Get synthesizer parameters from the input audio.
outputs = network(audio_input)
# Initialize signal processors.
harmonic = ddsp.synths.Harmonic()
filtered_noise = ddsp.synths.FilteredNoise()
add = ddsp.processors.Add()
reverb = ddsp.effects.TrainableReverb()
spectral_loss = ddsp.losses.SpectralLoss()
# Processor group DAG
dag = [
(harmonic,
['amps', 'harmonic_distribution', 'f0_hz']),
(filtered_noise,
['magnitudes']),
(add,
['harmonic/signal', 'filtered_noise/signal']),
(reverb,
['add/signal'])
]
processor_group = ddsp.processors.ProcessorGroup(dag=dag)
# Generate audio.
audio = processor_group(outputs)
# Multi-scale spectrogram reconstruction loss.
loss = spectral_loss(audio, audio_input)
ProcessorGroup (with gin)
The main advantage of a ProcessorGroup is that it can be defined with a .gin file, allowing flexible configurations without having to write new python code for every new DAG.
In the example below we pretend we have an external file written, which we treat here as a string. Now, after parsing the gin file, the ProcessorGroup will have its arguments configured on construction.
import ddsp
import gin
gin_config = """
import ddsp
processors.ProcessorGroup.dag = [
(@ddsp.synths.Harmonic(),
['amplitudes', 'harmonic_distribution', 'f0_hz']),
(@ddsp.synths.FilteredNoise(),
['magnitudes']),
(@ddsp.processors.Add(),
['filtered_noise/signal', 'harmonic/signal']),
(@ddsp.effects.TrainableReverb(),
['add/signal'])
]
"""
with gin.unlock_config():
gin.parse_config(gin_config)
# Get synthesizer parameters from the input audio.
outputs = network(audio_input)
# Initialize signal processors, arguments are configured by gin.
processor_group = ddsp.processors.ProcessorGroup()
# Generate audio.
audio = processor_group(outputs)
# Multi-scale spectrogram reconstruction loss.
loss = spectral_loss(audio, audio_input)
A word about gin...
The gin library is a "super power" of dependency injection, and we find it very helpful for our experiments, but with great power comes great responsibility. There are two methods for injecting dependencies with gin.
-
@gin.configurablemakes a function globally configurable, such that anywhere the function or object is called, gin sets its default arguments/constructor values. This can lead to a lot of unintended side-effects. -
@gin.registerregisters a function or object with gin, and only sets the default argument values when the function or object itself is used as an argument to another function.
To "use gin responsibly", by wrapping most
functions with @gin.register so that they can be specified as arguments of more "global" @gin.configurable functions/objects such as ProcessorGroup in the main library and
Model, train(), evaluate(), and sample() in ddsp/training.
As you can see in the code, this allows us to flexibly define hyperparameters of
most functions without worrying about side-effects. One exception is ddsp.core.oscillator_bank.use_angular_cumsum where we can enable a slower but more accurate algorithm globally.
Backwards compatability
For backwards compatability, we keep track of changes in function signatures in update_gin_config.py, which can be used to update old operative configs to work with the current library.
Contributing
We're eager to collaborate with you! See CONTRIBUTING.md
for a guide on how to contribute.
Citation
If you use this code please cite it as:
@inproceedings{
engel2020ddsp,
title={DDSP: Differentiable Digital Signal Processing},
author={Jesse Engel and Lamtharn (Hanoi) Hantrakul and Chenjie Gu and Adam Roberts},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://openreview.net/forum?id=B1x1ma4tDr}
}
Disclaimer
Functions and classes marked EXPERIMENTAL in their doc string are under active development and very likely to change. They should not be expected to be maintained in their current state.
This is not an official Google product.
Top Related Projects
Magenta: Music and Art Generation with Machine Intelligence
Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable music generation LM with textual and melodic conditioning.
A scalable generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech)
C++ library for audio and music analysis, description and synthesis, including Python bindings
Python library for audio and music analysis
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot