 txtai
txtai
💡 All-in-one open-source embeddings database for semantic search, LLM orchestration and language model workflows
Top Related Projects

🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.

💫 Industrial-strength Natural Language Processing (NLP) in Python

A library for efficient similarity search and clustering of dense vectors.

Official Python client for Elasticsearch

AI orchestration framework to build customizable, production-ready LLM applications. Connect components (models, vector DBs, file converters) to pipelines or agents that can interact with your data. With advanced retrieval methods, it's best suited for building RAG, question answering, semantic search or conversational agent chatbots.

💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Quick Overview
txtai is an AI-powered search engine for text data. It allows users to build semantic search applications and workflows, enabling natural language queries and text analysis. The library combines machine learning and natural language processing to create powerful, flexible text-based solutions.
Pros
- Easy to use and integrate with existing Python projects
- Supports multiple embedding models and can be extended with custom models
- Provides a wide range of functionalities beyond search, including text extraction, similarity, and classification
- Offers both local and API-based deployment options
Cons
- May require significant computational resources for large datasets
- Learning curve for advanced features and customizations
- Limited documentation for some of the more complex use cases
- Dependency on external libraries and models, which may require additional setup
Code Examples
- Creating a simple search index:
from txtai.embeddings import Embeddings
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
embeddings.index(["US tops 5 million confirmed virus cases",
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",
"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",
"The National Park Service warns against sacrificing slower friends in a bear attack",
"Maine man wins $1M from $25 lottery ticket"],
range(5))
print(embeddings.search("virus cases", 1))
- Performing text extraction:
from txtai.pipeline import TextExtractor
extractor = TextExtractor()
text = "This is a sample text. It contains information about txtai."
result = extractor(text, "What is this text about?")
print(result)
- Text classification:
from txtai.pipeline import Labels
labels = Labels()
data = [("This is a positive review", "positive"),
("I didn't like the product", "negative")]
labels.fit(data)
result = labels("The product exceeded my expectations")
print(result)
Getting Started
To get started with txtai, follow these steps:
- Install txtai:
pip install txtai
- Create a simple search application:
from txtai.embeddings import Embeddings
# Create embeddings model
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
# Index data
data = ["Text to search", "Add more text", "And more text"]
embeddings.index(data)
# Run a search
results = embeddings.search("search", 1)
print(results)
This basic example creates an embeddings model, indexes some text data, and performs a search. You can expand on this foundation to build more complex applications using txtai's various features.
Competitor Comparisons
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
Pros of transformers
- Extensive library of pre-trained models for various NLP tasks
- Large community support and frequent updates
- Comprehensive documentation and examples
Cons of transformers
- Steeper learning curve for beginners
- Larger library size and potential overhead for simple tasks
- May require more computational resources for some models
Code comparison
txtai:
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
embeddings.index([(1, "Text to embed"), (2, "Another text")])
embeddings.search("Query text", 1)
transformers:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("Text to embed", return_tensors="pt")
outputs = model(**inputs)
txtai focuses on simplifying embedding and search operations, while transformers provides a more comprehensive toolkit for various NLP tasks. txtai offers a more straightforward API for specific use cases, whereas transformers gives users more control and flexibility at the cost of increased complexity.
💫 Industrial-strength Natural Language Processing (NLP) in Python
Pros of spaCy
- More comprehensive NLP toolkit with advanced linguistic features
- Larger community and ecosystem with extensive documentation
- Better performance for traditional NLP tasks like parsing and named entity recognition
Cons of spaCy
- Steeper learning curve for beginners
- Larger model sizes and memory footprint
- Less focus on modern AI/ML techniques like embeddings and transformers
Code Comparison
spaCy:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.label_)
txtai:
from txtai.pipeline import EntityExtraction
extractor = EntityExtraction()
text = "Apple is looking at buying U.K. startup for $1 billion"
print(extractor(text))
spaCy provides more detailed linguistic analysis out-of-the-box, while txtai offers a simpler API for common NLP tasks. spaCy is better suited for traditional NLP workflows, whereas txtai focuses on AI-powered text analysis and search capabilities.
A library for efficient similarity search and clustering of dense vectors.
Pros of FAISS
- Highly optimized for large-scale similarity search and clustering
- Supports GPU acceleration for improved performance
- Extensive documentation and benchmarks available
Cons of FAISS
- Steeper learning curve and more complex API
- Primarily focused on vector similarity search, less versatile for general NLP tasks
- Requires separate text embedding process before indexing
Code Comparison
FAISS example:
import faiss
import numpy as np
d = 64 # dimension
nb = 100000 # database size
nq = 10000 # nb of queries
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
index = faiss.IndexFlatL2(d)
index.add(xb)
D, I = index.search(xq, k=4)
txtai example:
from txtai.embeddings import Embeddings
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
embeddings.index(["Sentence 1", "Sentence 2", "Sentence 3"])
results = embeddings.search("Query text", 2)
FAISS excels in high-performance vector similarity search, while txtai offers a more user-friendly API for general NLP tasks, including embeddings and search functionality.
Official Python client for Elasticsearch
Pros of elasticsearch-py
- Comprehensive API for Elasticsearch, supporting all features and operations
- Well-established and widely used in production environments
- Extensive documentation and community support
Cons of elasticsearch-py
- Focused solely on Elasticsearch, lacking broader NLP capabilities
- Steeper learning curve for those new to Elasticsearch
- Requires separate Elasticsearch server setup and maintenance
Code Comparison
elasticsearch-py:
from elasticsearch import Elasticsearch
es = Elasticsearch()
doc = {"title": "Test Document", "content": "This is a test"}
es.index(index="my_index", id=1, body=doc)
result = es.search(index="my_index", body={"query": {"match": {"content": "test"}}})
txtai:
from txtai.embeddings import Embeddings
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
embeddings.index([(0, "This is a test", None)])
results = embeddings.search("test", 1)
Summary
While elasticsearch-py offers a robust solution for working with Elasticsearch, txtai provides a more streamlined approach to text embeddings and search. elasticsearch-py is better suited for complex, large-scale search applications, while txtai excels in simplicity and ease of use for NLP tasks. The choice between the two depends on the specific requirements of your project and the scale of your search needs.
AI orchestration framework to build customizable, production-ready LLM applications. Connect components (models, vector DBs, file converters) to pipelines or agents that can interact with your data. With advanced retrieval methods, it's best suited for building RAG, question answering, semantic search or conversational agent chatbots.
Pros of Haystack
- More comprehensive framework with a wider range of components and integrations
- Stronger focus on production-ready deployments and scalability
- More extensive documentation and tutorials
Cons of Haystack
- Steeper learning curve due to its complexity and broader feature set
- Potentially heavier resource requirements for smaller projects
- Less flexibility for custom pipelines compared to txtai's modular approach
Code Comparison
Haystack example:
from haystack import Pipeline
from haystack.nodes import EmbeddingRetriever, FARMReader
retriever = EmbeddingRetriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
pipe = Pipeline()
pipe.add_node(component=retriever, name="Retriever", inputs=["Query"])
pipe.add_node(component=reader, name="Reader", inputs=["Retriever"])
txtai example:
from txtai.pipeline import Extractor
extractor = Extractor()
result = extractor("What is the capital of France?", "The capital of France is Paris.")
Both Haystack and txtai offer powerful NLP capabilities, but they cater to different use cases. Haystack is more suitable for large-scale, production-ready applications with complex requirements, while txtai provides a simpler, more flexible approach for smaller projects or rapid prototyping. The choice between the two depends on the specific needs of your project and the level of complexity you're comfortable with.
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Pros of Rasa
- Comprehensive conversational AI framework with built-in NLU and dialogue management
- Large community and extensive documentation for easier adoption and support
- Supports multiple languages and can be deployed on-premises for data privacy
Cons of Rasa
- Steeper learning curve due to its complex architecture and numerous components
- Requires more computational resources and setup time compared to lighter alternatives
- May be overkill for simpler text processing or embedding tasks
Code Comparison
Rasa (dialogue management):
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
class ActionGreet(Action):
def name(self) -> str:
return "action_greet"
def run(self, dispatcher: CollectingDispatcher, tracker: Tracker, domain: Dict[str, Any]) -> List[Dict[str, Any]]:
dispatcher.utter_message(text="Hello! How can I help you today?")
return []
txtai (text embedding and search):
from txtai.embeddings import Embeddings
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
embeddings.index(["Sentence 1", "Sentence 2", "Sentence 3"])
results = embeddings.search("Query text", 1)
print(results)
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()
All-in-one embeddings database



![]()

txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.


Embeddings databases are a union of vector indexes (sparse and dense), graph networks and relational databases.
This foundation enables vector search and/or serves as a powerful knowledge source for large language model (LLM) applications.
Build autonomous agents, retrieval augmented generation (RAG) processes, multi-model workflows and more.
Summary of txtai features:
- ð Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
- ð Create embeddings for text, documents, audio, images and video
- ð¡ Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarization and more
- âªï¸ï¸ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
- ð¤ Agents that intelligently connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems
- âï¸ Build with Python or YAML. API bindings available for JavaScript, Java, Rust and Go.
- ð Batteries included with defaults to get up and running fast
- âï¸ Run local or scale out with container orchestration
txtai is built with Python 3.9+, Hugging Face Transformers, Sentence Transformers and FastAPI. txtai is open-source under an Apache 2.0 license.
Interested in an easy and secure way to run hosted txtai applications? Then join the txtai.cloud preview to learn more.
Why txtai?

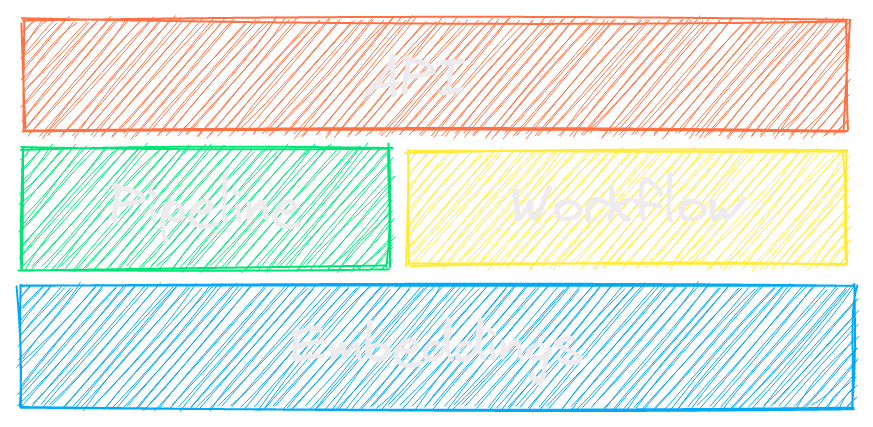
New vector databases, LLM frameworks and everything in between are sprouting up daily. Why build with txtai?
# Get started in a couple lines
import txtai
embeddings = txtai.Embeddings()
embeddings.index(["Correct", "Not what we hoped"])
embeddings.search("positive", 1)
#[(0, 0.29862046241760254)]
- Built-in API makes it easy to develop applications using your programming language of choice
# app.yml
embeddings:
path: sentence-transformers/all-MiniLM-L6-v2
CONFIG=app.yml uvicorn "txtai.api:app"
curl -X GET "http://localhost:8000/search?query=positive"
- Run local - no need to ship data off to disparate remote services
- Work with micromodels all the way up to large language models (LLMs)
- Low footprint - install additional dependencies and scale up when needed
- Learn by example - notebooks cover all available functionality
Use Cases
The following sections introduce common txtai use cases. A comprehensive set of over 60 example notebooks and applications are also available.
Semantic Search
Build semantic/similarity/vector/neural search applications.

Traditional search systems use keywords to find data. Semantic search has an understanding of natural language and identifies results that have the same meaning, not necessarily the same keywords.

Get started with the following examples.
| Notebook | Description | |
|---|---|---|
| Introducing txtai â¶ï¸ | Overview of the functionality provided by txtai | |
| Similarity search with images | Embed images and text into the same space for search | |
| Build a QA database | Question matching with semantic search | |
| Semantic Graphs | Explore topics, data connectivity and run network analysis |
LLM Orchestration
Autonomous agents, retrieval augmented generation (RAG), chat with your data, pipelines and workflows that interface with large language models (LLMs).
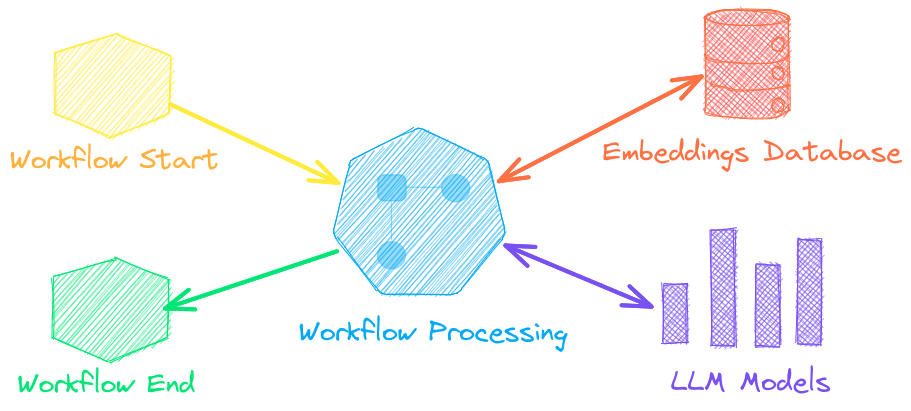
See below to learn more.
| Notebook | Description | |
|---|---|---|
| Prompt templates and task chains | Build model prompts and connect tasks together with workflows | |
| Integrate LLM frameworks | Integrate llama.cpp, LiteLLM and custom generation frameworks | |
| Build knowledge graphs with LLMs | Build knowledge graphs with LLM-driven entity extraction | |
| Parsing the stars with txtai | Explore an astronomical knowledge graph of known stars, planets, galaxies |
Agents
Agents connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems.
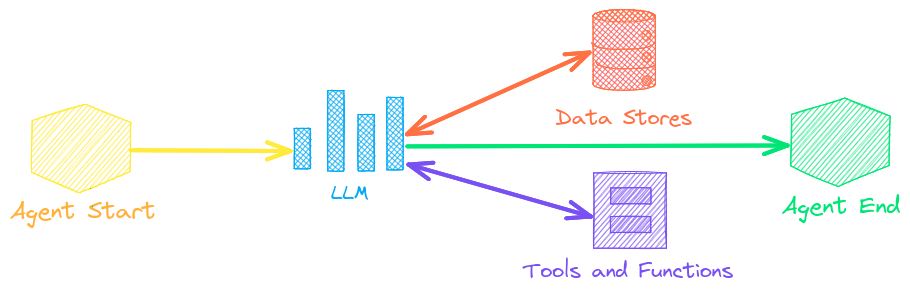
txtai agents are built on top of the Transformers Agent framework. This supports all LLMs txtai supports (Hugging Face, llama.cpp, OpenAI / Claude / AWS Bedrock via LiteLLM).
See the link below to learn more.
| Notebook | Description | |
|---|---|---|
| Analyzing Hugging Face Posts with Graphs and Agents | Explore a rich dataset with Graph Analysis and Agents | |
| Granting autonomy to agents | Agents that iteratively solve problems as they see fit | |
| Analyzing LinkedIn Company Posts with Graphs and Agents | Exploring how to improve social media engagement with AI |
Retrieval augmented generation
Retrieval augmented generation (RAG) reduces the risk of LLM hallucinations by constraining the output with a knowledge base as context. RAG is commonly used to "chat with your data".


A novel feature of txtai is that it can provide both an answer and source citation.
| Notebook | Description | |
|---|---|---|
| Build RAG pipelines with txtai | Guide on retrieval augmented generation including how to create citations | |
| Chunking your data for RAG | Extract, chunk and index content for effective retrieval | |
| Advanced RAG with graph path traversal | Graph path traversal to collect complex sets of data for advanced RAG | |
| Speech to Speech RAG â¶ï¸ | Full cycle speech to speech workflow with RAG |
Language Model Workflows
Language model workflows, also known as semantic workflows, connect language models together to build intelligent applications.


While LLMs are powerful, there are plenty of smaller, more specialized models that work better and faster for specific tasks. This includes models for extractive question-answering, automatic summarization, text-to-speech, transcription and translation.
| Notebook | Description | |
|---|---|---|
| Run pipeline workflows â¶ï¸ | Simple yet powerful constructs to efficiently process data | |
| Building abstractive text summaries | Run abstractive text summarization | |
| Transcribe audio to text | Convert audio files to text | |
| Translate text between languages | Streamline machine translation and language detection |
Installation


The easiest way to install is via pip and PyPI
pip install txtai
Python 3.9+ is supported. Using a Python virtual environment is recommended.
See the detailed install instructions for more information covering optional dependencies, environment specific prerequisites, installing from source, conda support and how to run with containers.
Model guide
See the table below for the current recommended models. These models all allow commercial use and offer a blend of speed and performance.
Models can be loaded as either a path from the Hugging Face Hub or a local directory. Model paths are optional, defaults are loaded when not specified. For tasks with no recommended model, txtai uses the default models as shown in the Hugging Face Tasks guide.
See the following links to learn more.
- Hugging Face Tasks
- Hugging Face Model Hub
- MTEB Leaderboard
- LMSYS LLM Leaderboard
- Open LLM Leaderboard
Powered by txtai
The following applications are powered by txtai.
| Application | Description |
|---|---|
| rag | Retrieval Augmented Generation (RAG) application |
| ragdata | Build knowledge bases for RAG |
| paperai | Semantic search and workflows for medical/scientific papers |
| annotateai | Automatically annotate papers with LLMs |
In addition to this list, there are also many other open-source projects, published research and closed proprietary/commercial projects that have built on txtai in production.
Further Reading


- Introducing txtai, the all-in-one embeddings database
- Tutorial series on Hashnode | dev.to
- What's new in txtai 8.0 | 7.0 | 6.0 | 5.0 | 4.0
- Getting started with semantic search | workflows | rag
- Running txtai at scale
- Vector search & RAG Landscape: A review with txtai
Documentation
Full documentation on txtai including configuration settings for embeddings, pipelines, workflows, API and a FAQ with common questions/issues is available.
Contributing
For those who would like to contribute to txtai, please see this guide.
Top Related Projects
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
💫 Industrial-strength Natural Language Processing (NLP) in Python
A library for efficient similarity search and clustering of dense vectors.
Official Python client for Elasticsearch
AI orchestration framework to build customizable, production-ready LLM applications. Connect components (models, vector DBs, file converters) to pipelines or agents that can interact with your data. With advanced retrieval methods, it's best suited for building RAG, question answering, semantic search or conversational agent chatbots.
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot