
Top Related Projects

Tom's Obvious, Minimal Language

PEG.js: Parser generator for JavaScript

A monadic LL(infinity) parser combinator library for javascript
A library and language for building parsers, interpreters, compilers, etc.

Parser Building Toolkit for JavaScript

ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
Quick Overview
Ohm is a parser generator and interpreter framework for building domain-specific languages (DSLs) and compilers in JavaScript. It provides a simple and expressive syntax for defining grammars, and a powerful set of tools for parsing, interpreting, and transforming those grammars.
Pros
- Expressive Grammar Syntax: Ohm's grammar syntax is designed to be intuitive and easy to read, making it simple to define complex grammars.
- Powerful Parsing and Interpretation: Ohm's parsing and interpretation capabilities allow for the creation of sophisticated DSLs and compilers.
- Extensibility: Ohm is designed to be highly extensible, allowing developers to add custom behavior and functionality as needed.
- Broad Language Support: Ohm can be used to build DSLs and compilers for a wide range of programming languages, not just JavaScript.
Cons
- Learning Curve: Ohm's powerful features and flexibility can come with a steeper learning curve, especially for developers new to parser generation and compiler design.
- Performance: Depending on the complexity of the grammar and the size of the input, Ohm's parsing and interpretation performance may not be as fast as some other parser generators.
- Ecosystem: Compared to some other parser generation tools, Ohm's ecosystem of third-party libraries and tools may be smaller.
- Documentation: While the Ohm documentation is generally good, some developers may find certain aspects of the documentation could be improved or expanded.
Code Examples
Here are a few short code examples demonstrating Ohm's usage:
Defining a Grammar
const ohm = require('ohm-js');
const calculator = ohm.grammar(`
Calculator {
Exp = Term ("+"|"-" Term)*
Term = Factor ("*"|"/" Factor)*
Factor = Prim ("^" Prim)*
Prim = number | "(" Exp ")"
}
`);
This defines a simple grammar for a calculator language, with rules for expressions, terms, factors, and primitive values.
Parsing Input
const match = calculator.match('1 + 2 * 3 - 4');
if (match.succeeded()) {
console.log(match.toAST());
} else {
console.error(match.message);
}
This code parses the input string '1 + 2 * 3 - 4' using the calculator grammar, and logs the resulting abstract syntax tree (AST) if the parse is successful.
Interpreting the AST
const semantics = calculator.createSemantics();
semantics.addOperation('eval', {
Exp(left, op, right) {
return op.eval() === '+' ? left.eval() + right.eval() : left.eval() - right.eval();
},
// ... other semantic rules
});
const result = semantics(match).eval();
console.log(result); // Output: -1
This code defines semantic actions for the calculator grammar, which can be used to evaluate the parsed expression and compute the final result.
Getting Started
To get started with Ohm, you can follow these steps:
-
Install Ohm using npm:
npm install ohm-js -
Define your grammar using the Ohm grammar syntax:
const ohm = require('ohm-js'); const myGrammar = ohm.grammar(` MyLanguage { // Grammar rules go here } `); -
Parse input using the grammar:
const match = myGrammar.match('some input'); if (match.succeeded()) { console.log('Parsing successful!'); } else { console.error(match.message); } -
Define semantic actions to interpret the parsed AST:
const semantics = myGrammar.createSemantics(); semantics.addOperation('eval', { // Semantic rules go here }); const result = semantics(match).eval(); console.log(result);
Competitor Comparisons
Tom's Obvious, Minimal Language
Pros of TOML
- Simple and human-readable configuration file format
- Widely adopted in various programming languages and tools
- Stricter and less ambiguous than alternatives like YAML
Cons of TOML
- Limited expressiveness compared to Ohm's parsing capabilities
- Focused solely on configuration, while Ohm is a general-purpose parsing toolkit
- Less flexibility for complex data structures or custom grammars
Code Comparison
TOML example:
[database]
server = "192.168.1.1"
ports = [ 8001, 8001, 8002 ]
connection_max = 5000
Ohm grammar example:
Arithmetic {
Exp = AddExp
AddExp = AddExp "+" MulExp -- plus
| AddExp "-" MulExp -- minus
| MulExp
MulExp = MulExp "*" PriExp -- times
| MulExp "/" PriExp -- divide
| PriExp
PriExp = "(" Exp ")" -- paren
| number
number = digit+
}
TOML is designed for simple configuration files, making it easy to read and write. It's widely supported across languages and tools. However, it lacks the flexibility and power of Ohm, which can define complex grammars for parsing various languages and formats. Ohm provides a more comprehensive toolkit for language processing tasks, while TOML focuses on a specific use case of configuration management.
PEG.js: Parser generator for JavaScript
Pros of PEG.js
- More mature and widely adopted, with a larger community and ecosystem
- Supports generating parsers in multiple target languages (JavaScript, TypeScript, Rust)
- Offers a web-based editor for testing and debugging grammars
Cons of PEG.js
- Less flexible grammar syntax compared to Ohm
- Limited support for incremental parsing and error recovery
- Steeper learning curve for complex grammars
Code Comparison
PEG.js grammar example:
Expression
= head:Term tail:(_ ("+" / "-") _ Term)* {
return tail.reduce(function(result, element) {
if (element[1] === "+") { return result + element[3]; }
if (element[1] === "-") { return result - element[3]; }
}, head);
}
Ohm grammar example:
Arithmetic {
Exp = AddExp
AddExp = AddExp "+" MulExp -- plus
| AddExp "-" MulExp -- minus
| MulExp
MulExp = MulExp "*" PriExp -- times
| MulExp "/" PriExp -- divide
| PriExp
PriExp = "(" Exp ")" -- paren
| number
number = digit+
}
A monadic LL(infinity) parser combinator library for javascript
Pros of Parsimmon
- More flexible and customizable parsing approach
- Better performance for certain types of grammars
- Easier integration with existing JavaScript code
Cons of Parsimmon
- Steeper learning curve for complex grammars
- Less readable for non-programmers
- Lacks built-in error reporting and debugging tools
Code Comparison
Parsimmon:
const P = require('parsimmon');
const parser = P.string('hello')
.then(P.string(' '))
.then(P.string('world'));
Ohm:
const ohm = require('ohm-js');
const grammar = ohm.grammar(`
Greeting = "hello" " " "world"
`);
Summary
Parsimmon offers more flexibility and potentially better performance for certain use cases, while Ohm provides a more declarative and readable approach to grammar definition. Parsimmon may be preferred by developers who want fine-grained control over parsing logic, while Ohm is often favored for its simplicity and built-in tooling. The choice between the two depends on the specific requirements of the project and the preferences of the development team.
A library and language for building parsers, interpreters, compilers, etc.
Pros of ohm
- More actively maintained with recent updates
- Larger community and contributor base
- Better documentation and examples
Cons of ohm
- Potentially more complex for simple use cases
- May have more dependencies
Code Comparison
ohm:
const ohm = require('ohm-js');
const grammar = ohm.grammar(`
Arithmetic {
Exp = AddExp
AddExp = AddExp "+" MulExp -- plus
| AddExp "-" MulExp -- minus
| MulExp
MulExp = MulExp "*" PriExp -- times
| MulExp "/" PriExp -- divide
| PriExp
PriExp = "(" Exp ")" -- paren
| number
number = digit+
}
`);
ohm>:
// No direct code comparison available as ohm> is not a separate repository
// It appears to be a typo or misunderstanding in the original question
Note: The comparison to "ohm>" seems to be an error, as there is no separate repository named "ohmjs/ohm>". The comparison is based solely on the ohm repository.
Parser Building Toolkit for JavaScript
Pros of Chevrotain
- Better performance for large-scale parsing tasks
- More flexible and customizable parsing approach
- Extensive documentation and examples for various use cases
Cons of Chevrotain
- Steeper learning curve, especially for beginners
- Requires more boilerplate code for simple grammars
- Less intuitive syntax for defining grammar rules
Code Comparison
Ohm grammar example:
Arithmetic {
Exp = AddExp
AddExp = AddExp "+" MulExp -- plus
| AddExp "-" MulExp -- minus
| MulExp
MulExp = MulExp "*" PriExp -- times
| MulExp "/" PriExp -- divide
| PriExp
PriExp = "(" Exp ")" -- paren
| number
number = digit+
}
Chevrotain lexer and parser example:
const createToken = chevrotain.createToken;
const Lexer = chevrotain.Lexer;
const CstParser = chevrotain.CstParser;
const Plus = createToken({ name: "Plus", pattern: /\+/ });
const Minus = createToken({ name: "Minus", pattern: /-/ });
const Mult = createToken({ name: "Mult", pattern: /\*/ });
const Div = createToken({ name: "Div", pattern: /\// });
Both Ohm and Chevrotain are powerful parsing libraries, but they cater to different needs and preferences. Ohm focuses on simplicity and readability, while Chevrotain offers more control and performance at the cost of complexity.
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
Pros of ANTLR4
- Supports multiple target languages (Java, C#, Python, JavaScript, etc.)
- Extensive documentation and large community support
- Powerful parsing capabilities with built-in error recovery
Cons of ANTLR4
- Steeper learning curve, especially for complex grammars
- Can be overkill for simpler parsing tasks
- Generated code can be verbose and less readable
Code Comparison
ANTLR4 grammar example:
grammar Expression;
expr : term (('+' | '-') term)*;
term : factor (('*' | '/') factor)*;
factor : NUMBER | '(' expr ')';
NUMBER : [0-9]+;
WS : [ \t\r\n]+ -> skip;
Ohm grammar example:
Expression {
Expr = Term (("+" | "-") Term)*
Term = Factor (("*" | "/") Factor)*
Factor = number | "(" Expr ")"
number = digit+
}
Both ANTLR4 and Ohm are powerful parsing tools, but they cater to different needs. ANTLR4 is more feature-rich and versatile, supporting multiple languages and complex parsing scenarios. However, it can be more challenging to learn and use for simpler tasks. Ohm, on the other hand, offers a more concise and readable grammar syntax, making it easier to use for smaller projects or when working primarily with JavaScript. The choice between the two depends on the specific requirements of your project and your familiarity with parsing concepts.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Ohm · 


Ohm is a parsing toolkit consisting of a library and a domain-specific language. You can use it to parse custom file formats or quickly build parsers, interpreters, and compilers for programming languages.
The Ohm language is based on parsing expression grammars (PEGs), which are a formal way of describing syntax, similar to regular expressions and context-free grammars. The Ohm library provides a JavaScript interface for creating parsers, interpreters, and more from the grammars you write.
- Full support for left-recursive rules means that you can define left-associative operators in a natural way.
- Object-oriented grammar extension makes it easy to extend an existing language with new syntax.
- Modular semantic actions. Unlike many similar tools, Ohm completely separates grammars from semantic actions. This separation improves modularity and extensibility, and makes both grammars and semantic actions easier to read and understand.
- Online editor and visualizer. The Ohm Editor provides instant feedback and an interactive visualization that makes the entire execution of the parser visible and tangible. It'll make you feel like you have superpowers. ðª
Some awesome things people have built using Ohm:
- Seymour, a live programming environment for the classroom.
- Shadama, a particle simulation language designed for high-school science.
- turtle.audio, an audio environment where simple text commands generate lines that can play music.
- A browser-based tool that turns written Konnakkol (a South Indian vocal percussion art) into audio.
- Wildcard, a browser extension that empowers anyone to modify websites to meet their own specific needs, uses Ohm for its spreadsheet formulas.
Sponsors
Since 2017, Ohm has been maintained by @pdubroy on an unpaid basis. Please consider becoming a sponsor!
Diamond ð
Getting Started
The easiest way to get started with Ohm is to use the interactive editor. Alternatively, you can play with one of the following examples on JSFiddle:
Resources
- Tutorial: Ohm: Parsing Made Easy
- The math example is extensively commented and is a good way to dive deeper.
- Examples
- Documentation
- For community support and discussion, join us on Discord, GitHub Discussions, or the ohm-discuss mailing list.
- For updates, follow @_ohmjs on Twitter.
Installation
On a web page
To use Ohm in the browser, just add a single <script> tag to your page:
<!-- Development version of Ohm from unpkg.com -->
<script src="https://unpkg.com/ohm-js@17/dist/ohm.js"></script>
or
<!-- Minified version, for faster page loads -->
<script src="https://unpkg.com/ohm-js@17/dist/ohm.min.js"></script>
This creates a global variable named ohm.
Node.js
First, install the ohm-js package with your package manager:
Then, you can use require to use Ohm in a script:
const ohm = require('ohm-js');
Ohm can also be imported as an ES module:
import * as ohm from 'ohm-js';
Deno
To use Ohm from Deno:
import * as ohm from 'https://unpkg.com/ohm-js@17';
Basics
Defining Grammars
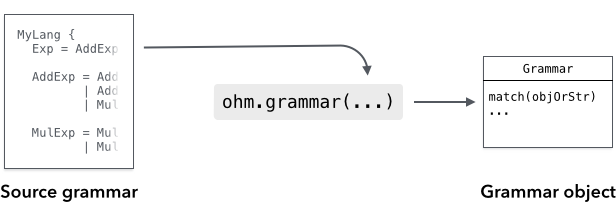
To use Ohm, you need a grammar that is written in the Ohm language. The grammar provides a formal definition of the language or data format that you want to parse. There are a few different ways you can define an Ohm grammar:
-
The simplest option is to define the grammar directly in a JavaScript string and instantiate it using
ohm.grammar(). In most cases, you should use a template literal with String.raw:const myGrammar = ohm.grammar(String.raw` MyGrammar { greeting = "Hello" | "Hola" } `); -
In Node.js, you can define the grammar in a separate file, and read the file's contents and instantiate it using
ohm.grammar(contents):In
myGrammar.ohm:MyGrammar { greeting = "Hello" | "Hola" }In JavaScript:
const fs = require('fs'); const ohm = require('ohm-js'); const contents = fs.readFileSync('myGrammar.ohm', 'utf-8'); const myGrammar = ohm.grammar(contents);
For more information, see Instantiating Grammars in the API reference.
Using Grammars
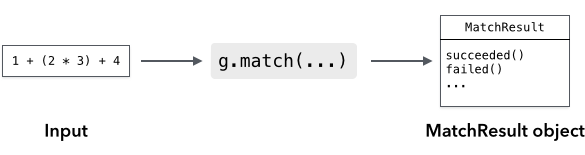
Once you've instantiated a grammar object, use the grammar's match() method to recognize input:
const userInput = 'Hello';
const m = myGrammar.match(userInput);
if (m.succeeded()) {
console.log('Greetings, human.');
} else {
console.log("That's not a greeting!");
}
The result is a MatchResult object. You can use the succeeded() and failed() methods to see whether the input was recognized or not.
For more information, see the main documentation.
Debugging
Ohm has two tools to help you debug grammars: a text trace, and a graphical visualizer.
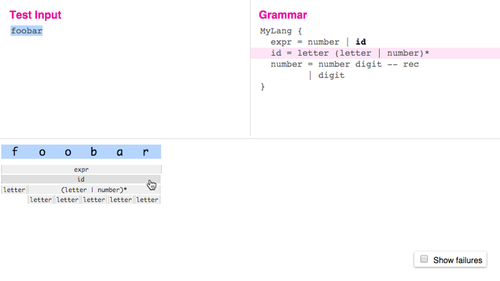
You can try the visualizer online.
To see the text trace for a grammar g, just use the g.trace()
method instead of g.match. It takes the same arguments, but instead of returning a MatchResult
object, it returns a Trace object â calling its toString method returns a string describing
all of the decisions the parser made when trying to match the input. For example, here is the
result of g.trace('ab').toString() for the grammar G { start = letter+ }:
ab â start â "ab"
ab â letter+ â "ab"
ab â letter â "a"
ab â lower â "a"
ab â Unicode [Ll] character â "a"
b â letter â "b"
b â lower â "b"
b â Unicode [Ll] character â "b"
â letter
â lower
â Unicode [Ll] character
â upper
â Unicode [Lu] character
â unicodeLtmo
â Unicode [Ltmo] character
â end â ""
Publishing Grammars
If you've written an Ohm grammar that you'd like to share with others, see our suggestions for publishing grammars.
Contributing to Ohm
Interested in contributing to Ohm? Please read CONTRIBUTING.md and the Ohm Contributor Guide.
Top Related Projects
Tom's Obvious, Minimal Language
PEG.js: Parser generator for JavaScript
A monadic LL(infinity) parser combinator library for javascript
A library and language for building parsers, interpreters, compilers, etc.
Parser Building Toolkit for JavaScript
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot