 odd-platform
odd-platform
First open-source data discovery and observability platform. We make a life for data practitioners easy so you can focus on your business.
Top Related Projects

Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.

The Metadata Platform for your Data and AI Stack

An Open Standard for lineage metadata collection
Quick Overview
The Open Data Discovery (ODD) Platform is an open-source data discovery and metadata management platform. It provides a centralized hub for managing and sharing data assets across an organization, enabling data discovery, lineage, and governance.
Pros
- Comprehensive Data Management: The ODD Platform offers a wide range of features for data discovery, cataloging, and lineage tracking, helping organizations better understand and manage their data assets.
- Collaborative Ecosystem: The platform supports collaboration and sharing, allowing users to contribute metadata, annotations, and other information about data assets.
- Scalable and Extensible: The ODD Platform is designed to handle large volumes of data and can be extended with custom plugins and integrations to fit an organization's specific needs.
- Open-Source and Community-Driven: The project is open-source, allowing for community contributions and customizations to meet unique requirements.
Cons
- Steep Learning Curve: The platform's comprehensive feature set and flexibility may present a steeper learning curve for some users, especially those new to data management platforms.
- Deployment Complexity: Setting up and configuring the ODD Platform may require more technical expertise compared to some other data discovery tools, especially for larger organizations with complex data landscapes.
- Limited Adoption: As an open-source project, the ODD Platform may have a smaller user base compared to some commercial data management solutions, which could impact the availability of support and community resources.
- Ongoing Maintenance: Maintaining and updating the ODD Platform may require dedicated resources and technical expertise, which could be a challenge for some organizations.
Getting Started
To get started with the ODD Platform, follow these steps:
- Clone the repository:
git clone https://github.com/opendatadiscovery/odd-platform.git
- Navigate to the project directory:
cd odd-platform
- Set up the development environment:
make setup
- Start the development server:
make run
-
Open the ODD Platform in your web browser at
http://localhost:8080. -
Follow the on-screen instructions to create an account and start exploring the platform's features.
For more detailed installation and configuration instructions, please refer to the ODD Platform documentation.
Competitor Comparisons
Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.
Pros of Amundsen
- More mature project with a larger community and wider adoption
- Extensive documentation and guides for setup and usage
- Built-in support for popular data sources like Hive, Presto, and Redshift
Cons of Amundsen
- More complex architecture with multiple components
- Steeper learning curve for setup and customization
- Less flexible metadata model compared to ODD Platform
Code Comparison
Amundsen (Python):
from amundsen_common.models.table import Table
from amundsen_databuilder.models.neo4j_csv_serde import Neo4jCsvSerializable
class TableMetadata(Neo4jCsvSerializable):
TABLE_NODE_LABEL = Table.TABLE_NODE_LABEL
TABLE_KEY_FORMAT = Table.TABLE_KEY_FORMAT
ODD Platform (TypeScript):
import { DataEntity, DataEntityType } from '@opendatadiscovery/odd-platform-api';
export interface TableMetadata extends DataEntity {
type: DataEntityType.TABLE;
columns: ColumnMetadata[];
primaryKey?: string[];
}
The code snippets show different approaches to defining table metadata. Amundsen uses a Python class inheriting from Neo4j serialization, while ODD Platform uses TypeScript interfaces for a more flexible structure.
The Metadata Platform for your Data and AI Stack
Pros of DataHub
- More mature project with a larger community and ecosystem
- Extensive documentation and tutorials for easier adoption
- Broader range of integrations with data tools and platforms
Cons of DataHub
- More complex architecture, potentially harder to set up and maintain
- Heavier resource requirements due to its comprehensive feature set
- Steeper learning curve for new users and developers
Code Comparison
DataHub (Python ingestion example):
from datahub.ingestion.run.pipeline import Pipeline
pipeline = Pipeline.create({
"source": {"type": "mysql", "config": {...}},
"sink": {"type": "datahub-rest", "config": {...}}
})
pipeline.run()
ODD Platform (Python SDK example):
from odd_models.models import DataEntity
from oddrn_generator import MysqlGenerator
generator = MysqlGenerator(host_settings="localhost:3306", database_name="mydb")
data_entity = DataEntity(name="users", oddrn=generator.get_table_oddrn("users"))
Both projects aim to provide data discovery and metadata management solutions, but DataHub offers a more comprehensive feature set at the cost of increased complexity, while ODD Platform focuses on simplicity and ease of use.
An Open Standard for lineage metadata collection
Pros of OpenLineage
- Focuses specifically on data lineage and metadata collection
- Supports a wide range of data processing frameworks and tools
- Has a well-defined, extensible event model for capturing lineage information
Cons of OpenLineage
- More limited in scope compared to ODD Platform's broader data discovery features
- Requires integration with other tools for visualization and advanced analytics
- May have a steeper learning curve for users new to data lineage concepts
Code Comparison
OpenLineage example (Python):
from openlineage.client import OpenLineageClient
from openlineage.client.run import RunEvent
client = OpenLineageClient()
event = RunEvent(...)
client.emit(event)
ODD Platform example (Java):
import org.opendatadiscovery.oddrn.model.OddrnModel;
import org.opendatadiscovery.oddplatform.ingestion.contract.model.DataEntity;
DataEntity dataEntity = new DataEntity();
dataEntity.setOddrn(OddrnModel.builder().build());
dataEntityList.add(dataEntity);
Both projects aim to improve data management and observability, but OpenLineage focuses more on lineage tracking, while ODD Platform offers a broader set of data discovery and metadata management features. OpenLineage may be better suited for organizations primarily concerned with lineage, while ODD Platform provides a more comprehensive solution for data catalog and discovery needs.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
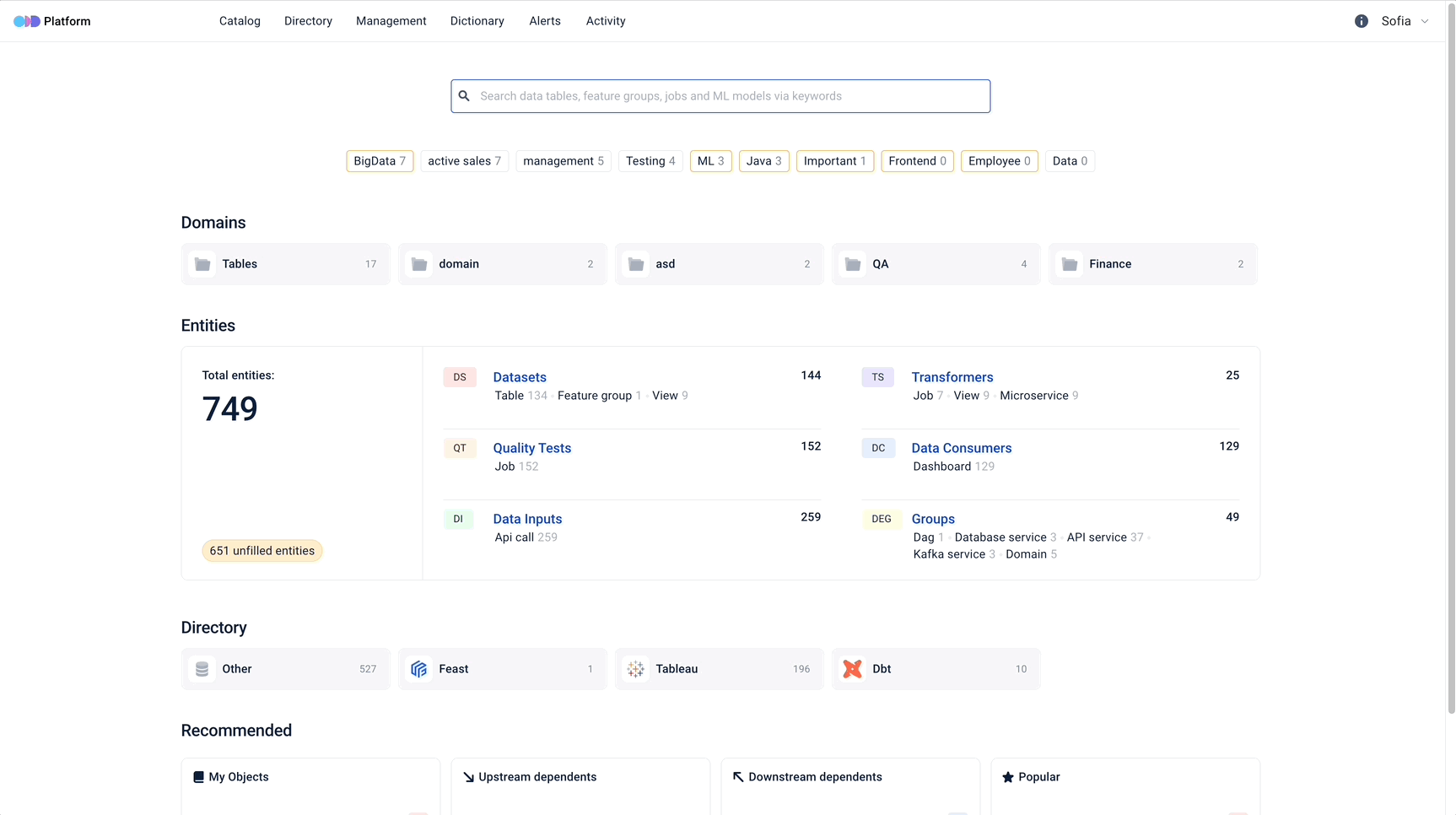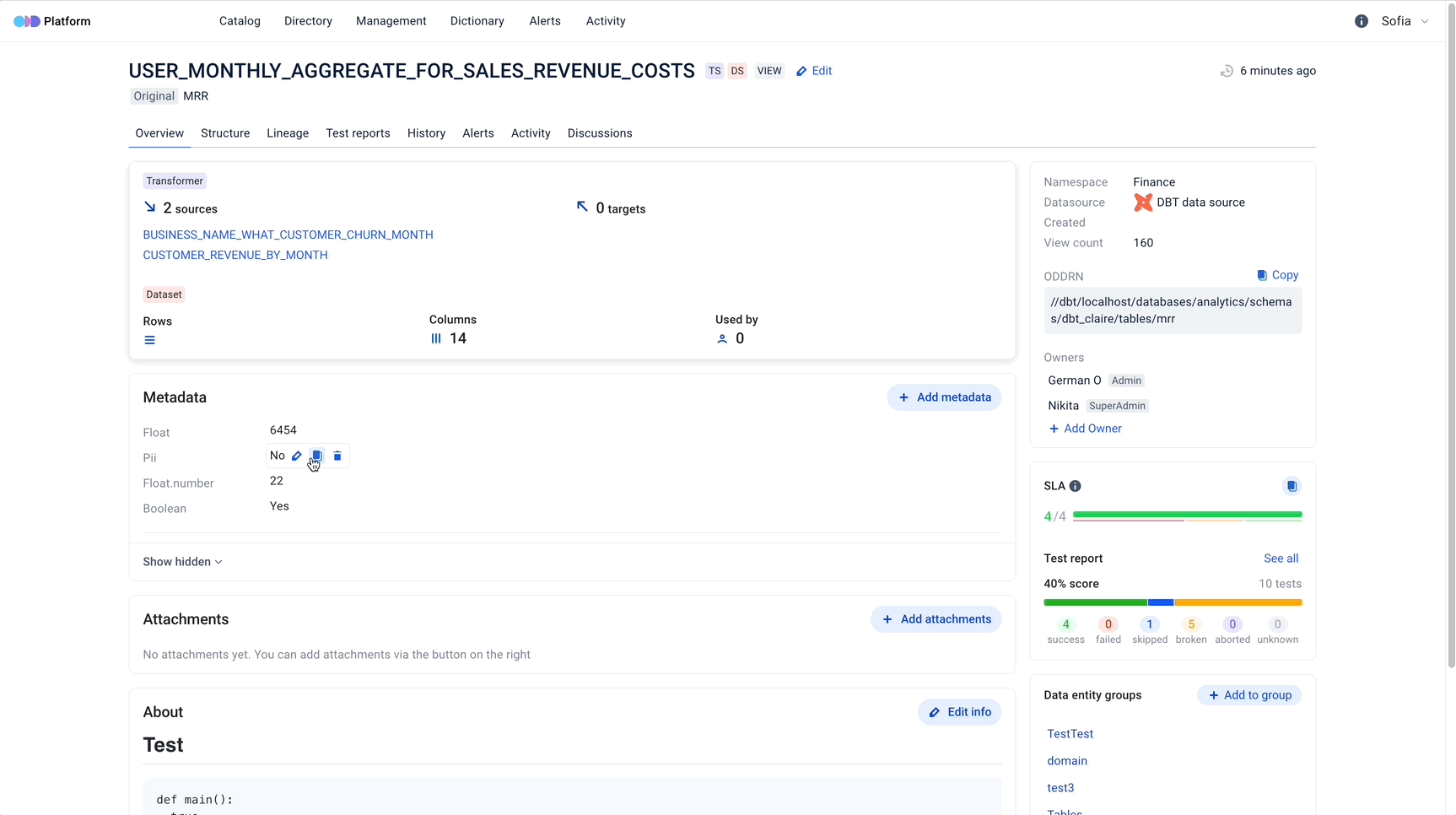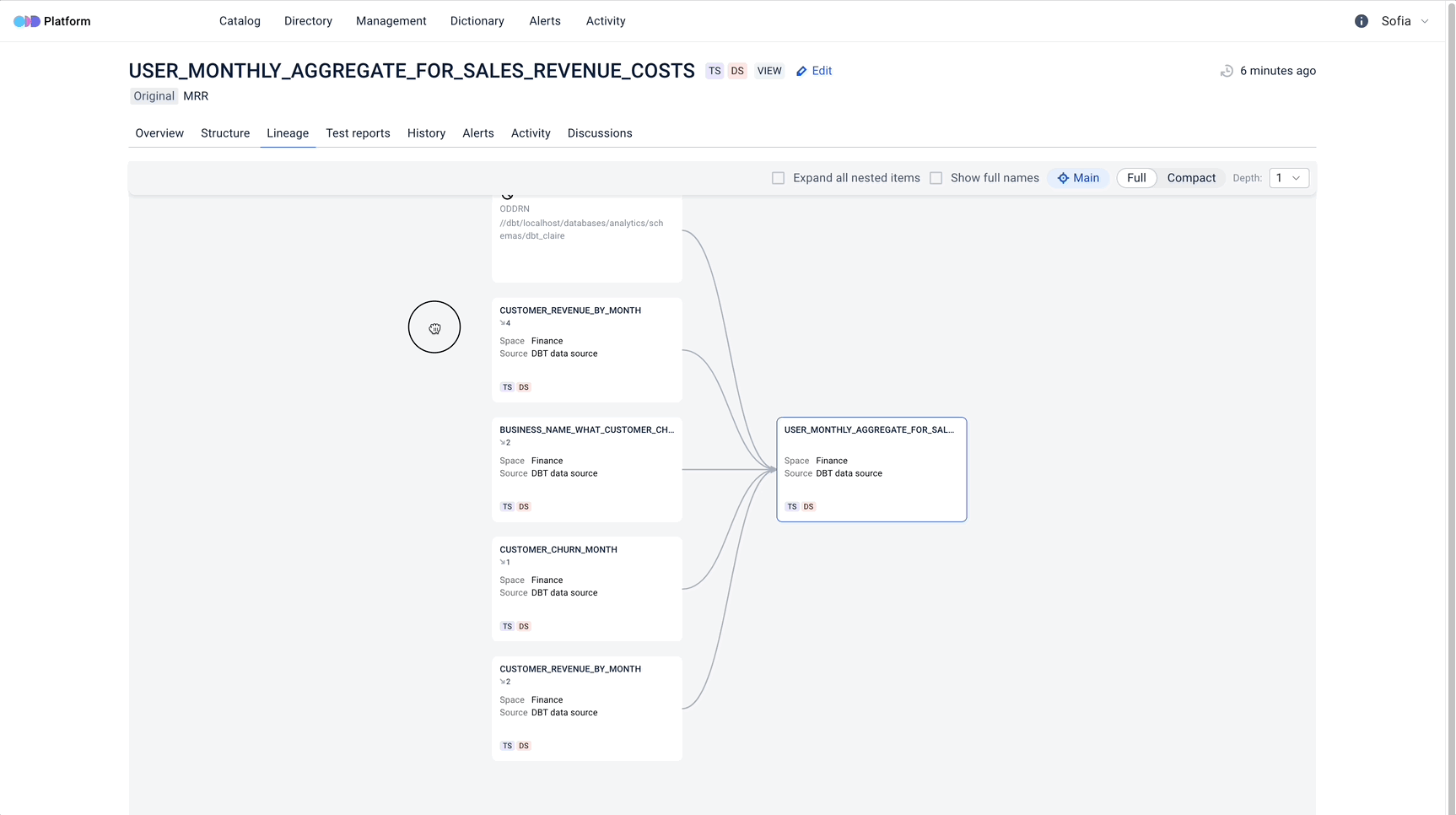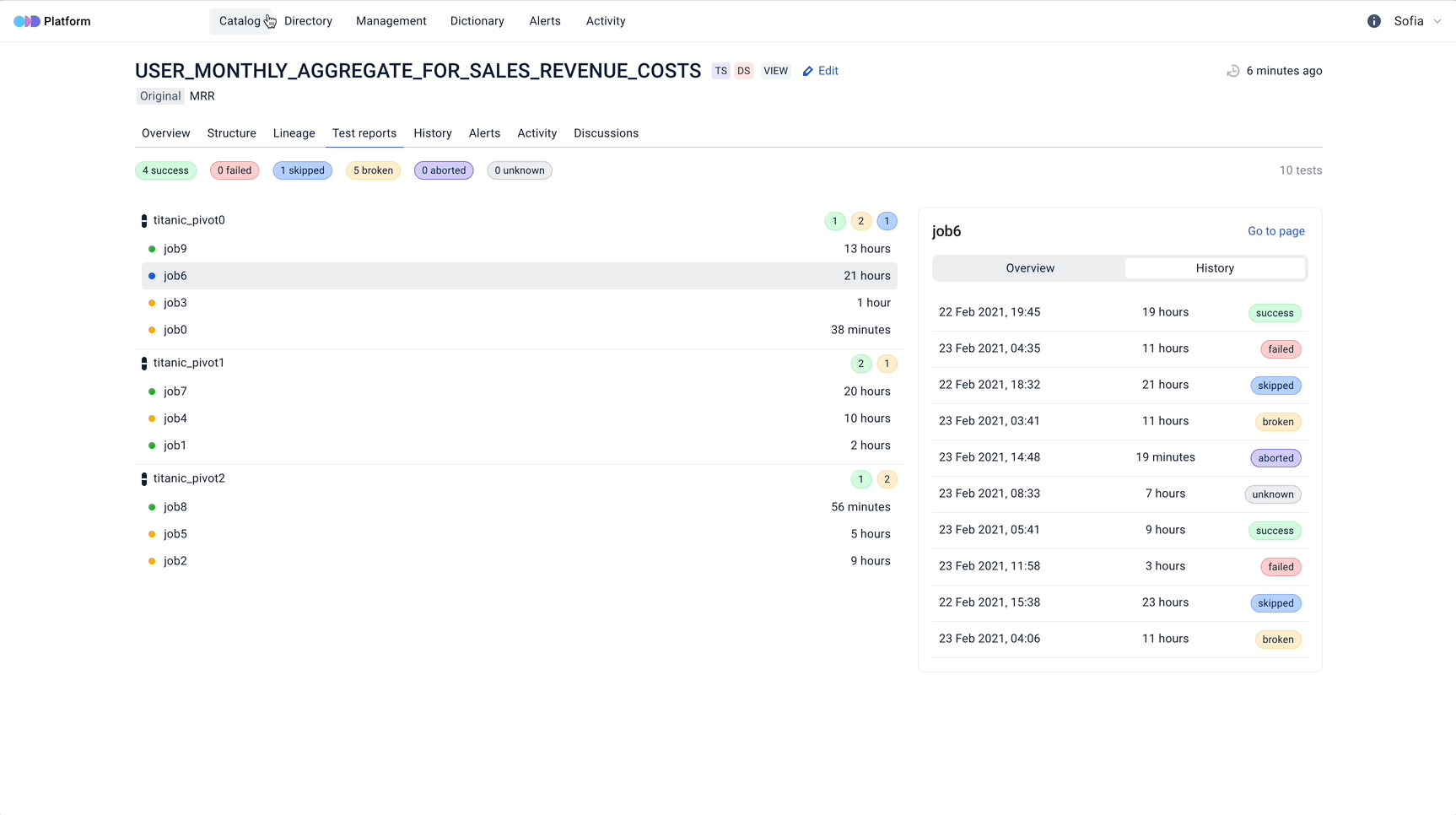
Next-Gen Data Discovery and Data Observability Platform
Website ⢠LinkedIn ⢠Slack ⢠Documentation ⢠Blog ⢠Demo
Demo
Play with our demo app!
Introduction
ODD is an open-source data discovery and observability tool for data teams that helps to efficiently democratise data, power collaboration and reduce time on data discovery through modern user-friendly environment.
Key wins
- Shorten data discovery phase
- Have transparency on how and by whom the data is used
- Foster data culture by continuous compliance and data quality monitoring
- Accelerate data insights
- Know the sources of your dashboards and ad hoc reports
- Deprecate outdated objects responsibly by assessing and mitigating the risks
- :point_right: ODD Platform is a reference implementation of Open Data Discovery Spec
Features
Data Discovery and Observability
- Accumulate scattered data insights in Federated Data catalogue
- Gain observability through E2E Data objects Lineage
- Benefit from cutting-edge E2E microservices Lineage feature in tracking your data flow through the whole data landscape
- Be warned and alerted by Pipeline Monitoring tools
- Store your metadata
- Use ODD-native modern lightweight UI
ML First citizen
- Save results of your ML Experiments by automatically logging its parameters
Data Security & Compliance
- Manage Tags to prevent any abuse of the data
- Refer to Tags to stay compliant with data security standards
- Have full transparency on how and by whom the data is used
Data Quality
- Utilize advanced Data Quality Dashboard to gain insights into data quality metrics, trends, and issues across your datasets, enabling proactive data quality management
- Simplify DQ processes by using ODD with Great Expectations and DBT tests compatibility
- Integrate ODD with any custom DQ framework
Reference Data Management (Lookup Tables) - a part of Master Data Management (MDM)
- Manage and store reference data centrally, ensuring a single source of truth for key data elements like currency codes, country names, and product categories, etc.
- Easily integrate Lookup Tables with data pipelines and transformations, enhancing data enrichment and validation processes
- Support data governance and compliance efforts by maintaining accurate and consistent reference data across all data assets
Getting Started
Running as a separate container
Setting up PostgreSQL connection details, for example:
export POSTGRES_HOST=172.17.0.1
export POSTGRES_PORT=5432
export POSTGRES_DATABASE=postgres
export POSTGRES_USER=postgres
export POSTGRES_PASSWORD=mysecretpassword
Starting new instance of the platform:
docker run -d \
--name odd-platform \
-e SPRING_DATASOURCE_URL=jdbc:postgresql://${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DATABASE} \
-e SPRING_DATASOURCE_USERNAME=${POSTGRES_USER} \
-e SPRING_DATASOURCE_PASSWORD=${POSTGRES_PASSWORD} \
-p 8080:8080 \
ghcr.io/opendatadiscovery/odd-platform:latest
Go to localhost:8080 in case of local environment.
Running Locally with Docker Compose
docker-compose -f docker/demo.yaml up -d odd-platform-enricher
- :point_right: QUICKSTART
Deploying to Kubernetes with Helm Charts
- :point_right: QUICKSTART
Example configurations
There are various example configurations (via docker-compose) within docker/examples directory.
Contributing
Contributing to ODD Platform is very welcome. For basic contributions, all you need is being comfortable with GitHub and Git. The best ways to contribute are:
- Work on new adapters
- Work on documentation
To ensure equal and positive communication, we adhere to our Code of Conduct. Before starting any interactions with this repository, please read it and make sure to follow.
Please before contributing check out our Contributing Guide and issues labeled "good first issue":
Integrations
OpenDataDiscovery Platform offers comprehensive data source support to meet your needs.
ODD Data Model
ODD operates the following high-level types of entities:
- Datasets (collections of data: tables, topics, files, feature groups)
- Transformers (transformers of data: ETL or ML training jobs, experiments)
- Data Consumers (data consumers: ML models or BI dashboards)
- Data Quality Tests (data quality tests for datasets)
- Data Inputs (sources of data)
- Transformer Runs (executions of ETL or ML training jobs)
- Quality Test Runs executions of data quality tests
For more information, please check specification.md.
Community Support
Join our community if you need help, want to chat or have any other questions for us:
- GitHub - Discussion forums and issues
- Slack - Join the conversation! Get all the latest updates and chat to the devs
Contacts
If you have any questions or ideas, please don't hesitate to drop a line to any of us.
| Team Member | GitHub | |
|---|---|---|
| German Osin | germanosin | |
| Nikita Dementev | DementevNikita | |
| Damir Abdullin | damirabdul | |
| Alexey Kozyurov | Leshe4ka | |
| Pavel Makarichev | vixtir | |
| Roman Zabaluev | Haarolean |
License
ODD Platform uses the Apache 2.0 License.
Top Related Projects
Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.
The Metadata Platform for your Data and AI Stack
An Open Standard for lineage metadata collection
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot