
Top Related Projects

YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )

YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite

Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors

Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.

Models and examples built with TensorFlow

Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
Quick Overview
Darknet is an open-source neural network framework written in C and CUDA. It's known for its speed and efficiency, particularly for real-time object detection. The framework is the foundation for popular object detection systems like YOLO (You Only Look Once).
Pros
- High performance and speed, especially on GPU
- Supports both CPU and GPU computation
- Implements various popular neural network architectures
- Minimal dependencies, making it easy to compile and run
Cons
- Limited documentation and examples compared to more mainstream frameworks
- Steeper learning curve for beginners
- Less active community support compared to PyTorch or TensorFlow
- Primarily focused on computer vision tasks, limiting its versatility
Code Examples
- Loading a pre-trained model and performing object detection:
#include "darknet.h"
int main(int argc, char **argv)
{
char *cfg = "cfg/yolov3.cfg";
char *weights = "yolov3.weights";
char *filename = "data/dog.jpg";
network *net = load_network(cfg, weights, 0);
image im = load_image_color(filename, 0, 0);
image sized = letterbox_image(im, net->w, net->h);
layer l = net->layers[net->n-1];
float *X = sized.data;
float *predictions = network_predict(net, X);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, 0.5, 0.5, 0, 1, &nboxes);
do_nms_sort(dets, nboxes, l.classes, 0.45);
draw_detections(im, dets, nboxes, 0.5, "predictions.jpg");
free_image(im);
free_image(sized);
free_detections(dets, nboxes);
free_network(net);
return 0;
}
- Training a custom object detection model:
#include "darknet.h"
int main(int argc, char **argv)
{
char *train_images = "data/train.txt";
char *backup_directory = "backup/";
char *cfg = "cfg/yolov3-custom.cfg";
char *weights = (argc > 1) ? argv[1] : "darknet53.conv.74";
srand(time(0));
char *base = basecfg(cfg);
printf("%s\n", base);
float avg_loss = -1;
network *net = load_network(cfg, weights, 0);
printf("Learning Rate: %g, Momentum: %g, Decay: %g\n", net->learning_rate, net->momentum, net->decay);
int imgs = net->batch * net->subdivisions;
int i = *net->seen / imgs;
data train, buffer;
list *plist = get_paths(train_images);
char **paths = (char **)list_to_array(plist);
load_args args = {0};
args.w = net->w;
args.h = net->h;
args.paths = paths;
args.n = imgs;
args.m = plist->size;
args.d = &buffer;
args.type = DETECTION_DATA;
pthread_t load_thread = load_data_in_thread(args);
clock_t time;
while(get_current_batch(net) < net->max_batches) {
i += 1;
time = clock();
pthread_join(load_thread, 0);
train = buffer;
load_thread = load_data_in_thread(args);
printf("Loaded: %lf seconds\n", sec(clock()-time));
time = clock();
float loss = train_network(net, train);
Competitor Comparisons
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
Pros of Darknet (AlexeyAB)
- More frequent updates and active development
- Additional features and improvements, including support for newer GPU architectures
- Enhanced documentation and user guides
Cons of Darknet (AlexeyAB)
- Potentially more complex codebase due to additional features
- May have slightly higher system requirements for some functionalities
Code Comparison
Darknet (pjreddie):
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear)
{
list *options = read_data_cfg(datacfg);
char *train_images = option_find_str(options, "train", "data/train.list");
char *backup_directory = option_find_str(options, "backup", "/backup/");
Darknet (AlexeyAB):
void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show, int calc_map, int mjpeg_port, int show_imgs, int benchmark_layers, char *chart_path)
{
list *options = read_data_cfg(datacfg);
char *train_images = option_find_str(options, "train", "data/train.list");
char *backup_directory = option_find_str(options, "backup", "/backup/");
The AlexeyAB version includes additional parameters for more customization options during training.
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
Pros of YOLOv5
- Written in PyTorch, offering better flexibility and ease of use
- More extensive documentation and community support
- Includes features like model export, hyperparameter evolution, and multi-GPU training
Cons of YOLOv5
- Larger model size and potentially slower inference time
- Less established track record compared to Darknet's long history
Code Comparison
Darknet (C):
layer make_convolutional_layer(int batch, int h, int w, int c, int n, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor)
{
layer l = {0};
l.type = CONVOLUTIONAL;
// ... (additional initialization)
return l;
}
YOLOv5 (Python):
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Pros of YOLOv7
- More recent and advanced YOLO implementation with improved performance
- Supports a wider range of modern deep learning techniques and architectures
- Active development and community support
Cons of YOLOv7
- More complex codebase and potentially steeper learning curve
- May require more computational resources for training and inference
- Less established than Darknet, which has been around longer
Code Comparison
Darknet (C):
layer make_convolutional_layer(int batch, int h, int w, int c, int n, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor)
{
layer l = {0};
l.type = CONVOLUTIONAL;
// ... (initialization continues)
}
YOLOv7 (Python):
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Pros of Detectron2
- Built on PyTorch, offering more flexibility and easier integration with modern deep learning ecosystems
- Provides a modular design, allowing for easier customization and extension of models
- Includes a wider range of pre-trained models and datasets out of the box
Cons of Detectron2
- Higher computational requirements and potentially slower inference speed
- Steeper learning curve due to more complex architecture and API
Code Comparison
Darknet (C):
layer make_convolutional_layer(int batch, int h, int w, int c, int n, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor)
{
layer l = {0};
l.type = CONVOLUTIONAL;
// ... (initialization continues)
}
Detectron2 (Python):
class Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(Conv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
Models and examples built with TensorFlow
Pros of TensorFlow Models
- Broader range of pre-trained models and architectures
- Better integration with TensorFlow ecosystem and tools
- More active development and community support
Cons of TensorFlow Models
- Steeper learning curve for beginners
- Potentially slower inference compared to Darknet
- Larger codebase and more complex setup
Code Comparison
Darknet (C):
layer make_convolutional_layer(int batch, int h, int w, int c, int n, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor)
{
layer l = {0};
l.type = CONVOLUTIONAL;
// ... (additional initialization)
return l;
}
TensorFlow Models (Python):
def conv2d(inputs, filters, kernel_size, strides=(1, 1), padding='valid', activation=None, use_bias=True, name=None):
return tf.keras.layers.Conv2D(
filters=filters, kernel_size=kernel_size, strides=strides,
padding=padding, activation=activation, use_bias=use_bias, name=name
)(inputs)
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
Pros of Mask_RCNN
- Provides instance segmentation in addition to object detection
- Built on top of Keras and TensorFlow, offering more flexibility and easier integration with other deep learning projects
- Includes pre-trained models on the COCO dataset
Cons of Mask_RCNN
- Generally slower inference time compared to Darknet
- Requires more computational resources for training and inference
- More complex architecture, which can be challenging for beginners
Code Comparison
Darknet (C):
image im = load_image("data/dog.jpg", 0, 0, 0);
network *net = load_network("cfg/yolov3.cfg", "yolov3.weights", 0);
detection *dets = get_network_boxes(net, im.w, im.h, 0.5, 0.5, 0, 1, &nboxes);
Mask_RCNN (Python):
import mrcnn.model as modellib
model = modellib.MaskRCNN(mode="inference", config=config, model_dir=MODEL_DIR)
model.load_weights(COCO_MODEL_PATH, by_name=True)
results = model.detect([image], verbose=1)
Both repositories offer powerful object detection capabilities, but Mask_RCNN provides additional instance segmentation features at the cost of increased complexity and computational requirements. Darknet, on the other hand, focuses on speed and efficiency, making it more suitable for real-time applications.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

Darknet
Darknet is an open source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation.
Discord invite link for for communication and questions: https://discord.gg/zSq8rtW
YOLOv7:
-
paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors: https://arxiv.org/abs/2207.02696
-
source code - Pytorch (use to reproduce results): https://github.com/WongKinYiu/yolov7
Official YOLOv7 is more accurate and faster than YOLOv5 by 120% FPS, than YOLOX by 180% FPS, than Dual-Swin-T by 1200% FPS, than ConvNext by 550% FPS, than SWIN-L by 500% FPS.
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100, batch=1.
- YOLOv7-e6 (55.9% AP, 56 FPS V100 b=1) by
+500%FPS faster than SWIN-L Cascade-Mask R-CNN (53.9% AP, 9.2 FPS A100 b=1) - YOLOv7-e6 (55.9% AP, 56 FPS V100 b=1) by
+550%FPS faster than ConvNeXt-XL C-M-RCNN (55.2% AP, 8.6 FPS A100 b=1) - YOLOv7-w6 (54.6% AP, 84 FPS V100 b=1) by
+120%FPS faster than YOLOv5-X6-r6.1 (55.0% AP, 38 FPS V100 b=1) - YOLOv7-w6 (54.6% AP, 84 FPS V100 b=1) by
+1200%FPS faster than Dual-Swin-T C-M-RCNN (53.6% AP, 6.5 FPS V100 b=1) - YOLOv7x (52.9% AP, 114 FPS V100 b=1) by
+150%FPS faster than PPYOLOE-X (51.9% AP, 45 FPS V100 b=1) - YOLOv7 (51.2% AP, 161 FPS V100 b=1) by
+180%FPS faster than YOLOX-X (51.1% AP, 58 FPS V100 b=1)



Scaled-YOLOv4:
-
paper (CVPR 2021): https://openaccess.thecvf.com/content/CVPR2021/html/Wang_Scaled-YOLOv4_Scaling_Cross_Stage_Partial_Network_CVPR_2021_paper.html
-
source code - Pytorch (use to reproduce results): https://github.com/WongKinYiu/ScaledYOLOv4
-
source code - Darknet: https://github.com/AlexeyAB/darknet
YOLOv4:
-
source code: https://github.com/AlexeyAB/darknet
For more information see the Darknet project website.
Expand
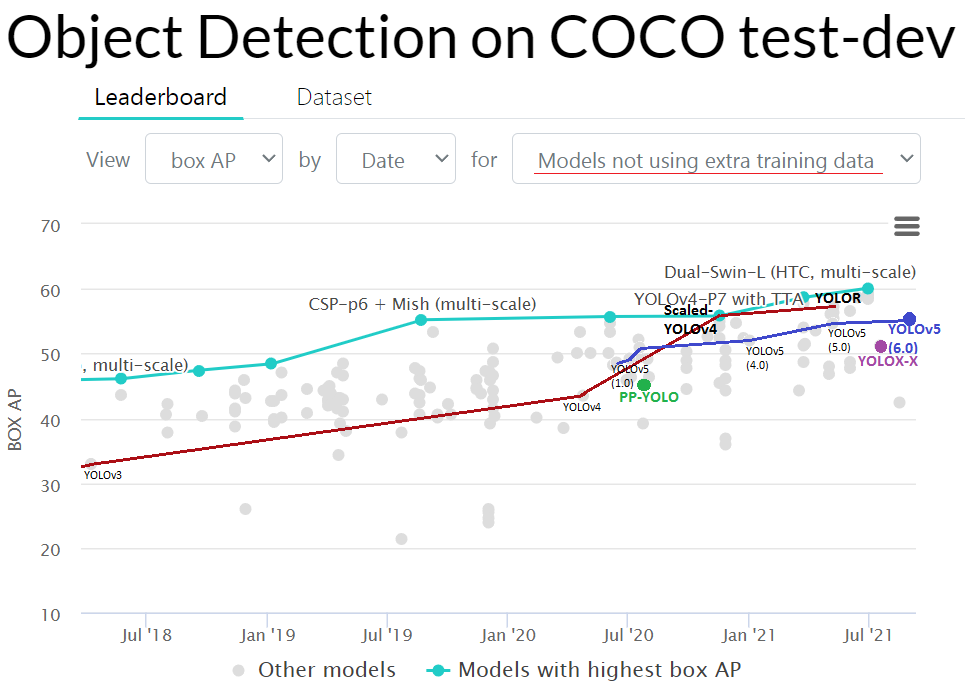 https://paperswithcode.com/sota/object-detection-on-coco
https://paperswithcode.com/sota/object-detection-on-coco
 AP50:95 - FPS (Tesla V100) Paper: https://arxiv.org/abs/2011.08036
AP50:95 - FPS (Tesla V100) Paper: https://arxiv.org/abs/2011.08036
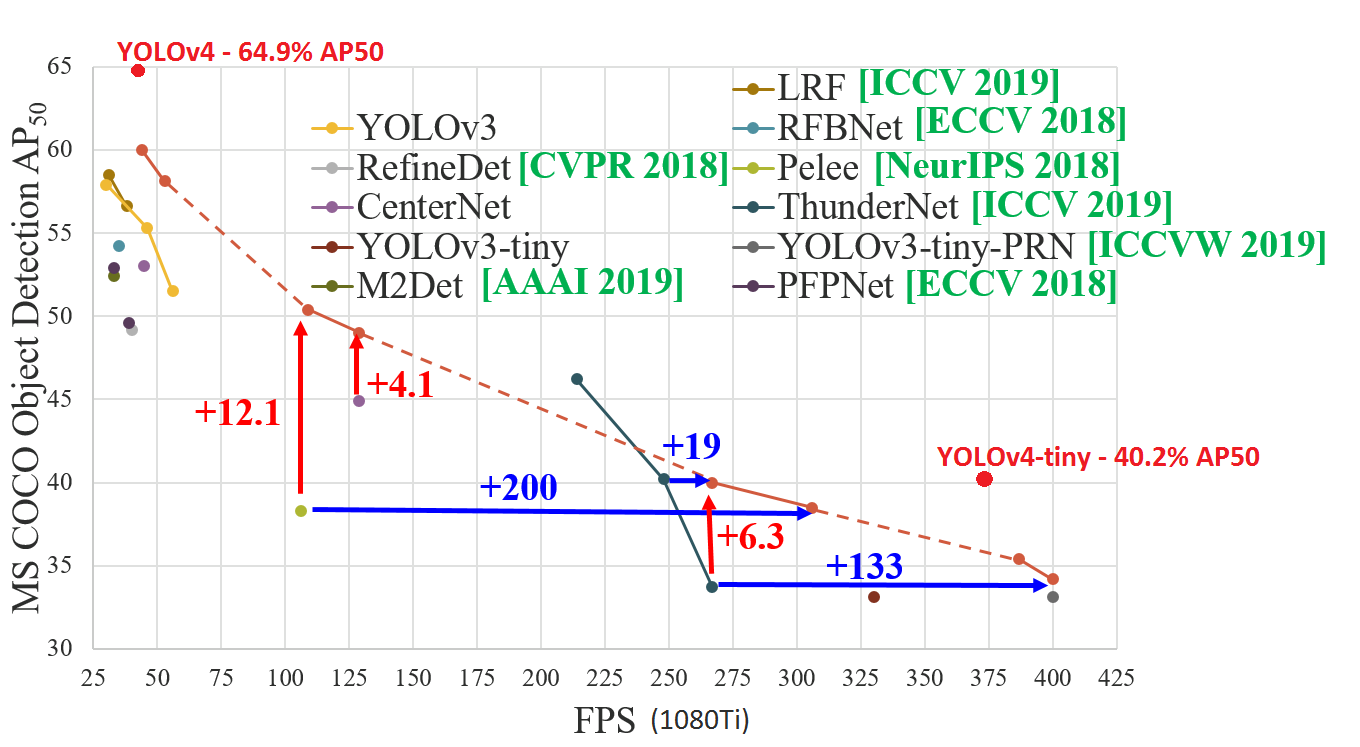

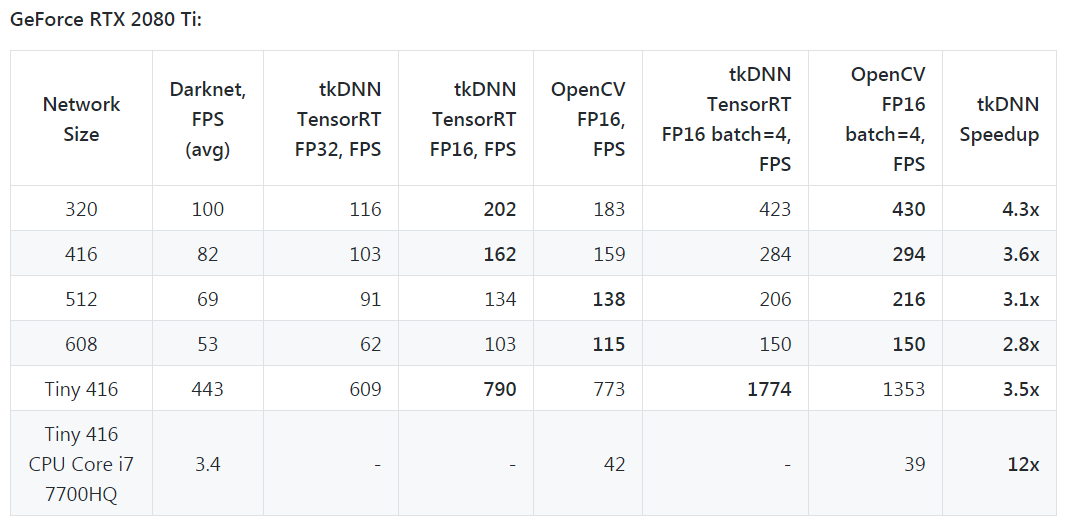
Citation
@misc{https://doi.org/10.48550/arxiv.2207.02696,
doi = {10.48550/ARXIV.2207.02696},
url = {https://arxiv.org/abs/2207.02696},
author = {Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
@misc{bochkovskiy2020yolov4,
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
year={2020},
eprint={2004.10934},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@InProceedings{Wang_2021_CVPR,
author = {Wang, Chien-Yao and Bochkovskiy, Alexey and Liao, Hong-Yuan Mark},
title = {{Scaled-YOLOv4}: Scaling Cross Stage Partial Network},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13029-13038}
}
Top Related Projects
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Detectron2 is a platform for object detection, segmentation and other visual recognition tasks.
Models and examples built with TensorFlow
Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot