 qdrant
qdrant
Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/
Top Related Projects

Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search

Weaviate is an open-source vector database that stores both objects and vectors, allowing for the combination of vector search with structured filtering with the fault tolerance and scalability of a cloud-native database.

A library for efficient similarity search and clustering of dense vectors.

Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk

Header-only C++/python library for fast approximate nearest neighbors

Free and Open Source, Distributed, RESTful Search Engine
Quick Overview
Qdrant is a vector similarity search engine designed for production-grade applications. It provides a fast, scalable, and feature-rich solution for nearest neighbor search, with support for filtering and payload storage. Qdrant is written in Rust, offering high performance and low resource usage.
Pros
- High performance and efficiency due to its Rust implementation
- Supports complex filtering and payload storage alongside vector search
- Offers both local and distributed modes for scalability
- Provides multiple APIs, including gRPC and REST, for easy integration
Cons
- Relatively new project, which may lead to potential stability issues
- Limited ecosystem compared to more established vector databases
- Steeper learning curve for users not familiar with vector similarity search concepts
- Documentation could be more comprehensive for advanced use cases
Code Examples
- Creating a collection:
from qdrant_client import QdrantClient
from qdrant_client.http import models
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="my_collection",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
)
- Inserting points:
from qdrant_client.http import models
client.upsert(
collection_name="my_collection",
points=[
models.PointStruct(
id=1, vector=[0.05, 0.61, 0.76, 0.74], payload={"city": "Berlin"}
),
models.PointStruct(
id=2, vector=[0.19, 0.81, 0.75, 0.11], payload={"city": "London"}
),
]
)
- Searching for similar vectors:
search_result = client.search(
collection_name="my_collection",
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=2
)
print(search_result)
Getting Started
To get started with Qdrant, follow these steps:
-
Install Qdrant:
docker pull qdrant/qdrant docker run -p 6333:6333 qdrant/qdrant -
Install the Python client:
pip install qdrant-client -
Connect to Qdrant and create a collection:
from qdrant_client import QdrantClient from qdrant_client.http import models client = QdrantClient("localhost", port=6333) client.create_collection( collection_name="my_collection", vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE), ) -
Start inserting and searching vectors as shown in the code examples above.
Competitor Comparisons
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Pros of Milvus
- Supports a wider range of index types, including HNSW, IVF, and GPU-accelerated indexes
- More mature project with a larger community and ecosystem
- Offers both standalone and distributed deployment options for scalability
Cons of Milvus
- Higher resource requirements and more complex setup process
- Steeper learning curve due to more advanced features and configuration options
- Less focus on ease of use for smaller-scale applications
Code Comparison
Milvus (Python client):
from pymilvus import Collection, connections
connections.connect()
collection = Collection("example")
collection.load()
results = collection.search(
data=[[1.0, 2.0, 3.0]],
anns_field="vector_field",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5
)
Qdrant (Rust client):
use qdrant_client::prelude::*;
let client = QdrantClient::new(Some("http://localhost:6334")).unwrap();
let search_result = client
.search_points(&SearchPoints {
collection_name: "example".to_string(),
vector: vec![1.0, 2.0, 3.0],
limit: 5,
with_payload: Some(true.into()),
..Default::default()
})
.await?;
Both repositories provide vector similarity search capabilities, but Milvus offers more advanced features and scalability options, while Qdrant focuses on simplicity and ease of use for smaller-scale applications.
Weaviate is an open-source vector database that stores both objects and vectors, allowing for the combination of vector search with structured filtering with the fault tolerance and scalability of a cloud-native database.
Pros of Weaviate
- More flexible data model with support for multiple vector fields per object
- Built-in GraphQL API for easier querying and integration
- Supports a wider range of machine learning models and integrations
Cons of Weaviate
- Generally slower performance for large-scale vector search operations
- More complex setup and configuration process
- Higher resource requirements for deployment and operation
Code Comparison
Qdrant query example:
client.search(
collection_name="my_collection",
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=5
)
Weaviate query example:
{
Get {
MyClass(
nearVector: {
vector: [0.2, 0.1, 0.9, 0.7]
}
limit: 5
) {
name
description
}
}
}
Both Qdrant and Weaviate are vector databases designed for similarity search and machine learning applications. Qdrant focuses on performance and simplicity, while Weaviate offers more flexibility and integration options. The choice between them depends on specific project requirements, such as scalability needs, data model complexity, and preferred query interfaces.
A library for efficient similarity search and clustering of dense vectors.
Pros of Faiss
- Highly optimized for CPU and GPU, offering excellent performance for large-scale similarity search
- Supports a wide range of indexing algorithms and distance metrics
- Extensive documentation and a large community for support
Cons of Faiss
- Primarily focused on vector similarity search, lacking built-in features for full-text search or filtering
- Requires more manual setup and management compared to Qdrant's out-of-the-box solution
- Limited support for distributed deployments and scalability
Code Comparison
Qdrant (Rust):
let client = QdrantClient::new(Some("http://localhost:6334")).await?;
client.upsert_points("collection_name", None, points, None).await?;
let search_result = client.search_points(&search_request).await?;
Faiss (Python):
index = faiss.IndexFlatL2(dimension)
index.add(vectors)
distances, indices = index.search(query_vector, k)
Both libraries offer efficient vector search capabilities, but Qdrant provides a higher-level API with built-in HTTP server and persistence, while Faiss offers lower-level control and optimization options. Qdrant is designed for production-ready vector search services, whereas Faiss is more suitable for integration into custom applications requiring fine-tuned similarity search.
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
Pros of Annoy
- Lightweight and easy to integrate into existing Python projects
- Optimized for memory usage, allowing for efficient handling of large datasets
- Supports both approximate and exact nearest neighbor search
Cons of Annoy
- Limited to static datasets; doesn't support dynamic updates
- Primarily designed for Python, with limited support for other languages
- Less feature-rich compared to Qdrant, focusing mainly on ANN search
Code Comparison
Annoy:
from annoy import AnnoyIndex
index = AnnoyIndex(100, 'angular')
for i in range(1000):
v = [random.gauss(0, 1) for z in range(100)]
index.add_item(i, v)
index.build(10)
Qdrant:
use qdrant_client::prelude::*;
let client = QdrantClient::new(Some("http://localhost:6334")).unwrap();
let collection_name = "example_collection";
client.create_collection(&CreateCollection {
collection_name: collection_name.to_string(),
vectors_config: Some(VectorsConfig::new(100, Distance::Cosine)),
..Default::default()
}).await?;
The code snippets demonstrate the basic setup and initialization process for each library. Annoy focuses on creating and building an index for ANN search, while Qdrant showcases the creation of a collection with vector configuration.
Header-only C++/python library for fast approximate nearest neighbors
Pros of hnswlib
- Lightweight and focused library for approximate nearest neighbor search
- Highly optimized C++ implementation with Python bindings
- Easier to integrate into existing projects as a component
Cons of hnswlib
- Limited to in-memory operations, not suitable for large-scale persistent storage
- Lacks built-in features for distributed computing and scalability
- No built-in support for filtering or complex queries
Code Comparison
hnswlib:
import hnswlib
index = hnswlib.Index(space='l2', dim=128)
index.init_index(max_elements=100000, ef_construction=200, M=16)
index.add_items(data, ids)
labels, distances = index.knn_query(query, k=10)
Qdrant:
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
client.upsert(collection_name="example", points=points)
results = client.search(collection_name="example", query_vector=query_vector, limit=10)
Summary
hnswlib is a specialized library for approximate nearest neighbor search, offering high performance and easy integration. However, it lacks features for persistence, scalability, and complex querying. Qdrant, on the other hand, provides a more comprehensive vector database solution with additional features like filtering and distributed computing, but may have a steeper learning curve for simple use cases.
Free and Open Source, Distributed, RESTful Search Engine
Pros of Elasticsearch
- Mature ecosystem with extensive documentation and community support
- Powerful full-text search capabilities and advanced querying options
- Scalable and distributed architecture for handling large datasets
Cons of Elasticsearch
- Higher resource consumption and complexity for small-scale deployments
- Steeper learning curve for configuration and optimization
- Less efficient for vector search operations compared to specialized solutions
Code Comparison
Elasticsearch query example:
GET /my_index/_search
{
"query": {
"match": {
"title": "vector search"
}
}
}
Qdrant query example:
client.search(
collection_name="my_collection",
query_vector=[0.2, 0.1, 0.9, 0.7],
limit=10
)
Elasticsearch is a versatile search engine with powerful text search capabilities, while Qdrant is specifically designed for vector similarity search. Elasticsearch offers a more comprehensive set of features for general-purpose search and analytics, but Qdrant provides a simpler and more efficient solution for vector-based operations. The choice between the two depends on the specific use case and requirements of the project.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
![]()
Vector Search Engine for the next generation of AI applications



![]()
![]()
Qdrant (read: quadrant) is a vector similarity search engine and vector database. It provides a production-ready service with a convenient API to store, search, and manage pointsâvectors with an additional payload Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural-network or semantic-based matching, faceted search, and other applications.
Qdrant is written in Rust ð¦, which makes it fast and reliable even under high load. See benchmarks.
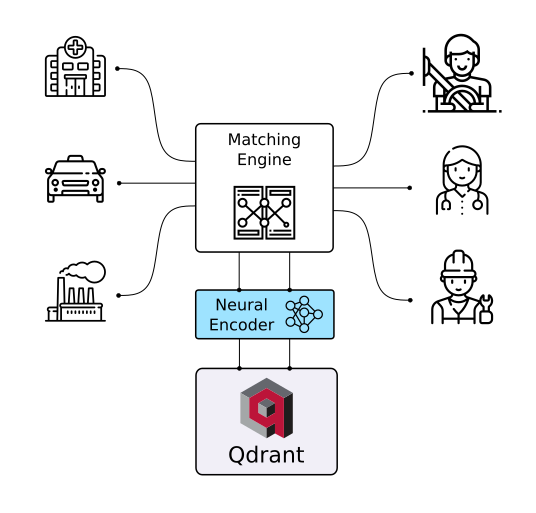
With Qdrant, embeddings or neural network encoders can be turned into full-fledged applications for matching, searching, recommending, and much more!
Qdrant is also available as a fully managed Qdrant Cloud â including a free tier.
Quick Start ⢠Client Libraries ⢠Demo Projects ⢠Integrations ⢠Contact
Getting Started
Python
pip install qdrant-client
The python client offers a convenient way to start with Qdrant locally:
from qdrant_client import QdrantClient
qdrant = QdrantClient(":memory:") # Create in-memory Qdrant instance, for testing, CI/CD
# OR
client = QdrantClient(path="path/to/db") # Persists changes to disk, fast prototyping
Client-Server
To experience the full power of Qdrant locally, run the container with this command:
docker run -p 6333:6333 qdrant/qdrant
Now you can connect to this with any client, including Python:
qdrant = QdrantClient("http://localhost:6333") # Connect to existing Qdrant instance
Before deploying Qdrant to production, be sure to read our installation and security guides.
Clients
Qdrant offers the following client libraries to help you integrate it into your application stack with ease:
- Official:
- Community:
Where do I go from here?
- Quick Start Guide
- End to End Colab Notebook demo with SentenceBERT and Qdrant
- Detailed Documentation are great starting points
- Step-by-Step Tutorial to create your first neural network project with Qdrant
Demo Projects 
Discover Semantic Text Search ð
Unlock the power of semantic embeddings with Qdrant, transcending keyword-based search to find meaningful connections in short texts. Deploy a neural search in minutes using a pre-trained neural network, and experience the future of text search. Try it online!
Explore Similar Image Search - Food Discovery ð
There's more to discovery than text search, especially when it comes to food. People often choose meals based on appearance rather than descriptions and ingredients. Let Qdrant help your users find their next delicious meal using visual search, even if they don't know the dish's name. Check it out!
Master Extreme Classification - E-commerce Product Categorization ðº
Enter the cutting-edge realm of extreme classification, an emerging machine learning field tackling multi-class and multi-label problems with millions of labels. Harness the potential of similarity learning models, and see how a pre-trained transformer model and Qdrant can revolutionize e-commerce product categorization. Play with it online!
More solutions
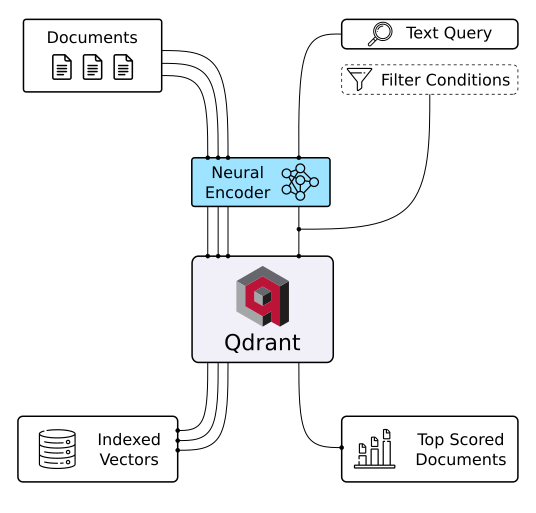
|
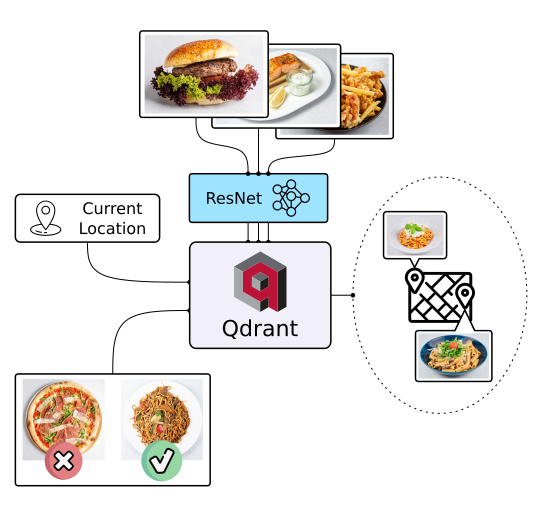
|
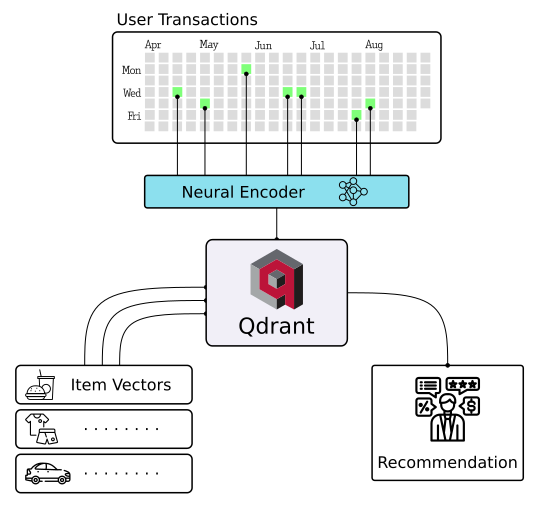
|
| Semantic Text Search | Similar Image Search | Recommendations |
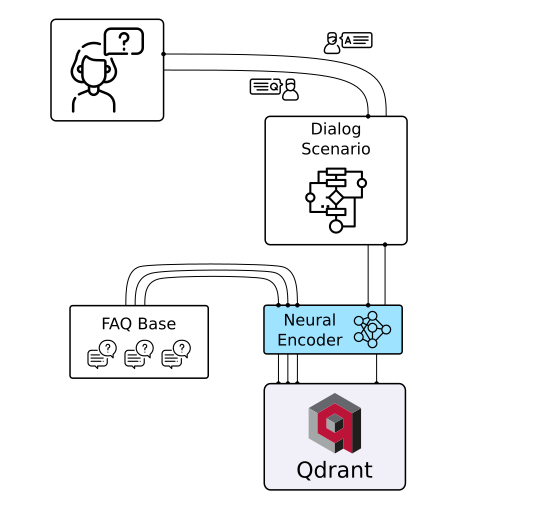
|
|

|
| Chat Bots | Matching Engines | Anomaly Detection |
API
REST
Online OpenAPI 3.0 documentation is available here. OpenAPI makes it easy to generate a client for virtually any framework or programming language.
You can also download raw OpenAPI definitions.
gRPC
For faster production-tier searches, Qdrant also provides a gRPC interface. You can find gRPC documentation here.
Features
Filtering and Payload
Qdrant can attach any JSON payloads to vectors, allowing for both the storage and filtering of data based on the values in these payloads. Payload supports a wide range of data types and query conditions, including keyword matching, full-text filtering, numerical ranges, geo-locations, and more.
Filtering conditions can be combined in various ways, including should, must, and must_not clauses,
ensuring that you can implement any desired business logic on top of similarity matching.
Hybrid Search with Sparse Vectors
To address the limitations of vector embeddings when searching for specific keywords, Qdrant introduces support for sparse vectors in addition to the regular dense ones.
Sparse vectors can be viewed as an generalization of BM25 or TF-IDF ranking. They enable you to harness the capabilities of transformer-based neural networks to weigh individual tokens effectively.
Vector Quantization and On-Disk Storage
Qdrant provides multiple options to make vector search cheaper and more resource-efficient. Built-in vector quantization reduces RAM usage by up to 97% and dynamically manages the trade-off between search speed and precision.
Distributed Deployment
Qdrant offers comprehensive horizontal scaling support through two key mechanisms:
- Size expansion via sharding and throughput enhancement via replication
- Zero-downtime rolling updates and seamless dynamic scaling of the collections
Highlighted Features
- Query Planning and Payload Indexes - leverages stored payload information to optimize query execution strategy.
- SIMD Hardware Acceleration - utilizes modern CPU x86-x64 and Neon architectures to deliver better performance.
- Async I/O - uses
io_uringto maximize disk throughput utilization even on a network-attached storage. - Write-Ahead Logging - ensures data persistence with update confirmation, even during power outages.
Integrations
Examples and/or documentation of Qdrant integrations:
- Cohere (blogpost on building a QA app with Cohere and Qdrant) - Use Cohere embeddings with Qdrant
- DocArray - Use Qdrant as a document store in DocArray
- Haystack - Use Qdrant as a document store with Haystack (blogpost).
- LangChain (blogpost) - Use Qdrant as a memory backend for LangChain.
- LlamaIndex - Use Qdrant as a Vector Store with LlamaIndex.
- OpenAI - ChatGPT retrieval plugin - Use Qdrant as a memory backend for ChatGPT
- Microsoft Semantic Kernel - Use Qdrant as persistent memory with Semantic Kernel
Contacts
- Have questions? Join our Discord channel or mention @qdrant_engine on Twitter
- Want to stay in touch with latest releases? Subscribe to our Newsletters
- Looking for a managed cloud? Check pricing, need something personalised? We're at info@qdrant.tech
License
Qdrant is licensed under the Apache License, Version 2.0. View a copy of the License file.
Top Related Projects
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Weaviate is an open-source vector database that stores both objects and vectors, allowing for the combination of vector search with structured filtering with the fault tolerance and scalability of a cloud-native database.
A library for efficient similarity search and clustering of dense vectors.
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
Header-only C++/python library for fast approximate nearest neighbors
Free and Open Source, Distributed, RESTful Search Engine
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot