
Top Related Projects

Apache Superset is a Data Visualization and Data Exploration Platform

The easy-to-use open source Business Intelligence and Embedded Analytics tool that lets everyone work with data :bar_chart:

Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.

The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Quick Overview
Hue is an open-source SQL Assistant for Data Warehouses, providing a web-based interface for querying and visualizing data. It supports multiple databases and data warehouses, offering features like SQL autocomplete, query optimization, and collaborative tools for data analysts and engineers.
Pros
- User-friendly interface with a rich set of features for data exploration and analysis
- Supports multiple databases and data warehouses, including Hive, Impala, Presto, and more
- Offers advanced SQL editing capabilities, including autocomplete and syntax highlighting
- Provides collaborative features for team-based data analysis and sharing
Cons
- Can be complex to set up and configure, especially for beginners
- May require significant resources to run efficiently, especially with large datasets
- Some users report occasional stability issues and bugs
- Limited customization options for the user interface
Getting Started
To get started with Hue, follow these steps:
- Install Hue using Docker:
docker run -it -p 8888:8888 gethue/hue:latest
-
Access Hue in your web browser at
http://localhost:8888 -
Configure your database connections in the Hue interface
-
Start querying and analyzing your data using the SQL Editor and other available tools
For more detailed installation and configuration instructions, refer to the official Hue documentation at https://docs.gethue.com/
Competitor Comparisons
Apache Superset is a Data Visualization and Data Exploration Platform
Pros of Superset
- More modern and feature-rich data visualization capabilities
- Stronger focus on business intelligence and analytics
- Active development with frequent updates and community contributions
Cons of Superset
- Steeper learning curve for non-technical users
- Less integrated with Hadoop ecosystem compared to Hue
- May require more setup and configuration for certain data sources
Code Comparison
Superset (Python):
from superset import db
from superset.models import Slice
slices = db.session.query(Slice).all()
for s in slices:
print(f"Slice: {s.slice_name}, Chart Type: {s.viz_type}")
Hue (Python):
from desktop.models import Document2
documents = Document2.objects.filter(type='query-hive')
for doc in documents:
print(f"Query: {doc.name}, Owner: {doc.owner}")
Both repositories use Python, but Superset focuses on data visualization and analytics, while Hue is more oriented towards Hadoop ecosystem integration and query management. Superset's code example demonstrates working with chart slices, while Hue's example shows querying Hive documents.
The easy-to-use open source Business Intelligence and Embedded Analytics tool that lets everyone work with data :bar_chart:
Pros of Metabase
- More user-friendly interface for non-technical users
- Supports a wider range of data sources out-of-the-box
- Faster setup and deployment process
Cons of Metabase
- Less customizable than Hue for advanced users
- Limited support for big data processing frameworks
- Fewer integration options with Hadoop ecosystem
Code Comparison
Metabase (JavaScript):
const question = Question.create({
databaseId: 1,
tableId: 2,
metadata: metadata
})
.query()
.aggregate(["count"])
.filter(["=", ["field", 1, null], "value"]);
Hue (Python):
from beeswax.design import hql_query
query = hql_query("SELECT COUNT(*) FROM table WHERE column = 'value'")
handle = execute_and_wait(query)
results = fetch_result(handle)
Both repositories provide data visualization and exploration tools, but they cater to different user bases and use cases. Metabase focuses on simplicity and ease of use for business users, while Hue offers more advanced features for data engineers and analysts working with big data technologies. The code examples demonstrate the different approaches: Metabase uses a JavaScript API for query building, while Hue relies on HiveQL queries executed through a Python interface.
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Pros of Redash
- More lightweight and easier to set up compared to Hue
- Supports a wider range of data sources out of the box
- More modern and user-friendly interface for data visualization
Cons of Redash
- Less integrated with Hadoop ecosystem
- Fewer advanced features for data exploration and manipulation
- Limited support for complex workflows and job scheduling
Code Comparison
Redash query execution:
query_result = execute_query(query)
data = json.loads(query_result.data)
Hue query execution:
query = hive.create_query(query_string)
handle = query.execute()
results = query.fetch()
Both Redash and Hue are open-source data exploration and visualization tools, but they have different focuses. Redash is more geared towards modern data analytics and dashboarding, while Hue is deeply integrated with the Hadoop ecosystem and offers more comprehensive data processing capabilities.
Redash excels in its simplicity and ease of use, making it a popular choice for teams looking for quick insights from various data sources. On the other hand, Hue provides a more robust set of features for working with big data platforms, including advanced SQL editors, workflow management, and tight integration with Hadoop services.
The code examples show that both tools offer programmatic ways to execute queries, but Hue's approach is more tightly coupled with Hadoop-specific components like Hive.
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
Pros of Zeppelin
- More versatile with support for multiple interpreters (SQL, Scala, Python, R, etc.)
- Better suited for data exploration and visualization with built-in charting capabilities
- Active development with frequent updates and community contributions
Cons of Zeppelin
- Steeper learning curve for non-technical users
- Less integrated with Hadoop ecosystem compared to Hue
- May require more setup and configuration for enterprise environments
Code Comparison
Hue (SQL query):
SELECT * FROM customers
WHERE country = 'USA'
LIMIT 10;
Zeppelin (SQL query with visualization):
%sql
SELECT country, COUNT(*) as count
FROM customers
GROUP BY country
ORDER BY count DESC
LIMIT 10
%spark.pyspark
z.show(df)
Summary
Zeppelin offers more flexibility for data analysis across various languages and provides built-in visualization tools. However, Hue is more user-friendly for SQL-focused tasks and integrates better with Hadoop. The choice between them depends on specific use cases and user preferences.
The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
Pros of Grafana
- More versatile data visualization capabilities, supporting a wider range of data sources
- Stronger focus on time-series data and real-time monitoring
- Larger and more active community, resulting in frequent updates and extensive plugin ecosystem
Cons of Grafana
- Less integrated with Hadoop ecosystem and big data tools
- Steeper learning curve for users primarily working with SQL and Hadoop
Code Comparison
Grafana (JavaScript):
const panel = new PanelModel({
type: 'graph',
title: 'CPU Usage',
datasource: 'Prometheus',
targets: [{ expr: 'node_cpu_utilization' }],
});
Hue (Python):
from desktop.lib.connectors.models import Connector
connector = Connector.objects.get(name='Impala')
query = 'SELECT * FROM cpu_usage LIMIT 10'
result = connector.execute(query)
Summary
Grafana excels in data visualization and monitoring, particularly for time-series data, with a large community and plugin ecosystem. Hue, on the other hand, is more tightly integrated with the Hadoop ecosystem and focuses on SQL query execution and big data workflows. The choice between the two depends on the specific use case and existing technology stack.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Pros of Airflow
- More robust and scalable workflow orchestration capabilities
- Larger and more active community, leading to frequent updates and extensive plugin ecosystem
- Better suited for complex data pipelines and ETL processes
Cons of Airflow
- Steeper learning curve, especially for users new to workflow management
- Requires more infrastructure setup and maintenance compared to Hue
- Less user-friendly interface for ad-hoc querying and data exploration
Code Comparison
Airflow DAG definition:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
dag = DAG('example_dag', start_date=datetime(2023, 1, 1))
def task_function():
print("Executing task")
task = PythonOperator(
task_id='example_task',
python_callable=task_function,
dag=dag
)
Hue SQL query:
SELECT column1, column2
FROM table_name
WHERE condition
LIMIT 10;
While both repositories serve different primary purposes, this comparison highlights the strengths of Airflow in workflow management and Hue's focus on user-friendly data exploration and querying.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Hue - SQL Assistant for Databases and Data Warehouses
![]()




![]()
Query. Explore. Share.
ðï¸ Overview
Hue is a mature SQL Assistant for querying Databases & Data Warehouses, trusted by:
- 1000+ customers worldwide
- Top Fortune 500 enterprises
Organizations use Hue to quickly answer questions via self-service querying, executing hundreds of thousands of queries daily.
Key Features
- âï¸ Interactive SQL editing with syntax highlighting and autocomplete
- ð File Browser for navigating and operating on HDFS, S3, ABFS, Ozone, and Google Storage (GS) files
- ð Job Browser for monitoring and managing Hive queries, Impala queries, YARN applications, and Livy Spark jobs
- ðï¸ Table Browser for exploring and managing database tables, schemas, and metadata
- ð¤ Table Importer for creating Hive and Impala tables from CSV/Excel files, with support for uploading from local system or importing from remote filesystems (HDFS, S3, ABFS, Ozone, GS)
- ð Multiple database connectors including Hive, Impala, MySQL, PostgreSQL, and more
ð Useful Links
- ð Website: gethue.com
- ð Connect to a database: Configuration Guide
- ð ï¸ Build your own Editor: SQL Scratchpad
- âï¸ Query Service: Kubernetes Setup and API
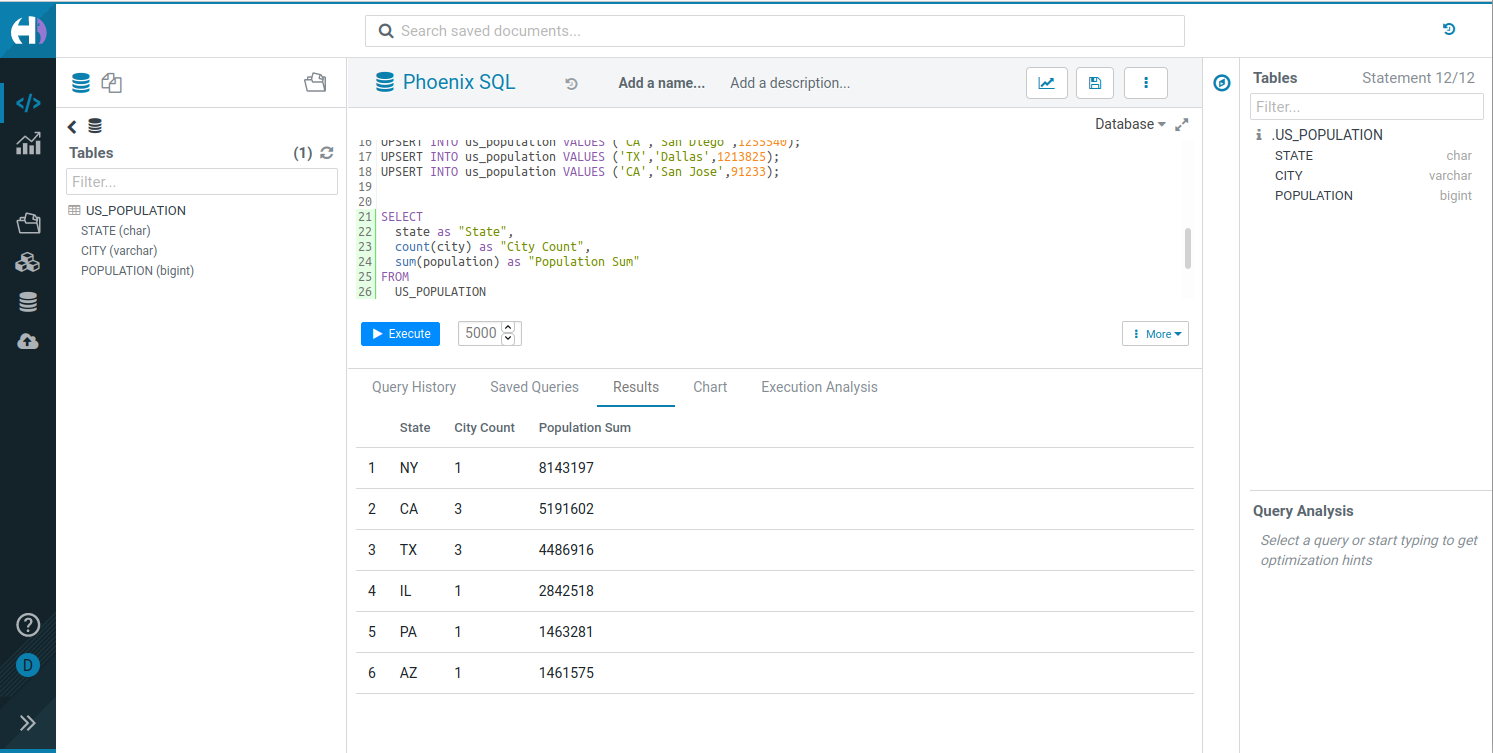
ð Getting Started
Try Hue Now
- ð Live demo: demo.gethue.com
- 𧪠Quick integrations:
Choose one of these deployment options to start the server, then configure the databases you want to query:
ð³ Docker
Start Hue instantly:
docker run -it -p 8888:8888 gethue/hue:latest
Hue will be available at http://localhost:8888
ð See the Docker Guide or watch the Quick Start Video
â¸ï¸ Kubernetes
helm repo add gethue https://helm.gethue.com
helm repo update
helm install hue gethue/hue
ð Read more about configurations in the Kubernetes docs
ð» Development Setup
Quick Start with Docker
Use the Dev Environment Docker for the fastest setup.
Manual Setup
- Install dependencies
- Clone and build:
git clone https://github.com/cloudera/hue.git
cd hue
make apps
build/env/bin/hue runserver
Hue will be available at http://localhost:8000
ð Read more in the development documentation
𧩠Components
Hue offers several powerful components:
- SQL Editor - Interactive query interface
- SQL Parsers - Syntax handling for multiple dialects
- REST/Python/CLI APIs - Programmatic access to all functionality
ð Learn about components and APIs
ð¤ Contributing
We welcome contributions! Please see our CONTRIBUTING.md guide to get started.
ð License
Top Related Projects
Apache Superset is a Data Visualization and Data Exploration Platform
The easy-to-use open source Business Intelligence and Embedded Analytics tool that lets everyone work with data :bar_chart:
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot