 dbt-core
dbt-core
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
Top Related Projects
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.

Apache Airflow - A platform to programmatically author, schedule, and monitor workflows

Prefect is a workflow orchestration framework for building resilient data pipelines in Python.

An orchestration platform for the development, production, and observation of data assets.

Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.
Quick Overview
dbt-core is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouses more effectively. It allows users to write, document, and execute data transformations using SQL, while leveraging software engineering best practices like modularity, portability, CI/CD, and documentation.
Pros
- Promotes version control and collaboration for data transformations
- Supports multiple data warehouses (Snowflake, BigQuery, Redshift, etc.)
- Encourages modular and reusable SQL code
- Provides built-in testing and documentation features
Cons
- Steep learning curve for those new to data modeling or software engineering practices
- Limited support for real-time or streaming data processing
- Can be overkill for small projects or simple data transformations
- Requires additional setup and maintenance compared to writing raw SQL
Code Examples
- Creating a dbt model:
-- models/customers.sql
{{ config(materialized='table') }}
SELECT
id,
first_name,
last_name,
email
FROM {{ source('raw', 'customers') }}
WHERE status = 'active'
- Defining a source:
# models/sources.yml
version: 2
sources:
- name: raw
database: my_database
schema: public
tables:
- name: customers
- name: orders
- Writing a test:
# models/schema.yml
version: 2
models:
- name: customers
columns:
- name: id
tests:
- unique
- not_null
- name: email
tests:
- unique
Getting Started
- Install dbt:
pip install dbt-core
- Initialize a new dbt project:
dbt init my_project
cd my_project
-
Configure your
profiles.ymlfile with your data warehouse credentials. -
Create your first model in the
models/directory. -
Run dbt:
dbt run
Competitor Comparisons
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
Pros of dbt-core
- Open-source data transformation tool with a large community
- Supports multiple data warehouses and integrates well with modern data stack
- Provides version control and CI/CD capabilities for data transformations
Cons of dbt-core
- Learning curve for SQL-based modeling and dbt-specific concepts
- Limited built-in data quality testing features
- May require additional tools for comprehensive data pipeline management
Code Comparison
Both repositories refer to the same project, so there's no code comparison to be made. However, here's a sample of dbt-core code:
{{ config(materialized='table') }}
SELECT
id,
name,
created_at
FROM {{ source('raw_data', 'users') }}
WHERE created_at >= '2023-01-01'
This example demonstrates a typical dbt model, showcasing the use of Jinja templating, configuration blocks, and source references.
Summary
dbt-core is a powerful open-source tool for data transformation and modeling. It offers strong version control and CI/CD capabilities but may have a learning curve for new users. While it supports multiple data warehouses, some users might find its built-in data quality testing features limited. Overall, dbt-core is widely adopted in the data community and integrates well with modern data stacks.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Pros of Airflow
- More versatile for general-purpose workflow orchestration across various data sources and systems
- Robust scheduling capabilities with complex dependencies and retry mechanisms
- Large ecosystem of plugins and integrators for diverse data platforms
Cons of Airflow
- Steeper learning curve due to its broader scope and Python-based configuration
- Can be resource-intensive for smaller projects or organizations
- Requires more setup and maintenance compared to dbt's focused approach
Code Comparison
dbt-core:
models:
- name: my_model
columns:
- name: id
tests:
- unique
- not_null
Airflow:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
def my_function():
# Task logic here
pass
dag = DAG('my_dag', schedule_interval='@daily')
task = PythonOperator(task_id='my_task', python_callable=my_function, dag=dag)
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
Pros of Prefect
- More versatile for general-purpose workflow orchestration
- Supports a wider range of data sources and integrations
- Offers real-time monitoring and dynamic workflow adjustments
Cons of Prefect
- Steeper learning curve for beginners
- Less specialized for data transformation tasks
- Requires more setup and configuration for data warehousing projects
Code Comparison
Prefect task definition:
@task
def process_data(data):
# Data processing logic here
return processed_data
with Flow("data_pipeline") as flow:
raw_data = get_data()
processed = process_data(raw_data)
dbt-core model definition:
-- models/my_model.sql
SELECT *
FROM {{ source('raw_data', 'table') }}
WHERE status = 'active'
Summary
Prefect is a more general-purpose workflow orchestration tool, while dbt-core focuses specifically on data transformation and modeling within data warehouses. Prefect offers greater flexibility and broader integration capabilities, but may require more setup and have a steeper learning curve. dbt-core excels in simplifying data transformations and maintaining data lineage, making it more accessible for data analysts and engineers working primarily with SQL and data warehouses.
An orchestration platform for the development, production, and observation of data assets.
Pros of Dagster
- More comprehensive data orchestration platform, handling entire data pipelines
- Supports a wider range of data processing tasks beyond just SQL transformations
- Offers a rich UI for monitoring and debugging data workflows
Cons of Dagster
- Steeper learning curve due to its broader scope and functionality
- Less specialized for SQL-based transformations compared to dbt-core
- May be overkill for projects primarily focused on data modeling
Code Comparison
Dagster example:
@solid
def process_data(context, data):
# Data processing logic here
return processed_data
@pipeline
def my_pipeline():
process_data()
dbt-core example:
-- models/my_model.sql
SELECT *
FROM {{ source('raw_data', 'table') }}
WHERE status = 'active'
Both tools serve different purposes in the data engineering ecosystem. Dagster is a more comprehensive data orchestration platform, while dbt-core focuses specifically on SQL-based transformations and data modeling. The choice between them depends on the specific needs of your data project and the complexity of your data workflows.
Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.
Pros of Meltano
- Offers a complete ELT pipeline solution, including data extraction and loading
- Provides a user-friendly UI for managing data pipelines
- Supports a wider range of data sources and destinations out-of-the-box
Cons of Meltano
- Less mature and smaller community compared to dbt-core
- Steeper learning curve due to its all-in-one approach
- May be overkill for projects that only require data transformation
Code Comparison
Meltano (pipeline configuration):
extractors:
- name: tap-gitlab
pip_url: git+https://github.com/meltano/tap-gitlab.git
loaders:
- name: target-snowflake
pip_url: target-snowflake
dbt-core (model definition):
{{ config(materialized='table') }}
SELECT *
FROM {{ source('raw_data', 'users') }}
WHERE status = 'active'
Both projects serve different purposes in the data stack. Meltano focuses on end-to-end ELT pipelines, while dbt-core specializes in data transformation. The choice between them depends on project requirements and existing infrastructure.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME

![]()
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.

Understanding dbt
Analysts using dbt can transform their data by simply writing select statements, while dbt handles turning these statements into tables and views in a data warehouse.
These select statements, or "models", form a dbt project. Models frequently build on top of one another â dbt makes it easy to manage relationships between models, and visualize these relationships, as well as assure the quality of your transformations through testing.
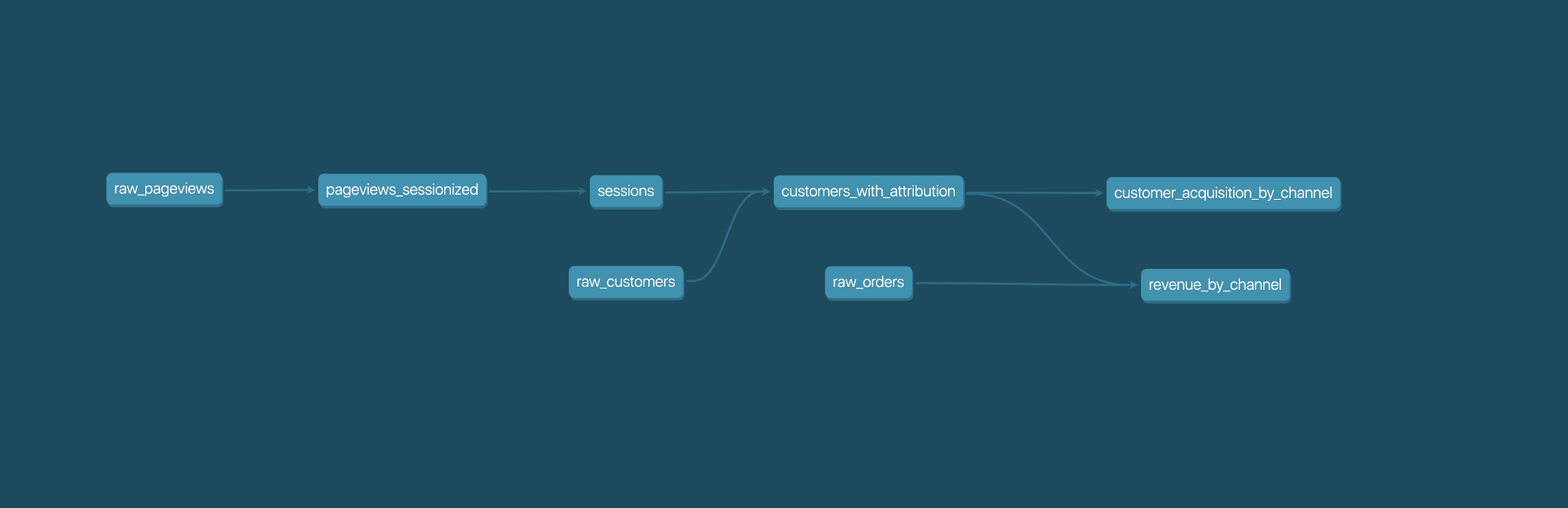
Getting started
- Install dbt Core or explore the dbt Cloud CLI, a command-line interface powered by dbt Cloud that enhances collaboration.
- Read the introduction and viewpoint
Join the dbt Community
- Be part of the conversation in the dbt Community Slack
- Read more on the dbt Community Discourse
Reporting bugs and contributing code
- Want to report a bug or request a feature? Let us know and open an issue
- Want to help us build dbt? Check out the Contributing Guide
Code of Conduct
Everyone interacting in the dbt project's codebases, issue trackers, chat rooms, and mailing lists is expected to follow the dbt Code of Conduct.
Top Related Projects
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
An orchestration platform for the development, production, and observation of data assets.
Meltano: the declarative code-first data integration engine that powers your wildest data and ML-powered product ideas. Say goodbye to writing, maintaining, and scaling your own API integrations.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot