
Top Related Projects

Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk

A library for efficient similarity search and clustering of dense vectors.

Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.

Uniform Manifold Approximation and Projection

Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search

Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/
Quick Overview
Ann-benchmarks is an open-source project that provides benchmarks for approximate nearest neighbor (ANN) search algorithms. It compares various ANN libraries and algorithms across different datasets, offering insights into their performance, accuracy, and build time.
Pros
- Comprehensive comparison of multiple ANN algorithms and libraries
- Includes diverse datasets for thorough testing
- Regularly updated with new algorithms and libraries
- Provides reproducible results and easy-to-understand visualizations
Cons
- May not always include the latest versions of all libraries
- Limited to specific hardware configurations, which may not reflect all use cases
- Focuses primarily on Python implementations, potentially overlooking other language-specific optimizations
- Can be computationally intensive to run all benchmarks
Code Examples
# Example 1: Running a specific benchmark
python run.py --dataset glove-100-angular --algorithm annoy
# Example 2: Generating plots for a specific dataset
python plot.py --dataset sift-128-euclidean
# Example 3: Creating a new algorithm definition
class MyAlgorithm(BaseANN):
def __init__(self, metric, dimension):
self.name = 'MyAlgorithm'
self.metric = metric
self.dimension = dimension
def fit(self, X):
# Implementation of index building
def query(self, v, n):
# Implementation of query
Getting Started
To get started with ann-benchmarks:
-
Clone the repository:
git clone https://github.com/erikbern/ann-benchmarks.git cd ann-benchmarks -
Install dependencies:
pip install -r requirements.txt -
Run a benchmark:
python run.py --dataset glove-25-angular --algorithm faiss -
Generate plots:
python plot.py --dataset glove-25-angular
Competitor Comparisons
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
Pros of Annoy
- Focused library for Approximate Nearest Neighbors (ANN) search
- Optimized for production use, particularly in music recommendation systems
- Lightweight and easy to integrate into existing projects
Cons of Annoy
- Limited to a specific ANN algorithm (random projection trees)
- Not designed for benchmarking or comparing different ANN algorithms
- May not be suitable for all types of datasets or use cases
Code Comparison
ann-benchmarks:
import ann_benchmarks
dataset = ann_benchmarks.datasets.random(1000, 100)
algorithm = ann_benchmarks.algorithms.annoy(n_trees=10)
results = ann_benchmarks.run(algorithm, dataset)
Annoy:
from annoy import AnnoyIndex
index = AnnoyIndex(100, 'angular')
for i, v in enumerate(vectors):
index.add_item(i, v)
index.build(10)
Key Differences
ann-benchmarks is a comprehensive benchmarking tool for various ANN algorithms, while Annoy is a specific implementation of an ANN algorithm. ann-benchmarks allows for comparison and evaluation of different approaches, whereas Annoy is designed for practical use in production environments, particularly for music recommendation systems.
ann-benchmarks provides a standardized framework for testing and comparing ANN algorithms across different datasets and metrics. Annoy, on the other hand, focuses on providing a fast and memory-efficient implementation of a single ANN algorithm, optimized for specific use cases like Spotify's music recommendation system.
A library for efficient similarity search and clustering of dense vectors.
Pros of Faiss
- Highly optimized C++ library with Python bindings, offering superior performance
- Extensive range of indexing algorithms and techniques for various use cases
- Actively maintained by Facebook AI Research with regular updates and improvements
Cons of Faiss
- Steeper learning curve due to its comprehensive feature set
- Requires more setup and configuration compared to ann-benchmarks
- Limited to similarity search and clustering tasks
Code Comparison
ann-benchmarks:
import numpy as np
from ann_benchmarks.algorithms.base import BaseANN
class ExampleAlgorithm(BaseANN):
def fit(self, X):
self.data = X
def query(self, v, n):
return [np.linalg.norm(self.data - v, axis=1).argsort()[:n]]
Faiss:
import faiss
import numpy as np
d = 64 # dimension
nb = 100000 # database size
nq = 10000 # number of queries
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
index = faiss.IndexFlatL2(d)
index.add(xb)
D, I = index.search(xq, k)
Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
Pros of nmslib
- Focuses on providing a comprehensive library for approximate nearest neighbor search
- Offers multiple indexing methods and search algorithms
- Provides bindings for multiple programming languages (C++, Python, Java)
Cons of nmslib
- Less emphasis on benchmarking and comparison with other ANN libraries
- May have a steeper learning curve due to its more extensive feature set
- Requires more setup and configuration for specific use cases
Code comparison
nmslib:
import nmslib
index = nmslib.init(method='hnsw', space='cosine')
index.addDataPointBatch(data)
index.createIndex({'post': 2})
ids, distances = index.knnQuery(query, k=10)
ann-benchmarks:
from ann_benchmarks.algorithms.nmslib import NMSlib
algo = NMSlib('cosine', 'hnsw')
algo.fit(data)
results = algo.query(queries, 10)
Summary
nmslib is a comprehensive library for approximate nearest neighbor search, offering multiple indexing methods and language bindings. ann-benchmarks, on the other hand, focuses on benchmarking various ANN libraries, including nmslib. While nmslib provides more flexibility and features, it may require more setup and have a steeper learning curve. ann-benchmarks offers a simpler interface for comparing different ANN algorithms but is primarily designed for benchmarking rather than production use.
Uniform Manifold Approximation and Projection
Pros of UMAP
- Focuses on dimensionality reduction and visualization
- Provides a more efficient and scalable alternative to t-SNE
- Offers better preservation of global structure in data
Cons of UMAP
- Limited to dimensionality reduction tasks
- May require more parameter tuning for optimal results
- Less comprehensive in terms of benchmarking different algorithms
Code Comparison
UMAP example:
import umap
reducer = umap.UMAP()
embedding = reducer.fit_transform(data)
ANN-Benchmarks example:
import ann_benchmarks
results = ann_benchmarks.run(dataset, algorithm)
ann_benchmarks.plot(results)
Summary
UMAP is a specialized library for dimensionality reduction and visualization, offering improved performance over t-SNE. It excels in preserving global structure but may require more tuning. ANN-Benchmarks, on the other hand, is a comprehensive benchmarking tool for various approximate nearest neighbor algorithms, providing a broader scope for comparison across different methods. While UMAP focuses on a specific task, ANN-Benchmarks offers a platform for evaluating and comparing multiple algorithms in the field of approximate nearest neighbor search.
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Pros of Milvus
- Full-featured vector database system with scalability and production-ready features
- Supports multiple index types and search algorithms for diverse use cases
- Provides a comprehensive API and client SDKs for easy integration
Cons of Milvus
- More complex setup and configuration compared to ANN-Benchmarks
- Requires more system resources and infrastructure to run effectively
- Steeper learning curve for users new to vector databases
Code Comparison
Milvus (Python client example):
from pymilvus import Collection, connections
connections.connect()
collection = Collection("example_collection")
results = collection.search(
data=[[1.0, 2.0, 3.0]],
anns_field="vector_field",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=5
)
ANN-Benchmarks (benchmark runner example):
import ann_benchmarks
dataset = ann_benchmarks.datasets.random(1000, 100)
algorithms = [
ann_benchmarks.algorithms.bruteforce,
ann_benchmarks.algorithms.annoy,
]
ann_benchmarks.run(dataset, algorithms)
The code examples highlight the different focus of each project. Milvus provides a client interface for interacting with a vector database, while ANN-Benchmarks offers a framework for running and comparing various ANN algorithms.
Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/
Pros of Qdrant
- Full-featured vector database with production-ready capabilities
- Supports complex filtering and payload storage alongside vector search
- Offers a RESTful API and client libraries for easy integration
Cons of Qdrant
- Focused on a single solution rather than benchmarking multiple algorithms
- May have a steeper learning curve for users new to vector databases
- Less flexibility in comparing different ANN algorithms
Code Comparison
ann-benchmarks:
import numpy
from ann_benchmarks.algorithms.base import BaseANN
class BruteForceBLAS(BaseANN):
def __init__(self, metric):
self.name = 'BruteForceBLAS(%s)' % metric
self._metric = metric
def fit(self, X):
self._db = X
Qdrant:
use qdrant_client::prelude::*;
let client = QdrantClient::new(Some(QdrantClientConfig::from_url("http://localhost:6334"))).await?;
client.create_collection(&CreateCollection {
collection_name: "my_collection".to_string(),
vectors_config: Some(VectorsConfig::Single(VectorParams {
size: 100,
distance: Distance::Cosine,
})),
..Default::default()
}).await?;
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
Benchmarking nearest neighbors

Doing fast searching of nearest neighbors in high dimensional spaces is an increasingly important problem with notably few empirical attempts at comparing approaches in an objective way, despite a clear need for such to drive optimization forward.
This project contains tools to benchmark various implementations of approximate nearest neighbor (ANN) search for selected metrics. We have pre-generated datasets (in HDF5 format) and prepared Docker containers for each algorithm, as well as a test suite to verify function integrity.
Evaluated
- Annoy
- FLANN
- scikit-learn: LSHForest, KDTree, BallTree
- Weaviate
- PANNS
- NearPy
- KGraph
- NMSLIB (Non-Metric Space Library)
: SWGraph, HNSW, BallTree, MPLSH
- hnswlib (a part of nmslib project)
- RPForest
- FAISS
- DolphinnPy
- Datasketch
- nndescent
- PyNNDescent
- MRPT
- NGT
: ONNG, PANNG, QG
- SPTAG
- PUFFINN
- N2
- ScaNN
- Vearch
- Elasticsearch
: HNSW
- Elastiknn
- ExpANN
- OpenSearch KNN
- DiskANN
: Vamana, Vamana-PQ
- Vespa
- scipy: cKDTree
- vald
- Qdrant
- HUAWEI(qsgngt)
- Milvus
: Knowhere
- Zilliz(Glass)
- pgvector
- pgvecto.rs
- RediSearch
- Descartes(01AI)
- kgn
- vsag
- PGVectorScale




























Data sets
We have a number of precomputed data sets in HDF5 format. All data sets have been pre-split into train/test and include ground truth data for the top-100 nearest neighbors.
| Dataset | Dimensions | Train size | Test size | Neighbors | Distance | Download |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidean | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidean | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angular | HDF5 (135MB) |
| COCO-I2I | 512 | 113,287 | 10,000 | 100 | Angular | HDF5 (136MB) |
| COCO-T2I | 512 | 113,287 | 10,000 | 100 | Angular | HDF5 (136MB) |
Results
These are all as of April 2025, running all benchmarks on a r6i.16xlarge machine on AWS with --parallelism 31 and hyperthreading disabled. All benchmarks are single-CPU.
glove-100-angular

sift-128-euclidean

fashion-mnist-784-euclidean

nytimes-256-angular

gist-960-euclidean
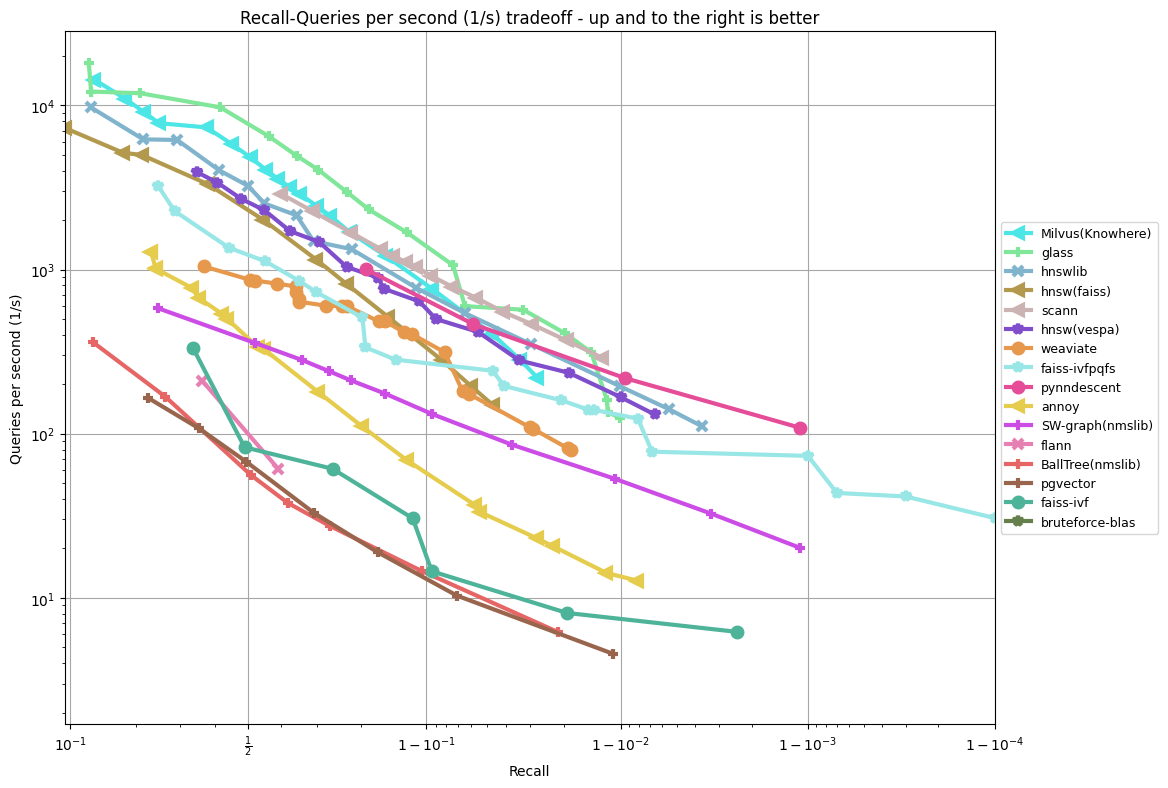
glove-25-angular

TODO: update plots on http://ann-benchmarks.com.
Install
The only prerequisite is Python (tested with 3.10.6) and Docker.
- Clone the repo.
- Run
pip install -r requirements.txt. - Run
python install.pyto build all the libraries inside Docker containers (this can take a while, like 10-30 minutes).
Running
- Run
python run.py(this can take an extremely long time, potentially days). - Run
python plot.py --x-scale logit --y-scale logto plot results. - Run
python create_website.pyto create a website with lots of plots.
You can customize the algorithms and datasets as follows:
- Check that
ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/config.ymlcontains the parameter settings that you want to test - To run experiments on SIFT, invoke
python run.py --dataset glove-100-angular. Seepython run.py --helpfor more information on possible settings. Note that experiments can take a long time. - To process the results, either use
python plot.py --dataset glove-100-angularorpython create_website.py. An example call:python create_website.py --plottype recall/time --latex --scatter --outputdir website/.
Including your algorithm
Add your algorithm in the folder ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/ by providing
- A small Python wrapper in
module.py - A Dockerfile named
Dockerfile - A set of hyper-parameters in
config.yml - A CI test run by adding your implementation to
.github/workflows/benchmarks.yml
Check the available implementations for inspiration.
Principles
- Everyone is welcome to submit pull requests with tweaks and changes to how each library is being used.
- In particular: if you are the author of any of these libraries, and you think the benchmark can be improved, consider making the improvement and submitting a pull request.
- This is meant to be an ongoing project and represent the current state.
- Make everything easy to replicate, including installing and preparing the datasets.
- Try many different values of parameters for each library and ignore the points that are not on the precision-performance frontier.
- High-dimensional datasets with approximately 100-1000 dimensions. This is challenging but also realistic. Not more than 1000 dimensions because those problems should probably be solved by doing dimensionality reduction separately.
- Single queries are used by default. ANN-Benchmarks enforces that only one CPU is saturated during experimentation, i.e., no multi-threading. A batch mode is available that provides all queries to the implementations at once. Add the flag
--batchtorun.pyandplot.pyto enable batch mode. - Avoid extremely costly index building (more than several hours).
- Focus on datasets that fit in RAM. For billion-scale benchmarks, see the related big-ann-benchmarks project.
- We mainly support CPU-based ANN algorithms. GPU support exists for FAISS, but it has to be compiled with GPU support locally and experiments must be run using the flags
--local --batch. - Do proper train/test set of index data and query points.
- Note that we consider that set similarity datasets are sparse and thus we pass a sorted array of integers to algorithms to represent the set of each user.
Authors
Built by Erik Bernhardsson with significant contributions from Martin Aumüller and Alexander Faithfull.
Related Publication
Design principles behind the benchmarking framework are described in the following publications:
- M. Aumüller, E. Bernhardsson, A. Faithfull: ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms. Information Systems 2019. DOI: 10.1016/j.is.2019.02.006
- M. Aumüller, E. Bernhardsson, A. Faithfull: Reproducibility protocol for ANN-Benchmarks: A benchmarking tool for approximate nearest neighbor search algorithms, Artifacts.
Related Projects
- big-ann-benchmarks is a benchmarking effort for billion-scale approximate nearest neighbor search as part of the NeurIPS'21 Competition track.
Top Related Projects
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
A library for efficient similarity search and clustering of dense vectors.
Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
Uniform Manifold Approximation and Projection
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot