 luigi
luigi
Luigi is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built in.
Top Related Projects

Apache Airflow - A platform to programmatically author, schedule, and monitor workflows

Prefect is a workflow orchestration framework for building resilient data pipelines in Python.

An orchestration platform for the development, production, and observation of data assets.

Always know what to expect from your data.
Apache Beam is a unified programming model for Batch and Streaming data processing.

Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
Quick Overview
Luigi is a Python package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, and more. Luigi was originally designed and built at Spotify, but has been released as an open-source project.
Pros
- Handles complex dependencies and task scheduling efficiently
- Provides a clear and intuitive way to define workflows
- Offers built-in support for various data sources and file systems
- Includes a web-based visualization tool for monitoring task progress
Cons
- Steep learning curve for beginners
- Limited support for real-time or streaming workflows
- Can be overkill for simple data processing tasks
- Requires careful design to avoid performance bottlenecks in large pipelines
Code Examples
- Defining a simple Luigi task:
import luigi
class MyTask(luigi.Task):
def requires(self):
return SomeOtherTask()
def output(self):
return luigi.LocalTarget("output.txt")
def run(self):
with self.output().open("w") as f:
f.write("Task completed")
- Running a Luigi task:
if __name__ == "__main__":
luigi.run(["MyTask", "--local-scheduler"])
- Defining a task with parameters:
class ParameterizedTask(luigi.Task):
date = luigi.DateParameter()
def output(self):
return luigi.LocalTarget(f"output-{self.date}.txt")
def run(self):
with self.output().open("w") as f:
f.write(f"Task completed for {self.date}")
Getting Started
To get started with Luigi, follow these steps:
- Install Luigi:
pip install luigi
- Create a Python file (e.g.,
my_workflow.py) and define your tasks:
import luigi
class MyTask(luigi.Task):
def output(self):
return luigi.LocalTarget("output.txt")
def run(self):
with self.output().open("w") as f:
f.write("Hello, Luigi!")
if __name__ == "__main__":
luigi.run(["MyTask", "--local-scheduler"])
- Run the workflow:
python my_workflow.py
This will execute the MyTask and create an output.txt file with the content "Hello, Luigi!".
Competitor Comparisons
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Pros of Airflow
- Rich web-based UI for monitoring and managing workflows
- Extensive plugin ecosystem and integrations with various services
- Dynamic pipeline generation using Python code
Cons of Airflow
- Steeper learning curve due to more complex architecture
- Higher resource requirements for setup and maintenance
- Potential overkill for simpler workflow needs
Code Comparison
Luigi:
class MyTask(luigi.Task):
def requires(self):
return SomeOtherTask()
def run(self):
# Task logic here
pass
def output(self):
return luigi.LocalTarget("output.txt")
Airflow:
def my_task():
# Task logic here
pass
with DAG('my_dag', start_date=datetime(2023, 1, 1)) as dag:
task = PythonOperator(
task_id='my_task',
python_callable=my_task
)
Summary
Airflow offers a more comprehensive solution for complex workflows with its rich UI and extensive integrations. However, it comes with a steeper learning curve and higher resource requirements. Luigi, on the other hand, provides a simpler, lightweight approach that may be more suitable for straightforward task dependencies. The choice between the two depends on the complexity of your workflows and the level of monitoring and management features required.
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
Pros of Prefect
- More modern and feature-rich workflow management system
- Better support for distributed and parallel execution
- Improved observability and monitoring capabilities
Cons of Prefect
- Steeper learning curve due to more complex architecture
- Requires more setup and configuration compared to Luigi
- Potentially overkill for simple workflow needs
Code Comparison
Luigi:
import luigi
class MyTask(luigi.Task):
def requires(self):
return SomeOtherTask()
def run(self):
# Task logic here
Prefect:
from prefect import task, Flow
@task
def my_task():
# Task logic here
with Flow("My Flow") as flow:
task_result = my_task()
Both Luigi and Prefect are workflow management systems, but they differ in their approach and features. Luigi is simpler and easier to get started with, making it suitable for smaller projects or teams new to workflow management. Prefect, on the other hand, offers more advanced features and better scalability, making it a good choice for larger, more complex projects that require distributed execution and advanced monitoring.
Luigi uses a class-based approach to define tasks, while Prefect uses decorators and a more functional style. Prefect's Flow object provides a more explicit way to define task dependencies and execution order.
An orchestration platform for the development, production, and observation of data assets.
Pros of Dagster
- More modern architecture with better support for containerization and cloud-native deployments
- Stronger type checking and data validation capabilities
- Richer UI for monitoring and debugging workflows
Cons of Dagster
- Steeper learning curve due to more complex concepts and abstractions
- Less mature ecosystem compared to Luigi's long-standing community and plugins
Code Comparison
Luigi example:
class MyTask(luigi.Task):
def requires(self):
return SomeOtherTask()
def run(self):
# Task logic here
with self.output().open('w') as f:
f.write('Done')
def output(self):
return luigi.LocalTarget('output.txt')
Dagster example:
@solid
def my_solid(context):
# Solid logic here
return 'Done'
@pipeline
def my_pipeline():
my_solid()
Summary
Dagster offers a more modern and type-safe approach to data orchestration, with better support for cloud-native environments. It provides a richer UI and stronger data validation capabilities. However, it has a steeper learning curve and a less mature ecosystem compared to Luigi.
Luigi, being older and more established, has a larger community and more plugins available. It's simpler to get started with but may lack some of the advanced features and architectural benefits of Dagster.
The choice between the two depends on specific project requirements, team expertise, and the complexity of the data workflows being managed.
Always know what to expect from your data.
Pros of Great Expectations
- Focuses on data quality and validation, providing a comprehensive framework for data testing
- Offers a user-friendly interface for creating and managing expectations
- Supports integration with various data sources and platforms
Cons of Great Expectations
- Steeper learning curve compared to Luigi's simpler task-based approach
- May require more setup and configuration for complex data pipelines
- Less suitable for general-purpose workflow management
Code Comparison
Luigi:
class MyTask(luigi.Task):
def requires(self):
return SomeOtherTask()
def run(self):
# Task logic here
with self.output().open('w') as f:
f.write('Done')
def output(self):
return luigi.LocalTarget('output.txt')
Great Expectations:
expectation_suite = context.create_expectation_suite("my_suite")
validator = context.get_validator(
batch_request=batch_request,
expectation_suite=expectation_suite
)
validator.expect_column_values_to_be_between(
"column_name", min_value=0, max_value=100
)
Both Luigi and Great Expectations are valuable tools in the data engineering ecosystem, but they serve different primary purposes. Luigi excels in workflow management and task orchestration, while Great Expectations specializes in data quality and validation. The choice between them depends on the specific needs of your data pipeline and project requirements.
Apache Beam is a unified programming model for Batch and Streaming data processing.
Pros of Beam
- Supports multiple programming languages (Java, Python, Go)
- Provides a unified model for batch and streaming data processing
- Offers built-in support for various data sources and sinks
Cons of Beam
- Steeper learning curve due to more complex concepts and abstractions
- Heavier resource requirements for setup and execution
- Less suitable for simple, lightweight workflow orchestration tasks
Code Comparison
Beam (Python):
import apache_beam as beam
with beam.Pipeline() as p:
lines = p | beam.io.ReadFromText('input.txt')
counts = (lines
| beam.FlatMap(lambda x: x.split())
| beam.Map(lambda x: (x, 1))
| beam.CombinePerKey(sum))
counts | beam.io.WriteToText('output.txt')
Luigi:
import luigi
class WordCount(luigi.Task):
def requires(self):
return ReadInputFile()
def output(self):
return luigi.LocalTarget('output.txt')
def run(self):
word_counts = {}
with self.input().open('r') as infile, self.output().open('w') as outfile:
for line in infile:
for word in line.split():
word_counts[word] = word_counts.get(word, 0) + 1
for word, count in word_counts.items():
outfile.write(f'{word}\t{count}\n')
if __name__ == '__main__':
luigi.run()
Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
Pros of Kedro
- More modern and actively maintained project with frequent updates
- Built-in support for data catalogs and pipelines, promoting better organization
- Stronger focus on reproducibility and best practices in data science workflows
Cons of Kedro
- Steeper learning curve due to more structured approach
- Less flexibility compared to Luigi's task-based system
- Smaller community and ecosystem of plugins/extensions
Code Comparison
Kedro pipeline definition:
def create_pipeline(**kwargs):
return Pipeline(
[
node(preprocess_data, "raw_data", "preprocessed_data"),
node(train_model, "preprocessed_data", "model"),
node(evaluate_model, ["model", "test_data"], "metrics"),
]
)
Luigi task definition:
class TrainModel(luigi.Task):
def requires(self):
return PreprocessData()
def output(self):
return luigi.LocalTarget("model.pkl")
def run(self):
# Load preprocessed data and train model
model = train_model(self.input().path)
with self.output().open('w') as f:
pickle.dump(model, f)
Both Kedro and Luigi are data pipeline frameworks, but they differ in their approach and target use cases. Kedro is more opinionated and focused on data science workflows, while Luigi offers more flexibility for general-purpose task scheduling and execution.
Convert  designs to code with AI
designs to code with AI

Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual CopilotREADME
.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/luigi.png :alt: Luigi Logo :align: center
{kind=link}
.. image:: https://img.shields.io/endpoint.svg?url=https%3A%2F%2Factions-badge.atrox.dev%2Fspotify%2Fluigi%2Fbadge&label=build&logo=none&%3Fref%3Dmaster&style=flat :target: https://actions-badge.atrox.dev/spotify/luigi/goto?ref=master
{kind=link}
.. image:: https://img.shields.io/codecov/c/github/spotify/luigi/master.svg?style=flat :target: https://codecov.io/gh/spotify/luigi?branch=master
{kind=link}
.. image:: https://img.shields.io/pypi/v/luigi.svg?style=flat :target: https://pypi.python.org/pypi/luigi
{kind=link}
.. image:: https://img.shields.io/pypi/l/luigi.svg?style=flat :target: https://pypi.python.org/pypi/luigi
{kind=link}
.. image:: https://readthedocs.org/projects/luigi/badge/?version=stable :target: https://luigi.readthedocs.io/en/stable/?badge=stable :alt: Documentation Status
Luigi is a Python (3.8, 3.9, 3.10, 3.11, 3.12 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Getting Started
Run pip install luigi to install the latest stable version from PyPI <https://pypi.python.org/pypi/luigi>_. Documentation for the latest release <https://luigi.readthedocs.io/en/stable/>__ is hosted on readthedocs.
Run pip install luigi[toml] to install Luigi with TOML-based configs <https://luigi.readthedocs.io/en/stable/configuration.html>__ support.
For the bleeding edge code, pip install git+https://github.com/spotify/luigi.git. Bleeding edge documentation <https://luigi.readthedocs.io/en/latest/>__ is also available.
Background
The purpose of Luigi is to address all the plumbing typically associated
with long-running batch processes. You want to chain many tasks,
automate them, and failures will happen. These tasks can be anything,
but are typically long running things like
Hadoop <http://hadoop.apache.org/>_ jobs, dumping data to/from
databases, running machine learning algorithms, or anything else.
There are other software packages that focus on lower level aspects of
data processing, like Hive <http://hive.apache.org/>,
Pig <http://pig.apache.org/>, or
Cascading <http://www.cascading.org/>. Luigi is not a framework to
replace these. Instead it helps you stitch many tasks together, where
each task can be a Hive query <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hive.html>,
a Hadoop job in Java <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hadoop_jar.html>,
a Spark job in Scala or Python <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.spark.html>,
a Python snippet,
dumping a table <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.sqla.html>_
from a database, or anything else. It's easy to build up
long-running pipelines that comprise thousands of tasks and take days or
weeks to complete. Luigi takes care of a lot of the workflow management
so that you can focus on the tasks themselves and their dependencies.
You can build pretty much any task you want, but Luigi also comes with a
toolbox of several common task templates that you use. It includes
support for running
Python mapreduce jobs <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hadoop.html>_
in Hadoop, as well as
Hive <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hive.html>,
and Pig <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.pig.html>,
jobs. It also comes with
file system abstractions for HDFS <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.hdfs.html>_,
and local files that ensures all file system operations are atomic. This
is important because it means your data pipeline will not crash in a
state containing partial data.
Visualiser page
The Luigi server comes with a web interface too, so you can search and filter among all your tasks.
.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/visualiser_front_page.png :alt: Visualiser page
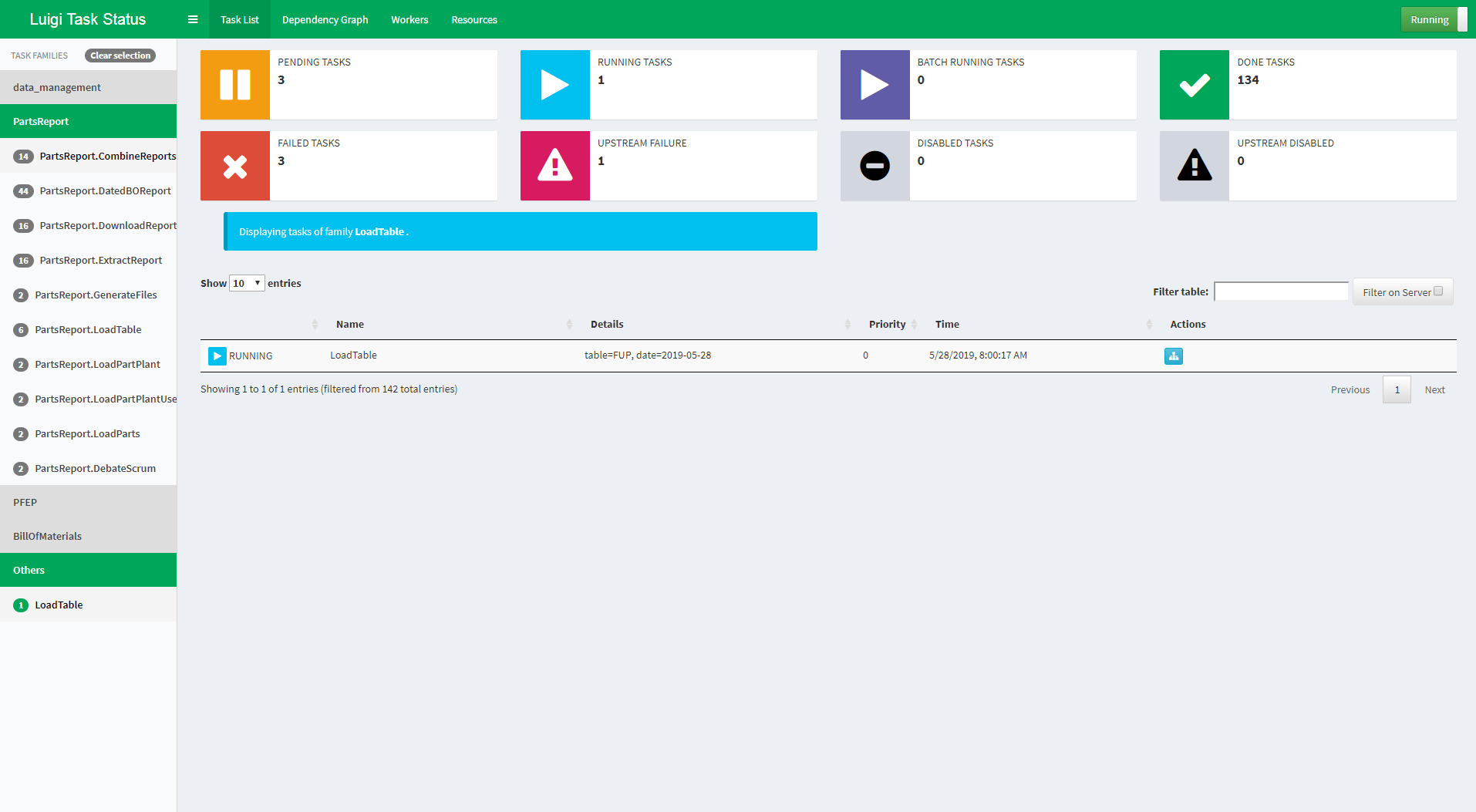{kind=link}
Dependency graph example
Just to give you an idea of what Luigi does, this is a screen shot from something we are running in production. Using Luigi's visualiser, we get a nice visual overview of the dependency graph of the workflow. Each node represents a task which has to be run. Green tasks are already completed whereas yellow tasks are yet to be run. Most of these tasks are Hadoop jobs, but there are also some things that run locally and build up data files.
.. figure:: https://raw.githubusercontent.com/spotify/luigi/master/doc/user_recs.png :alt: Dependency graph
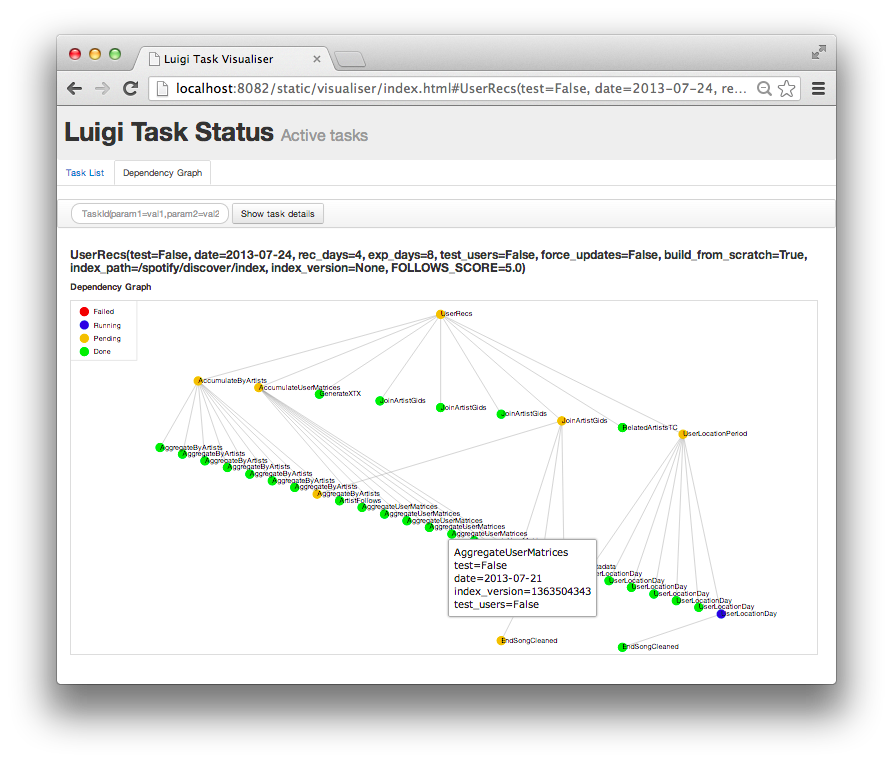{kind=link}
Philosophy
Conceptually, Luigi is similar to GNU Make <http://www.gnu.org/software/make/>_ where you have certain tasks
and these tasks in turn may have dependencies on other tasks. There are
also some similarities to Oozie <http://oozie.apache.org/>_
and Azkaban <https://azkaban.github.io/>_. One major
difference is that Luigi is not just built specifically for Hadoop, and
it's easy to extend it with other kinds of tasks.
Everything in Luigi is in Python. Instead of XML configuration or
similar external data files, the dependency graph is specified within
Python. This makes it easy to build up complex dependency graphs of
tasks, where the dependencies can involve date algebra or recursive
references to other versions of the same task. However, the workflow can
trigger things not in Python, such as running
Pig scripts <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.pig.html>_
or scp'ing files <https://luigi.readthedocs.io/en/latest/api/luigi.contrib.ssh.html>_.
Who uses Luigi?
We use Luigi internally at Spotify <https://www.spotify.com>_ to run
thousands of tasks every day, organized in complex dependency graphs.
Most of these tasks are Hadoop jobs. Luigi provides an infrastructure
that powers all kinds of stuff including recommendations, toplists, A/B
test analysis, external reports, internal dashboards, etc.
Since Luigi is open source and without any registration walls, the exact number of Luigi users is unknown. But based on the number of unique contributors, we expect hundreds of enterprises to use it. Some users have written blog posts or held presentations about Luigi:
Spotify <https://www.spotify.com>_(presentation, 2014) <http://www.slideshare.net/erikbern/luigi-presentation-nyc-data-science>__Foursquare <https://foursquare.com/>_(presentation, 2013) <http://www.slideshare.net/OpenAnayticsMeetup/luigi-presentation-17-23199897>__Mortar Data (Datadog) <https://www.datadoghq.com/>_(documentation / tutorial) <http://help.mortardata.com/technologies/luigi>__Stripe <https://stripe.com/>_(presentation, 2014) <http://www.slideshare.net/PyData/python-as-part-of-a-production-machine-learning-stack-by-michael-manapat-pydata-sv-2014>__Buffer <https://buffer.com/>_(blog, 2014) <https://buffer.com/resources/buffers-new-data-architecture/>__SeatGeek <https://seatgeek.com/>_(blog, 2015) <http://chairnerd.seatgeek.com/building-out-the-seatgeek-data-pipeline/>__Treasure Data <https://www.treasuredata.com/>_(blog, 2015) <http://blog.treasuredata.com/blog/2015/02/25/managing-the-data-pipeline-with-git-luigi/>__Growth Intelligence <http://growthintel.com/>_(presentation, 2015) <http://www.slideshare.net/growthintel/a-beginners-guide-to-building-data-pipelines-with-luigi>__AdRoll <https://www.adroll.com/>_(blog, 2015) <http://tech.adroll.com/blog/data/2015/09/22/data-pipelines-docker.html>__- 17zuoye
(presentation, 2015) <https://speakerdeck.com/mvj3/luiti-an-offline-task-management-framework>__ Custobar <https://www.custobar.com/>_(presentation, 2016) <http://www.slideshare.net/teemukurppa/managing-data-workflows-with-luigi>__Blendle <https://launch.blendle.com/>_(presentation) <http://www.anneschuth.nl/wp-content/uploads/sea-anneschuth-streamingblendle.pdf#page=126>__TrustYou <http://www.trustyou.com/>_(presentation, 2015) <https://speakerdeck.com/mfcabrera/pydata-berlin-2015-processing-hotel-reviews-with-python>__Groupon <https://www.groupon.com/>_ /OrderUp <https://orderup.com>_(alternative implementation) <https://github.com/groupon/luigi-warehouse>__Red Hat - Marketing Operations <https://www.redhat.com>_(blog, 2017) <https://github.com/rh-marketingops/rh-mo-scc-luigi>__GetNinjas <https://www.getninjas.com.br/>_(blog, 2017) <https://labs.getninjas.com.br/using-luigi-to-create-and-monitor-pipelines-of-batch-jobs-eb8b3cd2a574>__voyages-sncf.com <https://www.voyages-sncf.com/>_(presentation, 2017) <https://github.com/voyages-sncf-technologies/meetup-afpy-nantes-luigi>__Open Targets <https://www.opentargets.org/>_(blog, 2017) <https://blog.opentargets.org/using-containers-with-luigi>__Leipzig University Library <https://ub.uni-leipzig.de>_(presentation, 2016) <https://de.slideshare.net/MartinCzygan/build-your-own-discovery-index-of-scholary-eresources>__ /(project) <https://finc.info/de/datenquellen>__Synetiq <https://synetiq.net/>_(presentation, 2017) <https://www.youtube.com/watch?v=M4xUQXogSfo>__Glossier <https://www.glossier.com/>_(blog, 2018) <https://medium.com/glossier/how-to-build-a-data-warehouse-what-weve-learned-so-far-at-glossier-6ff1e1783e31>__Data Revenue <https://www.datarevenue.com/>_(blog, 2018) <https://www.datarevenue.com/en/blog/how-to-scale-your-machine-learning-pipeline>_Uppsala University <http://pharmb.io>_(tutorial) <http://uppnex.se/twiki/do/view/Courses/EinfraMPS2015/Luigi.html>_ /(presentation, 2015) <https://www.youtube.com/watch?v=f26PqSXZdWM>_ /(slides, 2015) <https://www.slideshare.net/SamuelLampa/building-workflows-with-spotifys-luigi>_ /(poster, 2015) <https://pharmb.io/poster/2015-sciluigi/>_ /(paper, 2016) <https://doi.org/10.1186/s13321-016-0179-6>_ /(project) <https://github.com/pharmbio/sciluigi>_GIPHY <https://giphy.com/>_(blog, 2019) <https://engineering.giphy.com/luigi-the-10x-plumber-containerizing-scaling-luigi-in-kubernetes/>__xtream <https://xtreamers.io/>__(blog, 2019) <https://towardsdatascience.com/lessons-from-a-real-machine-learning-project-part-1-from-jupyter-to-luigi-bdfd0b050ca5>__CIAN <https://cian.ru/>__(presentation, 2019) <https://www.highload.ru/moscow/2019/abstracts/6030>__
Some more companies are using Luigi but haven't had a chance yet to write about it:
Schibsted <http://www.schibsted.com/>_enbrite.ly <http://enbrite.ly/>_Dow Jones / The Wall Street Journal <http://wsj.com>_Hotels.com <https://hotels.com>_Newsela <https://newsela.com>_Squarespace <https://www.squarespace.com/>_OAO <https://adops.com/>_Grovo <https://grovo.com/>_Weebly <https://www.weebly.com/>_Deloitte <https://www.Deloitte.co.uk/>_Stacktome <https://stacktome.com/>_LINX+Neemu+Chaordic <https://www.chaordic.com.br/>_Foxberry <https://www.foxberry.com/>_Okko <https://okko.tv/>_ISVWorld <http://isvworld.com/>_Big Data <https://bigdata.com.br/>_Movio <https://movio.co.nz/>_Bonnier News <https://www.bonniernews.se/>_Starsky Robotics <https://www.starsky.io/>_BaseTIS <https://www.basetis.com/>_Hopper <https://www.hopper.com/>_VOYAGE GROUP/Zucks <https://zucks.co.jp/en/>_Textpert <https://www.textpert.ai/>_Tracktics <https://www.tracktics.com/>_Whizar <https://www.whizar.com/>_xtream <https://www.xtreamers.io/>__Skyscanner <https://www.skyscanner.net/>_Jodel <https://www.jodel.com/>_Mekar <https://mekar.id/en/>_M3 <https://corporate.m3.com/en/>_Assist Digital <https://www.assistdigital.com/>_Meltwater <https://www.meltwater.com/>_DevSamurai <https://www.devsamurai.com/>_Veridas <https://veridas.com/>_Aidentified <https://www.aidentified.com/>_
We're more than happy to have your company added here. Just send a PR on GitHub.
External links
Mailing List <https://groups.google.com/d/forum/luigi-user/>_ for discussions and asking questions. (Google Groups)Releases <https://pypi.python.org/pypi/luigi>_ (PyPI)Source code <https://github.com/spotify/luigi>_ (GitHub)Hubot Integration <https://github.com/houzz/hubot-luigi>_ plugin for Slack, Hipchat, etc (GitHub)
Authors
Luigi was built at Spotify <https://www.spotify.com>, mainly by
Erik Bernhardsson <https://github.com/erikbern> and
Elias Freider <https://github.com/freider>.
Many other people <https://github.com/spotify/luigi/graphs/contributors>
have contributed since open sourcing in late 2012.
Arash Rouhani <https://github.com/tarrasch>_ was the chief maintainer from 2015 to 2019, and now
Spotify's Data Team maintains Luigi.
Top Related Projects
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Prefect is a workflow orchestration framework for building resilient data pipelines in Python.
An orchestration platform for the development, production, and observation of data assets.
Always know what to expect from your data.
Apache Beam is a unified programming model for Batch and Streaming data processing.
Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
Convert designs to code with AI
Introducing Visual Copilot: A new AI model to turn Figma designs to high quality code using your components.
Try Visual Copilot